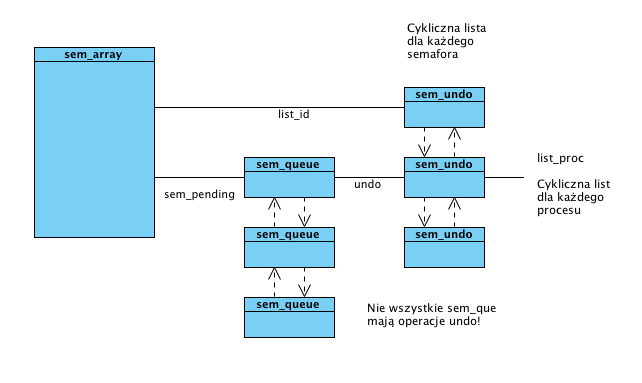
Schemat zależności między strukturami danych dotyczących semafora.
IPC, czyli Interprocess Communications, to zbiór mechanizmów służących do wymiany informacji między procesami. Elementami zaimplementowanego w Linuxie systemu SysV IPC są semafory, kolejki komunikatów i współdzielone segmenty pamięci.
Struktury danych służące do implementacji tych mechanizmów zmieniały się w kolejnych wersjach jądra, by zapewnić obsługę SMP, przestrzeni nazw, a także zwiększyć efektywność dzięki RCU.
...opanowaliśmy na kursowym wykładzie z SO. Przypomnę tylko, że mieliśmy funkcje ***get(), ***ctl(), gdzie pod *** ukrywa się jeden ze skrótów: sem, msq, shm.
Zwykle w celu stworzenia nowego zasobu IPC korzystamy z klucza IPC. Jeżeli chcemy, by dwa procesy współdzieliły ze sobą zasób IPC, to będą musiały znać ten wspólny klucz. Istnieje też ryzyko konfliktu, gdy jakiś inny proces będzie próbował wykorzystać ten sam klucz.
Do rozpoznawania przydzielonych zasobów IPC służą ich identyfikatory. Są one unikatowe w ramach jednej przestrzeni nazw. Oblicza je funkcja:
inline int ipc_buildid(int id, int seq)
{
return SEQ_MULTIPLIER * seq + id;
}
Zapewnia nam ona, że identyfikatory nie będą się powtarzać zbyt często. Zmienna seq jest zwiększana przy każdej dealokacji zasobu.
Informacje o każdym zasobie IPC, niezależnie od typu, są przechowywane w strukturze kern_ipc_perm
struct kern_ipc_perm
{
spinlock_t lock;
int deleted;
int id;
key_t key;
uid_t uid; /* właściciela */
gid_t gid;
uid_t cuid; /* twórcy */
gid_t cgid;
mode_t mode; /* Maska bitowa uprawnień */
unsigned long seq;
void *security;
};
Kiedyś (do wersji 2.2 włącznie) dla każdego typu zasobu trzymano globalną statyczną tablicę wskaźników na struktury typu kern_ipc_perm (które wtedy nazywały się ipc_perm). W jądrze 2.4 tablica była dynamiczna - w czasie działania systemu jej rozmiar mógł się zmieniać. Obecnie wprowadzony już został podział na przestrzenie nazw, zatem nie ma globalnych struktur przechowujących informacje o zasobach IPC. Zamiast nich, dla każdej przestrzeni nazw, w strukturze ipc_namespace mamy pole struct ipc_ids ids[3];, które dla każdego typu zasobów trzyma następujące informacje:
struct ipc_ids {
int in_use;
unsigned short seq;
unsigned short seq_max;
struct rw_semaphore rw_mutex;
struct idr ipcs_idr;
};
Pole ipcs_idr to drzewo pozycyjne, które przechowuje mapowanie między identyfikatorami zasobów, a wskaźnikami do obiektów typu kern_ipc_perm. W porównaniu do tablicy, którą trzeba było liniowo przeszukiwać, zyskaliśmy oszczędność czasu.
Przypomnijmy, że semafory IPC składają się z pewnej liczby semaforów prostych. Do przechowywania informacji o całej grupie służy struktura:
/* One sem_array data structure for each set of semaphores in the system. */
struct sem_array {
struct kern_ipc_perm sem_perm; /* permissions .. see ipc.h */
time_t sem_otime; /* last semop time */
time_t sem_ctime; /* last change time */
struct sem *sem_base; /* ptr to first semaphore in array */
struct list_head sem_pending; /* pending operations to be processed */
struct list_head list_id; /* undo requests on this array */
int sem_nsems; /* no. of semaphores in array */
int complex_count; /* pending complex operations */
};
Procesy, które zawisły na semaforze znajdują się w kolejce sem_pending w strukturze typu:
/* One queue for each sleeping process in the system. */
struct sem_queue {
struct list_head simple_list; /* queue of pending operations */
struct list_head list; /* queue of pending operations */
struct task_struct *sleeper; /* this process */
struct sem_undo *undo; /* undo structure */
int pid; /* process id of requesting process */
int status; /* completion status of operation */
struct sembuf *sops; /* array of pending operations */
int nsops; /* number of operations */
int alter; /* does the operation alter the array? */
};
Zwróćmy uwagę, że powyższa klasa ma 2 pola opisane jako "queue of pending operations" i jedno jako "array of pending operations". O co tu chodzi?
Operacje na semaforach mogą być wykonane w trybie undo. Wówczas, gdy proces umrze, to zostaną one automatycznie odwołane (o ile to możliwe). Jest to prosty sposób zapobiegania zakleszczeniom, gdy jakiś proces niespodziewanie zginie.
struct sem_undo {
struct list_head list_proc; /* per-process list: all undos from one process. */
/* rcu protected */
struct rcu_head rcu; /* rcu struct for sem_undo() */
struct sem_undo_list *ulp; /* sem_undo_list for the process */
struct list_head list_id; /* per semaphore array list: all undos for one array */
int semid; /* semaphore set identifier */
short * semadj; /* array of adjustments, one per semaphore */
};
Elementy sem_undo są chronione za pomocą rcu, co powinno polepszać efektywność.
Właściwa funkcjonalność jest realizowana bardzo prosto: w polu semadj znajduje się tablica liczb, o które należy zmienić wartości wszystkich semaforów prostych.
Zwróćmy uwagę, że struktury sem_undo leżą jednocześnie na dwóch listach: jednej właściwej dla procesu (list_proc) i drugiej dla semafora (list_id).
W zrozumieniu zależności między tymi strukturami może pomóc poniższy schemat:
Schemat zależności między strukturami danych dotyczących semafora.
Kolejki komunikatów służą do przekazywania pewnych wiadomości między procesami. Z każdą wiadomością związany jest jej typ (liczba naturalna), możliwe jest selektywne pobieranie wiadomości np. tylko określonego typu. Z tego powodu nazwa kolejka nie odpowiada w pełni rzeczywistości - wiadomości nie zawsze są przekazywane w kolejności FIFO.
Do przesyłania i odbierania komunikatów służą operacje msgsnd i msgrcv.
Struktura przechowująca informacje o całej kolejce:
/* one msq_queue structure for each present queue on the system */
struct msg_queue {
struct kern_ipc_perm q_perm;
time_t q_stime; /* last msgsnd time */
time_t q_rtime; /* last msgrcv time */
time_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
};
q_messages to głowa listy zawierającej komunikaty w strukturach:
/* one msg_msg structure for each message */
struct msg_msg {
struct list_head m_list;
long m_type;
int m_ts; /* message text size */
struct msg_msgseg* next;
void *security;
/* the actual message follows immediately */
};
W strukturze tej nie ma specjalnego pola na dane. Następują one w pamięci bezpośrednio po tej strukturze. Maksymalna ilość danych, określona przez makro DATALEN_MSG, jest dobrana tak, by wraz ze strukturą msg_msg zajmować jedną stronę. Jeżeli komunikat jest dłuższy, to pozostałą część danych przechowuje jednokierunkowa lista buforów typu:
struct msg_msgseg {
struct msg_msgseg* next;
/* the next part of the message follows immediately */
};
Tak jak poprzednio właściwe dane znajdują się w pamięci tuż za strukturą msg_msgseg.
Na poniższym schemacie przedstawiono struktury danych do przechowywania kolejki złożonej z trzech komunikatów, z których jeden jest dość długi.
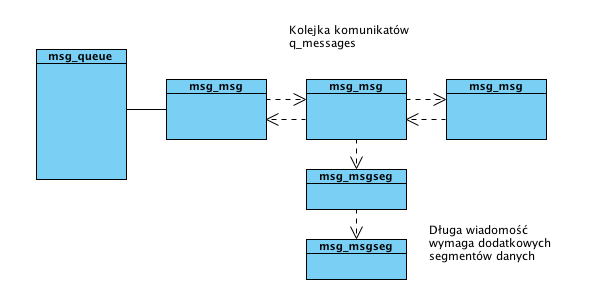
Schemat prezentujący komunikaty w kolejce IPC.
Dość ciekawe wydaje mi się, że komunikaty nadal są przechowywane w postaci zwykłej listy. Gdy proces chce znaleźć komunikat określonego typu może być zmuszonydo przejrzenia całej kolejki. Asymptotyczne przyśpieszenie tego procesu, przy założeniu że proces musi otrzymać zawsze pierwszy z akceptowanych przez siebie komunikatów nie byłoby proste. Wydaje mi się, że można by je zrealizować z pomocą drzewa przedziałowego. Prawdopodobnie w praktyce byłoby to jednak wolniejsze rozwiązanie.
Są dwie sytuacje związane z obsługą kolejek komunikatów, w których procesy muszą usnąć:
/* one msg_sender for each sleeping sender */
struct msg_sender {
struct list_head list;
struct task_struct *tsk;
};
/*
* one msg_receiver structure for each sleeping receiver:
*/
struct msg_receiver {
struct list_head r_list;
struct task_struct *r_tsk;
int r_mode;
long r_msgtype;
long r_maxsize;
struct msg_msg *volatile r_msg;
};
Dzięki zasobom tego typu procesy mogą w prosty sposób współdzielić ze sobą pewne segmenty pamięci.
Aby skorzystać z segmentu nie wystarczy go stworzyć. Proces musi go jeszcze dołączyć do swojej przestrzeni adresowej za pomocą funkcji shmat. Do odłączania służy funkcja shmdt.
W przeciwieństwie do innych zasobów IPC możemy zapewnić, że współdzielony segment pamięci zostanie usunięty po odłączeniu od niego ostatniego procesu. W tym celu wystarczy stworzyć go z ustawioną flagą SHM_DEST.
Struktura przechowująca informacje o współdzielonym segmencie pamięci:
struct shmid_kernel /* private to the kernel */
{
struct kern_ipc_perm shm_perm;
struct file * shm_file;
unsigned long shm_nattch;
unsigned long shm_segsz;
time_t shm_atim; /* czas ostatniego dołączenia, odłączenia i stworzenia */
time_t shm_dtim;
time_t shm_ctim;
pid_t shm_cprid; /* pidy twórcy i ostatniego użytkownika */
pid_t shm_lprid;
struct user_struct *mlock_user; /* użytkownik, który trzyma lock'a */
};
Segmenty pamięci współdzielonej są przechowywane w systemie jako pliki. Można je znaleźć w katalogu /proc/pid/maps, a ich nazwy są postaci SYSVkey.
Do tego pliku odnosi się pole shm_file w powyższej strukturze.
Powstały plik jest mapowany do pamięci procesu gdy wywołana zostaje funkcja shmat. Tak jak w przypadku mapowania zwykłych plików wykorzystuje ona funkcję do_mmap.
Pliki segmentów pamięci bardzo niewiele różnią się od innych plików. Mają jedynie inne pewne funkcje z vm_operations_struct (np. shm_open).
Wymagane dodatkowe informacje o takich plikach są przechowywane w strukturze:
struct shm_file_data {
int id;
struct ipc_namespace *ns;
struct file *file;
const struct vm_operations_struct *vm_ops;
};
Wskazuje na nią pole private_data. Dane uzyskuje się poniższym makrem:
#define shm_file_data(file) (*((struct shm_file_data **)&(file)->private_data))