Mechanizm RCU (Read, Copy, Update) to sposób synchronizacji, promowany jako bardziej wydajny od read-write lock. RCU pozwala na jednoczesny dostęp do danych wielu czytelnikom przy praktycznie zerowym narzucie. Pisarz może dokonywać modyfikacji nie blokując przy tym czytelników - zmiany nie są widoczne dla czytelników, dopóki nie zostaną "opublikowane". Mechanizm RCU zapewnia, że w każdym momencie czytelnicy widzą spójny obraz danych.
Ceną, jaką płaci się za tę wydajność, jest wymóg, by czytelnicy nie mogli blokować się wewnątrz sekcji krytycznej. Oprócz tego RCU może chronić jedynie dane alokowane dynamicznie na stercie.
RCU określa się czasem jako mechanizm publish-subscribe, to znaczy, że zarówno czytelnicy, jak i pisarze mają pewien "uchwyt", reprezentujący dane, na których chcą operować. W przypadku RCU funkcję owego "uchwytu" pełni wskaźnik, na którym nie operujemy bezpośrednio, ale poprzez API dostarczone przez RCU. I tak:
// Czytelnicy:
struct foo *gp; // "Uchwyt" do danych
/* ... */
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c); // Czytaj
}
rcu_read_unlock();
// Pisarz:
p = rcu_dereference(gp);
*q = *p;
q->b = 2;
rcu_assign_pointer(gp, q); // Opublikuj nową wersję
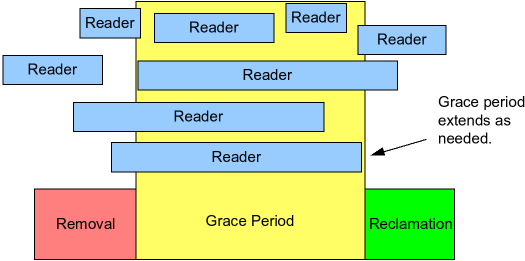
Powyższe przykłady ukazują dwa z trzech najważniejszych składowych RCU - pobieranie danych do odczytu oraz publikację nowej wersji danych. Trzecią składową RCU jest możliwość bezpiecznego zwolnienia pamięci po starej wersji danych. W tym celu pisarz, po zakończeniu swojego zadania, powinien zaczekać, aż wszyscy istniejący czytelnicy opuszczą sekcję krytyczną (a więc nikt nie będzie już czytał starej wersji), po czym zwolnić pamięć. Czas, który pisarz musi odczekać nazywamy grace period.
// Pisarz:
/* ... */
rcu_assign_pointer(gp, q);
synchronize_rcu(); // Zaczekaj na ostatniego czytelnika
kfree(p);
Jeśli pisarz nie chce blokować się w oczekiwaniu na koniec grace period, może zarejestrować, poprzez funkcję z API RCU (call_rcu), callback, który zostanie wywołany w odpowiednim momencie.
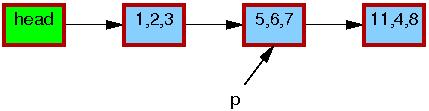
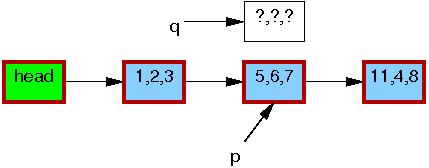
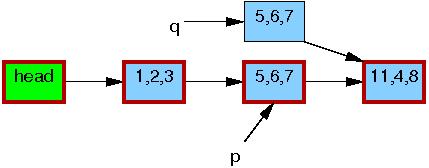
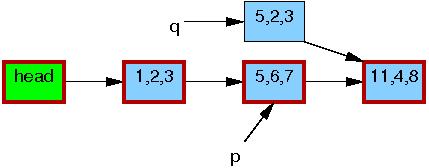
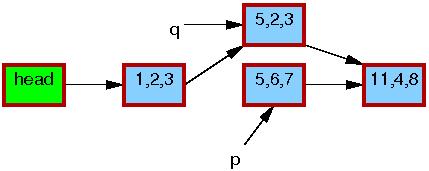
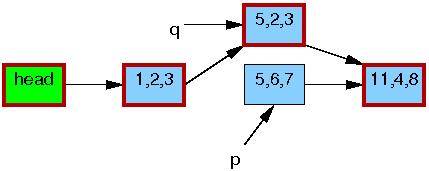
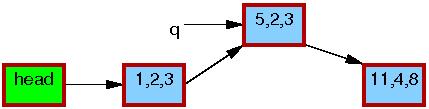
Jakkolwiek podstawowa funkcjonalność RCU zawiera się w już omówionych funkcjach i przykładach, do naszej dyspozycji są też funkcje wyższego poziomu, które wykorzystując RCU, manipulują na listach (zarówno cyklicznych, jak i typu hlist). Pozwolają one także zademonstrować prosty przykład - modyfikację elementu listy.
|
 |
|  |
|
 |
|
 |
|
 |
|
 |
|
 |
Zanim przejdziemy do szczegółów technicznych, rysunek przedstawiający graficznie potencjalny zysk wydajnościowy oferowany przez RCU:
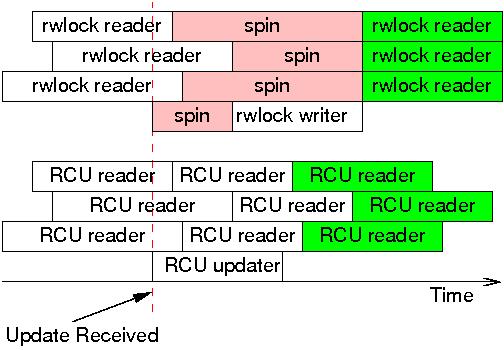
Jak już wspomniano na początku, koncepcyjnie RCU jest mechanizmem publish-subscribe, w którym wskaźnik pełni jedynie rolę "uchwytu". RCU wprowadza dodatkową warstwę abstrakcji w dostępie do danych - na wskaźniku nie operujemy bezpośrednio. Jak się to ma do wydajności?
Otóż okazuje się, że na większośc architektur operacje na wskaźnikach (a więc odczyt i zapis) są atomowe, więc nie potrzebujemy żadnych dodatkowych mechanizmów. Makra rcu_dereference i rcu_assign_pointer upewniają się jedynie, że ani kompilator, ani procesor nie zaczną ingerować w kolejność wykonywanych rozkazów.
W prostej implementacji RCU, operacje rcu_read_lock i rcu_read_unlock mogą być równoważne operacjom preempt_disable i preempt_enable. Dzięki temu możemy mieć pewność, że czytelnik nie zostanie wywłaszczony będąc w sekcji krytycznej i możemy łatwo kontrolować, kto widzi jakie dane. W takim modelu operacja synchronize_rcu po prostu zdobywa na chwilę każdy procesor, po czym ma pewność, że wszyscy czytelnicy rozpoczęli swoje sekcje krytyczne już po aktualizacji globalnego wskaźnika (*gp w przykładach). W tym miejscu warto przypomnieć, że czytelnikom nie wolno oddać procesora wewnątrz sekcji krytycznej (np. poprzez operację wejścia-wyjścia).
Jakkolwiek RCU występuje w kilku odmianach, obecnie używana implementacja pozwala jednak na wywłaszczanie czytelników wewnątrz sekcji krytycznej, przez co całość nieco się komplikuje.
Operacje na listach to w zasadzie kopie odpowiednich operacji znanych z pozostałych części jądra, które zamiast odczytywać i zapisywać wskaźniki ręcznie, używają do tego celu RCU:
static inline void list_replace_rcu(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->prev = old->prev;
rcu_assign_pointer(new->prev->next, new);
new->next->prev = new;
old->prev = LIST_POISON2;
}
| Janina Mincer-Daszkiewicz |