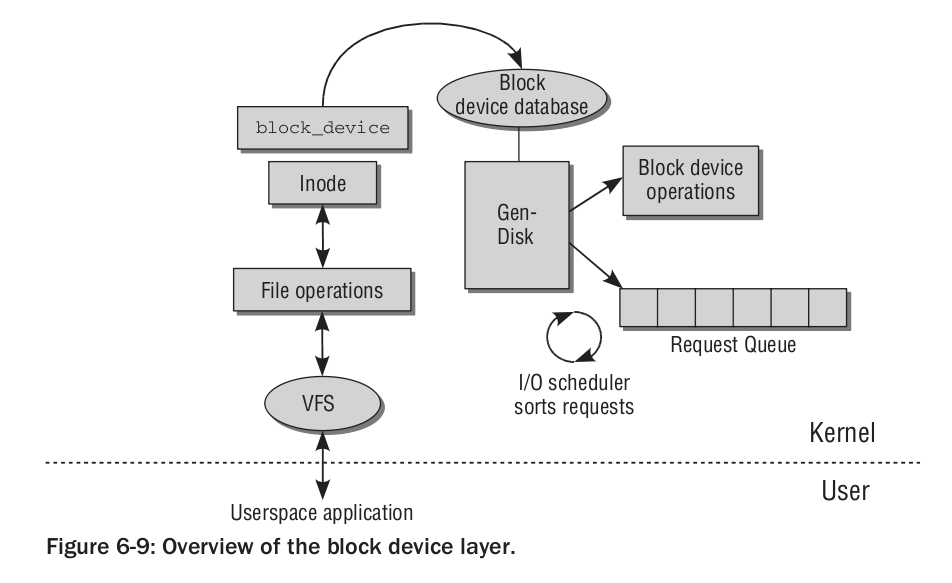
Rysunek: Warstwa blokowa - ogólny diagram (Źródło: Mauerer, Professional Linux Kernel Architecture")
Niniejsze materiały dotyczą wewnętrznej pracy warstwy blokowej. Kluczową obserwacją jest pozycja modułu szeregującego żądania wejścia-wyjścia - jest on częścią tej warstwy, a nie osobnym bytem. Nie stanowi też - jak kiedyś - mediatora między warstwą blokową a sterownikami, a za to obserwuje kolejkę żądań (request_queue) i reaguje na wywołania przychodzące z warstwy blokowej. Ten fakt będzie potrzebny do zrozumienia przepływu kontroli podczas obsługi żądania.
Rysunek: Warstwa blokowa - ogólny diagram (Źródło: Mauerer, Professional Linux Kernel Architecture")
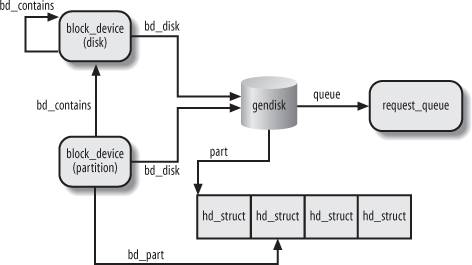
Rysunek: Warstwa blokowa - ogólny diagram (Źródło: Bovet, Cesati, Understanding the Linux Kernel")
struct block_device {
dev_t bd_dev;
struct inode * bd_inode;
struct super_block * bd_super;
int bd_openers;
struct mutex bd_mutex; /* open/close mutex */
struct list_head bd_inodes;
void * bd_holder;
int bd_holders;
struct block_device * bd_contains;
unsigned bd_block_size;
struct hd_struct * bd_part;
unsigned bd_part_count;
int bd_invalidated;
struct gendisk * bd_disk;
struct list_head bd_list;
unsigned long bd_private;
...
};
Urządzenie blokowe jest opisane przez strukturę block_device. Numer urządzenia jest zapisany w bd_dev. Wszystkie i-węzły, które reprezentują urządzenia blokowe są trzymane w pseudo systemie plików bdev, pole bd_inode wskazuje na odpowiedni i-węzeł. Pole bd_inodes służy do łączenia w listę wszystkich i-węzłów, które reprezentują pliki specjalne dla urządzenia blokowego. Pole bd_part wskazuje na strukturę reprezentującą partycję dysku. Pole bd_list tworzy listę wszystkich urządzeń blokowych w systemie (wskazuje na nią zmienna globalna all_bdevs).
struct gendisk {
int major; /* major number of driver */
int first_minor;
int minors; /* maximum number of minors, =1 for
* disks that can't be partitioned. */
char disk_name[DISK_NAME_LEN]; /* name of major driver */
struct hd_struct **part;
const struct block_device_operations *fops;
struct request_queue *queue;
void *private_data;
int flags;
struct device *driverfs_dev; // FIXME: remove
struct kobject kobj;
...
};
Struktura gendisk reprezentuje generyczny dysk twardy z partycjami. Pole major to numer główny urządzenia, disk_name to nazwa dysku opisująca go w systemie plików sysfs, part jest tablicą zawierającą wskaźniki do struktur hd_struct opisujących partycje dysku. fops to wskaźnik do tablicy funkcji niskopoziomowych. queue to kolejka żądań.
struct hd_struct {
sector_t start_sect;
sector_t nr_sects;
struct kobject kobj;
...
};
Partycja dysku jest reprezentowana przez strukturę hd_struct. Pole start_sect definiuje sektor startowy, a nr_sects rozmiar partycji.
struct elevator_queue
{
struct elevator_ops *ops;
void *elevator_data;
struct kobject kobj;
struct elevator_type *elevator_type;
struct mutex sysfs_lock;
struct hlist_head *hash;
};
struct request_queue {
struct list_head queue_head;
struct list_head *last_merge;
struct elevator_queue *elevator
struct request_list rq;
request_fn_proc *request_fn;
make_request_fn *make_request_fn;
prep_rq_fn *prep_rq_fn;
unplug_fn *unplug_fn;
...
};
Żądania odczytu i zapisu z i do urządzeń blokowych są umieszczane w kolejce żądań request_queue, wchodzącej w skład struktury gendisk. queue_head jest dwukierunkową listą żądań (tutaj trafiają struktury request reprezentujące żądania). elevator to rodzina funkcji elevator_ops do obsługi kolejki. rq pełni rolę pamięci podręcznej struktur request. Funkcja request_fn służy do dodawania nowych żądań do kolejki (strategy routine), make_request_fn tworzy nowe żądania, unplug_fn służy do odblokowywania urządzenia. Zablokowane urządzenie (ang. plugged device) nie realizuje żądań, a jedynie zbiera je i czeka aż zostanie odblokowane. Kolejka żądań może zostać zablokowana, gdy system jest przeciążony. Nie są wówczas obsługiwane nowe żądania aż do momentu, gdy kolejka zostanie odblokowana.
struct request {
struct list_head queuelist;
struct list_head donelist;
struct request_queue *q;
unsigned int cmd_flags;
enum rq_cmd_type_bits cmd_type;
sector_t sector; /*next sector to submit */
sector_t hard_sector; /* next sector to cpmplete */
unsigned long nr_sectors; /* number of sectors left to submit */
unsigned long hard_nr_sectors; /* number of sectors left to complete */
/* number of sectors left to submit in the current segment */
unsigned int current_nr_sectors;
/* number of sectors left to complete in the current segment */
unisgned int hard_cur_sectors;
struct bio *bio;
struct bio *biotail;
void *elevator_private;
void *elevator_private2;
struct gendisk *rq_disk;
unsigned long start_time;
...
};
Żądania są trzymane w kolejce poprzez pole queuelist, q wskazuje na zawierającą to żądanie kolejkę request_queue. Po obsłużeniu żądanie trafia do listy donelist. Dokładną pozycję danych do transmisji wskazują pola sector, current_nr_sectors i nr_sectors (liczba sektorów nadal czekających na przesłanie). Do transmisji danych między systemem a urządzeniem służą struktury bio. Pole bio wskazuje na bieżące bio, którego transmisja jeszcze się nie zakończyła, biotail wskazuje na ostatnie żądanie.
W jądrach z serii 2.4 podstawową jednostką wejścia-wyjścia warstwy blokowej była struct buffer_head, bardzo prosta struktura odpowiadająca za mapowanie jednej strony w pamięci na jeden blok urządzenia. By obsłużyć żądanie wejścia-wyjścia spreparowany przez kod wyższych warstw buffer_head był dodawany do modułu szeregującego. W serii 2.4 de facto jedynym modułem szeregującym był elevator_linus, działający metodą scan. Niestety, to rozwiązanie sprawowało się bardzo słabo. elevator_linus miał złożoność czasową O(n) względem liczby żądań. Ponieważ zaś struktura buffer_head mieściła najwyżej jedną stronę (a często znacznie mniej, opisywała bowiem ideologicznie jeden blok), obsługa wejścia-wyjścia pochłaniała bardzo dużo czasu. Wreszcie, cały moduł szeregujący był synchronizowany przy pomocy jednej blokady (io_request_lock). To wszystko prowadziło do bardzo niskiej skalowalności i wyraźnie ograniczało potencjał Linuksa. Dlatego też w serii 2.6 nastąpiły poważne zmiany w strukturze warstwy blokowej.
W jądrach serii 2.6 podstawową jednostką wejścia-wyjścia warstwy blokowej jest nowa struktura: struct bio. Zaprojektowano ją mając na względzie następujące cele:
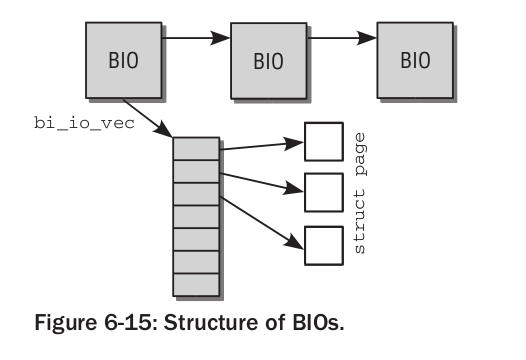
Na diagramie przedstawione są wzajemne połączenia bio, bio_vec i page. Godny uwagi jest fakt, że w odróżnieniu od buffer_head, strony nie muszą być w ogóle w pamięci wirtualnej jądra.
Poniżej przedstawiam definicje pomocnicze i właściwą definicję struct bio.
struct bio_vec {
struct page *bv_page; /* strona, do ktorej przypiety jest ten bio_vec */
unsigned int bv_len; /* dlugosc interesujacego fragmentu strony */
unsigned int bv_offset; /* offset fragmentu */
};
typedef void (bio_end_io_t) (struct bio *, int); /* callback wykonany po zakonczeniu bio */
typedef void (bio_destructor_t) (struct bio *); /* destruktor */
struct bio {
sector_t bi_sector; /* adres na urządzeniu (w 512B sektorach) */
struct bio *bi_next; /* odniesienie do kolejki request */
struct block_device *bi_bdev;
unsigned long bi_flags; /* flagi */
unsigned long bi_rw; /* dolne bity określają READ/WRITE, górne priorytet */
unsigned short bi_vcnt; /* ile jest bio_vec */
unsigned short bi_idx; /* gdzie teraz jesteśmy w bio_vec */
unsigned int bi_phys_segments; /* ile segmentów jest w BIO po złączeniu sąsiednich adresów fizycznych */
unsigned int bi_size; /* residual I/O count */
unsigned int bi_seg_front_size; /* rozmiar pierwszego i ostatniego segmentu w tym bio, które można złączyć */
/* potrzebne, by obliczać rozmiar segmentów w bio */
unsigned int bi_seg_back_size;
unsigned int bi_max_vecs; /* ile bio_vec można przechować w tym bio */
unsigned int bi_comp_cpu; /* procesor, na którym wykona się bi_end_io */
atomic_t bi_cnt; /* licznik użyć (modyfikowany przez bio_get/put) */
struct bio_vec *bi_io_vec; /* dane */
bio_end_io_t *bi_end_io; /* callback po zakończeniu operacji */
void *bi_private;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* sprawdzanie spójności danych */
#endif
bio_destructor_t *bi_destructor; /* destruktor */
/* pewna ilosc bio_vec mozna zaalokowac razem z bio, by uniknac podwojnej alokacji.
* w tej konfiguracji nieuzywane. */
struct bio_vec bi_inline_vecs[0];
};
Dla celów wydajności - szczególnie w sytuacjach kryzysowych - bio alokowane są przy pomocy mechanizmu mempool.
By wysłać żądanie zapisu lub odczytu z urządzenia blokowego, prosimy najpierw o bio za pomocą funkcji bio_alloc. Następnie wypełniamy pola struktury, wreszcie wywołujemy funkcję submit_bio lub bezpośrednio generic_make_request. Na skutek tego wywołane zostaje __generic_make_request, które ostatecznie odwołuje się do kolejki żądań urządzenia blokowego związanego z naszym bio i wywołuje make_request_fn, a więc dostarczoną przez kolejkę funkcję włączającą do niej bio. Przedtem przemapowuje numery sektorów do absolutnych pozycji na dysku, wywołując blk_partition_remap.
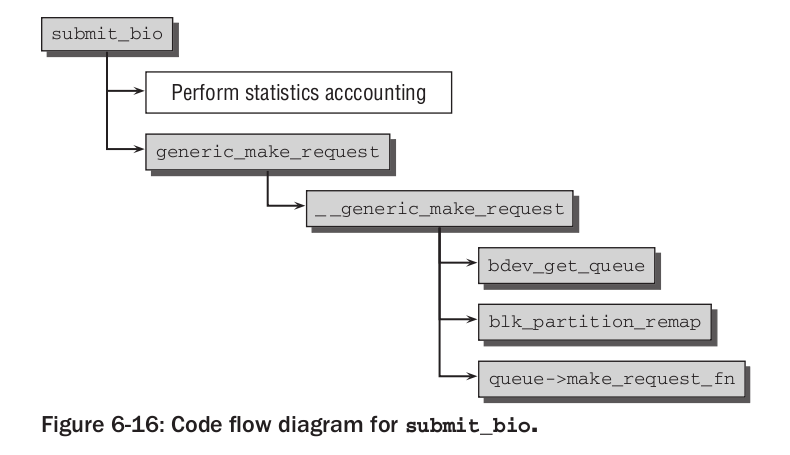
Powyższy diagram ilustruje przebieg procedury submit_bio. make_request_fn jest dostarczoną przez sterownik urządzenia funkcją, odpowiadającą za tworzenie struct request z podanego bio. Dzięki przemyślnej implementacji generic_make_request skutecznie radzi sobie z rekurencyjnymi wywołaniami, a więc przekierowaniem wejścia-wyjścia między urządzeniami, pozwalając na elegancką implementację mapowania urządzeń. Następnie przyjrzyjmy się domyślnej implementacji make_request_fn, czyli __make_request.
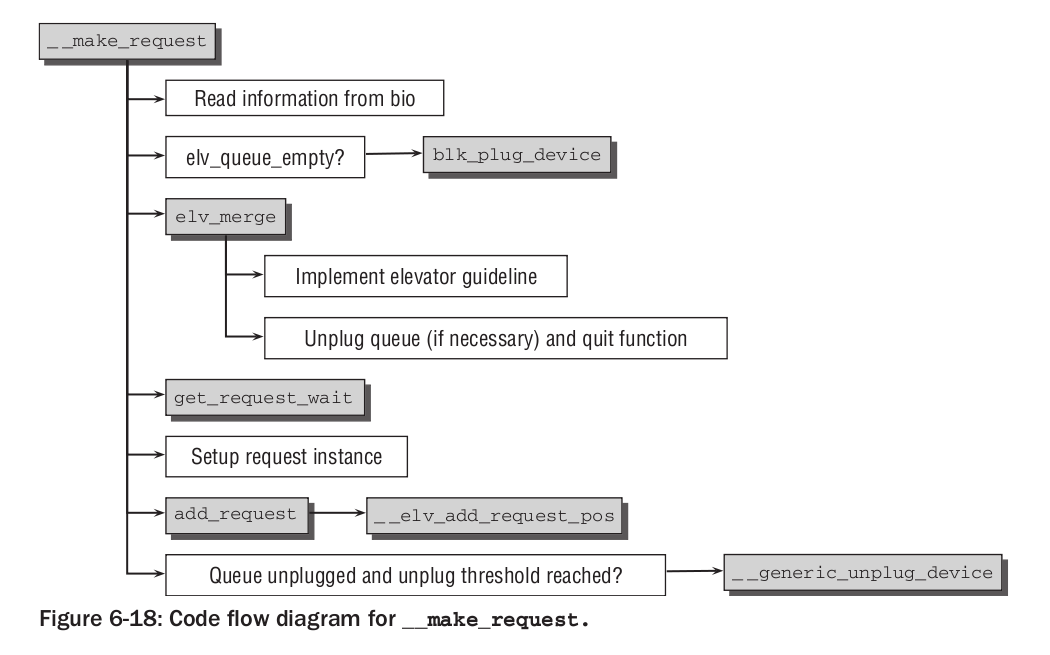
Wyjaśnijmy co robią poszczególne wywołania:
Reasumując, proces obsługi żądania przebiega następująco:
W rzeczywistości warstwa blokowa działa asynchronicznie i jest sterowana przerwaniami sprzętowymi sterowników urządzeń. Ważnym pojęciem jest plugging. Plug to po prostu blokada na kolejce. Usunięcie jej uruchamia proces przetwarzania kolejki. Plug usuwany jest dopiero wtedy, gdy jakiś proces rzeczywiście czeka na zakończenie wejścia-wyjścia. Dlatego też powyższy przepływ żądania miałby prawo - teoretycznie - zająć dowolnie długi czas. By temu zapobiec, z każdą kolejką związany jest timer, który zapewnia periodyczne wykonywanie unplug.
Dzięki nowej architekturze warstwy blokowej możliwe stało się wygodne podmienianie schedulerów i dostrajanie ich per-urządzenie. By to osiągnąć, wyekstrahowano prosty interfejs, którym scheduler komunikuje się z warstwą blokową. Ponieważ sterowniki również komunikują się z systemem przez warstwą blokową, pisanie sterownika nie wymaga znajomości żadnego schedulera - dobrze napisany sterownik powinien działać z każdym.
Oto fragment interfejsu elevatora (funkcje te wchodzą w skład struktury struct elevator_ops):
/* funkcja wywolywana, by obliczyc wszystkie żądania, ktore mozna polaczyc z podanym bio */
typedef int (elevator_merge_fn) (struct request_queue *, struct request **, struct bio *);
/* funkcja wywolywana, gdy podane żądania zostaja polaczone */
typedef void (elevator_merge_req_fn) (struct request_queue *, struct request *, struct request *);
/* funkcja wywolana dla kazdego żądania, ktore bralo udzial w polaczeniu */
typedef void (elevator_merged_fn) (struct request_queue *, struct request *, int);
/* funkcja, ktora wywolana jest przed wlaczeniem bio w żądaniu. tutaj scheduler moze zaprotestowac */
typedef int (elevator_allow_merge_fn) (struct request_queue *, struct request *, struct bio *);
/* funkcja sluzaca do wypelnienia kolejki gotowymi żądaniami. to od schedulera zalezy, ktore żądania do niej trafia */
typedef int (elevator_dispatch_fn) (struct request_queue *, int);
typedef void (elevator_add_req_fn) (struct request_queue *, struct request *);
/* prosi scheduler o odpowiedź, czy kolejka jest pusta */
typedef int (elevator_queue_empty_fn) (struct request_queue *);
/* wywolana po zakończeniu obsługi żądania */
typedef void (elevator_completed_req_fn) (struct request_queue *, struct request *);
/* ponizsze 2 funkcje kaza schedulerowi wykonac alokacje/dealokacje wewnetrznych struktur na żądanie */
typedef int (elevator_set_req_fn) (struct request_queue *, struct request *, gfp_t);
typedef void (elevator_put_req_fn) (struct request *);
/* ponizsze 2 funkcje informuja scheduler o wejściu-wyjściu żądania do/z sterownika urzadzenia */
typedef void (elevator_activate_req_fn) (struct request_queue *, struct request *);
typedef void (elevator_deactivate_req_fn) (struct request_queue *, struct request *);
/* inicjalizacja i wylaczanie schedulera */
typedef void *(elevator_init_fn) (struct request_queue *);
typedef void (elevator_exit_fn) (struct elevator_queue *);
Warstwa blokowa zapewnia, że na każdym żądaniu powyższe funkcje wykonane zostaną w następującej kolejności:
| Janina Mincer-Daszkiewicz |