Strategie szeregowania żądań wejścia-wyjścia stosuje się przy dostępie do urządzeń blokowych, w szczególności twardych dysków. Wynika to głównie z długiego czasu przeszukiwania, a więc czasu potrzebnego głowicy do przesunięcia się nad właściwą ścieżkę. Gdyby więc nie było żadnej strategii szeregowania żądań, głowica mogłaby wykonywać dużo ruchów na które traciłaby dużo czasu. Tak więc do zadań modułu szeregującego (I/O scheduler) należą:
Porównam następujące strategie:
Najprostszy możliwy algorytm szeregowania. Nie ma uporządkowanej kolejki, nowe żądania zawsze są dodawane na początku lub na końcu dispatch queue, a następnym obsługiwanym żądaniem jest pierwsze żądanie z kolejki.
Według RedHat: The noop scheduler is suitable for devices where there are no performance penalties for seeks. Examples of such devices are ones that use flash memory. noop can also be suitable on some system setups where I/O performance is optimized at the block device level, with either an intelligent host bus adapter, or a controller attached externally.
To najbardzie wyrafinowany algorytm szeregowania. Jest rozwinięciem algorytmu Deadline. Tutaj też utrzymuje się cztery kolejki. Moduł szeregujący przegląda kolejki posortowane, przełączając się pomiędzy żądaniami czytania i pisania, lecz faworyzując żądania czytania. Przeglądanie jest zasadniczo sekwencyjne, chyba, że dla żądania upływa termin. Dla żądań czytania termin upływa po - domyślnie - 125 milisekundach, a dla żądań pisania po 250 milisekundach. Stosowane są dodatkowe heurystyki:
W pewnych przypadkach algorytm może wybrać żądanie poza bieżącą pozycją w kolejce posortowanej, wymuszając zmianę ruchu głowicy. Zwykle ma to miejsce, gdy odległość żądania w przeciwnym kierunku jest mniejsza niż połowa odległości żądania za bieżącą pozycją w kolejce posortowanej.
Algorytm zbiera statystyki o wzorcu zachowań operacji wejścia-wyjścia dla każdego procesu w systemie. Po wybraniu żądania czytania pochodzącego od procesu P, sprawdzane jest czy następne żądanie w kolejce posortowanej pochodzi od tego samego procesu. Jeśli tak, to natychmiast jest wybierane następne żądanie. Wpp sprawdza się zebrane statystyki na temat procesu P, jeśli wynika z nich, że proces P wkrótce wygeneruje następne żądanie czytania, to zamiera na krótki okres czasu (domyślnie 7 milisekund). Zatem algorytm może przewidzieć żądanie czytania pochodzące od procesu P położone blisko na dysku względem ostatnio wybranego żądania.
Algorytm nadal dobrze obsługuje żądania czytania, ale ma szansę zapewnić lepszą globalną przepustowość.
Według RedHat: This algorithm is intended to optimize systems with small or slow disk subsystems. One artifact of using the AS scheduler can be higher I/O latency caused by numerous enforced delays. For the most part, the anticipatory scheduler performs well on most personal workstations, but very poorly for server-type workloads.
W tym algorytmie oprócz dispatch queue korzysta się z czterech dodatkowych kolejek. Dwie z nich - posortowane zgodnie z numerami sektorów - zawierają, odpowiednio, żądania czytania i pisania. Dwie pozostałe - deadline - zawierają te same żądania czytania i pisania, ale posortowane zgodnie z ich deadlinem (czyli budowane zgodnie z porządkiem FIFO). Ich zadaniem jest przeciwdziałanie zagłodzeniu żądań. Dla żądania czytania termin upływa (ang. expires) domyślnie po 500 milisekundach, a dla żądania pisania po 5 sekundach. Żądania czytania są uprzywilejowane, gdyż zwykle powodują blokowanie procesów, od których pochodzą.
W chwili gdy powinno się wypełnić ponownie dispatch queue, najpierw sprawdza się typ kolejnego żądania. Jeśli są dostępne zarówno żądania czytania, jak i pisania, to wybierane jest 'czytanie', o ile kierunek 'pisanie' nie był pomijany zbyt wiele razy.
Nastepnie sprawdzana jest kolejka deadline dla wybranego typu żądania. Jeśli dla pierwszego żądania w kolejce już upłynął termin, to żądanie jest przesuwane na koniec dispatch queue. Przenosi także do dispatch queue żądania z kolejki posortowanych, począwszy od żądania następującego po żądaniu, dla którego upłynął termin. Liczba przenoszonych żądań jest większa, gdy żądania są położone na dysku blisko siebie i krótsza w przeciwnym przypadku.
Jeśli dla żadnego żądania nie upłynął termin, to do dispatch queue są pobierane żądania z kolejki posortowanych począwszy od żądania następnego za ostatnio wziętym z tej kolejki. Po dojściu do końca kolejki, poszukiwanie jest rozpoczynane od jej początku.
Algorytm zmniejsza opóźnienia dla żądań czytania, ale robi to kosztem globalnej przepustowości.
Według RedHat: The deadline scheduler aims to keep latency low, which is ideal for real-time workloads.
Głównym celem algorytmu CFQ jest zapewnienie sprawiedliwego podziału przepustowości wejścia-wyjścia pomiędzy procesy generujące żądania. Aby osiągnąć ten cel w algorytmie wykorzystuje się dużą liczbę posortowanych kolejek (domyślnie 64), w których przechowywane są żądanią pochodzące od różnych procesów. Gdy dociera nowe żądanie jest wywoływana funkcja mieszająca, która przekształca identyfikator grupy wątków procesu (zwykle jest to PID) w indeks w kolejce. Następnie nowe żądanie jest wstawiane na koniec tej kolejki. Zatem żądania pochodzące od tego samego procesu zawsze trafiają do tej samej kolejki. Wypełnianie dispatch queue polega na tym, że kolejki są przeglądane w kolejności round-robin i zawartość niepustych kolejek jest przesuwana na koniec dispatch queue.
Według RedHat: CFQ is well suited for most medium to large multi-processor systems and for systems which require balanced I/O performance over multiple Logical Unit Numbers and I/O controllers.
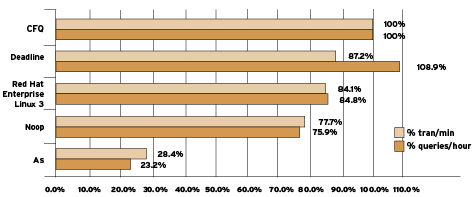
Porównanie chciałbym zacząć od przyjrzenia się zachowaniu poszczególnych strategii przy obciążeniu bazą danych Oracle.
Zostały wykonane 2 zestawy testów, jeden dla OLTP (Online Transaction Processing) - odczytów było mniej więcej tyle samo co zapisów; drugi dla DSS (Decision Support System). Maszyna posiadała 8 dysków połączonych w zestaw RAID.
Wydajność została zmierzona w transakcjach na minutę (OLTP) oraz w liczbie zapytań bazy w ciągu godziny (DSS).
Jako bazową wydajność przyjęto tę przy użyciu strategii CFQ, gdyż (zdaniem autorów RedHat) jest to strategia najlepsza dla znacznej części zastosowań.
Jak widać, do zastosowań bazodanowych najgorsza jest strategia AS. Sprawdza się ona za to dobrze w komputerach stacjonarnych, z pojedynczym, ewentualnie dwoma dyskami.
Zasadniczo używa się jej tam, gdzie czas oczekiwania jest ważniejszy niż całościowa przepustowość.
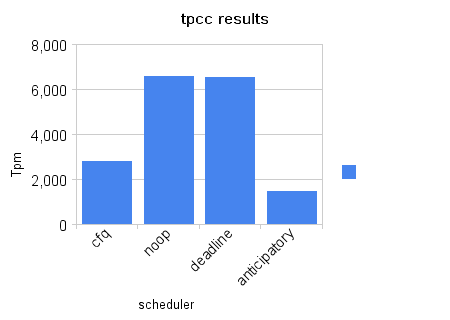
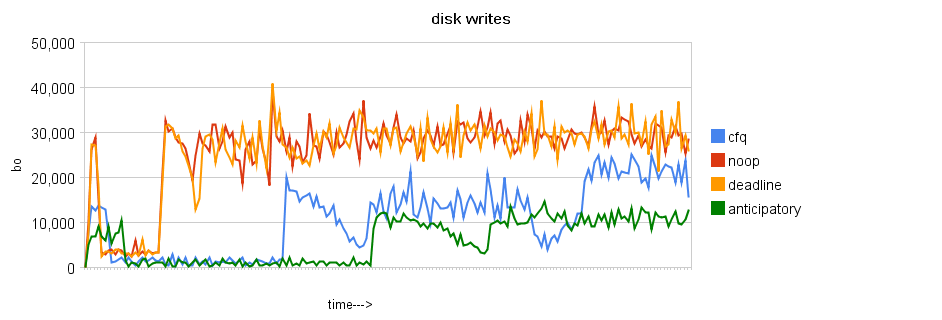
Warto porównać wyniki dla bazy Oracle z wynikami dla MySQL. Tutaj również wydajność została zmierzona za pomocą liczby transakcji w ciągu minuty, jednak wyniki są zupełnie inne. Okazuje się, że chętnie używany CFQ zupełnie się nie sprawdza przy MySQL. Za to dobre wyniki są osiągane przy użyciu algorytmu Noop.
Interesujące są też wyniki porównania strategii dla dysków SSD (Solid State Disk) - opartych o flash. W tych dyskach mamy swobodny dostęp do danych, zatem trud zmniejszenia czasu przeszukiwania jest niepotrzebny.
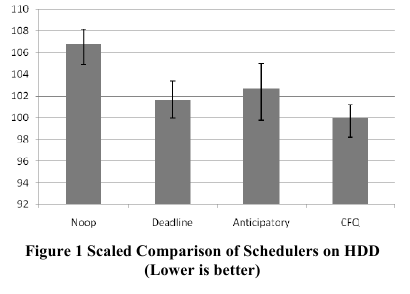
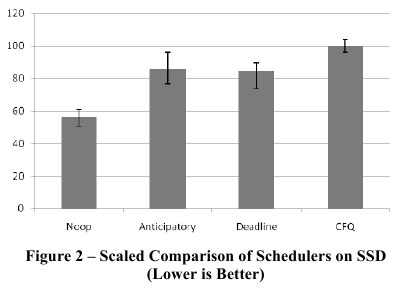
Wykonany test wydajności polegał na mierzeniu czasu potrzebnego na skopiowanie dużego pliku (700MB).
root@ajfin:~/studia/ZSO/prezentacja$ cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
root@ajfin:~/studia/ZSO/prezentacja$ time cp bigfile bigfile2
real 0m33.003s
user 0m0.008s
sys 0m4.000s
root@ajfin:~/studia/ZSO/prezentacja$ echo noop > /sys/block/sda/queue/scheduler
root@ajfin:~/studia/ZSO/prezentacja$ rm bigfile2
root@ajfin:~/studia/ZSO/prezentacja$ time cp bigfile bigfile2
real 0m32.028s
user 0m0.036s
sys 0m4.108s
root@ajfin:~/studia/ZSO/prezentacja$ time cp bigfile bigfile2
real 1m14.346s
user 0m0.040s
sys 0m3.716s
root@ajfin:~/studia/ZSO/prezentacja$ echo cfq > /sys/block/sda/queue/scheduler
root@ajfin:~/studia/ZSO/prezentacja$ rm bigfile2
root@ajfin:~/studia/ZSO/prezentacja$ time cp bigfile bigfile2
real 1m0.297s
user 0m0.036s
sys 0m3.616s
root@ajfin:~/studia/ZSO/prezentacja$ echo anticipatory > /sys/block/sda/queue/scheduler
root@ajfin:~/studia/ZSO/prezentacja$ rm bigfile2
root@ajfin:~/studia/ZSO/prezentacja$ time cp bigfile bigfile2
real 0m49.175s
user 0m0.008s
sys 0m3.588s
Z powyższego zestawienia wynika, że o żadnej ze strategii szeregowania wejścia-wyjścia nie można powiedzieć, że jest najlepsza. Nawet tak prosta strategia jak Noop okazuje się najlepsza w niektórych przypadkach. Jeśli więc komuś naprawdę zależy na wydajności operacji dyskowych, to powinien sam zrobić testy z typowym dla danego przypadku obciążeniem.