Jest to metoda zapisu i odczytu, która wykonuje sekwencyjny zapis do wielu buforów pamięci lub odczyt z wielu buforów pamięci przy pomocy jednego wywołania funkcji. Ten sposób zapisu i odczytu jest też zwany wektorowemym wejściem-wyjściem (vectored I/O), gdyż do funkcji zamiast standardowego pojedynczego bufora przekazywany jest wektor danych. (na podstawie: http://en.wikipedia.org/wiki/Vectored_I/O)
Podstawową różnicą jest to, że funkcje ReadFileScatter i WriteFileGather są asynchroniczne, a readv i writev - synchroniczne.
Ponieważ coraz częściej stosowano wektorowe wersje funkcji wczytujących lub zapisujących dane nawet wtedy, gdy wykonywana jest tylko jedna operacja read, zaczęto zastanawiać się czy nie byłoby dobrze umożliwić korzystanie z wektorowych operacji także asynchronicznie. Aby iść w kierunku ujednolicania API dostępu do danych, w jądrze w wersji 2.6.19 zostały zmienione deklaracje asynchronicznych operacji na plikach, czyli aio_read i aio_write.
Wersja z 2.6.18.8 i wcześniejszych:
ssize_t (*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);Wersja z 2.6.19:
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
Podobnie zmieniono deklaracje funkcji generic_file_aio_read, generic_file_aio_write i podobnych, które zapewniają standardowy, domyślny asynchroniczny odczyt i zapis danych.
Do testowania wydajności wektorowego wejścia/wyjścia użyłem napisanego przez siebie programu: scatter_gather.c
czy_vectored: 0
SIZE: 1024
COUNT: 1000
REPEATS: 10
Średni czas zapisu: 50 ms 494 us (19.0732 MB/s)
Średni czas odczytu: 1 ms 170 us (834.4648 MB/s)
czy_vectored: 1
SIZE: 1024
COUNT: 1000
REPEATS: 10
Średni czas zapisu: 10 ms 189 us (95.3672 MB/s)
Średni czas odczytu: 0 ms 842 us (1159.6680 MB/s)
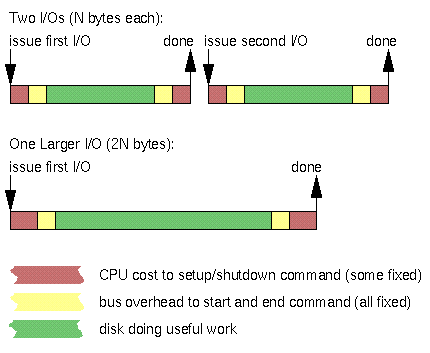
Przy małym rozmiarze pojedynczego bufora liczba wywołań systemowych ma duże znaczenie, stąd 5-krotnie większa prędkość zapisu dla zapisu wektorowego. Oczywiście, patrząc na prędkości odczytu danych, widać, że dane są buforowane przez system operacyjny, dlatego nie biorę pod uwagę czasu oczekiwania na dysk twardy (na podjazd głowicy itp.). Fakt buforowania danych przez system operacyjny potwierdza fakt, iż (mimo użycia funkcji fsync()) wykres pracy dysku w Monitorze systemu nie wykazał dużej liczby odczytów i zapisów danych w momencie działania programu, a jedynie kilkanaście sekund później.
czy_vectored: 0
SIZE: 102400
COUNT: 10
REPEATS: 10
Średni czas zapisu: 9 ms 852 us (98.2275 MB/s)
Średni czas odczytu: 0 ms 709 us (1377.1055 MB/s)
czy_vectored: 1
SIZE: 102400
COUNT: 10
REPEATS: 10
Średni czas zapisu: 10 ms 412 us (93.4600 MB/s)
Średni czas odczytu: 0 ms 699 us (1396.1787 MB/s)
W przypadku większego rozmiaru pojedynczego bufora, liczba wywołań systemowych nie gra aż takiej roli. Okazuje się, że wtedy używanie wektorowych wersji funkcji spowalnia operacje wejścia-wyjścia tak bardzo, że wyniki wersji wektorowej i zwykłej mogą być podobne, a nawet wersja wektorowa może być wolniejsza!
Dzieje się tak dlatego, że zysk z mniejszej liczby wywołań systemowych jest niwelowany przez inicjowanie struktur opisujących bufory wywoływane przed każdą operację readv/writev.
Przeniesienie bloku:
for (j = 0; j < COUNT; ++j) {
iov[j].iov_base = strings[czy_odczyt][j];
iov[j].iov_len = SIZE;
}
poza blok, w którym jest mierzony czas wykonania, sprawiło, że wektorowe operacje znowu okazały się szybsze (ale tylko trochę):
czy_vectored: 0
SIZE: 102400
COUNT: 10
REPEATS: 10
Średni czas zapisu: 10 ms 552 us (92.5059 MB/s)
Średni czas odczytu: 0 ms 715 us (1365.6611 MB/s)
czy_vectored: 1
SIZE: 102400
COUNT: 10
REPEATS: 10
Średni czas zapisu: 9 ms 613 us (101.0889 MB/s)
Średni czas odczytu: 0 ms 695 us (1404.7617 MB/s)
Z powyższych przykładów wynika, że z całą pewnością przy buforach rzędu kilku kilobajtów używanie operacji wektorowych opłaca się zawsze, natomiast przy większych buforach, należy brać pod uwagę optymalizację inicjowania struktur buforów. W praktyce wielkość buforów oraz ich położenie często jest stałe, a więc ustawienie odpowiednich danych do struktur iovec można przeprowadzić jednorazowo w ciągu działania programu.
| Janina Mincer-Daszkiewicz |