1. Cechy ogólne
Andrew S. Tannenbaum na początku lat 80. XX wieku zaprojektował i stworzył od zera system plików na potrzeby swojego systemu operacyjnego i nazwał go MINIX file system. System ten jest tak zaprojektowany, żeby uniknąć skomplikowanych struktur danych i funkcjonalności, które utrudnią proces nauki systemów operacyjnych, a jednocześnie działają. Gdy Linux Torwalds zaczynał prace nad Linuxem (1991) pracował na komputerze z Minixem i zaadoptował ten system plików. Wkrótce jednak okazało się to bardzo problematyczne, więc powstał extended file system, który jednak szybko został wyparty przez swoja drugą wersję, znaną jako ext2. Od tego momentu MFS jest używany niezwykle rzadko. Następcami systemu plików ext2 są ext3 i ext4. O systemie plików ext2 warto zapamiętać:
- Podczas tworzenia systemu administrator może wybrać optymalny rozmiar bloku (w zakresie od 1 KiB do 4 KiB), zależnie od spodziewanego średniego rozmiaru pliku.
- Podczas tworzenia systemu administrator może ustalić liczbę i-węzłów dla partycji określonego rozmiaru, zależnie od spodziewanej liczby plików.
- Bloki dyskowe są dzielone na grupy obejmujące sąsiadujące ze sobą ścieżki, dzięki czemu odczyt pliku położonego w ramach pojedynczej grupy wiąże się z krótkim czasem przesuwu głowicy.
- System plików alokuje wstępnie bloki dyskowe dla zwykłych plików, zatem gdy plik rośnie, są już dla niego zarezerwowane bloki w fizycznie spójnych obszarach, co zmniejsza fragmentację pliku.
- System wspiera dowiązania symboliczne (ang. symbolic link). Jeśli takie dowiązanie reprezentuje krótką nazwę ścieżkową (mniej niż 60 znaków), to umieszcza się go w i-węźle, dzięki czemu tłumaczenie nazwy nie wymaga czytania bloku danych.
Dzięki dobrej i przemyślanej implementacji ext2 jest stabilny i elastyczny. Podjęte decyzje projektowe minimalizują ryzyko błędu przy awarii systemu, np. przy tworzeniu dowiązań twardych (ang. hard link) najpierw jest zwiększany licznik dowiązań w i-węźle dyskowym, a dopiero później nowa nazwa jest dodawana do właściwego katalogu. System zapewnia wsparcie dla automatycznej kontroli spójności podczas ładowania.
Źródła systemu plików ext2 w naszym obrazie Minixa znajdują się w katalogu /usr/src/minix/fs/ext2.
Natomiast źródła MFS są w katalogu /usr/src/minix/fs/mfs.
2. Modyfikowanie, kompilowanie i instalowanie
Po dokonaniu zmian w systemie plików nie trzeba kompilować całego jądra.
Wystarczy wejść do katalogu z systemem plików, wykonać polecenie
make, następnie zainstalować zmiany poleceniem make install i
zrestartować Minixa.
3. Ćwiczenia
Aby szybciej zrozumieć, jak działa system plików, proponujemy przeprowadzenie tych zajęć w formie ćwiczeń. Podobne zadania pojawiają się co roku na pisemnym egzaminie licencjackim.
A. Systemowa tablica otwartych plików
Związek między procesem a systemem plików opisany jest przez dwa pola w strukturze danych procesu (task_struct):
struct fs_struct *fszawiera informacje o systemie plików,struct files_struct *fileszawiera informacje o otwartych przez proces plikach.
W strukturze files_struct znajduje się tablica indeksowana liczbami naturalnymi, które odpowiadają deskryptorom otwartych plików. Wartościami poszczególnych pozycji w tej tablicy są dowiązania do systemowej tablicy otwartych plików.
Każde zakończone powodzeniem wywołanie funkcji open() powoduje utworzenie nowej pozycji w systemowej tablicy otwartych plików. Natomiast wywołania funkcji dup() i fork() powoduje, że do jednej pozycji mogą odnosić się różne deskryptory. Pozycja w systemowej tablicy otwartych plików jest opisana przez strukturę file. Pole f_count tej struktury odpowiada liczbie dowiązań do danej pozycji.
I-węzeł pliku
I-węzeł każdego otwartego pliku znajduje się w pamięci operacyjnej. Dla każdego pliku jest tylko jedna kopia i-węzła w pamięci niezależnie od tego, ile razy dany plik był otwierany. Pole i_count w i-węźle informuje, ile razy dla danego pliku wykonano funkcję open().
Uwaga: przedstawiony tutaj opis jest oczywiście niepełny. Zawiera tylko wyrywkowe informacje pomocne przy wykonywaniu poniższych zadań.
Zadanie A.1
Załóżmy, że pewien proces, który nie tworzył procesów potomnych, korzysta z n otwartych plików przy czym wszystkie one są różne (odpowiadają im różne i-węzły). Załóżmy również, że ten proces jest jedynym procesem w systemie mającym otwarte pliki. Czy jest możliwa sytuacja, w której liczba deskryptorów otwartych plików dla tego procesu jest:
- mniejsza ostro od n?
- większa ostro od n?
Jeśli taka sytuacja jest możliwa, to kiedy może wystąpić? Opisz, jak można taką sytuację wykryć, znając jedynie zbiór struktur typu file dla danego procesu, a nie wiedząc nic o liczbie deskryptorów plików otwartych przez ten proces.
Zadanie A.2
Proces P działa według następującego schematu (sześcioelementowa tablica plik zawiera nazwy ścieżkowe plików):
fd = open(plik[0], ...);
for (int i = 1; i ≤ 5; ++i)
{
if (!fork()) break;
fd = open(plik[i], ...);
}
Jak będą wyglądały tablice deskryptorów plików procesu P i jego potomków?
Jak będzie wyglądała systemowa tablica otwartych plików (jakie wartości będą miały pola f_count)?
B. Struktura partycji w systemach plików ext2, ext3, ext4
W omawianych systemach plików pierwszy blok partycji jest zarezerwowany dla sektora startowego. Reszta partycji jest podzielona na grupy bloków tego samego rozmiaru o ustalonej strukturze. Liczba grup zależy od rozmiaru partycji i od wielkości bloku. Głównym ograniczeniem jest to, że mapa bitowa opisująca stan zajętości bloków wewnątrz grupy musi zmieścić się w jednym bloku.
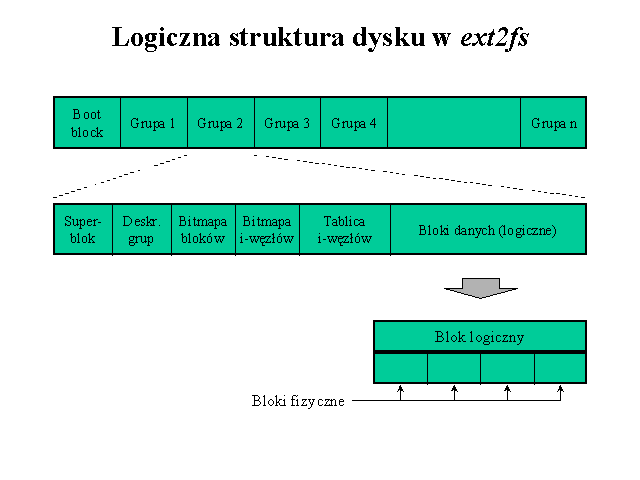
Jak widać na rysunku, również mapa bitowa opisująca zajętość i-węzłów oraz superblok zajmują po jednym bloku. Pozostałe struktury są zmiennej długości.
Superblok zawiera informacje o całym systemie plików (m.in. rozmiar bloku, łączną liczbę bloków i i-węzłów, łączną liczbę wolnych bloków i i-węzłów). Deskryptor grupy przechowuje podstawowe informacje dotyczące grupy, takie jak liczbę wolnych bloków oraz i-węzłów w danej grupie, numery bloków map bitowych i numer pierwszego bloku tablicy i-węzłów.
Tablica i-węzłów to zbiór bloków, w ramach których przydzielane są i-węzły. Ich liczba jest ustalana podczas tworzenia systemu plików.
Różnice w strukturze partycji pomiędzy kolejnymi wersjami systemu plików od ext2 do ext4 są niewielkie. W oryginalnej wersji systemu ext2 kopia superbloku oraz deskryptory grup znajdowały się w każdej grupie (redundancja miała na celu zabezpieczenie danych przed awarią). W nowszych wersjach wprowadzono możliwość pominięcia kopii w niektórych grupach. Kopie superbloku i deskryptorów grup znajdują się wtedy w grupach o numerach 0, 1 oraz będących potęgą 3, 5 lub 7.
Zauważmy, że dla bardzo dużych partycji taki sposób organizacji staje się nieefektywny, ponieważ zbyt wiele miejsca jest przeznaczone na (redundantne) metadane. Chodzi tutaj przede wszystkim o deskryptory grup, których liczba rośnie wraz z rozmiarem partycji. Dlatego w późniejszych wersjach systemu (ext3 i ext4) wprowadzono tak zwane metagrupy. Metagrupa jest zbiorem grup, o tak dobranym rozmiarze, aby deskryptory grup w obrębie jednej metagrupy mieściły się w pojedynczym bloku dyskowym. Deskryptory grup danej metagrupy są przechowywane w jej pierwszej grupie i dodatkowo w drugiej i ostatniej.
Zadanie B.1
Dla partycji ext2 o wielkości 4 GiB rozmiar bloku został ustalony na 4 KiB. Załóżmy, że rozmiar deskryptora grupy wynosi 48 B, rozmiar i-węzła na dysku wynosi 128 B, a na grupę przypada 4096 i-węzłów.
- Jaki jest rozmiar mapy bitowej zajętości bloków?
- Ile bloków z danymi będzie zawierać każda z grup?
- Jaki jest rozmiar danych przechowywanych w jednej grupie bloków?
- Ile grup bloków zostanie utworzonych?
- Jaki jest koszt obsługi danych, tzn. ile procent przestrzeni dyskowej zostanie zużyte na metadane?
Zadanie B.2
Załóżmy, że w pewnym systemie plików ext2:
- i-węzeł zajmuje 128 B,
- deskryptor grupy zajmuje 32 B,
- blok na dysku ma rozmiar 4 KiB,
- partycja dyskowa ma rozmiar 8 GiB.
Jak należy skonfigurować system plików na tej partycji, żeby metadane nie zajęły więcej niż 2% partycji?
Opisz szczegółowo, ile będzie grup dyskowych, ile bloków zajmie jedna grupa, co będzie się znajdowało w kolejnych blokach dyskowych partycji, jakie metadane będą przechowywane w kolejnych (ilu) blokach, ile bloków będzie przypadało średnio na jeden plik. Blok startowy można zaniedbać w rozważaniach.
Zadanie B.3
- Załóżmy, że blok na dysku ma rozmiar 1024 B. Jaki rozmiar ma grupa?
- Załóżmy, że grupa bloków ma rozmiar 128 MiB. Ile wynosi rozmiar bloku na dysku?
- Załóżmy, że blok na dysku ma rozmiar 1024 B. Grup na dysku jest dokładnie 400. Deskryptor grupy zajmuje 24 B. Który bit w mapie bitowej zajętości bloków w grupie zawierającej wszystkie deskryptory grup odpowiada blokowi zawierającemu tę mapę?
- Dlaczego funkcja kontrolująca spójność mapy bitowej dla każdej z tych map zakończy się błędem?
0111 1111 1101 1010 0110 ... 1011 0000 0000 0000 0000 ... 1101 1111 1111 1111 1111 ...
Zadanie B.4
Jaki jest maksymalny rozmiar partycji dla systemu plików, w którym pierwsza grupa przechowuje wszystkie deskryptory grup danej partycji. Przyjmijmy, że deskryptor grupy ma rozmiar 64 B, a blok dyskowy – 4 KiB. Jaki byłby w takiej sytuacji rozmiar metagrupy?
C. Operacje na plikach
I-węzeł pliku w systemach ext2 i ext3 zawiera numery pierwszych 12 bloków z danymi oraz numery jednego bloku pośredniego, jednego bloku podwójnie pośredniego i jednego bloku potrójnie pośredniego (tablica i-block).
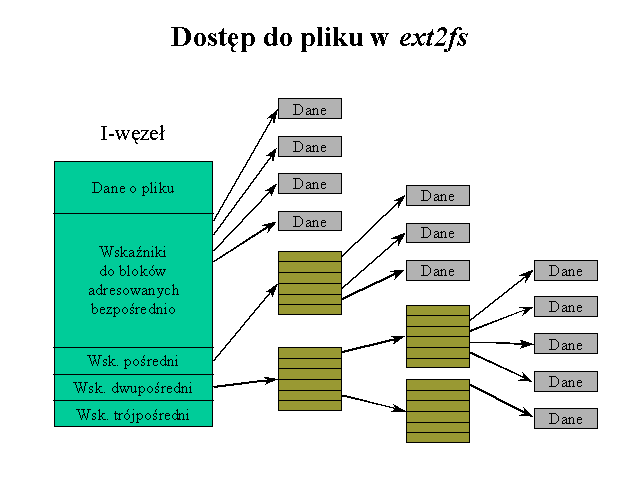
Zadanie C.1
Plik o rozmiarze logicznym 15000 B został umieszczony na partycji, dla której rozmiar bloku ustalono na 1 KiB.
Policz ile operacji dyskowych wymaga
- wczytanie,
- zapisanie
fragmentu pliku o wielkości 1000 B (uwaga: nie 1 KiB) położonego
- począwszy od adresu logicznego 6000,
- począwszy od adresu logicznego 14000.
W obu przypadkach plik jest otwarty, ale żaden blok danych nie został jeszcze sprowadzony do pamięci. W pamięci znajduje się jedynie i-węzeł pliku. Możemy założyć, że wszystkie bloki pliku są zapisane (plik nie jest dziurawy).
Jak zmienią się odpowiedzi bez ostatniego założenia?
W jakiej sytuacji uzyskamy najmniejszą liczbę operacji dyskowych?
Zadanie C.2
Załóżmy, że rozmiar bloku w systemie plików ext3 został ustalony na 1 KiB. Ile maksymalnie, a ile minimalnie bloków dyskowych może być potrzebne do zapamiętania pliku o rozmiarze 2 GiB?
Wskazówka: pliki mogą być rozrzedzone (dziurawe).
Zadanie C.3
Gdy rozmiar pliku w i-węźle systemu ext2 był opisywany liczbą 32-bitową i jej najstarszy bit był zarezerwowany, plik mógł mieć wielkość co najwyżej 2 GiB. We współczesnych systemach ext2 i ext3 32-bitowe pole i-węzła o nazwie i-blocks przechowuje rozmiar pliku wyrażony w liczbie 512 bajtowych porcji. Rozmiar bloków na dysku zależy od konfiguracji. Dopuszczalne są bloki o wielkości 512 B, 1 KiB, 2 KiB, 4 KiB, a nawet 8 KiB (o ile architektura na to pozwala). Numery bloków fizycznych są 32-bitowe.
Wiedząc to wszystko i biorąc pod uwagę sposób adresowania bloków, uzupełnij poniższą tabelkę dla systemów ext2 i ext3:
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KiB | ||
| 2 KiB | ||
| 4 KiB | ||
| 8 KiB |
D. System plików ext4
Nasuwa się wniosek, że system plików ext3 dochodzi do granic swoich możliwości. Maksymalna wielkość partycji, czyli 16 TiB (ew. 32 TiB) jest już często przekraczana (np. w macierzach RAID), a ze względu na 32-bitowe numery bloków dyskowych więcej osiągnąć się nie da. Od 2006 roku trwały prace nad dwoma zasadniczymi zmianami, które pojawiły się w ext4, a także dostępnymi w ext3 w postaci łat.
Pierwsza i najważniejsza zmiana polega na zwiększeniu wielkości numeru bloku do 48 bitów, a druga – na zamianie mechanizmu pośredniego adresowania bloków na tzw. ekstenty (ang. extent), czyli ciągłe zbiory (zakresy) bloków danych.
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
Pojedynczy ekstent opisuje:
- 32-bitowy numer bloku logicznego pliku, będącego początkiem zakresu,
- 15-bitową długość zakresu (najstarszy bit służy do określenia, czy zestaw jest zapisany, czy nie),
- 48-bitowy numer bloku na dysku, będący początkiem zakresu na dysku.
W strukturze i-węzła tablica i-block, która w systemach ext2 i ext3 jest wykorzystywana do zapisywania numerów bloków, w ext4 służy do zapisania czterech ekstentów i jednego nagłówka ekstentu. W przypadku dużych plików system ext4 tworzy drzewo ekstentów. Dodatkowa struktura indeks ekstentu zawiera pozycję początkową ekstentu w pliku i numer bloku na dysku. Mechanizm ekstentów jest obecny także w innych popularnych systemach plików m.in. w XFS, JFS, Reiser4, a nawet w NTFS.
Zadanie D.1
Wiedząc, że w systemie ext4 numery logiczne bloków są 32-bitowe, a numery fizyczne bloków są 48-bitowe, wypełnij tabelkę jak w zadaniu 3 dla rozmiaru bloku 1, 2 i 4 KiB.
Zadanie D.2
Ustalmy, że rozmiar bloku wynosi 4 KiB. Porównaj, ile bloków dyskowych jest potrzebne do zapamiętania pełnego pliku (bez dziur) o rozmiarze 512 MiB w systemach ext3 i ext4.