We wszystkich systemach operacyjnych kluczową sprawą jest odmierzanie upływającego czasu rzeczywistego - poczynając od opóźnień pozwalających rozpędzić się dyskowi twardemu, poprzez szybkość powtarzania przytrzymywanego klawisza, skończywszy na wyświetlaniu bieżącej godziny na ekranie i wygaszaniu ekranu po pewnym czasie nieużywania konsoli. Jest to zwykle realizowane przez mechanizm przerwań zegarowych - w 8-bitowych komputerach było to przerwanie wygaszania pionowego (VBLANK) wywoływane z częstotliwością 50Hz (60Hz w Ameryce). Współczesne komputery oferują nam szerszy wachlarz przerwań zegarowych - praktycznie na wszystkich modelach możliwe jest ustawienie specjalnego przerwania, które wykona się po dowolnym żądanych przez nas czasie, nawet dużo mniejszym niż częstotliwość przerwania VBLANK (0,02s), np. co 0,001s lub co 0,01s, jak to jest w Linuxie (zależy to od stałej HZ zazwyczaj równiej 100, tylko na alphie - 1000).
Linux jest systemem oferującym nawet na jednoprocesorowej maszynie wielozadaniowość (multitasking), czyli pozornie jednoczesne wykonywanie wielu programów. Jest to możliwe i przynosi zadowalające efekty, gdyż większość z tych zadań nie potrzebuje działać cały czas - są budzone do działania tylko w określonych sytuacjach zależnych od urządzeń wejścia/wyjścia (I/O). Jednak nawet wówczas gdy chętnych do pracy jest kilka zadań, trzeba każdemu z nich przydzielić procesor na pewien czas stosowny do ważności (priorytetu) zadania, co jest realizowanie przez procedury "schedulera" zawarte w pliku kernel/sched.c.
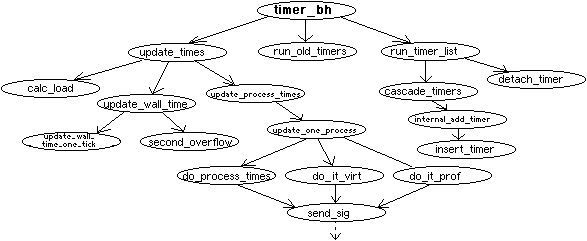
Gdy co każde 10ms wołane jest przerwanie zegarowe (szczegóły - funkcja timer_interrupt() w pliku arch/i386/kernel/time.c) woła do_timer(), która zwiększa czasowe liczniki systemowe: jiffies i lost_ticks, zaznacza "wolną" część procedury obsługi przerwania zegarowego tzw. bottom_half, wychodzi ze stanu przerwania i wywołuje ją. Wśród tych procedur jest timer_bh()i tqueue_bh(). Pierwsza z nich wykonuje kilka ważnych czynności, które wymienię w kolejności ich wywoływania:
Drzewo wywołań:
Podumowując: mamy dwie zmienne systemowe odmierzające czas:
Mamy też zmienne statystyczne:
- pola:
- zawiera niedokładne średnie liczby gotowych do wykonania procesów w ciągu ostatniej minuty, 5 minut i 15 minut (im później, tym większa waga) wyrażone w postaci stałoprzecinkowej (FSHIFT bitów precyzji); dane stąd można uzyskać procedurą systemową sysinfo(), wtedy będzie 16 bitów precyzji.
(ml)
Timerami (budzikami systemowymi) będę nazywał odwołanie do funkcji,
których wykonanie zostało odroczone do ściśle określonego czasu w przyszłości.
Są one wykorzystywane przez rozmaite drivery, funkcje obsługi sieci, a
także przez niektóre funkcje z katalogu kernel np.: schedule().
Struktury zawierające timery oraz funkcje je obsługujące znajdują się w
pliku sched.c. Jak one działają? Nie potrafię w sposób komunikatywny,
posługując się nazwami zniemmych występujących w programie opisać algorytmu,
posłużę się więc analogią. Ciekawych dokładnego zapisu algorytmu w C odsyłam
do lektury kodu sched.c.
Jak możemy uporządkować coś co mamy do wykonania w przyszłości? Możemy
na każdą "atomową" jednostkę czasu (np.: minutę, godzinę, dzień
czy, jak to ma miejsce w jądrze systemu, 1/100 s) przeznaczyć przegródkę,
jednak aby objąć "sensowną" (moje oszacowania mówią mi, że w
Linuxie oznacza to kilkaset lat od startu systemu - myślę, że to dużo nawet
jak pomyliłem się o rząd wielości - potem algorytm się "sypie")
przyszłość potrzebowalibyśmy ogromną tychże przegródek ilość. Moglibyśmy
też w jedną przegródkę włożyć wszystko co mamy do wykonania i w każdej
jednostce czasu sprawdzać całość naszych zobowiązań (co mogło być bardzo
czasochłonne). Jądro Linuxa implementuje inny (moim zdaniem sprytny) algorytm
zarządzania timerami, tak aby obsługa struktury danych nie była zbyt czasochłonna
ani zajmująca wiele pamięci.
Załóżmy, że planujesz swoje działania na przestrzeni roku z dokładnością
co do godziny, dysponując półką z przegródkami. Nie interesują cię działania
do których wykonania pozostało ci wiele czasu, nie masz ich pewnie zbyt
wiele, wszystkie więc nie dotyczące bieżącego miesiąca wkładasz do przegródek
tytułowanych nazwami miesięcy stosownymi do czasu przystąpienia do działania.
Z kolei zlecenia dotyczące bieżącego rozdzielasz na przegrodki z kolejnymi
tygodniami, zlecenia dotyczące bieżącego tygodnia rozdzielasz na kolejne
dni tygodnia, a obecny dzień na godziny. Masz wówczas bez żadnego szukania
dostęp do tego co zrobisz w tej godzinie i przez wszystkie pozostałe obecnego
dnia. Problem powstaje gdy skończy się dzień.
Przeanalizujmy jeszcze ogólniejszy przypadek - rozpoczyna się nowa godzina,
dzień, tydzień, ale nie miesiąc. Patrzysz wówczas na przegródkę następnego
tygodnia i przekładasz informacje o zleceniach do przegródek z dniami i
godzinami. Takie zarządzanie przyszłymi działaniami jest bardzo sprawne
(przy stosunkowo niewielkiej ilości przegródek - 12+5+7+24, i niewielkim
kosztem czasowym - przy co najwyżej czterech przełożeniach zlecenia z przegródki
do przegródki). Jedynym problemem który nam pozostał jest sprawne wkładanie
przychodzących zleceń do przegródek. Załóżmy, że jeśli coś leży w przegródce
dotyczącej godziny, która już minęła, to dotyczy przyszłego dnia. Przyjmijmy
podobne założenie wobec dni i tygodni itd. Wówczas z łatwością zdecydujemy,
w jaki rodzaj przegródek (miesiący, tygodni, dni, czy godzin) dane zlecenie
włożyć: jeśli pozostał nam mniej niż dzień to wkładamy zlecenie do przegródek
z godzinami, gdy więcej niż dzień a mniej niż tydzień to odpowiednia jest
jedna z przegródek reprezentująch dni itd. - stosując tą metodę rodzaj
przegródek jest w oczywisty i prosty do obliczenia sposób zależny od czasu
pozostałego do wykonania zlecenia. W końcu zauważmy, że w naszym systemie
zarządzania zleceniami odleglejsze niż o rok mogą być obsługiwane - po
prostu przebywają długo nie przekładane w przegródkach z miesiącami.
Linux oczywiście nie posługuje się naturalnymi, takimi jak godziny czy
dni, jednostkami czasu. W Linuxie podstawową jednostką czasu jest 1/100
sekundy (w zasadzie zależy ona od definicji stałej HZ w pliku
param.h), dla niej jednostką nadrzędną (tak jak w naszym modelu dla godziny
dzień) jest (28)*1/100 s, a kolejne jednostki nadrzędne to 26
razy jednostka podrzędna (to też w zasadzie zależy od definicji stałych).
Grupy przegródek odpowiadające poszczególnym jednostkiom czasowym (tak
jak w opisie powyżej przegródki odpowiadające dniom czy miesiącom) to tablice,
każda z dodatkowym indeksem opisującym "obecną" chwilę czasu
(tak jak w przedstawionym modelu odwoływałem sie do bieżącej godziny, dnia
etc. tak i w Linuxie indeksy takie zapewniają szybki, bezpośredni dostęp
do bieżącego czasu wyrażonego w odpowiednich jednostkach). W tych elementach
tablic z kolei mieszczą się kolejki timerów.
Zawarte w sched.c funkcje obsługujące
timery:
insert_timer() - funkcja
dodaje timer do tablicy vec na miejscu idx.
internal_add_timer()
- funkcja dodaje timer do struktury danych (wybiera tablice i miejse w
niej, do którego należy dany timer dodać).
add_timer() - funkcja robi
to samo co internal_add_timer()
uprzednio wyłączając przerwania.
detach_timer() - funkcja
odłącza dany timer z listy w ktorej sie tenże timer znajduje (proste bo
lista timerów jest dwukierunkowa).
del_timer() - funkcja robi
to samo co detach_timer()
wyłączjąc przerwania.
cascade_timers() -
funkcja ta jest wołana gdy nadchodzi czas uaktualnienia struktury (sytuacja
analogiczna do końca dnia czy końca dnia i tygodnia w przedstawionym powyżej
modelu algorytmu). Wybiera ona bieżącą listę z tablicy tv i na
nowo umieszcza w strukturze danych wszystkie elementy tej listy.
run_timer_list() -
funkcja ta obsługuje tyknięcia zegara uruchamiając funkcje "na które
nadszedł czas" oraz gdy nadchodzi właściwy czas woła cascade_timers()
(być może wiele razy gdy czas ten nadszedł dla wielu poziomów odmierzania
czasu).
(bk)
System udostępnia procesom użytkownika 3 niezależne zegary interwałowe
(ang. interval timers). Zegary te pojawiły się po raz pierwszy w
jądrze systemu 4.2BSD, następnie w Systemie V Release 4, gdzie zaimplementowano
je jako funkcje biblioteczne. W Linuxie zaimplementowane są w jądrze.
Omawiane funkcje to: setitimer()
oraz getitimer(). Dokładne
informacje na temat ich użycia Czytelnik znajdzie na odpowiedniej stronie
man.
Opisywane zegary mogą być ustawione na określony okresu czasu, po upływie którego proces otrzymuje sygnał. Działanie podobne jest do standardowej funkcji alarm(), ale zapewnia większą dokładność (alarm() działa z dokładnością do 1 sekundy, podczas gdy zegary interwałowe teoretycznie z dokładnością do mikrosekund. W praktyce jest to dużo mniej - w Linuxie zegar standardowo "tyka" co 10 milisekund, ponadto należy wziąć pod uwagę opóźnienia wynikające z szeregowania).
Dostępne rodzaje zegarów odliczających:
| ITIMER_REAL | Zegar działający w czasie rzeczywistym. Po upływie zadanego czasu do procesu wysyłany jest sygnał SIGALRM. |
| ITIMER_VIRUTAL | Zegar działający tylko podczas wykonywania się procesu poza jądrem, w trybie użytkownika. Po upływie zadanego czasu wysyłany jest sygnał SIGVTALRM. |
| ITIMER_PROF | Zegar działający tylko w czasie wykonywania procesu, zarówno w trybie użytkownika, jak i jądra. Wysyłany sygnał to SIGPROF. |
W strukturze task_struct opisującej każdy z procesów systemu, następujące pola odnoszą się do zegarów odliczających:
Implementacja funkcji getitimer(),
setitimer() znajduje się
w pliku kernel/itimer.c.
Funkcja związana z obsługą zegara ITIMER_REAL to it_real_fn().
Wywołanie ma miejsce w run_timer_list().
Funkcje dla zegarów ITIMER_VIRTUAL i ITIMER_PROF to odpowiednio:
do_it_virt() oraz do_it_prof(),
wywoływane z update_one_process().
Standardowa funkcja alarm() zrealizowana jest przy użyciu zegara ITIMER_REAL - unimożliwia to jednoczesne ich używanie. Ograniczenie to może dziwić - wystarczyłoby dodać dodatkowe pole typu struct timer_list. Jest to jednak uzasadnione tym, że w obu przypadkach wysyłany jest ten sam sygnał - nie byłoby możliwości stwierdzenia, z jakiego powodu taki sygnał nadszedł.
(gc)