Ścieżka wykonywania kodu rozpoczyna się od dobrze zdefiniowanego adresu (w pamięci ROM BIOS w PC) i przechodzi przez wiele rozgałęzień (skoków, wywołań funkcji, przerwań ... ). Odkąd wiadomo, gdzie następuje rozpoczęcie wykonywania programu, możliwa jest analiza kodu aż do pierwszego rozgałęzienia i umiejscowienie punktu przerwania tuż przed końcową instrukcją. Po wykonaniu tego fragmentu programu przerwanie to powoduje przekazanie sterowania monitorowi maszyny wirtualnej, który otrzymując kolejny adres instrukcji dokonuje dalszej analizy kodu.
Metoda ta pozwala nie tylko na ustawianie przerwań w punktach rozgałęzień, lecz także w dowolnych innych miejscach, na przykład przy instrukcjach, których wykonanie wymaga emulacji.
Dużą zaletą tej techniki jest to, że musimy sprawdzać jedynie ten kod programu, który zostanie faktycznie wykonany. Możemy również zapamiętywać zmiany w raz przeanalizowanym kodzie, więc jeśli do niego wrócimy nie musimy go już skanować.
Zasada działania dynamicznego skanowania kodu
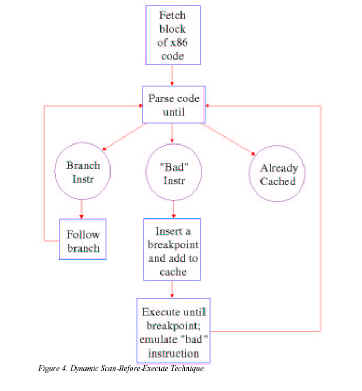
Na podstawie informacji z artykułu Machine Emulation, Virtualization, and Translation J.R.Petrusa
Podstawowym problemem zaistniałym przy dynamicznym skanowaniu kodu jest jego fizyczna modyfikacja. Może to prowadzić do błędów w dwóch przypadkach:
- w sytuacji, gdy program gościnny czyta ze swojego kodu i otrzymuje wstawioną przez monitor instrukcję przerwania (Self Examining Code w skrócie SEC)
- w momencie, gdy program gościnny modyfikuje swój kod podczas wykonania (Self Modifying Code w skrócie SMC) co może prowadzić do utraty kontroli przez monitor maszyny wirtualnej
Kolejnym wyzwaniem staje się więc wykrywanie odczytów i zapisów dotyczących uprzednio skanowanego kodu. To z kolei prowadzi do następnych trudności:
- wielokrotne skanowanie tego samego fragmentu kodu
- zbyt duża ilość przerwań i wyjątków