G. Coulouris, J. Dollimore, T. Kindberg.
Systemy rozproszone, podstawy i projektowanie.
WNT, 1998. (Rozdział 8. Przegląd systemów usług plikowych)
U. Vahalia. UNIX - nowe horyzonty, WNT, 2001. (Rozdział 10. Rozproszone systemy plików)
NFS Version 4. Technical Brief, Sun Microsystems, 1999.
NFS Version 4 Protocol, B.Pawlowski et al., 2000.
Leszek Gryz. Zastosowanie schowków w rozproszonych systemach plików. Praca magisterska, Instytut Informatyki, 2000.
DFS (ang. Distributed File System) stanowi rozproszoną implementację klasycznego modelu systemu plików z podziałem czasu, w którym wielu użytkowników współdzieli pliki i zasoby pamięciowe.
DFS zarządza zbiorami rozproszonych urządzeń pamięci.
Przezroczystość położenia:
Niezależność położenia:
Pełna integracja składowych systemów plików:
Synchronizacja przy dostępnie do współdzielonego pliku jest prosta, gdy plik jest przechowywany na centralnym serwerze. Problemem jest jednak wydajność. Jeśli w celu poprawienia wydajności pozwala się klientom na tworzenie lokalnych kopii plików lub ich części, to pojawia się problem z zachowaniem standardowej uniksowej semantyki współdzielenia pliku.
system wymusza porządkowanie wszystkich operacji w czasie i zawsze przekazuje najbardziej aktualną zawartość;
zmiany w otwartym pliku są początkowo widoczne tylko w procesie dokonującym modyfikacji. Inne procesy zauważą zmiany dopiero po zamknięciu pliku;
nie można otworzyć pliku do zapisu, jedynie do odczytu i do tworzenia (zamiast modyfikowania pliku, trzeba utworzyć go od nowa pod tą samą nazwą - ta operacja jest atomowa). Zatem chociaż nie można modyfikować plików, to jednak można modyfikować katalogi;
wszystkie zmiany mają własność wszystko albo nic (np. system bankowy).
Przechowywanie ostatnio używanych bloków dyskowych w podręcznej pamięci buforowej pozwala zmniejszyć ruch w sieci
Problem utrzymania spójności pamięci podręcznych, tzn. zgodności kopii podrzędnych z kopią główną.
Gdzie przechowywać pliki: dysk serwera, pamięć główna serwera, dysk klienta, pamięć główna klienta?
Zalety dyskowych pamięci podręcznych:
Zalety pamięci podręcznej w pamięci głównej:
Aktualizowanie danych w pamięci podręcznej:
Pamięć podręczna pozwala obsługiwać większość żądań zdalnego dostępu tak szybko jak żądania lokalnego dostępu.
Powoduje, że kontakt z serwerem jest rzadszy:
Narzut związany z komunikacją poprzez sieć jest mniejszy, gdy przesyła się dane dużymi porcjami (pamięć podręczna) zamiast jako szereg odpowiedzi na specjalne żądania (obsługa zdalna).
Pamięć podręczna sprawdza się lepiej, gdy żądania pisania są rzadkie (gdy częste, duży narzut na utrzymanie zgodności).
Pamięć podręczna pozwala osiągać korzyści, gdy wykonanie odbywa się na komputerze z lokalnymi dyskami lub dużą pamięcią główną.
Zdalny dostęp na komputerach bezdyskowych i z małą pamięcią główną trzeba realizować poprzez zdalną obsługę.
Mechanizm:
Zwiększona wydajność:
Rekonstrukcja systemu po awarii:
Narzut jaki płaci się za mniej zawodną usługę:
Niektóre środowiska wymagają usługi z pamiętaniem stanu (np. użycie w Uniksie deskryptorów plików i niejawnych pozycji w pliku wymaga przechowywania informacji o stanie).
Zwiększa dostępność i może skrócić czas dostępu.
Umożliwia uniknięcie sytuacji, gdy pojedynczy serwer staje się wąskim gardłem.
Istnienie wielu kopii powinno być niewidoczne na wyższych poziomach; na niższych poziomach kopie muszą się różnić nazwami.
Aktualizacja jednej kopii powinna być przeprowadzona również na pozostałych kopiach.
Kopiowanie na żądanie - czytanie zdalnej kopii powoduje zapamiętanie jej w pamięci podręcznej, a więc utworzenie lokalnej kopii.
Protokół aktualizacji:
aktualizacja pliku powoduje wysłanie komunikatu do serwera kopii głównej, który następnie wysyła komunikaty do serwerów kopii podrzędnych (gdy serwer kopii głównej ulegnie awarii, to wszelkie aktualizacje przestają być możliwe) - serwer kopii głównej zapewnia całkowite uporządkowanie komunikatów ze zleceniem aktualizacji;
głosowanie - klienci muszą otrzymać od serwerów pozwolenie na czytanie lub zapis pliku z wieloma kopiami, nowa wersja pliku dostaje nowy numer:
N - liczba kopii
Nr - liczba głosów dająca prawo do czytania (read quorum)
Nw - liczba głosów dająca prawo do pisania (write quorum)
musi zachodzić warunek:
Nr + Nw > N (zapobiega konfliktom czytanie-pisanie)
Nw > N/2 (zapobiega konfliktom pisanie-pisanie)
np N = 12; Nr = 3, Nw = 10; Nr = 7, Nw = 6; Nr = 1; Nw = 12
(przykład b - potencjalny konflikt pisania)
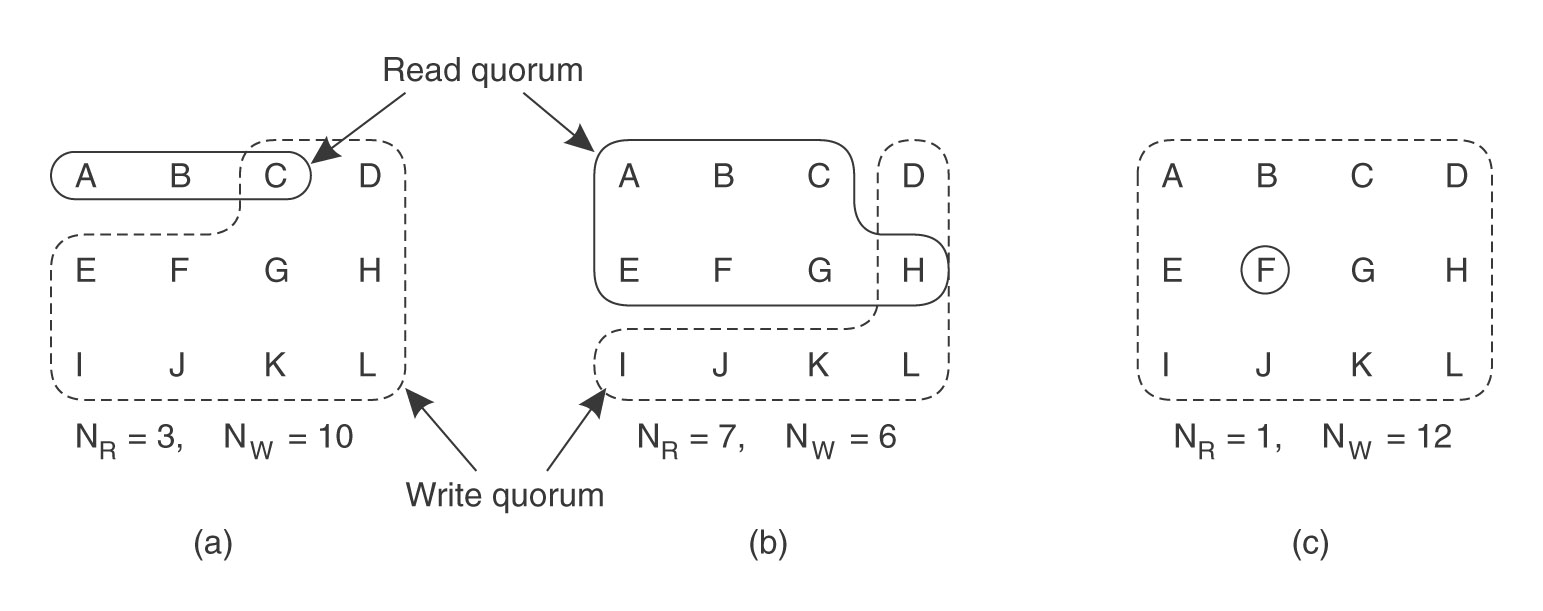
(źródło: Tanenbaum, van Steen, Systemy rozproszone i paradygmaty)
Produkt firmy Sun Microsystem wprowadzony do użytku w 1985 roku (wersja 2.0). Wersję 3.0 udostępniono w roku 1994. To ona właśnie będzie omawiana na wykładzie. Wersja ta jest obecnie intensywnie modyfikowana, nowa wersja 4.0 doczekała się już przykładowej implementacji, ale na razie na rynku nadal dominuje wersja 3.0.
Bardzo rozpowszechniony, standard w sieciach lokalnych.
Od początku firma Sun upowszechniła definicje podstawowych interfejsów oraz, na zasadzie licencji, kod źródłowy, dzięki czemu system jest teraz dostarczany przez wielu wytwórców.
Każdy komputer w sieci może działać zarówno jako klient, jak i sewer NFS. Często jednak rolę serwerów pełnią dedykowane maszyny.
System jest adaptowalny do różnych architektur i rozwiązań sprzętowych i do różnych systemów operacyjnych: prawie wszystkie aktualnie używane wersje systemu UNIX, Mach, DEC VMS, Novell Netware, MS-DOS i inne.
Cele projektowe systemu NFS i stopień ich urzeczywistnienia:
Interfejs klienta systemu NFS jest identyczny z interfejsem lokalnego systemu operacyjnego. Istniejące programy mogą bez żadnych zmian w kodzie działać na zdalnych plikach.
Klient montuje zdalne pliki w lokalnej strukturze katalogów, określając tym samym sieciową przestrzeń nazw (można montować tylko pliki eksportowane z serwera). Decyzja o położeniu pliku w tej strukturze należy do klienta, może więc być różna w różnych systemach lokalnych (NFS nie wymusza jednolitej ogólnosieciowej przestrzeni nazw). Można osiągnąć przezroczystość położenia ustalając jednolitą przestrzeń nazw budowaną przez odpowiednie pliki konfiguracyjne u każdego klienta.
Sewer NFS jest serwerem bezstanowym, a większość operacji to operacje idempotentne (powtarzalne). Dzięki temu sytuacje awaryjne w odniesieniu do plików zdalnych są postrzegane przez klienta jak awarie plików lokalnych (następuje czasowe zawieszenie usług). Awaria klienta nie ma wpływu na działanie żadnego serwera.
Buforowanie po stronie serwera (proste: standardowy mechanizm podręcznej pamięci buforowej) i po stronie klienta (złożone: buforowane bloki zdalnych plików i atrybuty plików). Moduły klienta i serwera są instalowane w jądrze systemu UNIX.
W każdym kliencie działa proces odpowiedzialny za montowanie zdalnych plików w lokalnej przestrzeni nazw. Zwykle montowanie odbywa się podczas inicjalnego ładowania systemu. Można przenosić pliki między serwerami, ale trzeba wtedy oddzielnie uaktualniać tablice montowania u każdego klienta. Nie ma więc pełnej przezroczystości wędrówki.
Można także stosować automontowanie, czyli montowanie na żądanie z dynamicznym wyborem serwera, na którym zlokalizowano jedną z kopii pliku z prawami tylko do czytania.
Nie zrealizowane wymagania:
NFS nie zapewnia zwielokrotniania plików. Oddzielnym zbiorem usług jest NIS (Network Information Service - kiedyś yellow pages), który umożliwia zwielokrotnianie baz danych odpowiadających standardowym plikom konfiguracyjnym systemu UNIX (jak /etc/hosts, /etc/services itp.)
W systemie UNIX jest możliwe zakładanie blokad na pliki, w NFS-ie serwer jest bezstanowy, więc implementacja zakładania blokad jest trudna. W NFS wersji 4.0 wprowadzono możliwość zdalnego korzystania z pomocniczego zakładania blokad na poziomie rekordów (ang. advisory record-level locks).
Ograniczona skalowalność. Liczba klientów jednocześnie korzystających z dzielonego pliku jest ograniczona wydajnością serwera dostarczającego plik (który może się stać wąskim gardłem). Wynika z braku zwielokrotniania.
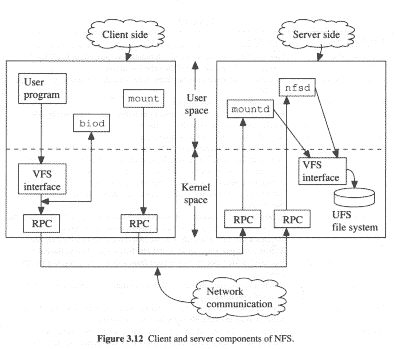
Rysunek: Architektura systemu NFS (źródło: Brown, Distributed Programming)
Składowe systemu po stronie klienta:
Składowe systemu po stronie serwera:
Protokół NFS działa w oparciu o RPC. Zlecenia klientów z poziomu użytkownika są tłumaczone na operacje protokołu NFS i przekazywane siecią do serwera.
Interfejs RPC dostarczany przez serwer NFS (fh=file handle=uchwyt pliku):
lookup(dirfh, name) -> fh, attr // odnajduje JEDNOCZŁONOWĄ nazwę
create(dirfh, name, attr) -> newfh, attr
remove(dirfh, name) -> status
getattr(fh) -> attr
read(fh, offset, count) -> attr, data
write(fh, offset, count, data) -> attr
. . .
Jeśli klient posługuje się nazwą ścieżkową, to trzeba wykonać wiele zapytań lookup - dlaczego?
![]()
Rysunek: Obsługa operacji read() (źródło: Brown, Distributed Programming)
Wynik każdego kroku tłumaczenia nazwy ścieżkowej jest przechowywany w pamięci podręcznej (po stronie klienta).
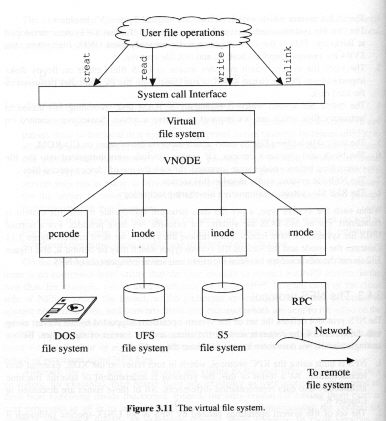
Rysunek: Wirtualny system plików (źródło: Brown, Distributed Programming)
Jest to zewnętrzna warstwa uniksowej implementacji systemu plików, pozwalająca na ujednolicenie dostępu do różnych systemów plików, w tym zdalnych.
Identyfikator pliku w systemie NFS nosi nazwę uchwytu pliku (ang. file handle) i składa się z:
Każdemu plikowi odpowiada w VFS jeden v-węzeł. W przypadku pliku lokalnego zawiera on dowiązanie do i-węzła, a w przypadku pliku zdalnego - uchwyt tego pliku.
Moduł klienta emuluje dokładnie semantykę elementarnych operacji standardowego systemu plików UNIX i jest zintegrowany z jądrem systemu, dzięki czemu:
Moduł serwera systemu NFS jest zintegrowany z jądrem systemu operacyjnego ze względów wydajnościowych.
Serwer jest bezstanowy, dlatego musi przy każdym żądaniu sprawdzać tożsamość użytkownika. Protokół RPC wymaga od klienta przesyłania informacji dotyczącej tożsamości. Dane te są porównywane z prawami dostępu do pliku.
Od NFS wersji 4.0 w protokole RPC można szyfrować informację o tożsamości użytkownika.
Montowaniem plików na zlecenie klienta zajmuje się demon mountd, wykonywany na poziomie użytkownika, po stronie serwera. Montowany plik musi być eksportowany po stronie serwera (eksportowane pliki są opisane w pliku /etc/exports).
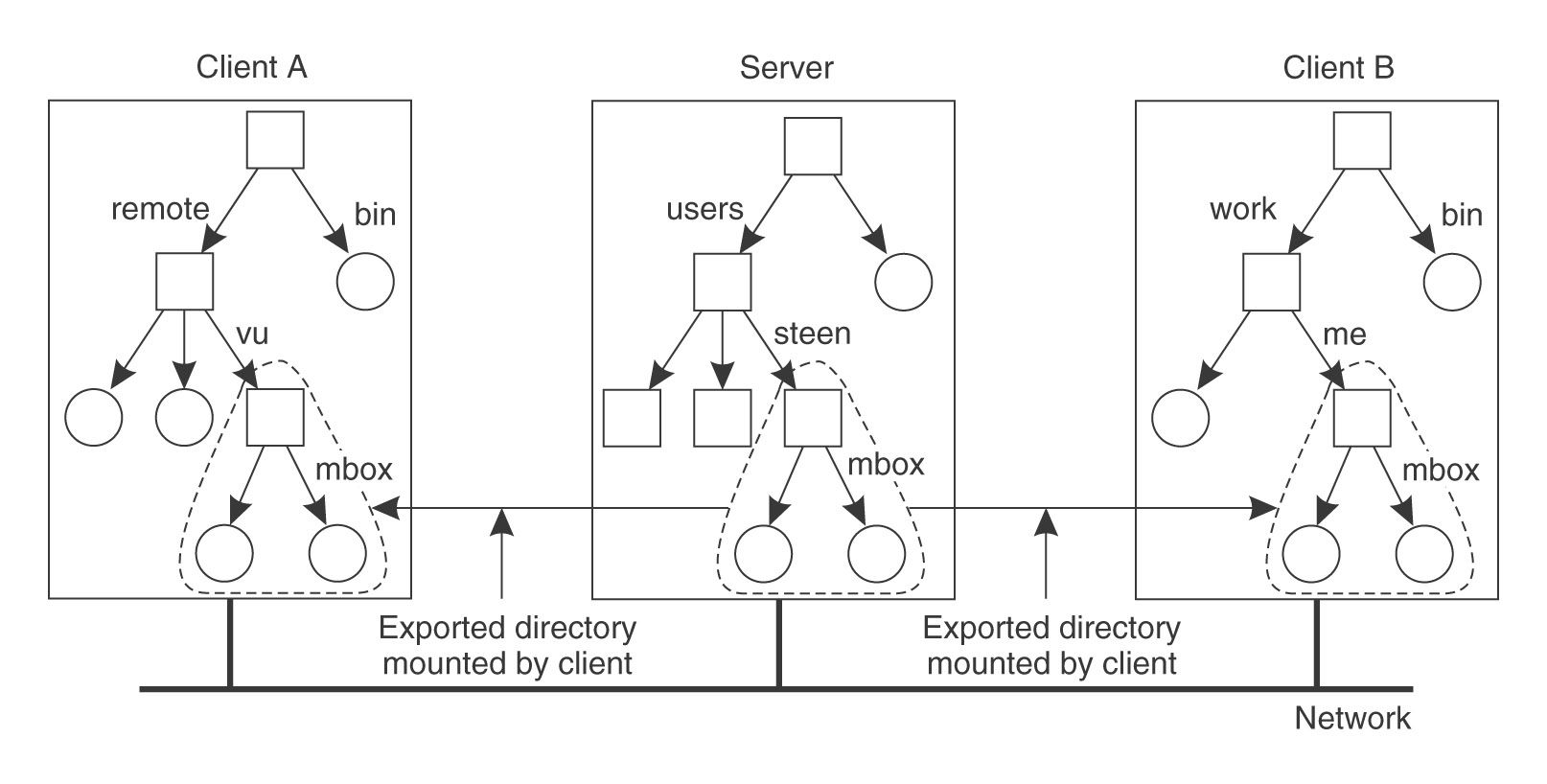
(źródło: Tanenbaum, van Steen, Systemy rozproszone i paradygmaty)
Serwer NFS może sam zamontować u siebie katalogi wyeksportowane przez inne serwery. Nie może jednak eksportować tych zewnętrznych katalogów do swoich klientów. Oznacza to, że jeśli klient odwoła się do takiego punktu zamontowania na serwerze, to odczyta jego oryginalną zawartość, a nie korzeń zamontowanego w danym katalogu system plików.
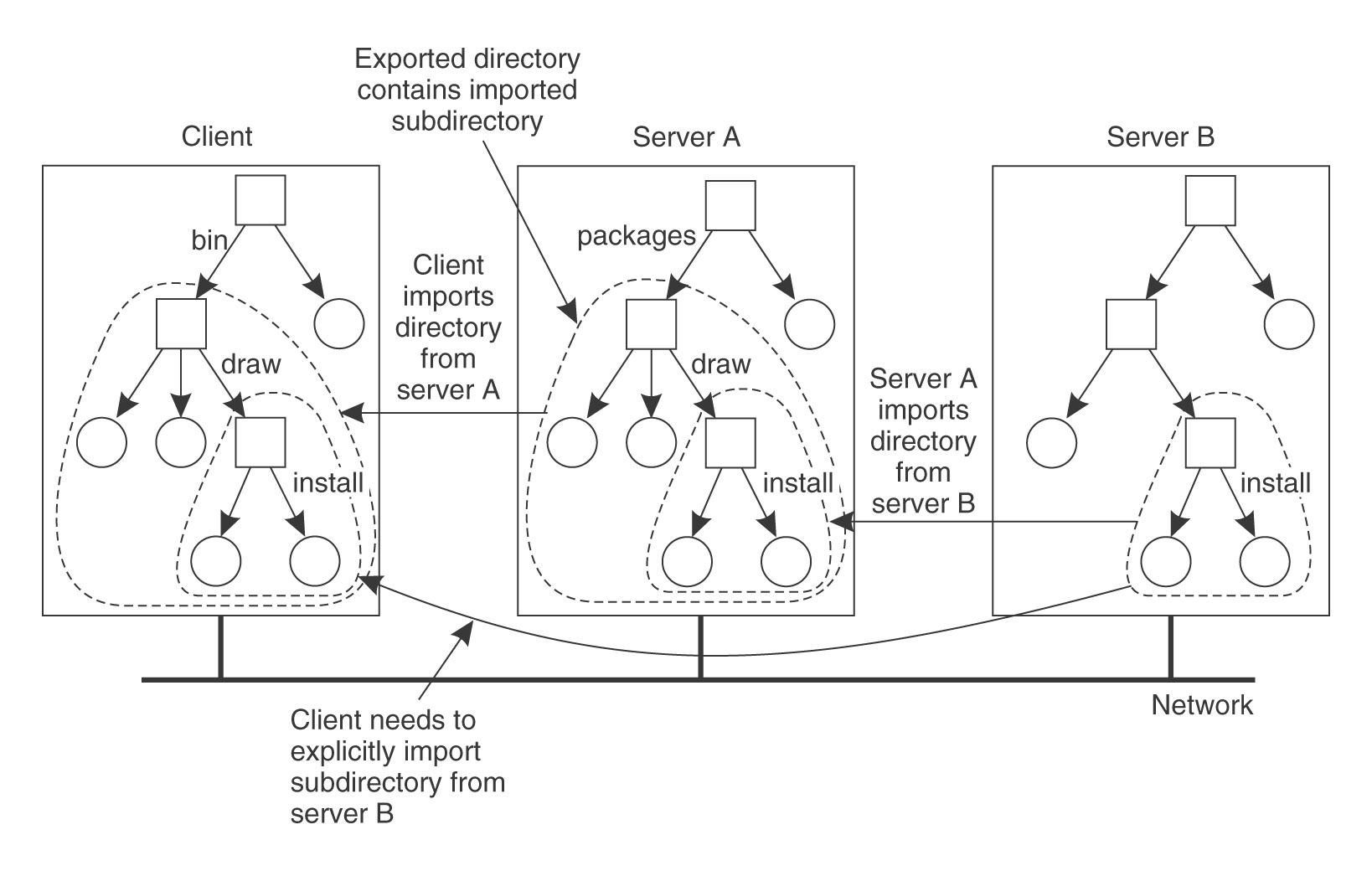
(źródło: Tanenbaum, van Steen, Systemy rozproszone i paradygmaty)
Do montowania służy wersja standardowego uniksowego polecenie mount, w której podaje się nazwę zdalnego komputera, nazwę ścieżki zdalnego katalogu i nazwę lokalnego katalogu. Proces wykonujący polecenie mount komunikuje się z demonem mountd na zdalnym komputerze za pomocą protokołu zdalnego montowania i otrzymuje uchwyt katalogu głównego zdalnego systemu plików. Zwykle montowanie odbywa się podczas inicjalnego ładowania systemu, na podstawie skryptu /etc/rc.
Montowanie sztywne: jeśli zdalny komputer jest niedostępny, to moduł klienta ponawia zamówienie aż do skutku.
Montowanie miękkie: jeśli zdalny komputer jest niedostępny, to moduł klienta po kilku próbach wykonania operacji zgłasza błąd procesom z poziomu użytkownika.
Automonter to proces z poziomu użytkownika, który utrzymuje tablicę punktów zamontowania i z każdym kojarzy jeden lub więcej serwerów NFS. Zachowuje się jak lokalny serwer NFS w maszynie klienta. Otrzymawszy zamówienie lookup odnajduje potrzebny system plików w swojej tablicy i wysyła próbne zamówienie do każdego serwera. Zamontuje system plików serwera, który odpowie pierwszy. Zamontowany system plików jest łączony z punktem zamontowania za pomocą dowiązania symbolicznego. Po pewnym okresie nieaktywności demontuje zdalny system plików.
Pozwala to na pewne tolerowanie uszkodzeń i równoważenie obciążenia.
Standardowo systemy uniksowe utrzymują w pamięci głównej podręczną pulę buforów wejścia-wyjścia (podręczna pamięć buforowa), zapewniają czytanie z wyprzedzeniem i opóźniony zapis. W ustalonych odstępach czasu (zwykle 30 sekund) wykonywana jest operacja sync, która odsyła zmienione bufory na dysk.
Serwery NFS korzystają z tej podręcznej pamięci buforowej na swojej maszynie lokalnej, z tym, że operacje pisania są realizowane natychmiast (ang. write-through) - awaria serwera mogłaby spowodować utratę danych niezauważalną po stronie klienta.
Po stronie klienta są buforowane zarówno bloki danych (w podręcznej pamięci buforowej), jak i atrybuty (w r-węźle). Może to powodować kłopoty z utrzymaniem zgodności danych. Wykonanie po stronie klienta operacji pisania nie powoduje natychmiastowego uaktualnienia pozostałych kopii. Z blokami plików pamięta się czas ostatniej modyfikacji pliku na serwerze. Co jakiś czas klient prosi serwer o podanie czasu modyfikacji i w przypadku, gdy jest on nowszy, to unieważnia wszystkie przechowywane w pamięci podręcznej bloki pliku.
Sprawdzenie ważności wykonuje się przy każdym otwarciu pliku i kontakcie z serwerem w celu sprowadzenia nowego bloku pliku. Domyślnie zakłada się, że bloki zwykłych plików pozostają ważne przez 3 sekundy, bloki katalogów przez 30 sekund, a atrybuty przez 60 sekund (wartości ustalane podczas montowania zdalnego systemu plików).
Za czytanie z wyprzedzeniem i opóźnione pisanie odpowiada biodemon. Jest on powiadamiany o każdej operacji czytania i inicjuje czytanie następnego bloku. Operacje pisania powodują oznaczenie bloków jako brudnych i są kierowane asynchronicznie do wysłania do serwera. Dokładniej, stosuje się asynchroniczny zapis PEŁNYCH bloków i opóźniony zapis CZĘŚCIOWO wypełnionych bloków. Bloki katalogów są przesyłane po każdej modyfikacji.
NFS wymaga synchronicznego wykonania operacji zapisu po stronie serwera. Oznacza to zmiany zarówno atrybutów pliku, jak i jego treści. Wszelkie operacje zapisu są więc kosztowne.
Stosunkowo słabą wydajność operacji write można poprawić stosując po stronie serwera zasilaną z baterii nieulotną pamięć RAM (NVRAM - od ang. non-volatile RAM). Umieszcza się ją w jednostce sterującej dysku serwera. Serwer potwierdza więc operację pisania po wysłaniu danych na NVRAM, czyli szybciej.
Pobieranie atrybutów pliku wymaga jednego RPC na plik. Polecenia takie jak ls -l wykonane na katalogu mogą generować dużą liczbę żądań RPC.
Jeśli serwer nie odpowiada na żądanie wystarczająco szybko, to klient retransmituje komunikat. To jeszcze bardziej zmniejsza wydajność
Protokół NFS jest bezstanowy, a więc po stronie serwera nie przechowuje się informacji o otwartych plikach. Prowadzi to do kilku niezgodności z uniksową semantyką plików.
W systemie UNIX prawa dostępu do pliku sprawdza się podczas otwierania pliku (NIE podczas operacji czytania/pisania). Załóżmy, że po otwarciu pliku do pisania, właściciel pliku zmieni prawa dostępu na tylko-do-czytania. W UNIX-ie użytkownik może kontynuować pisanie aż do momentu zamknięcia pliku. W NFS prawa do wykonania operacji sprawdza się przy każdym odczycie/zapisie.
Jeśli proces usuwa plik otwarty przez inny proces, to jądro zaznacza plik do usunięcia i usuwa odpowiadającą mu pozycję z katalogu macierzystego. Żaden nowy proces nie może teraz otworzyć pliku, ale procesy, które zrobiły to wcześniej mogą z niego korzystać aż do zamknięcia. Dopiero gdy ostatni taki proces wykona close, system fizycznie usunie plik. Korzysta się z tego przy implementacji plików tymczasowych.
W NFS próbuje się obejść problem modyfikując kod po stronie klienta. Gdy klient wykryje próbę usunięcia otwartego pliku, zmienia ją na rename (wybierając jakąś nietypową nazwę). Po zamknięciu pliku klient wykonuje remove.
Rozwiązanie sprawdza się, gdy proces, który otworzył plik działa na tej samej maszynie co proces, który plik usuwa. Nie ma się jak chronić przed usuwaniem plików na innych klientach lub na serwerze.
W UNIX-ie operacja read i write powoduje założenie blokady na v-węzeł na początku operacji wejścia-wyjścia. Operacje te są więc atomowe. Jeśli w mniej więcej tym samym czasie zostaną zgłoszone dwie operacje pisania, to jądro wykona je po kolei, w pewnym porządku (najpierw jedną, a po jej zakończeniu drugą). Oznacza to, że plik NIE MOŻE się zmienić PODCZAS czytania.
W przypadku pliku zdalnego jądro po stronie klienta szereguje współbieżne żądania dostępu do pliku pochodzące od dwóch procesów na tej samej maszynie. Jeśli jednak procesy wykonują się na różnych maszynach, to ich żądania trafiają do serwera niezależnie. Operacja read i write może przekładać się na KILKA żądań RPC (maksymalny rozmiar komunikatu wynosi 8K bajtów) i serwer nie zakłada blokad między żądaniami.
| Janina Mincer-Daszkiewicz |