G. Coulouris, J. Dollimore, T. Kindberg. Systemy rozproszone, podstawy i projektowanie. WNT, 1998 (rozdział 17: Rozproszona pamięć dzielona).
Distributed Shared Memory: Where We Are and Where We Should Be Headed. John B. Carter, Dilip Khandekar, Linus Kamb. Appeared in Proc. of the 5th IEEE Workshop on Hot Topics in Operating Systems, May 1995.
Interesują nas jedynie systemy zbudowane ze zbioru niezależnych komputerów. Dzielimy je na dwie grupy:
Wieloprocesory (ang. multiprocessors) - komputery mają wspólną pamięć. W wieloprocesorze istnieje pojedyncza fizyczna przestrzeń adresowa, współdzielona przez wszystkie procesory.
Wielokomputery (ang. multicomputers) - komputery nie mają wspólnej pamięci. Każdy komputer ma własną prywatną pamięć fizyczną.

Rysunek: Architektura systemów rozproszonych (źródło: Tanenbaum, Distributed Systems)
Zależnie od architektury połączeń między komputerami można wyróżnić dwie kategorie systemów:
z pojedynczą szyną (ang. bus-based) - istnieje pojedyncza sieć, szkielet, szyna, kabel lub inne medium transmisyjne, które łączy wszystkie komputery (tak działa telewizja kablowa);
z przełącznikami (ang. switched) - nie ma pojedynczej sieci szkieletowej, komputery są połączone między sobą różnymi kablami, przy przejściu komunikatu z jednego kabla do drugiego trzeba podejmować jawną decyzję (tak działa tradycyjna telefonia). Przełączniki przełącza się sprzętowo. Wiele CPU może mieć równocześnie dostęp do pamięci (do różnych bloków). Pełna siatka wymaga n x n przełączników, sieć typu omega wymaga mniejszej liczby, ale bardziej skomplikowanych (droższych) przełączników (w przykładowej sieci każdy ma dwa wejścia i dwa wyjścia).
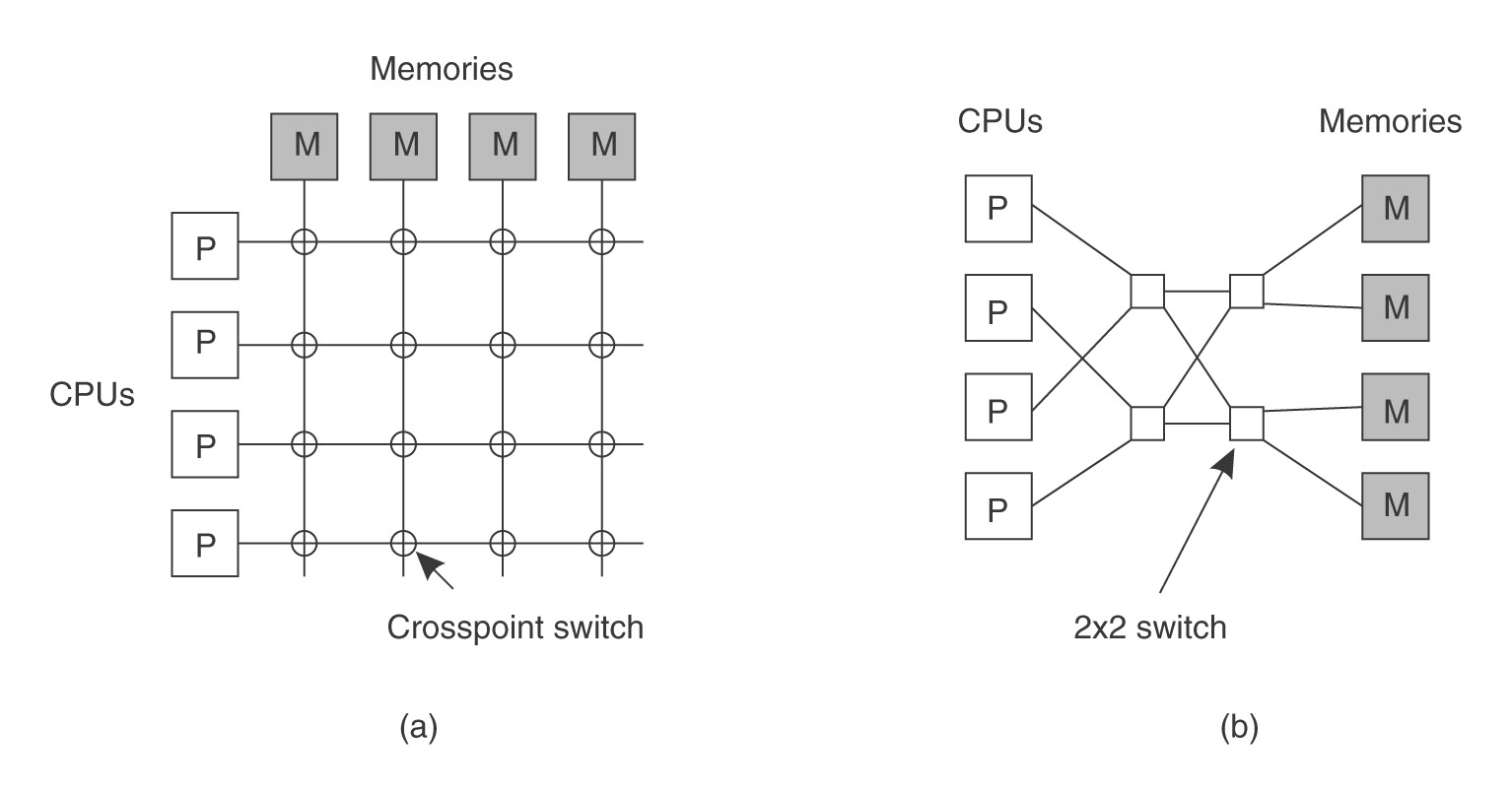
Rysunek: Typy połączeń (źródło: Tanenbaum, Distributed Systems)
Można zredukować koszt przełączników budując systemy hierarchiczne. Każde CPU ma szybki dostęp do własnej lokalnej pamięci i dłuższy dostęp do pamięci innych CPU. Takie architektury nazywają się NUMA (ang. Non-uniform memory access). Mają one krótszy średni czas dostępu niż systemy z sieciami typu omega, ale ten czas zależy od właściwego rozmieszczenia kodu i danych programów w pamięciach lokalnych.
Tradycyjne wieloprocesory określa się terminem UMA (ang. Uniform Memory Access), a wielokomputery terminem NORMA (ang. No Remote Memory Access).
Wieloprocesory:
Wielokomputery:
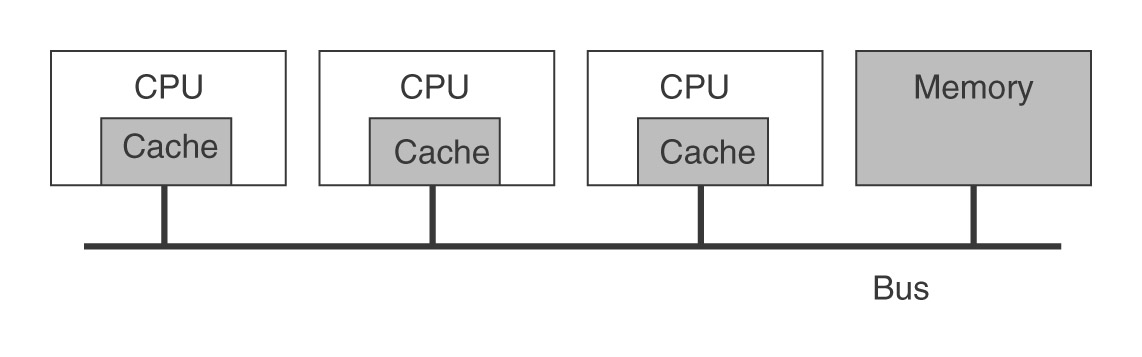
Rysunek: Wieloprocesor z pojedynczą szyną (źródło: Tanenbaum, Distributed Systems)
Dostęp do pamięci poprzez szynę.
Rozstrzyganie konfliktów w dostępie do szyny.
Szyna potencjalnym wąskim gardłem (kłopoty ze skalowalnością) - do 64 CPU, zwykle raczej 4-8.
Podsłuchująca pamięć podręczna (ang. snooping cache - rozmiary pamięci podręcznych są od 512 KB do 1 MB bajtów, dają współczynnik trafień rzędu 90%. Wszystkie żądania dotyczące pamięci przechodzą przez pamięć podręczną.
Protokoły zapewniające zgodność danych przechowywanych w pamięci podręcznej (ang. cache consistency protocol).
Akcja podjęta przez pamięć podręczną w reakcji na działanie własnego CPU:
Akcja podjęta przez pamięć podręczną w reakcji na działanie zdalnego CPU:
Możliwy stan bloku pamięci podręcznej:
Pomysł głównie sprowadza się do tego, że blok czytany przez wiele procesorów będzie obecny w wielu pamięciach podręcznych. Blok intensywnie modyfikowany przez jeden procesor będzie przechowywany tylko w jego pamięci podręcznej i NIE BĘDZIE zapisywany do pamięci przy każdej modyfikacji.
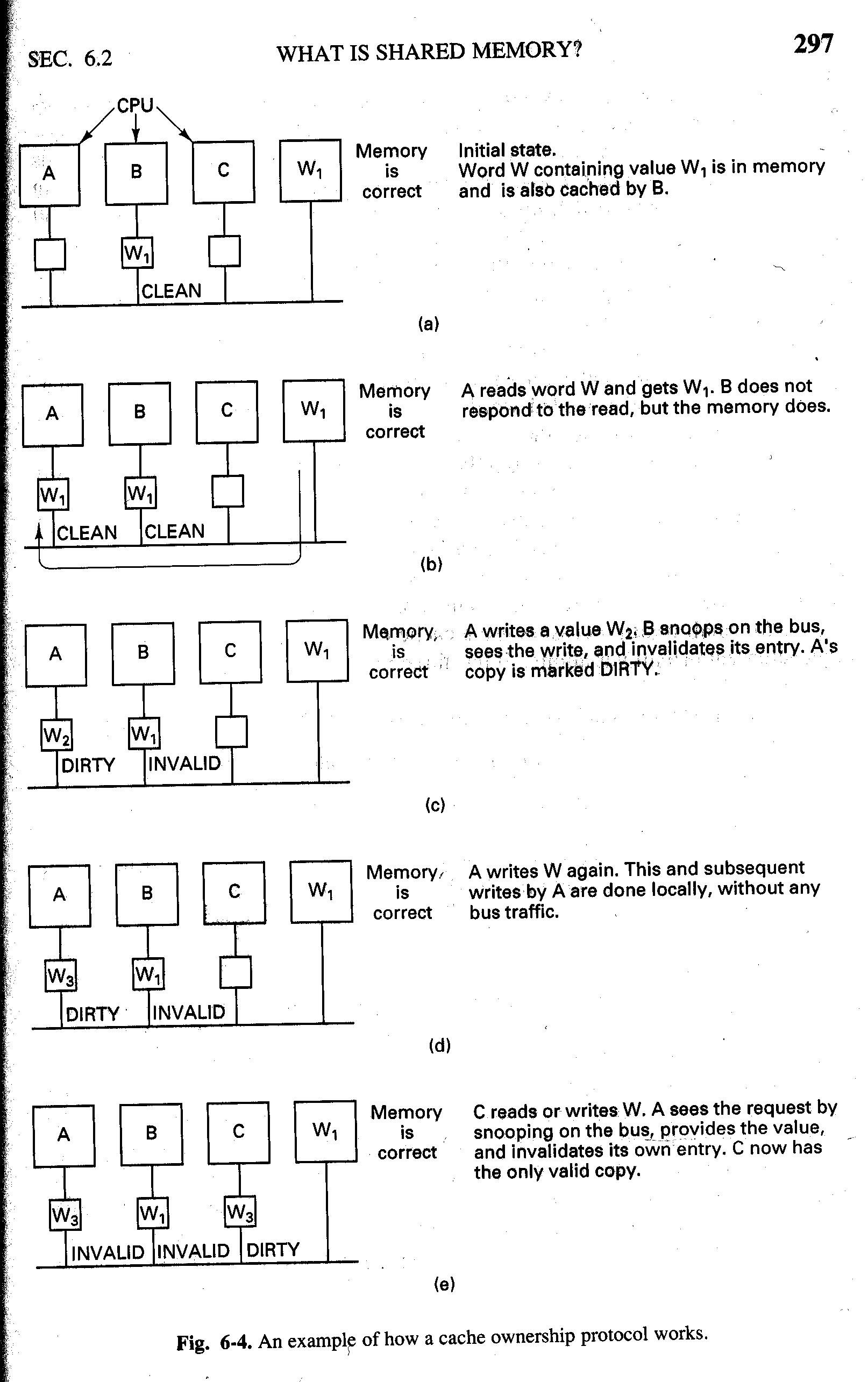
Rysunek: Algorytm jednokrotnego pisania (źródło: Tanenbaum, Distributed Systems)
Cechy tego protokołu:
Wieloprocesory z pojedynczą szyną nie skalują się do systemów z setkami lub tysiącami procesorów. Jedynym efektywnym sposobem zwiększenia skalowalności jest zwiększenie przepustowości łączy komunikacyjnych. Rozwiązanie może polegać na zmianie topologii połączeń - zamiast jednej szyny użyć dwóch lub siatki szyn.
Innym sposobem jest stworzenie architektury hierarchicznej. Pojedynczy klaster (ang. cluster) składa się z kilku CPU i pamięci połączonych szyną. System składa się z wielu takich klastrów połączonych ze sobą za pomocą specjalnej szyny (ang. intercluster bus). Dopóki większość CPU komunikuje się ze sobą głównie w ramach jednego klastra, dopóty ruch międzyklastrowy będzie niewielki. Jeśli zrobi się intensywny, to można rozbudowywać połączenia międzyklastrowe, tworząc np. siatkę takich połączeń.
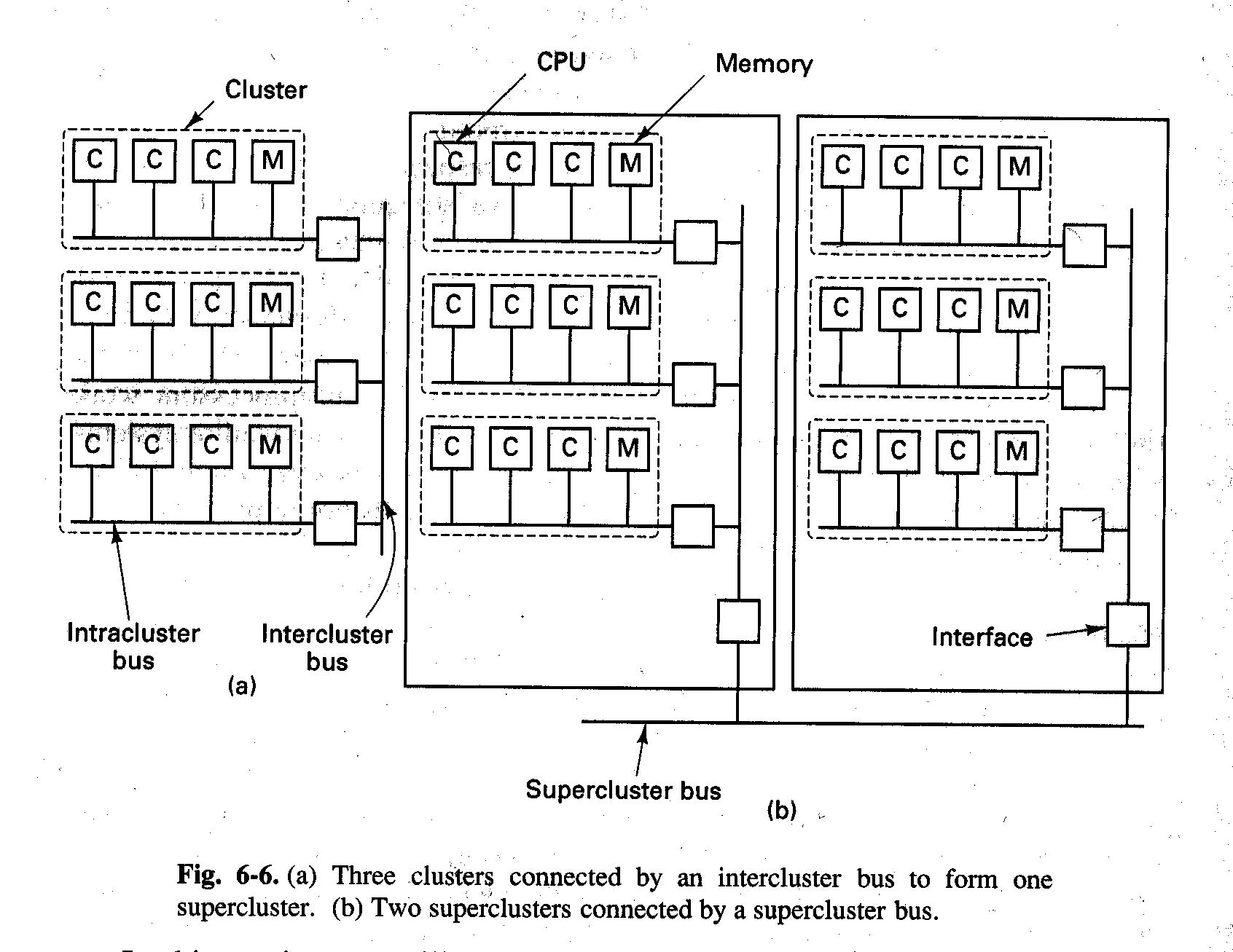
Rysunek: DASH (źródło: Tanenbaum, Distributed Systems)
Przykładem takiego rozwiązania jest DASH (nazwa pochodzi od skrótu Directory Architecture for Shared Memory), zaprojektowany w Stanford University w latach 90-tych. Zbudowano prototyp złożony z 64 CPU.
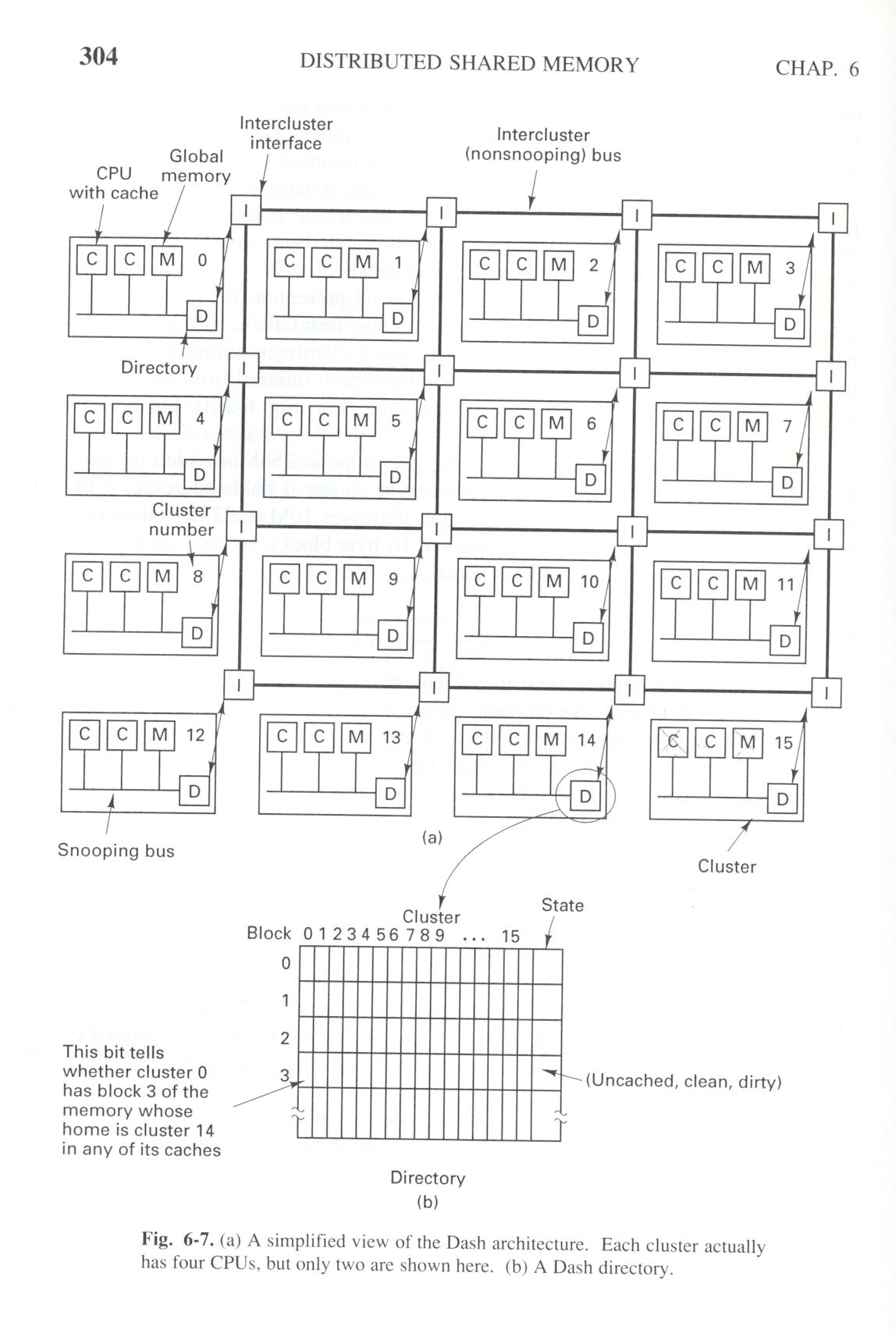
Rysunek: DASH (źródło: Tanenbaum, Distributed Systems)
DASH składa się z 16 klastrów, każdy zawiera szynę, 4 CPUs, 16 MB pamięci głównej i urządzenia wejścia-wyjścia (rysunek jest uproszczony i nie przedstawia wszystkich elementów). Każde CPU może podsłuchiwać lokalną szynę, ale nie inne szyny. Całkowita przestrzeń adresowa zawiera 256 MB, podzielone na 16 obszarów po 16 MB każdy. Pamięć główna klastra 0 zawiera adresy od 0 do 16M, klastra 2 adresy 16M - 32M itd. Bloki pamięci o wielkości 16 bajtów są przesyłane między klastrami i przechowywane w pamięciach podręcznych. Każdy klaster ma w swojej przestrzeni adresowej 1M bloków pamięci.
Każdy klaster ma katalog (ang directory), w którym trzyma informacje o kopiach swoich bloków umieszczonych w innych klastrach. Katalog ma 1M pozycji (tyle co bloków). Każda pozycja przechowuje mapę bitową z jednym bitem na każdy klaster - bit jest ustawiony jeśli wskazany blok jest w jakiejkolwiek pamięci podręcznej wskazanego klastra. Ponadto w dwubitowym polu jest opisany stan bloku. Każdy katalog zajmuje ponad 2M bajtów (1M pozycji x 18 bitów).
Każdy blok pamięci może być w jednym z trzech stanów:
Protokół zgodności stosowany w DASH korzysta z pojęcia własności oraz unieważniania. W każdej chwili każdy blok ma tylko jednego właściciela. Dla bloków niebuforowanych i czystych właścicielem jest macierzysty klaster tego bloku. W przypadku bloków brudnych jego właścicielem jest klaster przechowujący jedyną kopię bloku. Modyfikacja bloku w stanie czysty wymaga wcześniejszego odszukania i unieważnienia wszystkich istniejących kopii.
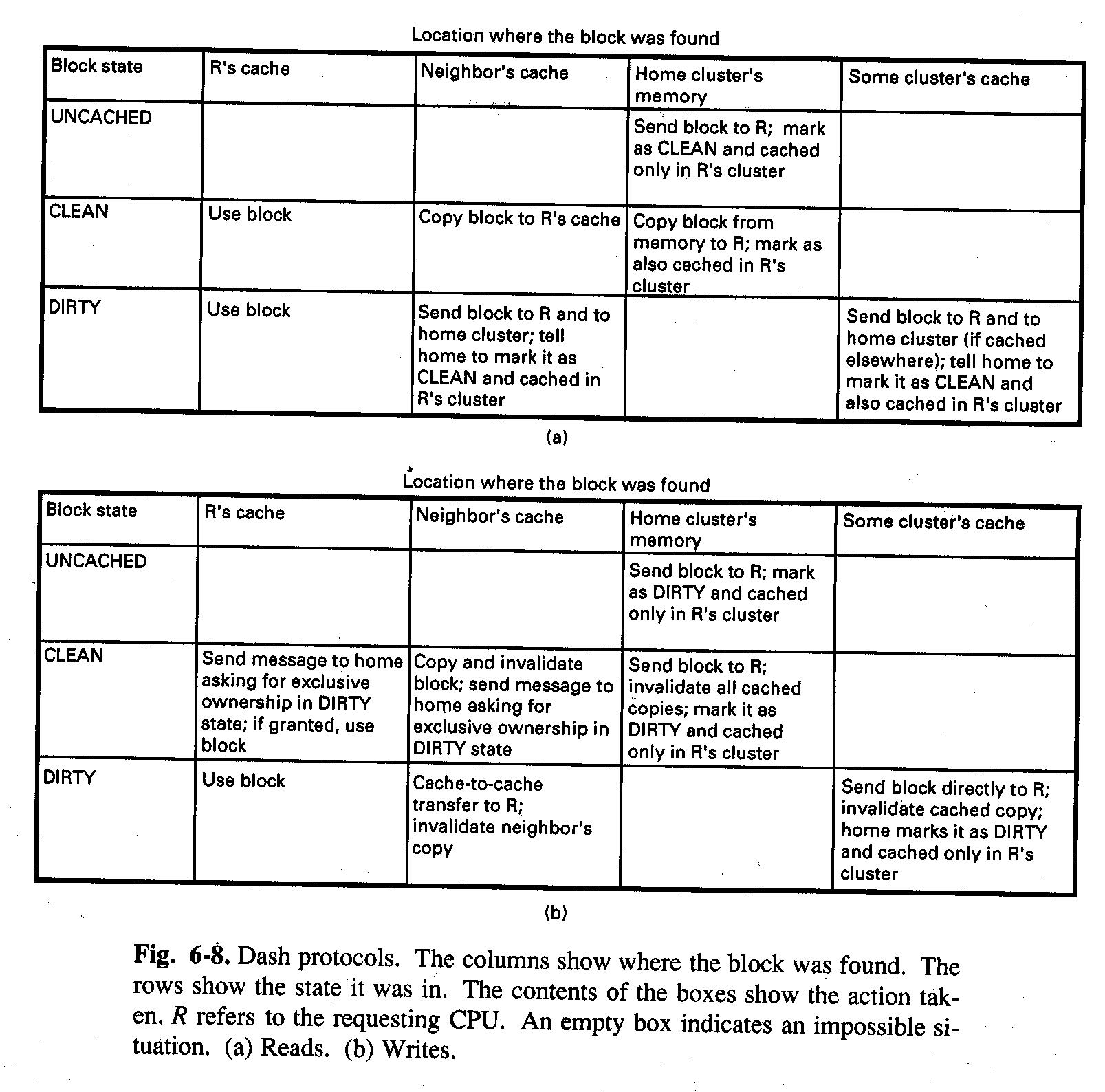
Rysunek: Protokoły zgodności w DASH (źródło: Tanenbaum, Distributed Systems)
Dostęp do bloku może wymagać przesłania wielu komunikatów. Dlatego w celu poprawienia wydajności stosuje się różne specjalne techniki: dwa zbiory połączeń międzyklastrowych, potokowe zapisy, inny model spójności pamięci.
Wnioski końcowe: implementacja pamięci dzielonej wymaga dużej bazy danych (katalogów), dużej mocy obliczeniowej (sprzęt do zarządzania katalogami), intensywnej komunikacji.
Sprzętowe buforowanie w dużych wieloprocesorach jest kosztowne. Rozwiązaniem nie wymagającym wyrafinowanych technik buforowania są architektury wieloprocesorowe typu NUMA. Tak jak w tradycyjnych wieloprocesorach typu UMA (ang. Uniform Memory Access), w wieloprocesorach typu NUMA istnieje pojedyncza wirtualna przestrzeń adresowa widoczna przez wszystkie procesory. Wartość zapisana do komórki przez dowolny procesor jest natychmiast widoczna dla wszystkich pozostałych procesorów, kolejna operacja odczytu na pewno dostarczy tę właśnie wartość.
Różnica między NUMA i UMA nie leży w semantyce, tylko w wydajności. W NUMA dostęp do zdalnej pamięci jest dużo wolniejszy niż dostęp do lokalnej i nie próbuje się niwelować tej różnicy za pomocą sprzętowego buforowania (współczynnik jest rzędu 1:10).
Pierwszą maszyną typu NUMA był wieloprocesor Cm* zbudowany w końcu lat 70-tych. Składał się on z kilku klastrów, każdy zawierał CPU, mikroprogramowalne MMU, moduł pamięci i urządzenia wejścia-wyjścia. Nie było pamięci podręcznych ani podsłuchujących szyn. Klastry były połączone międzyklastrowymi szynami.
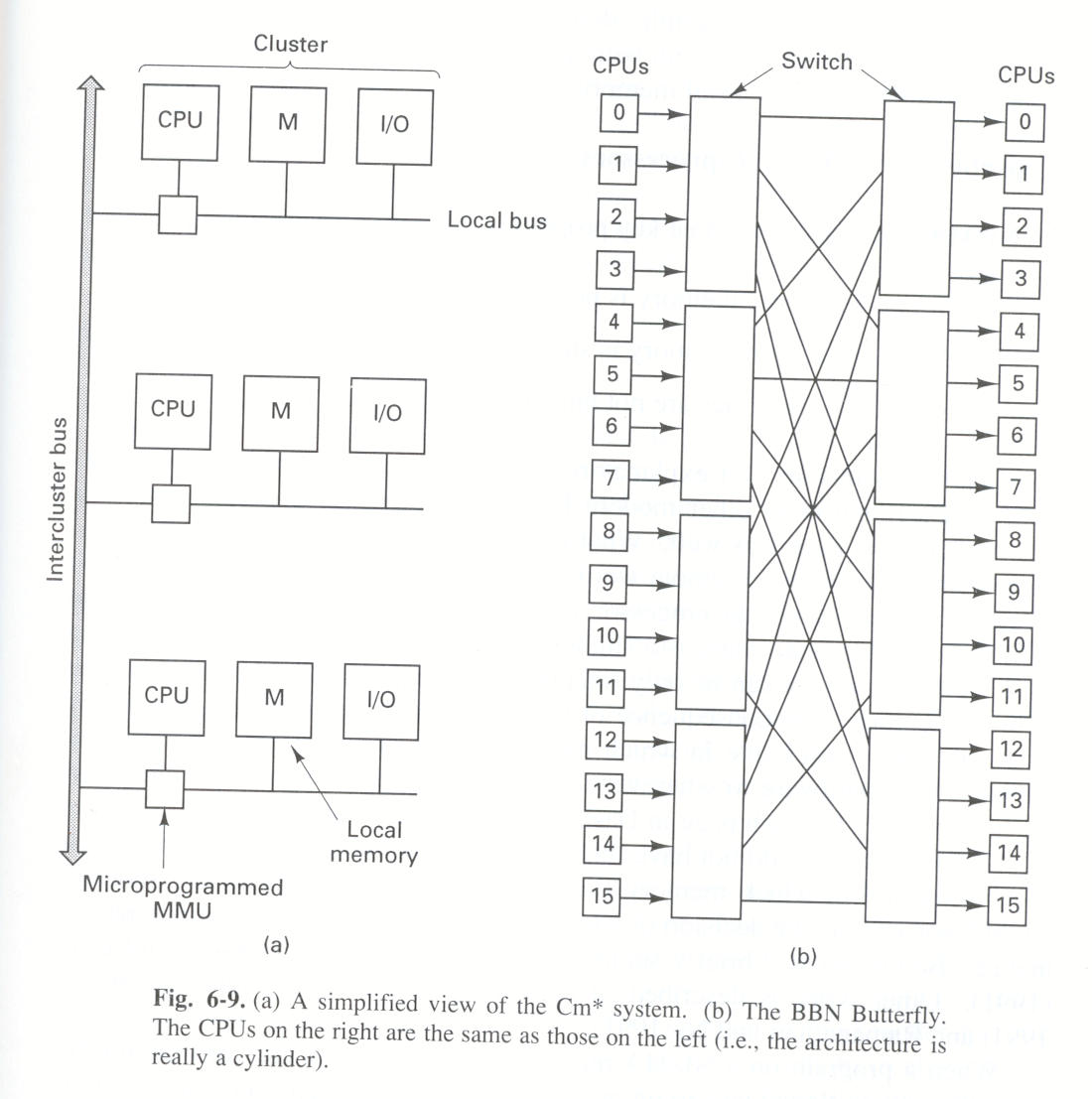
Rysunek: Architektura NUMA (źródło: Tanenbaum, Distributed Systems)
Żądanie wygenerowane przez CPU jest najpierw analizowane przez lokalne MMU, które po górnych bitach adresu rozpoznaje, o którą pamięć chodzi. Żądanie do lokalnej pamięci jest realizowane w tradycyjny sposób. Żądanie do zdalnej pamięci jest zamieniane na komunikat wysyłany szyną do zdalnego MMU.
W maszynach typu UMA lokalizacja strony nie ma kluczowego znaczenia (bo dzięki buforowaniu strona i tak zostanie przeniesiona tam, gdzie jest potrzebna).
W maszynach typu NUMA lokalizacja ma decydujące znaczenie dla wydajności systemu.
Rozproszona pamięć dzielona (ang. distributed shared memory, w skrócie DSM) jest abstrakcją używaną do określenia wspólnego użytkowania danych przez procesy, które nie dzielą pamięci fizycznej. Pamięć dzielona stanowi część przestrzeni adresowej procesów i mogą one z niej korzystać w standardowy sposób. Zadaniem systemu operacyjnego ew. systemu wykonawczego jest zapewnienie w sposób przezroczysty dostępu do wspólnych danych (emulowanie wspólnej pamięci fizycznej).
Głównym celem DSM jest zapewnienie programiście wygodnego dostępu do współdzielonych danych, bez konieczności korzystania z mechanizmu przekazywania komunikatów. Oczywiście w systemie rozproszonym nie da się całkowicie uniknąć przekazywania komunikatów - korzysta z niego system wsparcia działania pamięci DSM wysyłając aktualizacje między komputerami.
Przekazywanie komunikatów a pamięć DSM:
Model programowania. Przekazywanie komunikatów umożliwia synchronizację dostępu do wspólnych danych oraz uwzględnienie różnic w ich reprezentacji. W przypadku DSM do synchronizacji trzeba zastosować odrębne mechanizmy (np. semafory). Używanie pamięci DSM wymaga więc zorganizowania usług rozproszonej synchronizacji (ale konstrukcje synchronizujące są budowane za pomocą przekazywania komunikatów). Pamięć DSM może być trwała, więc komunikujące się procesy mogą nie istnieć w tym samym czasie. Procesy przekazujące sobie komunikaty muszą działać w tym samym czasie (chyba że korzystają ze skrzynki pocztowej).
Wydajność. Wydajność programu stosującego DSM zależy od wielu czynników, m.in. od sposobu współdzielenia zmiennych. Przy przekazywaniu komunikatów wszelkie zdalne dostępy do danych są jawne (z dokładnością do optymalizacji stosowanych przez implementację). Przy zastosowaniu DSM operacja czytania lub pisania może, lecz nie musi, prowadzić do wymiany komunikatów.
Podstawowe podejścia do realizacji pamięci DSM:
Wsparcie przez stronicowanie. Systemy Ivy, Munin, Clouds realizują pamięć DSM jako obszar pamięci wirtualnej zajmujący ten sam przedział adresów w przestrzeni adresowej każdego z uczestniczących procesów. Spójność danych jest utrzymywana przez jądro jako część procedury obsługi błędów strony.
Wsparcie biblioteczne. Języki programowania takie jak Linda i Orca dostarczają DSM w postaci współdzielonych obiektów. Ich obsługą zajmują się systemy wykonawcze (ang. runtime system) tych języków. Procesy korzystają z obiektów za pomocą wywołań bibliotecznych wstawionych przez kompilator. Procedury biblioteczne korzystają z lokalnych obiektów, komunikując się ze zdalnymi systemami w niezbędnych przypadkach utrzymania spójności.
Struktura danych przechowywanych w pamięci DSM:
Obraz bajtowy. Pamięć jest sekwencją bajtów. Takie podejście zrealizowano w systemie Ivy. Aplikacje mogą umieszczać w pamięci dzielonej dowolne pożądane struktury danych. Dostęp do pamięci bajtowej odbywa się tak jak w zwykłej pamięci wirtualnej.
Obiekty dzielone. Pamięć jest zbiorem dzielonych obiektów. Podejście zrealizowano w Orce. Zaleta: synchronizacja związana ściśle z operacjami na obiektach.
Dane stałe. Pamięć jest traktowana jako zbiór stałych obiektów danych. Podejście zrealizowane w Lindzie. Procesy nie mogą zmieniać obiektów, mogą je zastępować innymi.
Wydaje się, że w praktyce w wysoko-wydajnych wielokomputerach dużej skali nadal dominują systemy z przesyłaniem komunikatów - DSM nie jest w stanie spełnić wysokich wymagań wydajnościowych.
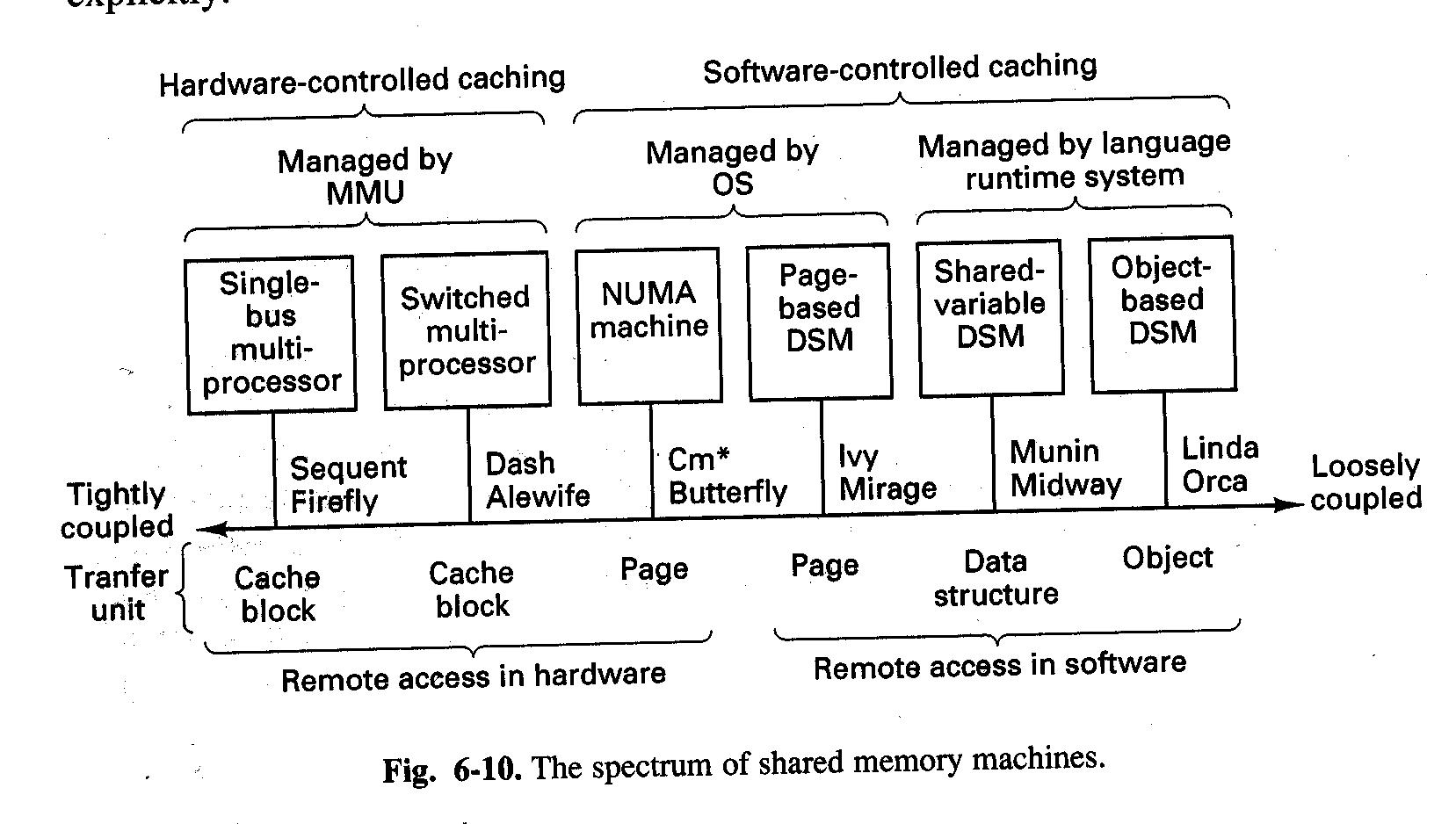
Rysunek: Porównanie (źródło: Tanenbaum, Distributed Systems)
Wieloprocesor z pojedynczą szyną: obsługa pamięci dzielonej realizowana całkowicie sprzętowo.
Wieloprocesor z przełącznikami: sprzętowe buforowanie, ale programowe struktury danych przechowujące informacje o położeniu buforowanych bloków. Zgodność zachowuje się dzięki stosowaniu złożonych algorytmów zwykle realizowanych przez mikrokod MMU.
Maszyny typu NUMA: rozwiązanie hybrydowe. CPU może czytać/pisać z/do wspólnej wirtualnej przestrzeni adresowej, ale buforowanie (kopiowanie, migracja stron) jest kontrolowane programowo.
DSM - strony: CPU nie może bezpośrednio sięgać do pamięci zdalnej; obsługa błędów braku zdalnej strony odbywa się programowo (SO).
DSM - zmienne dzielone: nie ma pojedynczej pamięci wspólnej, informacje o dzielonych strukturach danych dostarcza użytkownik.
DSM - obiekty: zdalny dostęp tylko poprzez chronione metody (ułatwia zachowanie zgodności obiektów), wszystko realizowane programowo.
Podsumowanie
| Szyna | Przełączniki | NUMA | DSM-strona | DSM-zm.dz. | DSM-obiekty | |
| Liniowa, dzielona wirtualna przestrzeń adresowa? | Tak | Tak | Tak | Tak | Nie | Nie |
| Możliwe operacje | Czyt/Pis | Czyt/Pis | Czyt/Pis | Czyt/Pis | Czyt/Pis | Ogólne |
| Kapsułkowanie i metody? | Nie | Nie | Nie | Nie | Nie | Tak |
| Czy zdalny dostęp jest możliwy w sprzęcie? | Tak | Tak | Tak | Nie | Nie | Nie |
| Kto zamienia zdalne żądania dostępu do pamięci na komunikaty? | MMU | MMU | MMU | SO | System wykonawczy j.p. | System wykonawczy j.p. |
| Środek transmisji? | Szyna | Szyna | Szyna | Sieć | Sieć | Sieć |
| Kto realizuje migrację danych? | Sprzęt | Sprzęt | Oprog. | Oprog. | Oprog. | Oprog. |
| Jednostka transmisji? | Blok | Blok | Strona | Strona | Zmienna dzielona | Obiekt |
| Janina Mincer-Daszkiewicz |