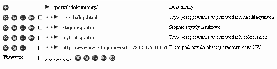
|
Jarosław Kołakowski, Sławomir Mroczek
Grudzień 2001
W ostatnim czasie dużego znaczenia nabrały technologie pozwalające na udostępnienie informacji możliwie największej liczbie odbiorców, w możliwie najkrótszym czasie i możliwie najniższym kosztem. Informacje te powinny być przedstawione w taki sposób, aby odbiorca mógł łatwo i szybko dotrzeć także do informacji powiązanych z nimi tematycznie. Pożądane jest również zróżnicowanie treści i wyglądu informacji oraz możliwości dostępu do niej w zależności od typu odbiorcy. Takie możliwości daje Internet, WWW oraz koncepcja portali internetowych.
Celem naszej pracy magisterskiej było stworzenie i wdrożenie na Wydziale Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego (MIM UW) Wydziałowego Portalu Internetowego. Niezbędnym elementem pracy było zaprojektowanie i oprogramowanie uniwersalnego narzędzia do tworzenia portali internetowych. Narzędzie to otrzymało nazwę XMportal, od technologii XML i XSLT, na których zostało oparte oraz wydziału, na którym powstało.
Projekt był realizowany przez zespół trzyosobowy w składzie: Marek Dębowski, Jarosław Kołakowski, Sławomir Mroczek. Jądro narzędzia i aplikacje powstały we współpracy wszystkich trzech członków zespołu, przetwarzanie dokumentów z użyciem technologii XML i XSLT zostało zaimplementowane przez autorów tej pracy, natomiast częścią bazodanową zajął się Marek Dębowski (por. Wstęp do [Dębowski]).
W rozdziale 1 przedstawimy sieć WWW i omówimy stosowane obecnie standardy i technologie umożliwiające funkcjonowanie WWW oraz wykorzystywane przez aplikacje działające w sieci. Znaczną część rozdziału poświęcimy omówieniu technologii XML i XSLT oraz popularnych języków programowania używanych do pisania takich aplikacji.
W rozdziale 2 wprowadzimy czytelnika w tematykę portali i sprecyzujemy wymagania postawione przed narzędziem XMportal i Wydziałowym Portalem Internetowym.
W rozdziale 3 szczegółowo opiszemy projekt narzędzia -- jego architekturę, zastosowane koncepcje, wraz z uzasadnieniem ich wyboru, oraz logiczny model danych.
W rozdziale 4 skupimy się na szczegółach implementacji narzędzia XMportal. Uzasadnimy słuszność wyboru użytych przez nas technologii oraz omówimy szczegółowo procesy przetwarzania danych i fizyczny model danych.
W rozdziale 5 opiszemy historię wdrożenia portalu na Wydziale Matematyki, Informatyki i Mechaniki UW.
Rozdział 6 poświęcimy na podsumowanie pracy, w szczególności wyjaśnimy, w jakim stopniu narzędzie XMportal spełnia postawione przed nim wymagania.
Dodatek A to instrukcja instalacji narzędzia XMportal z załączonej do pracy płyty CD-ROM.
W dodatku B umieszczono instrukcję obsługi aplikacji administratorskiej wchodzącej w skład narzędzia.
W dodatku C znajdują się przykładowe scenariusze pracy administratora z narzędziem XMportal.
Pragniemy gorąco podziękować pani dr Janinie Mincer-Daszkiewicz za sprawowanie pieczy nad projektem, promowanie tej pracy oraz masę cennych uwag, a także panu dr Piotrowi Krzyżanowskiemu -- opiekunowi wydziałowych stron WWW -- za cierpliwość i pełne zaangażowanie w realizację projektu. Chcielibyśmy również podziękować naszym najbliższym za okazaną pomoc i wyrozumiałość.
W tym rozdziale zostanie omówione zaplecze WWW, czyli protokoły, języki i oprogramowanie, dzięki którym funkcjonuje World Wide Web. Do pojęć zdefiniowanych w tym rozdziale będziemy się odwoływać w dalszej części pracy.
WWW to skrót od World Wide Web, czyli Wielkiej Światowej Pajęczyny. Jest to hipertekstowy i multimedialny sieciowy system informacyjny oparty na publicznie dostępnych, otwartych standardach IETF, W3C i ISO. Powstał w roku 1990 w ośrodku badawczym CERN, po 21 latach istnienia Internetu i od razu stał się bardzo popularny. Od połowy lat 90-tych jest najczęściej wykorzystywaną usługą oferowaną w Internecie.
Główne przyczyny ogromnej popularności WWW to:
W 1989 roku Tim Berners-Lee opublikował w CERN-ie dokument ,,Information Management: A Proposal'', który zapoczątkował prace nad systemem mającym ułatwić naukowcom współdzielenie informacji w sieci Internet. W 1990 roku napisał program do przeglądania i edycji hipertekstu, który nazwał WorldWideWeb (por. rys. 1.1).
W tym samym roku powstała przeglądarka WWW przeznaczona do pracy w trybie tekstowym. Już pod koniec roku WWW stała się usługą ogólnodostępną, z jednym serwerem WWW znajdującym się w CERN-ie. W roku 1993 około 1% ruchu w Internecie generowali użytkownicy WWW, a liczba serwerów wzrosła do ponad 200.
Wtedy pojawiła się pierwsza graficzna przeglądarka dostępna na wszystkie popularne platformy programowe: X Window, Microsoft Windows i Macintosh. W tym roku powstało też W3 Consortium ([W3C]) nadzorujące rozwój WWW i związanych z nim standardów ([W3C-Hist]).
Obecnie liczbę serwerów WWW szacuje się na ponad 30 milionów, a liczbę użytkowników Internetu nie korzystających w ogóle z WWW na ok. 2% (dane zaczerpnięto z [IntTime]).
W roku 1994 David Filo i Jerry Yang z uniwersytetu w Stanford zapragnęli skatalogować w uporządkowany sposób adresy interesujących stron sieciowych, do których zaglądali. Każdą ze stron przydzielili do określonej kategorii, a gdy okazało się że kategorie są zbyt ogólne -- podzielili je na podkategorie. W taki sposób narodziło się Yahoo!, najbardziej znany katalog stron WWW. W roku 1997 Yahoo!, będąc już wtedy dobrze prosperującym przedsiębiorstwem, zaczęło za darmo udostępniać konta poczty elektronicznej i miejsca na prywatne strony WWW (por. rys. 1.2). W kolejnych latach firma zakupiła wiele tematycznych serwisów WWW, które zostały włączone do Yahoo! ([Yahoo-Hist]). W ten sposób powstał pierwszy portal, czyli rozbudowany serwis internetowy spełniający funkcję przedsionka Internetu, od którego użytkownicy WWW mieli rozpoczynać przeglądanie zasobów sieciowych. Od roku 1998 powstało wiele portali oferujących informacje z wielu różnych dziedzin tematycznych, m.in. najpopularniejsze w Polsce onet.pl (http://onet.pl/) oraz Wirtualna Polska (http://www.wp.pl/).
Usługa WWW jest obsługiwana przez protokół HTTP (ang. HyperText Transfer Protocol), zdefiniowany w [RFC2068]. Komunikacja między klientem a serwerem usługi odbywa się na zasadzie pytanie/odpowiedź i zazwyczaj wg następującego schematu:
Dokument odsyłany klientowi jest opatrzony tzw. nagłówkiem MIME, który definiuje jego typ. Dzięki temu przeglądarka WWW może taki dokument prawidłowo obsłużyć. Specyfikacja typów MIME jest opisana w [RFC2046].
Każdy dokument w WWW jest identyfikowany jednoznacznie przez tzw. URL (ang. Uniform Resource Locator). URL definiuje sposób dostępu do serwera, ścieżkę dostępu do dokumentu na tymże serwerze oraz opcjonalne parametry. W przypadku HTTP standardowy URL ma postać http://host/dokument. Jednak w przypadku powiązanych ze sobą dokumentów znajdujących się na tym samym serwerze, można używać samej ścieżki do dokumentu. Co więcej, ścieżka taka może zawierać odwołania względne (np. '..' oznacza nadkatalog). Dokładną specyfikację URL można znaleźć w [RFC1738].
Żądanie otrzymania dokumentu może nieść ze sobą dodatkowe parametry. Zazwyczaj są to zakodowane przez przeglądarkę informacje wpisane przez użytkownika w formularzach, ale mogą być to też parametry uruchamiania aplikacji internetowych. W HTTP używane są dwie metody przesyłania parametrów: GET i POST.
Parametry przesyłane metodą GET są dopisywane na końcu URL w zakodowanej postaci. Jest to metoda używana do przesyłania parametrów o niewielkim rozmiarze i nie wymagających tajności. W metodzie POST parametry są ukryte w zapytaniu do serwera i są używane do przesyłania większych ilości danych oraz danych wymagających tajności.
Serwer HTTP jest serwerem bezstanowym -- nie przechowuje żadnych danych na temat klientów usługi. Sesja związana z pamiętaniem stanu komunikacji z klientem jest otwierana tylko na czas transmisji pojedynczego dokumentu. Zaletą takiego rozwiązania są niskie wymagania pamięciowe i czasowe serwera, ale wadą jest znaczne utrudnienie realizacji bardziej zaawansowanych projektów. Dlatego też powstały tzw. ciasteczka (ang. cookies), czyli mechanizm przechowywania stanu klienta na lokalnej maszynie (por. [Nets-Cook]). Skrótowo można powiedzieć, że klient przy każdym odwołaniu do serwera HTTP wysyła mu łańcuch tekstowy, który otrzymał przy pierwszym odwołaniu. Dzięki ciasteczkom można m.in. zaimplementować mechanizm sesji albo zapamiętać preferencje użytkownika.
Istnieje również wersja HTTP obsługująca mechanizm szyfrowania, tzw. HTTPS. Komunikacja między serwerem a klientem odbywa się w standardowy sposób, ale połączenie jest szyfrowane przy pomocy protokołu SSL (ang. Secure Socket Layer). Specyfikacja tego protokołu znajduje się w [Nets-SSL].
Obecnie najszybszymi, najbardziej popularnymi i najbardziej zaawansowanymi technicznie serwerami HTTP na rynku są: Apache i Microsoft Internet Information Server (por. [Apache], [MS-IIS]). Wśród najlepszych serwerów HTTP jedynie Apache jest produktem darmowym (opartym na licencji GNU) i zajmuje pierwsze miejsce w większości rankingów.
Dokumenty wysyłane do klienta zazwyczaj nie są zwykłym tekstem. Zgodnie z ideą WWW, sposób zapisu dokumentów powinien umożliwiać hipermedialność, a jednocześnie być zrozumiały dla wszystkich przeglądarek.
Formatem dokumentów dedykowanym usłudze WWW jest język HTML (ang. HyperText Markup Language) oparty na metajęzyku SGML (ang. Standard Generalized Markup Language, por. [W3C-SGML]), międzynarodowym standardzie opisu dokumentów. Początkowo język ten miał definiować znaczenie tekstu, szybko jednak stał się językiem opisu wyglądu stron WWW. HTML cechuje się przede wszystkim prostotą i niezależnością od platformy. Dokument w języku HTML to zwykły tekst, którego fragmenty są ujęte w tzw. znaczniki. Znaczniki opisują formatowanie tekstu, definiują powiązania między dokumentami, tabele, rysunki itp. ([W3C-HTML]).
HTML jest rozwijany od 1989 roku, od 1993 roku oficjalnie przez W3 Consortium, a nieoficjalnie przez twórców przeglądarek. Obecnie obowiązująca wersja, HTML 4.01 (opisana w [W3C-HTML4]), udostępnia bardziej zaawansowane funkcje, jak np.:
![[*]](footnote.png) (por. [Nets-JS], [MS-JS]) oraz VBScript (por. [MS-VBS]),
(por. [Nets-JS], [MS-JS]) oraz VBScript (por. [MS-VBS]),
Liczba formatów obsługiwanych standardowo przez przeglądarki jest dosyć ograniczona -- potrafią one wyświetlić różne wersje HTML-a i zwykły tekst oraz wymienione wcześniej formaty graficzne. Wyświetlenie dokumentów zapisanych w mniej typowych formatach jest możliwe dopiero po zainstalowaniu w przeglądarce odpowiednich modułów, nazywanych plug-in lub add-in. Dotyczy to m.in. coraz popularniejszego formatu PDF (ang. Portable Document Format) opracowanego przez firmę Adobe. Jest to format najczęściej używany do prezentacji dokumentów przeznaczonych do druku, chociaż jego twórcy uwzględnili także obsługę hipertekstu.
Ostatnio bardzo popularne stały się również dokumenty stworzone w formacie Flash opracowanym przez firmę Macromedia. Format ten umożliwia przedstawienie w przeglądarkach interaktywnych prezentacji multimedialnych łączących w sobie grafikę, animacje, teksty, dźwięk i wideo. Zaletą prezentacji tworzonych w tym formacie jest ich stosunkowo mała objętość oraz bardzo efektowny wygląd. Dokumenty takie są również używane do tworzenia elementów nawigacyjnych, animacji reklamowych czy też gier.
Najnowsze przeglądarki potrafią również wyświetlić dokument zapisany w XML (ang. eXtensible Markup Language, por. [W3C-XML]). Jest to metajęzyk będący podzbiorem SGML-a, nad którym W3C rozpoczęło prace w 1998 roku. Według W3C ,,XML to uniwersalny format przechowywania ustrukturyzowanych dokumentów i danych w sieci WWW''. Jest to metajęzyk pozwalający tworzyć dokumenty o dowolnej strukturze logicznej, zdefiniowanej przez tzw. DTD (ang. Document Type Definition) lub utworzonej ad hoc.
Cechy odróżniające XML od czystego SGML-a to:
Główne zalety XML to:
XSL składa się z trzech części:
Pojedynczy szablon może tworzyć struktury o dużym stopniu złożoności. Może używać łańcuchów znakowych otrzymanych z określonych lokalizacji w drzewie źródłowym, czy też generować struktury powtarzające się w zależności od pojawiania się określonych elementów w drzewie źródłowym.
Lokalizacje elementów w drzewie źródłowym oraz dopasowywane wzorce są zapisane w języku XPath (por. [W3C-XPath]). Jest to język, którego głównym zadaniem jest adresowanie części dokumentów XML. Dodatkowo dostarcza on podstawowych funkcji służących do manipulacji na łańcuchach znaków, liczbach i wartościach logicznych oraz mechanizm umożliwiający użycie zmiennych. Język XPath traktuje dokument XML jako drzewo złożone z węzłów (ang. nodes). Wyróżnia się różne typy węzłów, m.in. węzły-elementy, węzły-atrybuty, węzły tekstowe. XPath definiuje sposób wyliczenia wartości znakowej z węzła każdego typu.
Koncepcja zawarta w XSL FO (por. [W3C-XSLFO]) to jeden z najbardziej rozwijających się obszarów specyfikacji XSL. Zdefiniowane w niej obiekty służą jako uniwersalne znaczniki formatujące, możliwe do zastosowania m.in w przekazach wizyjnych i w druku. Jest to jednak koncepcja bardzo młoda, a zarazem na tyle obszerna, że niewiele jest narzędzi, które potrafią wykorzystać ten powstający dopiero standard. Do nielicznych wyjątków należy np. napisany w języku Java i rozwijany przez Apache Software Foundation, produkt o nazwie FOP (por. [Apache-FOP]), który potrafi odpowiednio sformatowany obiekt XML zapisać we wcześniej już wspomnianym formacie PDF.
Lista standardów, które powstają w oparciu o XML jest długa. Najciekawsze z nich to XML Schema, który ma zastąpić bardzo ograniczony standard DTD oraz XML Query mający służyć do ekstrakcji danych z dokumentów XML na zasadach znanych z baz danych. Inne to np. XForms, XML Protocol, XML Encryption i XML Signature.
XML nie został zaprojektowany, żeby zastąpić HTML, ale żeby ułatwić składowanie i przetwarzanie informacji. Do wyświetlania dokumentów W3C rekomenduje obecnie język XHTML 1.0, który jest aplikacją XML ze znacznikami HTML, czyli -- w znacznej mierze upraszczając -- można go nazwać porządnym HTML-em. Kolejną aplikacją XML jest WML (ang. Wireless Markup Language) używany do wyświetlania stron w telefonach komórkowych i innych małych urządzeniach przenośnych. WML jest częścią protokołu WAP (ang. Wireless Application Protocol) będącego odpowiednikiem WWW dla takich właśnie urządzeń.
Istotnym problemem związanym z przechowywaniem, przetwarzaniem i prezentacją dokumentów jest obsługa specjalnych znaków diakrytycznych, tzn. nie występujących w angielskiej wersji alfabetu łacińskiego. Jest to problem, z którym informatycy z krajów nieanglojęzycznych, w tym z Polski, borykają sie od dosyć dawna. Przyczyną tego jest mocno zakorzeniony standard ASCII kodujący znaki na jednym bajcie, przy pomocy liczb z przedziału 0-127. Wśród tak kodowanych znaków te specjalne nie występują. Od dłuższego czasu funkcjonują rozwiązania polegające na użyciu tzw. kodowań, czyli tłumaczeń liczb z zakresu 128-255 na brakujące znaki. Obowiązującym standardem są kodowania ogłoszone przez organizację ISO (ang. International Organization for Standardization) oznaczone przedrostkiem ISO-8859. W Polsce obowiązuje standard ISO-8859-2, choć niestety nie wszyscy go respektują. Wadami tego rozwiązania jest mnogość standardów kodowania oraz niewielka liczba formatów umożliwiających połączenie tekstów zapisanych wg więcej niż jednego kodowania w jednym dokumencie. Dlatego też podjęto próby utworzenia jednego, wspólnego zestawu wszystkich znaków. Jedna z nich to projekt ISO 10646 zainicjowany przez ISO, druga to projekt Unicode zainicjowany przez zrzeszenie producentów wielojęzycznego oprogramowania -- Unicode Consortium. W 1991 roku twórcy obu projektów rozpoczęli współpracę, aby nie mnożyć liczby obowiązujących standardów. Od tej chwili standardy publikowane przez Unicode Consortium i ISO, mimo że niezależnie, są ze sobą w pełni zgodne.
Problemy związane ze specjalnymi znakami zdaje się rozwiązywać kodowanie UTF-8. Jest to standard zdefiniowany w ISO 10646-1:2000 Annex D, w [RFC2279] oraz w rozdziale 3.8 standardu Unicode 3.0.
UTF-8 ma następujące właściwości:
Oprócz serwowania statycznych stron, WWW od początku swojego istnienia umożliwiało serwowanie dynamicznej treści. Bez możliwości uruchamiania aplikacji po stronie serwera, WWW miałoby bardzo ograniczoną funkcjonalność. Pierwszą aplikacją generującą dynamiczną zawartość przez WWW była wyszukiwarka dokumentów zgromadzonych w CERN-ie, uruchomiona na pierwszym serwerze HTTP.
Aplikacje działające po stronie serwera umożliwiają m.in.:
Wysyłanie dynamicznej treści do klienta wcale nie jest trudnym do rozwiązania problemem. Umożliwiał to już pierwszy służący do tego interfejs, CGI (ang. Common Gateway Interface, por. [W3C-CGI]).
Aplikacje CGI mogą być napisane w dowolnym języku, w szczególności mogą to być programy zapamiętane w postaci skompilowanej. CGI zapisuje parametry wołania na zmienne środowiskowe lub przekazuje je przy pomocy standardowego wejścia. Parametry te są zakodowane w ustalony sposób. Wynik działania aplikacji, ew. poprzedzony serią nagłówków HTTP, jest wyświetlany w przeglądarce klienta.
Oprócz zalet CGI, czyli prostoty, niezależności od języka i platformy, ujawniła się jednak duża wada, która spowodowała, że interfejs ten okazał się niewystarczający: każde zapytanie do serwera odwołujące się do aplikacji CGI wiązało się z koniecznością utworzenia nowego procesu. Przy dużym obciążeniu serwera aplikacje CGI stawały się wąskim gardłem.
Rozpoczęto prace nad interfejsem FastCGI (por. [FastCGI]), różniącym się od CGI tym, że procesy po wysłaniu dokumentu nie kończą pracy, lecz oczekują na nadejście kolejnego żądania. Programy wykorzystujące interfejs FastCGI muszą używać niestandardowego zestawu funkcji wejścia-wyjścia i dodatkowej pętli. Mimo konieczności poprawienia aplikacji, FastCGI jest rozwiązaniem najprostszym z możliwych.
W przypadku aplikacji zapisanych w językach skryptowych, o najbardziej wydajną komunikację z serwerem HTTP powinien zadbać odpowiedni interpreter. Większość popularnych interpreterów języków skryptowych występuje także w postaci modułów do różnych serwerów HTTP. Na przykład do serwera Apache dostępne są m.in. moduły mod_perl i mod_php, odpowiedzialne za uruchamianie programów w językach Perl i PHP. Możliwe jest też dołączenie własnych modułów przy pomocy Apache API (por. [Apache-API]). Z kolei aby podłączyć moduł do Microsoft IIS, należy posłużyć się ISAPI (por. [MS-ISAPI]). W ten sposób jest podłączony m.in. interpreter języka ASP.
Podłączenie interpreterów jako modułów serwera HTTP jest bardzo korzystne, ponieważ eliminuje podstawową wadę CGI, umożliwiając do tego pełniejszą i jeszcze szybszą niż dla FastCGI komunikację między aplikacją a serwerem. Wadą jest mała przenośność tego rozwiązania, jednak większość dobrych interpreterów posiada odpowiednie API zarówno dla serwera Apache, jak i dla IIS.
Perl (por. [Perl]) jest najstarszym językiem skryptowym używanym nie tylko do generacji stron WWW. Powstał w 1987 roku na zasadach Otwartego Oprogramowania (ang. Open Source, por. [OpenSource]), a jego interpreter jest darmowy. Perl jest językiem bardzo prostym, jednak jego użycie przy bardziej zaawansowanych projektach jest dosyć uciążliwe, głównie przez dosyć niską czytelność kodu. Język ten charakteryzuje się bardzo mocnym zestawem funkcji służących do operacji na łańcuchach znakowych, także przy użyciu wyrażeń regularnych. Liczba bibliotek dostępnych dla Perla jest bardzo duża. Biblioteki te charakteryzują się dużą funkcjonalnością, ale nie są dostępne standardowo i nie są dobrze udokumentowane. Perl posiada wsparcie dla interfejsu ISAPI oraz serwera Apache. Wadą Perla jest jego nienajlepsza skalowalność. Ostatnio jego popularność maleje, głównie na rzecz PHP.
PHP (por. [PHP]) powstał w 1994 na zasadach Otwartego Oprogramowania. Jego interpreter jest darmowy, ale dodatkowe moduły są płatne. Dotyczy to m.in. modułu Zend Accelerator (por. [PHP-ZAcc]) podnoszącego wydajność PHP, ale istnieją już jego darmowe odpowiedniki -- APC (por. [PHP-APC]), afterBURNER*Cache (por. [PHP-BWC]) i PHP Accelerator (por. [PHP-Acc]). Sam język powstał na bazie wielu innych języków, m.in. Perla, specjalnie do tworzenia dynamicznych stron WWW. PHP jest bardzo prostym językiem, nie sprawiającym większych problemów nawet przy stosowaniu go przy bardziej zaawansowanych projektach. Liczba bibliotek dla PHP jest bardzo duża, a większość z nich jest dołączona do standardowej dystrybucji. Biblioteki te charakteryzują się bardzo dużą funkcjonalnością. Zarówno język, jak i biblioteki są bardzo dobrze udokumentowane. PHP posiada wsparcie dla interfejsu ISAPI oraz serwera Apache. Podobnie jak w przypadku Perla, wadą PHP jest jego nienajlepsza skalowalność. Ponadto przy bardziej obciążonych stronach, nie wyposażony w moduły akcelerujące PHP staje się mało wydajny. Prace nad poprawieniem jego wydajności trwają. Od niedawna PHP umożliwia programowanie obiektowe, jednak na bardzo niskim poziomie zaawansowania. Mimo to jego popularność rośnie w szybkim tempie.
JSP (ang. Java Server Pages) są częścią J2EE (por. [Sun-J2EE]), stanowiącego pakiet specyfikacji oparty na technologii Java, wyprodukowany w 1998 roku przez Sun Microsystems. Środowiska programistyczne dla tej platformy są dostępne za darmo, ale za serwery aplikacji trzeba płacić. Istnieje jednak darmowy serwer aplikacji JSP o nazwie Tomcat (por. [Apache-Tomcat]) rozwijany przez Apache Software Foundation na zasadach Otwartego Oprogramowania. Siłę JSP stanowi używany język -- JavaScript, dzięki któremu rozwiązanie to jest bardzo łatwo przenośne. Ponadto programy mogą korzystać z ogromnej liczby bibliotek napisanych w języku Java, dzięki czemu mają bardzo duże możliwości. Rozwiązania oparte na J2EE są też dosyć łatwo skalowalne. Wady to bardzo duże wymagania sprzętowe oraz dosyć wysoki stopień skomplikowania kodu. Dlatego też J2EE sprawdza się w dużych przedsiębiorstwach, w długoterminowych i skomplikowanych projektach.
ASP (ang. Active Server Pages) stanowiące część środowiska .NET (por. [MS-NET]), są odpowiednikiem JSP rozwijanym przez Microsoft Corporation od 1996 roku. Część składników jest dołączana do systemów operacyjnych Microsoftu za darmo, za niektóre trzeba płacić. W ASP używa się języka VBScript o podobnym stopniu złożoności co JavaScript. Przenośność tego rozwiązania jest zdecydowanie gorsza, ponieważ .NET działa tylko na platformach Microsoftu. Oferowana jest za to bardzo duża liczba bibliotek umożliwiających m.in. bardzo szybkie tworzenie najbardziej standardowych aplikacji WWW.
Produkt ColdFusion (por. [Macr-CF]) prezentuje zupełnie odmienną koncepcję budowy aplikacji WWW. Jest to produkt płatny, rozwijany od 1995 roku przez firmę Allaire, a obecnie przez firmę Macromedia. Program napisany przy użyciu ColdFusion jest zdefiniowany przy pomocy specjalnych znaczników zanurzonych w kodzie HTML. Dzięki temu tworzenie aplikacji na tej platformie jest bardzo łatwe i szybkie, a kod jest bardzo czytelny. Na uwagę zasługuje też bardzo bogate i intuicyjne graficzne środowisko programistyczne, dzięki któremu aplikację może stworzyć osoba nie mająca nawet odpowiedniej wiedzy na temat programowania. Wadami tego rozwiązania jest brak bardziej zaawansowanych funkcji oraz brak możliwości dodawania własnych rozszerzeń i definiowania własnych funkcji. To powoduje, że ColdFusion nadaje się jedynie do prostych serwisów, nie wymagających bardziej zaawansowanych technologii.
Bardziej zaawansowane aplikacje muszą składować i przetwarzać większe ilości danych. Dotyczy to również tych najczęściej spotykanych aplikacji WWW, jak wyszukiwarki, katalogi stron, rankingi, moduły personalizacji, systemy ochrony dostępu itp. Ilość informacji, jaką aplikacje muszą zgromadzić i przetwarzać ma zazwyczaj tendencję do przyrastania. Konieczne więc staje się takie projektowanie aplikacji, aby funkcje składowania i operacji na danych wykonywały wyspecjalizowane serwery bazodanowe.
Wybór odpowiedniego serwera nie jest zazwyczaj łatwą do rozstrzygnięcia kwestią. Serwer bazy danych dla aplikacji WWW powinien obsługiwać standard SQL, być wystarczająco szybki i łatwo osiągalny z wybranej platformy programistycznej. W zasadzie wszystkie znane serwery posiadają takie cechy. Różnią się natomiast cenami, prędkością oraz możliwością wykonywania bardziej zaawansowanych funkcji. Jednak aplikacje WWW z reguły nie potrzebują zaawansowanych funkcji. Większość operacji jakie wykonuje się na bazie danych używanej w serwisie WWW to zapytania. Operacje zapisu do bazy występują o wiele rzadziej, nie jest też potrzebna obsługa transakcji. Dzięki temu serwer bazy danych używany przez aplikacje WWW może być mniej wyrafinowany, ale za to tańszy.
Najbardziej znanymi prostymi serwerami bazodanowymi, opartymi na zasadach Otwartego Oprogramowania (a więc darmowymi), są PostgreSQL (por. [PgSQL]) i MySQL (por. [MySQL]). Oba obsługują standard SQL. PostgreSQL dostarcza bardziej zaawansowanych funkcji i jest wygodny w użyciu. Obsługuje też transakcyjność. Serwer MySQL sprawia czasami trudności w użyciu, brakuje mu niektórych bardzo podstawowych funkcji, jest za to jednym z najszybszych darmowych serwerów baz danych. W miarę popularny jest też mSQL (por. [MSQL]), ale nie jest on w pełni zgodny ze standardem SQL i jest dosyć prymitywny.
W rozdziale tym przedstawimy wymagania stawiane przed portalami internetowymi oraz narzędziami służącymi do ich budowy. Scharakteryzujemy istniejące na rynku rozwiązania. Następnie opiszemy wymagania stawiane przed narzędziem do budowy portali XMportal oraz portalem Wydziałowy Portal Internetowy, które są wynikami naszej pracy.
Sprecyzowanie wymagań stawianych portalowi jest zadaniem niezwykle trudnym. Nie istnieje jednoznaczna definicja pojęcia Portal Internetowy. Jest to spowodowane świeżością tematu i stale poszerzającym się zakresem, jaki obejmuje.
Początki portali internetowych związane są z wyszukiwarkami, które zaczęto obudowywać aplikacjami mającymi zwiększyć atrakcyjność serwisu i co za tym idzie liczbę gości i reklam. Później zaczęły powstawać duże serwisy internetowe, w których wyszukiwarka była już tylko jednym z elementów, bynajmniej nie najważniejszym. Portale szybko zaczęły się specjalizować.
Dziś można wyróżnić cztery podstawowe rodzaje portali internetowych, które omawiamy w kolejnych punktach.
Portale poziome (ang. horizontal portals) to typowe serwisy internetowe, nastawione na pozyskanie jak największej liczby klientów i związanych z tym zysków. Efektem tego jest zwykle olbrzymia liczba oferowanych usług i przykuwający uwagę wygląd (ta zasada powoli ustępuje priorytetowi szybkości działania systemu). Przykładami serwisów tego typu są Yahoo!, Excite, MSN, Netscape Netcenter, AOL oraz Onet i Wirtualna Polska. Większość klientów traktuje je jako bramę wiodącą do Internetu, miejsce od którego zaczynają przeglądanie stron w Internecie.
Większość dużych portali oferuje:
Dostęp do tego typu portali jest zwykle darmowy. Dochody pozyskiwane są z reklam i prowizji od sklepów internetowych. Ciekawostką jest to, że na razie większość dużych portali tego typu przynosi olbrzymie straty.
Wortale lub portale pionowe (ang. vertical portals) to specjalistyczne (niszowe) portale internetowe. Są zwykle skierowane do konkretnego klienta. Przykładem tego typu serwisów mogą być bardzo popularne portale ekonomiczne. Kolejne przykłady to serwisy dla miłośników ogrodnictwa (http://garden.com), administratorów sieci (http://SearchNetworking.com). Różnica między wortalem i klasycznym portalem internetowym leży głównie w zawartości. Choć również są one efektowne graficznie, to jednak pierwszoplanowa jest zawartość. Wortale posiadają nieco mniejszą liczbę aplikacji. Bardzo rzadko trafia się na wortale oferujące bezpłatne strony domowe czy konta poczty elektronicznej.
Portale korporacyjne (ang. Enterprise Resource Portal, w skrócie ERP, lub Enterprise Information Portal, w skrócie EIP) wywodzą się z tradycyjnego Intranetu. Międzynarodowe korporacje są dziś małymi państwami. Potrzebują więc bardzo dostępu do jednakowej informacji, niezależnie od miejsca, z którego się jej poszukuje. Użytkownikami tych systemów są najczęściej pracownicy przedsiębiorstwa. Jednak często udostępnia się je również klientom, partnerom biznesowym, a czasem nawet ludziom nie związanym z przedsiębiorstwem. Dostęp do wiedzy, aplikacji i wiadomości jest zależny od stopnia posiadanych uprawnień. Cechą różniącą portale korporacyjne od tradycyjnych portali jest położenie bardzo dużego nacisku na ochronę danych oraz możliwość umieszczania w nich bardzo zaawansowanych aplikacji bazodanowych.
Podstawowe cechy systemów ERP to:
Portale B2B (ang. business to business) są tym dla portali korporacyjnych, czym wortale dla tradycyjnych portali. Mają służyć polepszaniu (poszerzaniu) kontaktów i wymianie handlowej. Odbiorcą informacji zawartych w tym systemie jest zwykle ktoś z zewnątrz, np. klient lub partner biznesowy.
Ważne są tu rozwiązania zapewniające właściwy obieg dokumentów (umowy, zamówienia, faktury) między podmiotami kupującymi i sprzedającymi.
Na rynku istnieją następujące rodzaje portali B2B:
Różne rodzaje portali są skierowane do różnych grup klientów. Wymusza to stosowanie różnej technologii przy ich tworzeniu i odmiennego podejścia przy projektowaniu. Cechy wspólne, łączące wszystkie rodzaje portali, dotyczą strony technicznej. Każdy portal powinien:
Na rynku istnieją dziesiątki dużych narzędzi służących do budowy portali internetowych. Pojęcie narzędzia jest jednak trochę mylące. Najczęściej nie są to produkty służące tylko do zaprojektowania i wykonania portalu. Przez pojęcie narzędzia rozumie się zwykle środowisko portalowe zawierające:
Wymagania stawiane przed narzędziami portalowymi są podobne do wyżej opisanych wymagań dotyczących portali. Podstawowym wymaganiem jest umożliwienie łatwej i wygodnej budowy możliwie zaawansowanych portali. Kolejnym wymaganiem jest dostarczenie wygodnych narzędzi do administrowania portalem.
Właściwie jedynym wymaganiem dotyczącym narzędzi portalowych, które nie zostało wymienione w trakcie opisywania oczekiwań względem portali jest dostarczenie narzędzi pomagających budować dokumenty i aplikacje internetowe bez znajomości jakiegokolwiek języka programowania. Ma to umożliwić administrowanie portalem i rozwijanie go osobom nie posiadającym przygotowania informatycznego.
Najbardziej znane narzędzia portalowe to WebSphere Portal Server [IBM-WAS], Oracle9iAS Portal [Oracle-9iAS] oraz Microsoft Commerce Server [MS-IIS]. Są to duże, komercyjne rozwiązania przeznaczone dla przedsiębiorstw. Wszystkie mają podobną, opisaną wcześniej strukturę. Jako że narzędzia te zostały stworzone przez duże przedsiębiorstwa, ogromne znaczenie ma integracja z innymi ich produktami. Dzięki temu w aplikacjach portalowych możemy korzystać z innych narzędzi danego producenta. Możemy zanurzyć w portalu aplikacje umożliwiające zaawansowane raportowanie (agregowanie danych, obsługa zapytań), obsługę baz i hurtowni danych.
Wynikiem naszej pracy magisterskiej ma być Wydziałowy Portal Internetowy wykonany przy pomocy narzędzia XMportal i wdrożony na Wydziale MIM Uniwersytetu Warszawskiego. Można go zakwalifikować jako wortal, ewentualnie jako bardzo prosty system typu ERP. Nie jest to komercyjny portal, więc funkcje typu sklep internetowy, reklamy i darmowe strony internetowe nie mają tu większego sensu.
Pierwszym etapem prac przy budowie portalu było określenie wymagań dotyczących środowiska portalowego. Wymagania te były potem konsultowane z wydziałowym opiekunem stron internetowych.
Ustaliliśmy, że środowisko portalowe ma pozwalać na:
.
Podstawowe elementy narzędzia XMportal to jądro portalu oraz zestaw narzędzi aministratorskich. Jak widać jest to typowe rozwiązanie, w którym narzędzie użyte do budowy portalu jest ściśle zintegrowane z budowanym portalem.
XMportal może zostać użyty do budowy dowolnych typów portali internetowych. Nie należy jednak zapominać, że podstawowym wymaganiem postawionym przed naszym narzędziem było wykonanie Wydziałowego Portalu Internetowego. Wynika stąd, że choć stworzenie dowolnego typu portalu jest możliwe, to może wymagać dużo pracy. Jest to spowodowane tym, że zestaw aplikacji dołączony do narzędzia jest wystarczający dla serwisu uniwersyteckiego, ale niewystarczający np. dla aplikacji B2B.
Drugim niezwykle istotnym założeniem jest rozszerzalność systemu. Umożliwiamy łatwe poszerzanie listy standardowych aplikacji dołączanych do narzędzia oraz rozszerzanie funkcjonalności jądra o obsługę nowych internetowych języków programowania.
Kolejnym założeniem jest darmowość wszystkich elementów użytych do budowy systemu.
Ostatnim wymaganiem jest wydajne i szybkie działanie portali stworzonych przy pomocy narzędzia XMportal. Oznacza to, że narzuty związane z przetwarzaniem dokumentów przez jądro powinny być niewielkie.
XMportal ma rozróżniać dwie podstawowe role:
W tym rozdziale opiszemy projekt narzędzia XMportal. Przedstawimy jego architekturę i schemat przetwarzania, omówimy koncepcje zastosowane w projekcie oraz zaprezentujemy logiczny model danych.
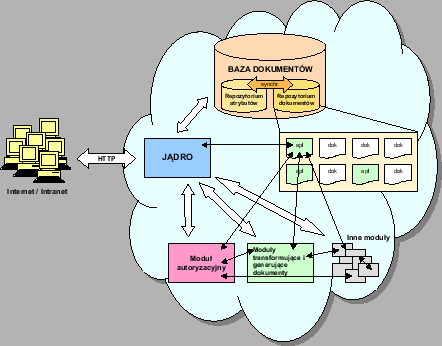
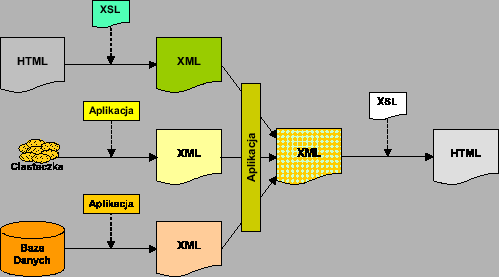
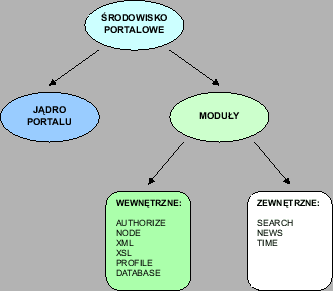
Portal zbudowany przy pomocy narzędzia XMportal będzie się składać z jądra, modułów i bazy dokumentów. Jądro to program odpowiadający za prawidłowe wyświetlanie dokumentów i aplikacji w portalu. Moduły to pakiety funkcji wykorzystywane przez jądro i aplikacje. Baza dokumentów ma przechowywać wszystkie informacje dotyczące dokumentów i aplikacji zanurzonych w portalu. Narzędzie administratorskie będzie jedną z aplikacji zanurzonych w systemie. Schemat struktury portalu przedstawiono na rysunku 3.1.
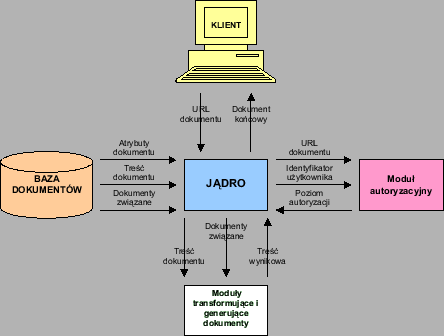
Jądro portalu będzie najważniejszym elementem środowiska portalowego. Będzie to program uruchamiany przy każdym odwołaniu się do portalu. Zadaniem jądra będzie połączenie się z bazą dokumentów i sprawdzenie, czy dokument istnieje. Następnie jądro sprawdza, czy użytkownik ma prawo dostępu do tego dokumentu. Jeśli tak, to korzystając z informacji zapisanych w bazie dokumentów jądro ma wygenerować dokument wynikowy. Jeśli nie, to zostanie wygenerowany komunikat z informacją o błędzie. Dokument wynikowy będzie się składać z dokumentu głównego otoczonego aplikacjami. Za sposób generacji otoczenia dokumentu również odpowiada jądro. Wygenerowany dokument wynikowy będzie wysłany do przeglądarki użytkownika.
Jądro będzie też odpowiadać za komunikację między bazą dokumentów a aplikacjami. To jądro ma otwierać połączenie z bazą danych, zgodne z uprawnieniami posiadanymi przez użytkownika.
Moduły to pakiety funkcji wykorzystywane przez jądro i aplikacje. Dzielą się one na dwie części: wewnętrzne i zewnętrzne.
Moduły wewnętrzne będą zawierać funkcje niezbędne do prawidłowego działania portalu. Będą one wykorzystywane przez jądro portalu i aplikację administratorską. Mogą zostać również wykorzystane przez aplikacje zewnętrzne. W zestawie modułów wewnętrznych znajdować się będą:
,
Moduły zewnętrzne będą służyć do obsługi konkretnych aplikacji. Przewiduje się powstanie modułów potrzebnych do obsługi:
Najprostsze rozwiązania dotyczące przechowywania dokumentów serwisów WWW to umieszczenie ich w zwykłych plikach dyskowych lub w relacyjnej bazie danych. Oba rozwiązania mają swoje zalety i wady.
W przypadku przechowywania dokumentów w całości w plikach powstaje problem z przechowywaniem atrybutów tych dokumentów (m.in. sposób wyświetlania, informacje dla modułu autoryzacji itp.). Zazwyczaj takie informacje są przechowywane w specjalnych plikach, jednak znacznie utrudnia to ich przetwarzanie. Dlatego też w bardziej zaawansowanych serwisach nie stosuje się tego rozwiązania. Z kolei jeśli wszystkie dane zostaną umieszczone w bazie danych, to administrator będzie miał do nich znacznie utrudniony dostęp.
Bardziej elastyczne jest rozwiązanie hybrydowe -- dokumenty są przechowywane w plikach, natomiast atrybuty dokumentów w bazie danych. Problem, który się pojawia w takiej sytuacji to redundancja przechowywanych danych -- dokumenty serwisu znajdujące się w plikach muszą być zarejestrowane w bazie. W takim wypadku o spójność danych powinny dbać odpowiednie aplikacje synchronizacyjne.
Oto krótkie porównanie trzech wspomnianych rozwiązań:
| Pliki | Baza danych | Hybrydowe | |
|---|---|---|---|
| dostęp do dokumentów przez administratora | łatwy | utrudniony | łatwy |
| dostęp do atrybutów przez administratora | łatwy | utrudniony | utrudniony |
| dostęp do dokumentów przez system | łatwy | łatwy | łatwy |
| dostęp do atrybutów przez system | utrudniony | łatwy | łatwy |
| przejrzystość struktury | duża | mała | duża |
| podatność na błędy | duża | mała | średnia |
| naprawa błędów | utrudniona | łatwa | łatwa |
| dowolność definiowania atrybutów | duża | mała | mała |
| przetwarzanie dokumentów | utrudnione | łatwe | utrudnione |
| przetwarzanie atrybutów | utrudnione | łatwe | łatwe |
W naszym projekcie zdecydowaliśmy się na użycie rozwiązania hybrydowego. Powodem była chęć zapewnienia administratorom jak największej wygody korzystania z tworzonych serwisów z jednoczesnym ułatwieniem implementacji wydajnego jądra i aplikacji WWW. Dostęp do atrybutów ma zapewniać aplikacja administratorska, a spójność danych przywracać automatycznie aplikacja synchronizacyjna, uruchamianą na życzenie administratora. Aplikacje WWW, zanurzone w tworzonych serwisach, powinny mieć do dyspozycji funkcje udostępniające dokumenty i związane z tymi dokumentami atrybuty oraz funkcje służące do przetwarzania dokumentów.
W ramach narzędzia XMportal postanowiliśmy zaprojektować i zaimplementować funkcje, moduły i aplikacje dla jednego z najpopularniejszych i najprostszych w użyciu języków skryptowych używanych w WWW. Miałyby one zapewnić funkcjonalność potrzebną w każdym zaawansowanym serwisie -- od autentykacji i autoryzacji, przez personalizację, wyszukiwarkę i bazę dokumentów, po funkcje pomocnicze dla aplikacji.
Po przeanalizowaniu wymagań stawianych narzędziu oraz zapoznaniu się z dostępnymi technologiami i rozwiązaniami przyjęliśmy koncepcje realizacji projektu opisane w kolejnych punktach.
Wybór formatu przechowywania dokumentów jest newralgicznym punktem w realizacji każdego projektu WWW. Format dokumentów jest podstawowym czynnikiem decydującym o późniejszej elastyczności narzędzia i możliwościach jego łatwej rozbudowy. Wybrany format powinien być łatwy w przetwarzaniu, ale też jednocześnie umożliwiać realizację bardziej zaawansowanych funkcji niskim kosztem.
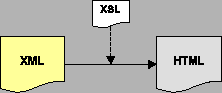
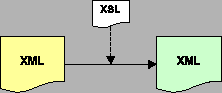
Dlatego za preferowany format przechowywania dokumentów przyjęliśmy dowolne aplikacje języka XML (w tym XHTML). O wyborze zadecydowała popularność i prostota tego standardu, możliwość jego konwersji do języka HTML na wiele różnych sposobów, duża liczba związanych z nim narzędzi oraz inne liczne zalety. Dodatkowo aplikacje działające po stronie serwera mogłyby korzystać z języka XPath, w celu ekstrakcji wybranych fragmentów dokumentów. Zgodnie ze standardem, sposób wyświetlania dokumentów zapisanych w XML określałyby przypisane do nich arkusze stylów XSLT. Natomiast przeglądarki WWW otrzymywałyby już wynik transformacji XSLT, którym najczęściej byłby dokument zapisany w języku HTML.
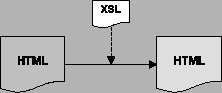
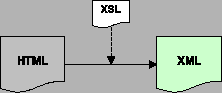
Za drugi z preferowanych formatów przyjęliśmy HTML, głównie w celu zachowania wstecznej zgodności z istniejącymi już serwisami WWW. Konwersja dokumentów z języka HTML do XML mogłaby się okazać skomplikowana, a do tego dosyć czasochłonna i trudno odwracalna. Jako dodatkową funkcjonalność założyliśmy możliwość transformacji dokumentów HTML arkuszami stylów XSLT -- w miarę możliwości technicznych oferowanych przez wybrane środowisko programistyczne. Funkcjonalność taka nie jest zgodna ze standardem, ale byłaby bardzo pożądana.
Zarówno dokumenty XML, jak i HTML będą mogły być zapisane w dowolnym obsługiwanym standardowo kodowaniu znaków, w tym także w UTF-8 oraz ISO-8859-2. Kodowanie to powinno być wyspecyfikowane w dokumencie, w przeciwnym wypadku zakładane będzie kodowanie domyślne (UTF-8 dla dokumentów XML oraz ISO-8859-2 dla dokumentów HTML). Sposób kodowania znaków w dokumencie umieszczonym w bazie będzie niezależny od sposobu kodowania znaków w dokumencie przeznaczonym do wyświetlenia w przeglądarce klienta.
Wybór konkretnych formatów przechowywania dokumentów nie powinien ograniczać użytkownika końcowego. Zatem powinna istnieć możliwość umieszczenia w serwisie plików we wszystkich pozostałych formatach, chociaż nie będą one podlegać żadnym transformacjom. Powinna również istnieć możliwość przesłania do przeglądarki WWW dokumentów XML i HTML bez ich transformacji arkuszami stylów XSLT.
Narzędzie XMportal powinno generować strony w języku HTML oraz dowolnych aplikacjach języka XML, więc odbiorcami serwisów zbudowanych przy jego pomocy będą m.in. dowolne przeglądarki WWW i WAP. Postać generowanego kodu HTML i XML będzie zależała w głównej mierze od administratora serwisu -- to on będzie decydował o końcowym wyglądzie publikowanych stron. W skrajnym przypadku administrator będzie mógł posłużyć się narzędziem XMportal do zbudowania serwisu udostępniającego wyłącznie statyczne dokumenty, wzbogaconego jedynie o funkcje autentykacyjne i autoryzacyjne.
Aplikacja administratorska przeznaczona dla administratorów serwisów powinna generować dokumenty zgodne ze standardem HTML 3.2 i być możliwa do używania we wszystkich nowszych graficznych przeglądarkach WWW.
Dokumenty w wielu nowszych serwisach WWW są osiągalne przez specjalne skrypty, które otrzymują identyfikator dokumentu do wyświetlenia w postaci parametru GET lub POST. My zdecydowaliśmy się na rozwiązanie polegające na identyfikacji wszystkich dokumentów przy pomocy standardowego URL. Takie rozwiązanie ma wiele zalet, m.in.:
Dokumenty znajdujące się w serwisie nie będą musiały być wysyłane w takim formacie, w jakim są przechowywane. Jądro portalu będzie transformować je w zdefiniowany przez administratora sposób, otaczając je elementami graficznymi i aplikacjami. Dokument nie zostanie w ogóle wysłany, gdy użytkownik nie będzie posiadał do niego stosownych uprawnień.
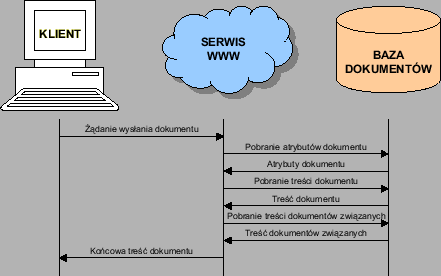
Typowy scenariusz interakcji serwisu WWW z przeglądarką klienta jest pokazany na rysunku 3.2.
Sposób transformacji dokumentu będzie zdefiniowany przez związane z nim dokumenty. Do takich dokumentów należą m.in.:
Informacje o statycznych dokumentach i aplikacjach zanurzonych w portalu będą przechowywane w bazie dokumentów. Wymaga to zaprojektowania właściwego modelu danych umożliwiającego przechowanie informacji o:
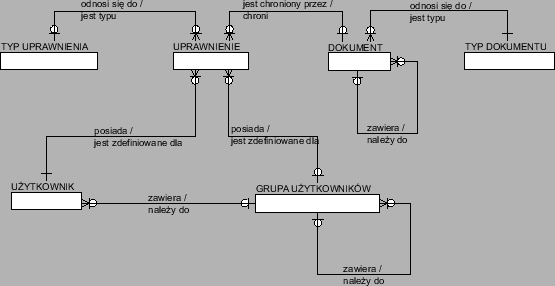
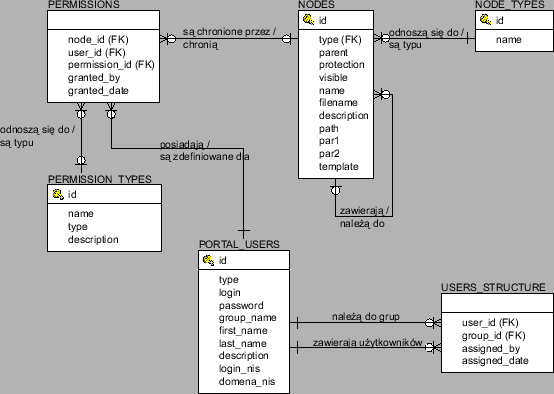
Logiczny model danych spełniających te wymagania przedstawiono na rysunku 3.4.
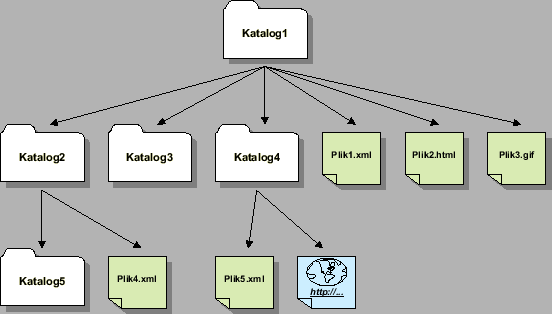
Podstawowe informacje dotyczące dokumentów będą reprezentowane przez encję DOKUMENT. Znajdą się w niej informacje o hierarchi, fizycznym położeniu i sposobie wyświetlania dokumentów. Katalogi będą szczególnym rodzajem dokumentów. Będą one mogły być przywiązane do dowolnej liczby innych dokumentów. Przykładową strukturę dokumentów przedstawiono na rysunku 3.5. Dokumentami w systemie będą katalogi, pliki i dowiązania internetowe.
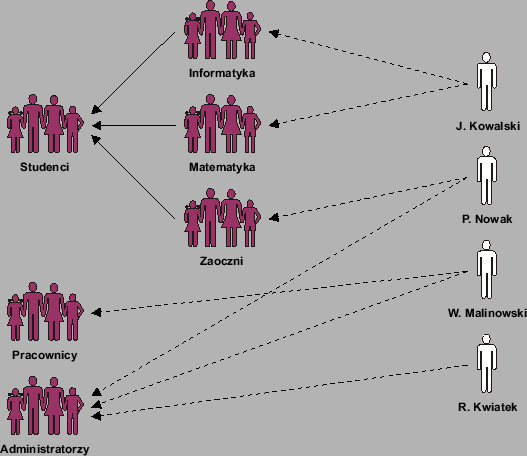
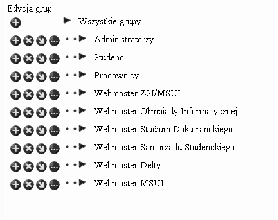
Informacje o użytkownikach będą reprezentowane przez encję UŻYTKOWNICY. Znajdą się tam informacje o każdym użytkowniku uprawnionym do korzystania z chronionej części serwisu. Użytkownicy będą mogli należeć do dowolnej liczby grup. Grupy będą miały strukturę hierarchiczną. Przynależność użytkownika do danej grupy będzie implikować przynależność do wszystkich jej nadgrup. Przykładowe przypisanie użytkowników do grup przedstawiono na rysunku 3.6. Użytkownik J. Kowalski należy do grup Informatyka i Matematyka. Grupy te są podgrupami grupy Studenci. Oznacza to, że J. Kowalski będzie przez system traktowany tak, jakby należał do grup Informatyka, Matematyka oraz Studenci.
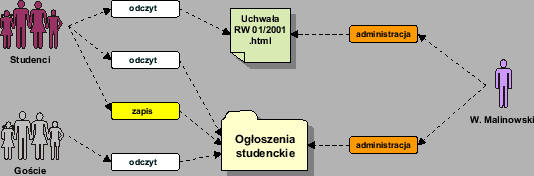
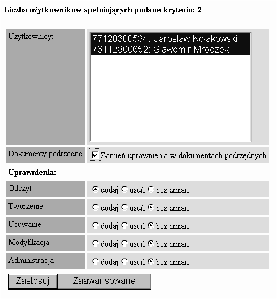
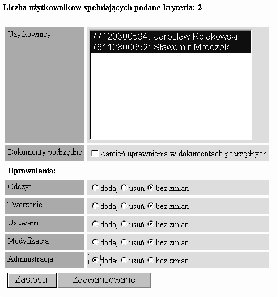
Informacje o istniejących w systemie uprawnieniach będą reprezentowane przez encję TYP UPRAWNIENIA. W encji UPRAWNIENIE będzie się znajdować informacja o przypisaniu uprawnień do konkretnych dokumentów dla konkretnych użytkowników. Przykład takiego przypisania przedstawiono na rysunku 3.7. Użytkownicy należący do grup Goście i Studenci mają prawo czytać dokumenty znajdujące się w katalogu Ogłoszenia studenckie. Użytkownicy należący do grupy Studenci mogą wysyłać nowe ogłoszenia. Natomiast użytkownik W.Malinowski może administrować ogłoszeniami.
W tym rozdziale opiszemy rozwiązania techniczne, których użyliśmy do implementacji narzędzia XMportal.
Wybór niektórych technologii do naszego projektu nie przedstawiał żadnych trudności, natomiast w przypadku innych okazał się dosyć trudny.
Jako serwer HTTP wybraliśmy serwer Apache -- najlepszy z dostępnych na rynku, a jednocześnie całkowicie darmowy. Ponadto wiele dostępnych środowisk programistycznych umożliwia uruchamianie aplikacji wewnątrz modułu serwera Apache -- procesy nie są tworzone przy każdym zapytaniu klienta. W trakcie implementacji projektu najnowszą wersją był Apache 1.3.20.
Serwer bazy danych wybieraliśmy spośród trzech całkowicie darmowych, popularnych rozwiązań obecnych na rynku: PostgreSQL, MySQL i mSQL. Decydującym kryterium była dla nas prędkość działania serwera, więc zdecydowaliśmy się oprzeć bazę danych na serwerze MySQL -- najszybszym z nich, a jednocześnie wystarczająco zaawansowanym technologicznie. W trakcie implementacji projektu aktualną wersją był MySQL 3.23.41.
Środowisko programistyczne, którego mieliśmy używać w naszym projekcie musiało charakteryzować się następującymi cechami:
Żadne z tych trzech rozwiązań nie ustępuje pozostałym pod względem liczby i funkcjonalności bibliotek służących do komunikacji z bazą danych. Współpraca z bazą danych jest podstawowym wymaganiem stawianym obecnie środowiskom programistycznym służącym do budowy aplikacji WWW.
W przypadku bibliotek zapewniających obsługę XML i XSLT sytuacja przedstawia się podobnie. Dla każdej z tych platform istnieją biblioteki umożliwiające zarówno manipulację dokumentami XML, jak i transformacje z użyciem arkuszy stylów XSLT. Jednak gdy potrzebne są funkcje służące do manipulacji dokumentami XML w podejściu obiektowym, okazuje się, że jedynie technologia Java jest w stanie bezproblemowo spełnić to wymaganie.
Dokumentacja języka i bibliotek jest najobszerniejsza i najłatwiej dostępna w przypadku PHP. Oprócz wyczerpującej dokumentacji producenta, w Internecie można znaleźć wiele stron poświęconych tej platformie, z dużą liczbą porad i przykładów. Dokumentacja dla Perla i Javy jest znacząco gorzej dostępna.
Duża prostota języka jest zaletą Perla i PHP, przy czym ten pierwszy uważany jest za mniej czytelny. Natomiast w przypadku Javy implementacja nawet prostych aplikacji wymaga znacznie większych umięjętności, lepszego przygotowania oraz więcej czasu.
Wydajność wszystkich trzech języków jest do siebie bardzo zbliżona, o ile testy przeprowadzane są na szybkich maszynach. Mimo to Java uznawana jest za rozwiązanie o wiele wolniejsze od pozostałych, co uwidacznia się na serwerach o gorszych parametrach lub o większym obciążeniu. Wydajność Perla i PHP jest porównywalna, przy czym przewaga jednego rozwiązania nad drugim w głównej mierze zależy od jego konfiguracji. Częściej za szybsze uznawane są rozwiązania oparte na Perlu.
Perl, jako środowisko bardzo podobne do PHP, a jednocześnie nie przewyższające PHP w żadnej z wymienionych cech (może z wyjątkiem nieznacznie lepszej wydajności), został przez nas odrzucony. Dlatego ostateczny wybór był dokonywany między PHP a Javą. Biorąc pod uwagę wymienione wcześniej cechy, Java imponuje jedynie bogactwem i profesjonalizmem bibliotek do obsługi standardów XML i XSLT. W PHP natomiast najbardziej razi niski poziom zaawansowania rozszerzeń do obsługi tych standardów. Jednak możliwość takiej obsługi ma być jedynie środkiem do osiągnięcia celu, a nie celem samym w sobie. Ostatecznie więc zdecydowaliśmy się na użycie w naszym projekcie języka PHP i ewentualne rozszerzenie jego funkcjonalności.
W PHP 4.0.6 -- wersji przez nas używanej -- jest dostępny bardzo bogaty zbiór funkcji, służących m.in. do dostępu do baz danych, obsługi sesji i ciasteczek, manipulacji łańcuchami znaków itp. Funkcje te są zaimplementowane w dodatkowych pakietach, nazywanych rozszerzeniami. Do obsługi dokumentów standardu XML i jego pochodnych zdefiniowano trzy rozszerzenia: XML parser, DOM XML oraz XSLT.
Pakiet XML parser (por. [PHP-XML]) umożliwia tworzenie parserów języka XML i podstawową obsługę dokumentów XML przy pomocy mechanizmu zdarzeń. Parsowane dokumenty nie podlegają walidacji.
Rozszerzenie XML parser używa biblioteki expat (ang. XML Parser Toolkit, por. [Expat]), opartej na licencji MIT. Jest to obecnie najbardziej popularna biblioteka napisana w języku C, służąca do parsowania dokumentów XML. Sam pakiet nie zapewnia jednak żadnych bardziej zaawansowanych funkcji. Dokument XML, wczytany przy pomocy dostępnych funkcji, musi być przetwarzany w sposób ściśle zdefiniowany przez programistę. Przetwarzanie powinno odbywać się najlepiej w miejscu, ponieważ przechowywanie większych dokumentów przy pomocy wewnętrznych struktur PHP jest bardzo mało wydajne. Rozszerzenie nadaje się więc wyłącznie do implementacji najbardziej podstawowych operacji na dokumentach XML.
W trakcie implementacji projektu aktualną wersją był expat 1.2.
Pakiet DOM XML (por. [PHP-DOM]) udostępnia funkcje do operacji na dokumentach XML przy pomocy interfejsu nazwanego DOM API. DOM (ang. Document Object Model, por. [W3C-DOM]) jest zdefiniowanym przez W3C standardem interpretacji dokumentów XML jako drzew specjalnych obiektów.
Funkcjonalność rozszerzenia jest bardzo prosta -- jedynym jego zadaniem jest uruchamianie funkcji z biblioteki libxml2, rozwijanej w ramach projektu Gnome ([LibXML]). Jest to biblioteka darmowa, oparta na licencji GNU LGPL, napisana w całości w języku C, dzięki czemu jest bardzo wydajna i łatwo przenośna. Obecnie znajduje się w fazie szybkiego rozwoju i w wersji stabilnej udostępnia zaawansowane funkcje umożliwiające m.in.:
Niestety, rozszerzenie DOM XML znajduje się w fazie eksperymentalnej i nie udostępnia pełnej funkcjonalności biblioteki libxml2 ani żadnej funkcjonalności biblioteki libxslt. Obecnie niemożliwe jest parsowanie dokumentów HTML i zapis dokumentów do tego formatu. Brakuje też poprawnie zaimplementowanej obsługi błędów. Ogromne możliwości bibliotek libxml2 i libxslt są ograniczone przez niedopracowanie interfejsu ze strony PHP. Interfejs ten jest obecnie na tyle niekompletny, że cały pakiet funkcji ma niewystarczającą funkcjonalność do zastosowania go w narzędziu XMportal.
W trakcie implementacji projektu aktualnymi wersjami bibliotek były libxml2 2.4.3 oraz libxslt 1.0.3.
Pakiet XSLT (por. [PHP-XSLT]) umożliwia jedynie transformacje dokumentów XML w inne dokumenty XML oraz HTML przy pomocy arkuszy stylów XSLT.
Funkcjonalność rozszerzenia polega na uruchamianiu funkcji z dowolnych bibliotek, będących procesorami XSLT. Do prawidłowej współpracy z danym procesorem XSLT rozszerzenie potrzebuje specjalnego zestawu funkcji do jego obsługi (por. [Sablot-PHP]). W październiku 2000, kiedy rozszerzenie to powstało, istniała możliwość użycia tylko jednego procesora XSLT o nazwie Sablotron (por. [Sablot]). W lipcu 2001 dodano obsługę biblioteki libxslt (por. [PHP-WS44]).
Sablotron jest biblioteką darmową, opartą na licencji MPL, napisaną w języku C++. Sablotron jest rozwiązaniem uboższym, alternatywnym dla bibliotek libxml2 i libxslt, stale rozwijanym, ale nadal nie implementującym pełnego standardu XSLT.
Sablotron używa parsera expat, a transformacje są wykonywane bez widocznego udziału DOM -- dokumenty wejściowe, wyjściowe oraz arkusze stylów są zapisane w postaci łańcuchów znakowych. Wpływa to negatywnie na wydajność biblioteki -- i tak już dosyć niską w porównaniu z libxslt -- w przypadku wielokrotnego przetwarzania tego samego dokumentu. Twórcy biblioteki pracują nad poprawieniem jej wydajności, udostępnieniem interfejsu DOM API oraz obsługi standardu XPath (por. [Sablot-LibXSLT]). W trakcie implementacji projektu aktualną wersją narzędzia był Sablotron 0.71.
Rozszerzenie XSLT znajduje się w fazie eksperymentalnej i udostępnia obecnie wyłącznie funkcje służące do transformacji dokumentów XML, zapisanych w postaci łańcuchów znakowych. Nie cała obsługa błędów jest zaimplementowana poprawnie. Jest to obecnie jedyny interfejs w PHP umożliwiający jakiekolwiek transformacje XSLT, jednak brak obsługi standardu DOM powoduje, że rozszerzenie to ma niewystarczającą funkcjonalność do zastosowania jej w naszym narzędziu.
Po przeanalizowaniu dostępnych w PHP pakietów funkcji stwierdziliśmy, że podstawowa potrzebna nam funkcjonalność, czyli obsługa dokumentów XML, zapytań XPath oraz transformacji XSLT, jest zaimplementowana w stopniu niewystarczającym. W narzędziu XMportal pożądana i wystarczająca byłaby pełna funkcjonalność udostępniana przez biblioteki libxml2 i libxslt. Możliwa byłaby wtedy manipulacja dokumentami XML i XSLT, reprezentowanymi jako drzewa obiektów DOM. Dzięki temu możliwe byłoby osiągnięcie większej wydajności w przypadku wielokrotnej transformacji tego samego dokumentu oraz w przypadku obsługi wielu zapytań w języku XPath do tego samego dokumentu. Dodatkowo dostępne byłyby zaawansowane funkcje służące do operacji na całych drzewach dokumentów oraz na pojedynczych węzłach.
Dlatego podjęliśmy decyzję o takim rozbudowaniu istniejącego pakietu funkcji DOM XML, aby spełniał nasze oczekiwania. Rozszerzenie to wzbogaciliśmy o:
Przy okazji prac nad funkcjami znaleźliśmy jeden drobny błąd w bibliotece libxml2. Stosowną łatę wysłaliśmy do systemu śledzenia błędów w implementacji biblioteki. Poprawka została zaakceptowana i wprowadzona do oficjalnej dystrybucji libxml2 (por. [LibXML-55380]).
W tym rozdziale zostanie omówiony standardowy sposób przetwarzania dokumentów znajdujących się w portalu do formatu przeznaczonego do wyświetlenia w przeglądarce klienta.
Większość dokumentów znajdujących się w portalu to dokumenty statyczne, zapisane w językach HTML i XML. Dokumenty dynamiczne, produkowane przez aplikacje, prawie zawsze są w formacie XML. Część dokumentów HTML oraz wszystkie dokumenty XML wymagają transformacji przed wysłaniem ich do klienta.
Do transformacji dokumentów używa się -- zgodnie ze standardem -- arkuszy stylów XSLT. Odpowiedni arkusz stylów jest przypisany do każdego pliku HTML i XML, który wymaga przetworzenia. Podstawowe przetwarzanie polega na transformacji takiego pliku w formacie HTML lub XML do dokumentu w formacie HTML lub XML. Schematy takiego przetwarzania są przedstawione na rysunku 4.1. Wyjście w formacie XML może być zastosowane m.in. do obsługi protokołu WAP lub w zewnętrznych aplikacjach wykorzystujących dane pobrane z serwisu.
Część aplikacji musi korzystać z bardziej zaawansowanych sposobów przetwarzania. Końcowa treść dokumentu może być złożeniem transformacji wielu mniejszych dokumentów -- zarówno statycznych, jak i generowanych dynamicznie. Przykład takiego zaawansowanego przetwarzania przedstawiono na rysunku 4.2.
Informacja o przypisanym do dokumentu arkuszu XSLT jest zapamiętana w bazie (por. p. 4.5.2) w postaci częściowej ścieżki dostępu do pliku z arkuszem. Dla częściowej ścieżki postaci:
ścieżka_do_katalogu/prefiksużywany jest plik:
ścieżka_do_katalogu/prefiks.nazwa_profilu.xslProfile zostaną opisane dokładnie w punkcie 4.4. Warto zaznaczyć, że ścieżka_do_katalogu może używać odwołań względnych i bezwzględnych, np.:
Katalogi są przetwarzane w sposób odmienny niż zwykłe pliki. Co prawda z naszego punktu widzenia katalog jest również dokumentem, ale nie zawierającym treści i pełniącym wyłącznie funkcję grupującą inne dokumenty. W standardowych serwisach WWW próba wyświetlenia katalogu w przeglądarce klienta powoduje zazwyczaj wyświetlenie zawartości katalogu lub odpowiedniego pliku -- o nazwie domyślnej index.html -- znajdującego się w tymże katalogu. Również w naszym portalu próba wyświetlenia katalogu powoduje wyświetlenie określonego dokumentu. Taki dokument będziemy nazywać dokumentem głównym katalogu.
W naszym systemie odwołania do katalogów są obsługiwane trójstopniowo:
Przyjęte rozwiązanie trójstopniowe zmniejsza w znacznym stopniu redundancję dokumentów oraz umożliwia łatwe skonfigurowanie sytuacji wyjątkowych, polegających na szczególnej obsłudze wyświetlania wybranych katalogów w portalu.
Aplikacje produkujące dokumenty dynamiczne mogą wykonać się z błędami. Dotyczy to głównie aplikacji będących w fazie implementacji lub testowania, ale nie można wykluczyć pojawienia się błędów w już istniejących programach. Komunikaty o błędach nie powinny się jednak pojawiać w przeglądarce klienta. Jądro naszego portalu potrafi przejąć wszystkie komunikaty o błędach generowane przez końcowe aplikacje i przetworzyć je w zdefiniowany sposób.
W chwili obecnej -- gdy portal znajduje się w fazie testów -- sposób przetwarzania błędów polega na wyróżnieniu ich czerwonym kolorem w przeglądarce klienta. Można jednak zrealizować takie rozwiązania, jak np. przesłanie zestawienia o błędach do pliku XML, a w przeglądarce wyświetlenie krótkiego komunikatu z identyfikatorem zdarzenia.
Niektóre pojawiające się komunikaty o błędach muszą być ignorowane. Dotyczy to np. komunikatów pojawiających się przy parsowaniu źle sformatowanych dokumentów HTML, które mimo to chcemy zapisać w postaci drzewa DOM. Dlatego na czas parsowania dokumentów HTML obsługa błędów jest całkowicie wyłączana.
Dokumenty HTML wyświetlane w przeglądarce klienta mają pewną szatę graficzną, z zaprojektowanym nagłówkiem i stopką strony. Często jest też dołączany zestaw aplikacji pomocniczych. Umieszczanie szaty graficznej lub aplikacji w dokumentach -- często stosowane w zwykłych serwisach WWW -- powoduje uciążliwą redundancję danych. W naszym portalu szata graficzna strony oraz dołączane do niej aplikacje są zdefiniowane przy pomocy szablonów stron, do których będziemy również używać określenia template.
Szablon jest statycznym plikiem HTML zawierającym układ wyświetlanej strony. Zarówno miejsce na dokument główny, jak i miejsce na dokumenty używane przez szablon, są wskazane przez specjalny znacznik o nazwie portal-window. Podstawowa składnia tego znacznika to:
Każdy ze wstawianych dokumentów powinien być zapisany w formacie HTML lub XML. W przypadku, gdy do takiego dokumentu jest przywiązany arkusz XSLT, to jest on stosowany przed wstawieniem dokumentu do szablonu. Sposób transformacji dokumentu można zmienić, dodając do znacznika portal-window atrybut xsl. Na przykład użycie następującego znacznika:
Aplikacje uruchamiane przy pomocy znacznika portal-window mają dostęp do wartości jego atrybutów -- można więc tą drogą przekazać im dodatkowe parametry, np.:
nazwa_szablonu.nazwa_profilu.htmlStandardowo dostępne są następujące szablony:
Zmiana szablonu następuje wtedy, gdy w portalowej bazie danych do wyświetlanego dokumentu jest przypisany odmienny szablon (por. p. 4.5.2). Użytkownik może również przełączyć używany domyślnie szablon przy pomocy odpowiedniej aplikacji w portalu.
Podobnie jak szablony określają układ i zawartość wyświetlanych stron, tak profile definiują końcowy wygląd stron wysyłanych do przeglądarki klienta. Wygląd jest zależny od klasy użytkownika (np. student, pracownik, administrator) oraz od typu przeglądarki (np. tekstowa, graficzna, obsługująca JavaScript).
Sam profil nie jest zapisany w portalu ani w postaci fizycznego pliku, ani w portalowej bazie danych -- każdy profil to po prostu zestaw szablonów i arkuszy stylów XSLT. Na przykład szablon error.student.html określa sposób wyświetlania stron z komunikatami o błędach w profilu student, a arkusz catalogs.admin.xsl -- specjalny sposób wyświetlania zawartości katalogów w profilu admin.
Najważniejszym profilem jest profil o nazwie default. Jest to profil nadrzędny dla wszystkich innych -- jeśli jądro portalu nie może znaleźć szablonu lub arkusza zdefiniowanego dla bieżącego profilu, to używa pliku zdefiniowanego właśnie dla profilu default. Dzięki temu zaprojektowanie nowego profilu nie wiąże się z koniecznością projektowania dla niego szablonu i wszystkich możliwych arkuszy XSLT. Natomiast dodanie nowego arkusza stylów pociąga za sobą konieczność stworzenia go najpierw w profilu domyślnym, a dopiero w następnej kolejności w wybranych innych profilach.
Zestaw i wygląd profili zależy od administratora serwisu WWW. Przykładowy zestaw może wyglądać następująco:
Standardowo zmiana profilu polega na uruchomieniu odpowiedniej aplikacji w portalu. Wybrany profil jest używany do momentu wyłączenia przeglądarki. Aplikacja zmieniająca profil próbuje też ustawić u klienta trwałe ciasteczko przechowujące nazwę preferowanego przez użytkownika profilu. Ciasteczko to jest używane przy pierwszym odwołaniu do portalu po ponownym uruchomieniu przeglądarki.
Stosowany sposób przypisania profilu nie jest jedynym możliwym. Technicznie możliwe jest przypisanie najwłaściwszego profilu w zależności od adresu IP klienta, wersji przeglądarki, czy też innych czynników (np. informacji z systemu USOSweb). Jak widać, wybór profilu jest w dużym stopniu uzależniony od konfiguracji środowiska portalu, należy więc do tego zagadnienia podchodzić indywidualnie.
Istnieją dwa rodzaje danych portalowych. Pierwszy rodzaj to dane wewnętrzne wymagane przez jądro systemu, jednak dostępne również dla aplikacji portalowych. Drugi to dane zewnętrzne używane wyłącznie przez aplikacje portalowe. W rozdziale 3.3 przedstawiono logiczny model danych wewnętrznych. W tym rozdziale opiszemy dokładną strukturę tabel służących do przechowywania tych danych.
Dane wewnętrzne są niezbędne do prawidłowej pracy portalu. Znajdują się tam informacje o dokumentach, użytkownikach i uprawnieniach zarejestrowanych w systemie. Informacje te są przechowywane w następujących tabelach:
Związki między tabelami przedstawiono na rysunku 4.5 (logiczny model danych przedstawiono na rysunku 3.4).
Tabela NODE_TYPES przechowuje informacje o typach dokumentów obsługiwanych przez jądro systemu.
Struktura:
| Nazwa kolumny | Typ | Opis |
| id | Identyfikator | Identyfikator typu dokumentu |
| name | tekst | Nazwa typu dokumentu |
Najważniejsze obsługiwane typy dokumentów to:
Tabela NODES jest podstawową tabelą systemu przechowującą informacje o dokumentach. Zapamiętane są w niej informacje o:
| Nazwa kolumny | Typ | Opis |
| id | Identyfikator | Identyfikator dokumentu |
| type | Klucz obcy | Typ dokumentu |
| (odwołanie do tabeli NODE_TYPES) | ||
| parent | Klucz obcy | Katalog, do którego należy dokument |
| (odwołanie do tabeli NODES) | ||
| protection | Tekst | Stopień ochrony |
| visible | Tekst | Widoczność dokumentu |
| name | Tekst | Nazwa dokumentu |
| filename | Tekst | Nazwa fizyczna dokumentu |
| description | Tekst | Opis dokumentu |
| path | Tekst | Ścieżka wskazująca na fizyczne położenie dokumentu |
| template | Tekst | Układ strony, w jakim dokument ma być wyświetlony |
| par1 | Tekst | Parametr pierwszy |
| (znaczenie jest zależne od typu dokumentu) | ||
| par2 | Tekst | Parametr drugi |
| (znaczenie jest zależne od typu dokumentu) |
Dopuszczalne wartości pola protection:
Domyślnie w systemie są zdefiniowane następujące szablony:
Pola par1 i par2 mają różne znaczenie dla różnych typów dokumentów.
Dla katalogów:
Tabela PORTAL_USERS przechowuje informacje o grupach i użytkownikach zarejestrowanych w systemie.
Struktura:
| Nazwa kolumny | Typ | Opis |
| id | Identyfikator | Identyfikator użytkownika lub grupy |
| type | Tekst | Typ rekordu (grupa / użytkownik) |
| login | Tekst | Identyfikator użytkownika w systemie |
| password | Tekst | Hasło użytkownika |
| group_name | Tekst | Nazwa grupy |
| first_name | Tekst | Imię użytkownika |
| last_name | Tekst | Nazwisko użytkownika |
| description | Tekst | Opis grupy lub użytkownika |
| login_nis | Tekst | Identyfikator użytkownika w domenie NIS |
| domena_nis | Tekst | Nazwa domeny NIS |
Dopuszczalne wartości pola type:
Tabela USERS_STRUCTURE przechowuje informacje o hierarchii grup użytkowników oraz ich zawartości.
Struktura:
| Nazwa kolumny | Typ | Opis |
| user_id | Klucz zewnętrzny | Identyfikator użytkownika lub grupy |
| (odwołanie do tabeli PORTAL_USERS) | ||
| group_id | Klucz zewnętrzny | Identyfikator grupy |
| (odwołanie do tabeli PORTAL_USERS) | ||
| assigned_by | Klucz zewnętrzny | Identyfikator użytkownika przypisującego uprawnienie |
| (odwołanie do tabeli PORTAL_USERS) | ||
| assigned_date | Znacznik czasowy | Data zdefiniowania tego połączenia |
Tabela PERMISSION_TYPES przechowuje typy uprawnień. Uprawnienia te wykorzystuje administrator nakładając ograniczenia w dostępie do dokumentów i aplikacji.
Struktura:
| Nazwa kolumny | Typ | Opis |
| id | Identyfikator | Identyfikator uprawnienia |
| name | Tekst | Nazwa uprawnienia |
| type | Tekst | Typ uprawnienia |
| description | Tekst | Opis uprawnienia |
Dopuszczalne wartości pola type:
Tabela PERMISSIONS przechowuje informacje o uprawnieniach nałożonych na dokumenty.
Struktura:
| Nazwa kolumny | Typ | Opis |
| user_id | Klucz zewnętrzny | Identyfikator użytkownika lub grupy |
| (odwołanie do tabeli PORTAL_USERS) | ||
| permission_id | Klucz zewnętrzny | Identyfikator uprawnienia |
| (odwołanie do tabeli PERMISSION_TYPES) | ||
| node_id | Klucz zewnętrzny | Identyfikator dokumentu |
| (odwołanie do tabeli NODES) | ||
| granted_by | Klucz zewnętrzny | Identyfikator użytkownika definiującego uprawnienie |
| (odwołanie do tabeli PORTAL_USERS) | ||
| granted_date | Znacznik czasowy | Data zdefiniowania tego połączenia |
W tej części pracy opiszemy strukturę modułów i jądro portalu, stanowiące najbardziej niskopoziomową część systemu portalowego. Jądro jest programem odpowiadającym za prawidłowe wyświetlanie dokumentów i aplikacji w portalu. Moduły to pakiety funkcji wykorzystywane przez jądro i aplikacje. Moduły dzielą się na zewnętrzne i wewnętrzne. Moduły zewnętrzne służą tylko aplikacjom portalowym. Moduły wewnętrzne są wykorzystywane zarówno przez jądro systemu, jak i aplikacje. Podział systemu na jądro i moduły przedstawiono na rysunku 4.6.
Jądro portalu jest najważniejszym elementem środowiska portalowego. Jest wykorzystywane przy każdym odwołaniu do zawartości portalu. Najważniejsza funkcjonalność udostępniana przez jądro to:
Moduł AUTHORIZE zawiera funkcje umożliwiające zarządzanie użytkownikami i uprawnieniami. Jest to najważniejszy moduł w systemie wykorzystywany przez jądro i większość aplikacji dołączonych do narzędzia XMportal.
Najważniejsza funkcjonalność udostępniana przez moduł AUTHORIZE to:
Moduł NODE zawiera funkcje pozwalające na administrowanie bazą dokumentów. Wykorzystywany jest głównie przez aplikację administratorską.
Najważniejsza funkcjonalność udostępniana przez moduł NODE to:
Moduł XML służy do obsługi dokumentów XML zapisanych w postaci obiektów DOM. Jest nakładką na funkcje PHP z pakietu DOM XML umożliwiającą:
Moduł XSL służy do wykonywania transformacji XSLT na dokumentach XML. Jest nakładką na funkcje PHP z pakietu DOM XML umożliwiającą:
Moduł LOGIN zawiera funkcje pozwalające użytkownikowi na autoryzację w systemie przy pomocy hasła zdefiniowanego w domenie NIS.
Moduł PROFILE zawiera funkcje pozwalające użytkownikowi zmienić profil w jakim prezentowane są dokumenty, np. zmiana profilu domyślnego na tekstowy.
Moduł DATABASE zawiera interfejs pozwalający użytkownikowi na korzystanie z baz danych. Dzięki takiemu rozwiązaniu zmiana bazy danych będzie pociągała za sobą konieczność zmiany tylko tego modułu.
Najważniejsza funkcjonalność udostępniana przez moduł DATABASE to:
Moduł SEARCH zawiera funkcje pozwalające na administrowanie wyszukiwarką i obsługę zapytań.
Najważniejsza funkcjonalność udostępniana przez moduł SEARCH to:
Moduł NEWS zawiera funkcje obsługujące forum dyskusyjne i ogłoszenia.
Najważniejsza funkcjonalność udostępniana przez moduł NEWS to:
Moduł TIME zawiera funkcje pozwalające użytkownikowi na otrzymanie informacji o bieżącej dacie w języku polskim.
Zgodnie z przyjętymi założeniami, aplikacje włączane do portalu powinny być implementowane w języku PHP, mimo że istnieje możliwość włączenia dowolnych aplikacji, obsługiwanych przez standardowe serwisy WWW. Wybór języka PHP daje programiście dodatkową funkcjonalność oferowaną przez portal, przykładowo:
Podczas implementacji aplikacji wykorzystujących informacje z portalowej bazy danych oraz z innych źródeł danych trzeba zwrócić uwagę na sposób kodowania znaków. Baza danych przechowuje informacje w UTF-8, natomiast dokumenty umieszczone w portalu -- w dowolnym kodowaniu znaków. Dokument będący wynikiem działania aplikacji musi być natomiast zapisany według tylko jednego kodowania (zaleca się używanie UTF-8). Aby było możliwe wygenerowanie takiego dokumentu, konieczne może się okazać wykonanie szeregu konwersji znaków -- służy do tego funkcja iconv, standardowo dostępna w dystrybucji PHP.
Oprócz obsługi formatów HTML i XML, jest możliwe uruchamianie aplikacji generujących dokumenty w bardziej zaawansowanych formatach, jak np. licznik odwołań do strony w postaci obrazu GIF, używany w wielu serwisach WWW.
Zaimplementowane aplikacje -- identyfikowane, tak jak wszystkie dokumenty portalu, przez URL -- mogą być uruchamiane zarówno na żądanie klienta, jak i przez jawne umieszczenie ich w szablonie strony. W tym celu wystarczy odpowiednio wstawić do szablonu i skonfigurować znacznik portal-window. Konfiguracja często polega jedynie na podaniu ścieżki do aplikacji. Przy bardziej zaawansowanych aplikacjach może być konieczne przeciążenie parametru definiującego używany arkusz stylów XSLT oraz przekazanie do aplikacji dodatkowych parametrów wejściowych.
Zaprojektowanie i zaimplementowanie narzędzia XMportal wynikło z zapotrzebowania na nowy serwis WWW na Wydziale Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego. W tym rozdziale zostanie opisane wdrożenie Wydziałowego Portalu Internetowego prowadzone równolegle z rozwijaniem narzędzia XMportal.
Prace nad portalem zostały zapoczątkowane przez panią dr Janinę Mincer-Daszkiewicz, Prodziekan ds. Informatyzacji Wydziału. W ramach poszukiwań chętnych do stworzenia nowego portalu i napisania na ten temat pracy magisterskiej, do wszystkich studentów zostało skierowane ogłoszenie. Początkowo zgłosiło się ośmiu studentów, a po szeregu spotkań wyodrębniły się dwa konkurencyjne zespoły. Pierwszy, dwuosobowy zespół zadeklarował chęć implementacji portalu z użyciem technologii XML, XSLT i Java. Drugi zespół, do którego należą Marek Dębowski, Jarosław Kołakowski i Sławomir Mroczek, rozpoczął prace nad portalem opisanym w tej pracy magisterskiej.
Pierwszy etap prac polegał na analizie używanych obecnie technologii. Zapoznaliśmy się z dostępnymi platformami programistycznymi do budowy aplikacji WWW oraz z bardzo popularnymi technologiami XML i XSLT. Dokładniej przeanalizowaliśmy dostępne rozwiązania w językach PHP i Java.
Następnie zajęliśmy się sprecyzowaniem wymagań i zaprojektowaniem systemu. Podstawowe wymagania zostały przedstawione podczas przetargu, a precyzowaliśmy je na podstawie analizy dostępnych w sieci serwisów WWW, m.in. portali i stron domowych uczelni z całego świata, w tym strony domowej Wydziału. Dosyć dużo czasu poświęciliśmy na projektowanie jądra, poszukując kompromisu między maksymalną wydajnością portalu, maksymalną wygodą jego użycia oraz maksymalną elastycznością i rozszerzalnością.
Najbardziej pracochłonnym etapem była implementacja jądra i aplikacji. Podczas tego etapu wyniki testów niejednokrotnie powodowały, że musieliśmy wracać do poprzednich faz, aby wzbogacić projekt o nowe elementy. W wyniku prac powstało wydajne, funkcjonalne i elastyczne jądro oraz zestaw przykładowych aplikacji.
Portal będący wynikiem naszych prac zainstalowaliśmy na serwerze, na którym ma się w przyszłości znajdować Wydziałowy Portal Internetowy. Zainstalowaliśmy go jako dodatkową usługę i wypełniliśmy przykładowymi dokumentami. Serwis został pokazany opiekunowi wydziałowych stron WWW, panu dr Piotrowi Krzyżanowskiemu. Opiekun stron wstawił do portalu dokumenty z dotychczasowego serwisu wydziałowego, które znajdą się w wersji produkcyjnej i rozpoczął jego testy. W wyniku tych testów zostały usunięte usterki oraz wprowadzone m.in. następujące zmiany:
Mimo uzyskania zakładanej na początku prac funkcjonalności portalu, nadal pozostaje wiele do zrobienia. W trakcie wdrażania portalu pojawiały się nowe wymagania; obecnie lista zadań do wykonania obejmuje kilkanaście pozycji, które można podzielić na:
Oprócz rozszerzeń funkcjonalności portalu, rozważane jest również zaprojektowanie nowej szaty graficznej przez zawodowego grafika.
Powodzenie projektu najlepiej można ocenić analizując funkcjonalność portalu wydziałowego przez pryzmat postawionych przed nim wcześniej wymagań.
Do pracy magisterskiej dołączona jest płyta CD-ROM, na której znajduje się wersja instalacyjna narzędzia XMportal zanurzonego w przykładowym portalu. Wersja instalacyjna składa się z:
Główny katalog instalacyjny zawiera następujące katalogi:
Podstawowa instalacja portalu odbywa się w sposób opisany w kolejnych punktach.
Na serwerze, na którym ma być zainstalowany portal, powinny być prawidłowo zainstalowane i działające następujące pakiety oprogramowania:
-- testowano wersję 3.23.41,
) oraz nagłówki dla programistów -- testowano wersję 1.3.20,
Drzewo katalogów z katalogu instalacyjnego należy skopiować na lokalny dysk do wybranego katalogu. Podkatalog _instalacje będzie używany tylko w trakcie instalacji portalu.
W dalszej części będziemy zakładać, że wybranym katalogiem, do którego skopiowano katalogi instalacyjne, jest /home/portal. Tak więc np. katalog _instalacje będzie dostępny przez ścieżkę /home/portal/_instalacje.
Pożądane jest również utworzenie specjalnego konta użytkownika, o mniejszych przywilejach niż root, które będzie używane przez portal. Założymy, że to konto ma nazwę portal i przynależy do grupy o nazwie http.
Prawa dostępu do katalogów powinny być tak ustawione, aby jakikolwiek dostęp do nich miał wyłącznie użytkownik portal (ewentualnie grupa http). Jedynie do katalogu htdocs powinien być dostęp publiczny do odczytu i wejścia, tak jak dla katalogu z dokumentami w standardowych konfiguracjach serwerów http.
Narzędzie XMportal wymaga środowiska PHP z zaaplikowaną specjalną łatką służącą do obsługi biblioteki libxslt. Łatka znajduje się w pliku php-4.0.6-libxslt-patch. Łatkę stosuje się do źródeł PHP w wersji 4.0.6 (archiwum php-4.0.6.tar.gz) przy pomocy polecenia patch. W większości wypadków wystarczy wejść do katalogu ze źródłami i wykonać polecenie:
Następnie należy skonfigurować źródła PHP poleceniem ./configure. Należy przy tym koniecznie uwzględnić następujące rozszerzenia PHP:
'./configure' \
'-prefix=/usr' \
'-exec-prefix=/usr' \
'-bindir=/usr/bin' \
'-sbindir=/usr/sbin' \
'-sysconfdir=/etc' \
'-datadir=/usr/share' \
'-includedir=/usr/include' \
'-libdir=/usr/lib' \
'-libexecdir=/usr/libexec' \
'-localstatedir=/usr/var' \
'-sharedstatedir=/usr/com' \
'-mandir=/usr/share/man' \
'-infodir=/usr/share/info' \
'-with-apxs=/usr/sbin/apxs' \
'-with-config-file-path=/etc' \
'-with-exec-dir=/usr/bin' \
'-disable-debug' \
'-enable-magic-quotes' \
'-enable-shared' \
'-enable-track-vars' \
'-enable-safe-mode' \
'-enable-trans-sid' \
'-enable-session' \
'-with-mysql' \
'-with-mysql-sock=/var/lib/mysql/mysql.sock' \
'-without-gd' \
'-with-pgsql' \
'-enable-posix' \
'-with-xml' \
'-enable-xml' \
'-with-zlib' \
'-with-dom' \
'-with-iconv'
Szczegółowy opis sposobu instalacji jest zawarty w źródłach PHP.
Konfiguracja PHP jest zazwyczaj zawarta w pliku /etc/php.ini. W celu prawidłowej interpretacji plików XML (zaczynających się od tekstu ,,<?xml''), skrypty PHP muszą używać normalnej notacji znaczników otwierających -- ,,<?php program ?>'', a nie skrótowej -- ,,<? program ?>''. W konfiguracji PHP należy wyłączyć obsługę skrótowej notacji skryptów:
Konfiguracja serwera Apache jest zazwyczaj zawarta w pliku /etc/httpd/httpd.conf. Konfiguracja ta powinna:
AddModule mod_php4.c
AddType application/x-httpd-php .php3 .inc .php .php4
AddModule mod_ssl.c
dalsze opcje mod_ssl
Group http
<Directory "/home/portal/htdocs">
konfiguracja korzenia dokumentów
</Directory>
AddModule mod_dir.c
<IfModule mod_dir.c>
DirectoryIndex index.php inne pliki z indeksami
</IfModule>
ForceType application/x-httpd-php
</Location>
Następnym krokiem jest założenie portalowej bazy danych o nazwie np. portaldb. Aby to wykonać, należy uruchomić jako polecenie:
on portaldb.*
to portal
identified by 'hasło_dostępu';
Inicjalne wypełnienie bazy polega na uruchomieniu poleceń SQL zwartych w pliku install.sql. Należy to wykonać z konta użytkownika portal, uruchamiając polecenie:
Plik /home/portal/includes/global_constants.inc zawiera globalną konfigurację portalu. Trzeba skonfigurować są następujące zmienne:
Programy w C znajdujące się w portalu należy skompilować. Należy w tym celu wejść do katalogu /home/portal/programs i wykonać polecenie:
Po prawidłowym skonfigurowaniu i uruchomieniu portalu oraz wszystkich wymaganych przez niego pakietów oprogramowania, można przystąpić do:
Narzędzie administratorskie to aplikacja napisana w języku PHP, wchodząca w skład narzędzia XMportal. Służy ona do budowy, administracji i rozwijania portali internetowych zbudowanych przy pomocy narzędzia XMportal. Używać jej mogą tylko osoby z uprawnieniami administratorskimi.
Aplikację administratorską można łatwo rozszerzać o funkcje typowe dla konkretnego portalu (np. obsługa specyficznych dla danego serwisu aplikacji). W tej pracy opiszemy funkcjonalność aplikacji administratorskiej przygotowanej do obsługi Wydziałowego Portalu Internetowego.
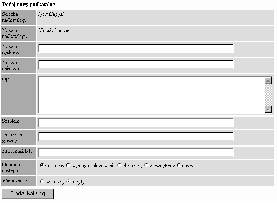
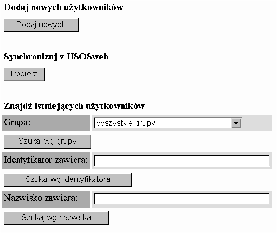
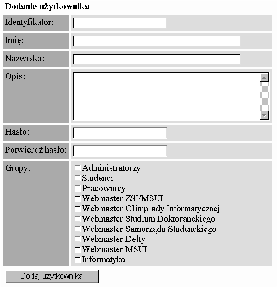
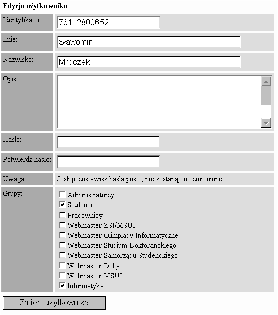
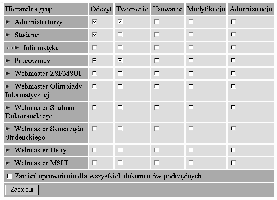
Aplikacja administratorska umożliwia (por. rys. B.1):
Aplikacja służąca do administracji katalogami i plikami jest najważniejszą i najbardziej skomplikowaną spośród aplikacji administratorskich. Umożliwia operowanie na katalogach, plikach i dowiązaniach, czyli na dokumentach umieszczonych w bazie dokumentów. Jednym z podstawowych zadań postawionych przed tą aplikacją jest dbanie o zgodność zarejestrowanej w bazie dokumentów struktury katalogów ze strukturą katalogów, zapamiętaną na dysku.
Pojęcie dokumenty, często używane w dalszej części instrukcji oznacza pliki, dowiązania lub katalogi.
Najważniejsze funkcje udostępniane przez tą aplikację to:
Po uruchomieniu aplikacji do administracji katalogami pojawi się widok przedstawiony na rysunku B.2.
Na stronie jest widoczna lista katalogów zarejestrowanych w systemie.
Początkowo katalogi są nierozwinięte. Rozwijamy je i zwijamy przy
pomocy przycisków
![]() i
i
![]() znajdujących się przy nazwie katalogu. Aby wejść do aplikacji umożliwiającej
administrację plikami i dowiązaniami znajdującymi się wewnątrz wybranego
katalogu, musimy nacisnąć odnośnik znajdujący się w nazwie katalogu.
znajdujących się przy nazwie katalogu. Aby wejść do aplikacji umożliwiającej
administrację plikami i dowiązaniami znajdującymi się wewnątrz wybranego
katalogu, musimy nacisnąć odnośnik znajdujący się w nazwie katalogu.
Operacje, które możemy wykonać na katalogach dzielą się na trzy grupy:
Do dodania nowego podkatalogu służy przycisk
![]() umieszczony obok nazwy wybranego nadkatalogu. Na ekranie pojawi się
wtedy widok przedstawiony na rysunku B.4.
umieszczony obok nazwy wybranego nadkatalogu. Na ekranie pojawi się
wtedy widok przedstawiony na rysunku B.4.
Jeśli na dysku w wybranym katalogu znajdują się niezarejestrowane w bazie katalogi, to zostaną one udostępnione w polu wyboru. Możemy również wpisać własną nazwę. Katalog o podanej nazwie zostanie wtedy fizycznie utworzony na dysku.
Dodanie nowego katalogu wymaga zdefiniowania następujących elementów:
Pole Ochrona dostępu określa poziom ochrony katalogu. Dopuszczalne wartości pola Ochrona dostępu to:
Do przeniesienia katalogu służy przycisk
![]() znajdujący się obok nazwy wybranego katalogu. Zostaniemy poproszeni
o wybranie katalogu, do którego przenosimy wybrany folder. Przeniesienie
katalogu dotyczy całej jego zawartości (podkatalogi, pliki i dowiązania).
Zachowywane są atrybuty katalogu i związane z nim uprawnienia.
znajdujący się obok nazwy wybranego katalogu. Zostaniemy poproszeni
o wybranie katalogu, do którego przenosimy wybrany folder. Przeniesienie
katalogu dotyczy całej jego zawartości (podkatalogi, pliki i dowiązania).
Zachowywane są atrybuty katalogu i związane z nim uprawnienia.
Do usunięcia katalogu służy przycisk
![]() znajdujący się obok nazwy wybranego katalogu. Zostaniemy poproszeni
o potwierdzenie chęci usunięcia katalogu. Możemy również zaznaczyć
opcję usunięcia katalogu nie tylko z bazy dokumentów, ale również
fizycznie z dysku. Usunięcie katalogu odbywa się wraz z całą jego
zawartością.
znajdujący się obok nazwy wybranego katalogu. Zostaniemy poproszeni
o potwierdzenie chęci usunięcia katalogu. Możemy również zaznaczyć
opcję usunięcia katalogu nie tylko z bazy dokumentów, ale również
fizycznie z dysku. Usunięcie katalogu odbywa się wraz z całą jego
zawartością.
Funkcja ta jest dostępna również dla grup katalogów.
Zmiana atrybutów katalogu jest możliwa po naciśnięciu przycisku
![]() znajdującego się obok nazwy wybranego katalogu. Pojwi się wtedy ekran
podobny do tego, który widzieliśmy dodając katalog.
znajdującego się obok nazwy wybranego katalogu. Pojwi się wtedy ekran
podobny do tego, który widzieliśmy dodając katalog.
Jeśli zaznaczymy opcję kaskadowego nakładania poprawek, wartość pola Ochrona dostępu zostanie nadana również wszystkim podkatalogom i plikom znajdującym się wewnątrz modyfikowanego katalogu.
Zmiana atrybutów jest możliwa również dla wielu katalogów na raz. Mamy wtedy możliwość zmiany wartości drugiego parametru, pól Ochrona dostępu i Widoczność. Możemy również użyć opcji zmiany kaskadowej.
Funkcja ta jest dostępna również dla grup katalogów.
Uprawnienia do katalogu możemy przypisać po naciśnięciu przycisku
![]() znajdującego się obok nazwy
wybranego katalogu.
znajdującego się obok nazwy
wybranego katalogu.
Interfejs do przypisywania uprawnień składa się z dwóch części. Pierwsza z nich dotyczy nałożenia praw dla całych grup użytkowników i przedstawiona jest na rysunku B.5.
Na ekranie otrzymamy pełną listę dostępnych praw i grup użytkowników. Przypisanie wybranego prawa dla danej grupy polega na zaznaczeniu pustego pola. Jeśli chcemy odebrać wybrane uprawnienie, wystarczy odznaczyć zaznaczone pole.
Drugi interfejs dotyczy nakładania praw dla wybranych użytkowników.
Najpierw wybieramy użytkowników, którym chcemy nadać uprawnienia. Mamy do wyboru wyszukiwarkę wg grup, identyfikatorów i nazwisk. Po wybraniu odpowiednich użytkowników mamy do wyboru dwie możliwości nadania im uprawnień.
Pierwsza z nich to nadanie uprawnień całej zaznaczonej grupie użytkowników (por. rys. B.6).
Druga pozwala na dokładne przypisanie praw każdemu z wybranych użytkowników. Po zaznaczeniu wybranych użytkowników i naciśnięciu przycisku Zaawansowane pojawia się ekran bardzo podobny do ekranu używanego do nakładania uprawnień dla grup (por. rys. B.7). Jednak zamiast nazw grup otrzymujemy listę dostępnych użytkowników. Uprawnienia nadaje się i odbiera identycznie jak dla grup.
Możemy zaznaczyć opcję umożliwiającą nadanie wybranych uprawnień dla wszystkich dokumentów podrzędnych.
Funkcja nadawania uprawnień jest dostępna również dla grup katalogów.
Po naciśnięciu przycisku
![]() możemy
odświeżyć informacje o zawartości katalogu. Możemy wybrać, jaką wartość
przyjmie pole Ochrona dostępu w nowych plikach i katalogach
(domyślnie wartość N -- dokument nowy). Do bazy zostaną
dodane wszystkie pliki i podkatalogi znajdujące się na dysku, a niezarejestrowane
w bazie dokumentów. Z bazy zostaną usunięte informacje o nieistniejących
fizycznie podkatalogach i plikach. Informacje wczytane
z dysku wymagają uzupełnienia (opisy, wartości parametrów).
możemy
odświeżyć informacje o zawartości katalogu. Możemy wybrać, jaką wartość
przyjmie pole Ochrona dostępu w nowych plikach i katalogach
(domyślnie wartość N -- dokument nowy). Do bazy zostaną
dodane wszystkie pliki i podkatalogi znajdujące się na dysku, a niezarejestrowane
w bazie dokumentów. Z bazy zostaną usunięte informacje o nieistniejących
fizycznie podkatalogach i plikach. Informacje wczytane
z dysku wymagają uzupełnienia (opisy, wartości parametrów).
Jeśli dodany tą drogą plik ma rozszerzenie .html, to aplikacja próbuje uzyskać z niego informacje o tytule dokumentu (wartość znacznika <title> znajdującego się wewnątrz znacznika <head>) i wpisać go jako nazwę opisową pliku. Dodatkowo, jeśli w pliku wewnątrz znacznika <html> istnieje znacznik <body>, to aplikacja przypisuje do pliku arkusz XSLT wycinający zawartość tego znacznika.
Dla pozostałych dokumentów nazwą opisową staje się nazwa dyskowa pliku lub katalogu.
Funkcja ta jest dostępna również dla grup katalogów.
Okno umożliwiające administrację plikami i dowiązaniami jest bardzo podobne do tego używanego do administrowania katalogami (por. rys. B.8).
Aplikacja umożliwia modyfikowanie informacji o pojedynczych plikach i dowiązaniach, jak również o całych ich grupach. Możliwe operacje to:
Dodanie pliku odbywa się po naciśnięciu przycisku
![]() .
Zarejestrowanie pliku jest możliwe wyłącznie w przypadku, gdy plik
znajduje się już fizycznie w bieżącym katalogu. Lista nazw plików
dostępnych wewnątrz katalogu i niezarejestrowanych w bazie jest podana
w polu wyboru.
.
Zarejestrowanie pliku jest możliwe wyłącznie w przypadku, gdy plik
znajduje się już fizycznie w bieżącym katalogu. Lista nazw plików
dostępnych wewnątrz katalogu i niezarejestrowanych w bazie jest podana
w polu wyboru.
Formularz służący do dodawania nowych plików uruchamia się tym samym
przyciskiem, co formularz do dodawania nowych dowiązań. W przypadku
braku na dysku nowych plików (niezarejestrowanych w bazie), formularz
ten nie pojawi się. Po naciśnięciu przycisku
![]() będziemy mogli dodać jedynie dowiązania. Formularz służący do dodania
nowych plików przedstawiono na rysunku B.9.
będziemy mogli dodać jedynie dowiązania. Formularz służący do dodania
nowych plików przedstawiono na rysunku B.9.
Aby zarejestrować plik, musimy podać nazwę opisową pliku, opis, wartości parametrów oraz pól Szablon, Ochrona dostępu i Widoczność.
Pola Szablon, Ochrona dostępu i Widoczność (domyślnie takie jak wartości nadkatalogu) oznaczają dokładnie to samo co dla katalogów.
Parametr Typ zawartości określony jest tylko dla plików typu FILE, i przechowuje typ pliku.
Parametr Arkusz XSLT określa sposób przetwarzania pliku i jest określony dla plików typu XML i HTML.
Dodanie dowiązania jest możliwe po naciśnięciu przycisku
![]() (por. rys. B.10).
(por. rys. B.10).
Definicja dowiązania polega na określeniu jego adresu URL, nazwy opisowej, opisu oraz parametru Widoczność.
Możemy zdefiniować dowiązania lokalne. W polu URL podajemy ścieżkę do dokumentu. Ścieżka może być względna ('/' oznacza dokument główny w portalu).
Usunięcie pliku lub dowiązania jest możliwe po wciśnięciu przycisku
![]() . Zostaniemy poproszeni o potwierdzenie
chęci usunięcia dokumentu. Możemy zaznaczyć opcję usunięcia pliku
nie tylko z bazy dokumentów, ale również fizycznie z dysku.
. Zostaniemy poproszeni o potwierdzenie
chęci usunięcia dokumentu. Możemy zaznaczyć opcję usunięcia pliku
nie tylko z bazy dokumentów, ale również fizycznie z dysku.
Funkcja ta jest dostępna również dla grup plików i dowiązań.
Przeniesienie plików lub dowiązań odbywa się identycznie jak katalogów.
Funkcja ta jest dostępna również dla grup dokumentów.
Do zmiany atrybutów plików lub dowiązań służy przycisk
![]() .
Po naciśnięciu go pojawi się widok bardzo podobny do używanego podczas
dodawania nowych plików lub dowiązań. Możemy w nim zmienić dowolne
parametry dokumentu.
.
Po naciśnięciu go pojawi się widok bardzo podobny do używanego podczas
dodawania nowych plików lub dowiązań. Możemy w nim zmienić dowolne
parametry dokumentu.
Funkcja ta jest dostępna również dla grup dokumentów. Jeśli w grupie tej znajdują się wyłącznie to pliki możemy zmienić wartości parametrów oraz pól Ochrona dostępu i Widoczność. Jeśli znajdują się tam również dowiązania, to możemy zmienić tylko parametr Widoczność.
Uprawnienia możemy nakładać wyłącznie na pliki (dowiązania są ogólnodostępne). Metoda nakładania uprawnień dla plików jest identyczna jak dla katalogów.
Funkcja ta jest dostępna dla grup plików.
W celu wczytania z dysku informacji o bieżącym katalogu, należy wcisnąć
przycisk
![]() . Do bazy zostaną dodane
wszystkie pliki i podkatalogi znajdujące się na dysku, a niezarejestrowane
w bazie dokumentów. Z bazy zostaną usunięte informacje o nieistniejących
fizycznie podkatalogach i plikach.
. Do bazy zostaną dodane
wszystkie pliki i podkatalogi znajdujące się na dysku, a niezarejestrowane
w bazie dokumentów. Z bazy zostaną usunięte informacje o nieistniejących
fizycznie podkatalogach i plikach.
Aplikacja do administrowania użytkownikami pozwala na zdefiniowanie hierarchicznej struktury grup oraz przypisanie użytkowników do dowolnej liczby grup.
Aplikacja do administracji grupami użytkowników umożliwia dodawanie, usuwanie i modyfikację grup. Przy jej pomocy definiujemy również hierarchię grup (por. rys. B.11).
Do dodawania nowych grup służy przycisk
![]() .
Musimy wybrać grupę nadrzędną (lub Wszystkie grupy, jeśli
grupa ma być grupą główną) i po naciśnięciu przycisku definiujemy
nazwę i opis grupy.
.
Musimy wybrać grupę nadrzędną (lub Wszystkie grupy, jeśli
grupa ma być grupą główną) i po naciśnięciu przycisku definiujemy
nazwę i opis grupy.
Do modyfikacji informacji dotyczącej wybranej grupy służy przycisk
![]() . Modyfikacja istniejącej grupy
polega na zmianie nazwy i opisu grupy.
. Modyfikacja istniejącej grupy
polega na zmianie nazwy i opisu grupy.
Do przeniesienia grupy w inne miejsce służy przycisk
![]() .
Zostaniemy poproszeni o wybranie grupy, do której ma zostać przeniesiona
grupa i wszystkie jej podgrupy. Użytkownicy należący do przenoszonej
grupy nadal w niej pozostaną.
.
Zostaniemy poproszeni o wybranie grupy, do której ma zostać przeniesiona
grupa i wszystkie jej podgrupy. Użytkownicy należący do przenoszonej
grupy nadal w niej pozostaną.
Usunięcie istniejącej podgupy jest możliwe po wybraniu przycisku
![]() .
Usunięcie grupy użytkowników nie powoduje usunięcia użytkowników należących
do tej grupy.
.
Usunięcie grupy użytkowników nie powoduje usunięcia użytkowników należących
do tej grupy.
Administracja użytkownikami obejmuje (por. rys. B.12):
Synchronizacja z USOSwebem odbywa się po naciśnięciu przycisku Pobierz. System sprawdza wtedy informacje o użytkownikach znajdujące się w USOSwebie, aktualizuje informacje o użytkownikach zarejestrowanych w portalu oraz dodaje nowych, których znalazł w USOSwebie, a nie znalazł w portalu (importowane są informacje o identyfikatorze użytkownika, jego imieniu i nazwisku). Użytkownicy importowani z USOSweba są automatycznie kierowani do grup Studenci lub Pracownicy. Użytkownicy, którzy byli zarejestrowani w portalu, ale nie zostali odnalezieni w USOSwebie oraz ich pole login_nis jest wypełnione (informacja mówiąca, że dane o użytkowniku były importowane z USOSweba) są usuwani, w przeciwnym przypadku są pozostawiani (użytkownicy byli zarejestrowani w portalu bez udziału USOSweba).
Nowych użytkowników możemy dodać również ręcznie. Aby to zrobić, musimy nacisnąć przycisk Dodaj nowych. Pojawi się wtedy formularz, w który należy wpisać informacje o użytkowniku, jego identyfikator, hasło i listę grup, do których ma należeć (por. rys B.13).
Aby zmodyfikować informacje o użytkownikach, musimy najpierw zidentyfikować ich w systemie. W tym celu musimy ich odnaleźć korzystając z wyszukiwarki dołączonej do narzędzia. Użytkowników możemy wyszukiwać według grup, do których należą, identyfikatora systemowego lub nazwiska. W wyniku wyszukiwania dostaniemy listę osób spełniających zadane kryteria.
Z listy wyświetlonych osób powinniśmy wybrać (podświetlając je) osoby, których dane chcemy zmieniać. Aplikacja umożliwia nam:
Administracja uprawnieniami polega na dodawaniu, usuwaniu i modyfikacji dostępnych w systemie uprawnień. Nowe uprawnienia mogą się przydać przy obsłudze dołączanych do portalu aplikacji.
Wewnątrz systemu istnieje pięć podstawowych uprawnień, których nie wolno usunąć ani zmodyfikować. Są to:
Po uruchomieniu aplikacji pojawi się okno, w którym znajdować się będzie pole wyboru z dostępnymi uprawnieniami oraz trzy przyciski, pozwalające na dodawanie, usuwanie i modyfikację uprawnień (por. rys. B.16).
Jeśli wybierzemy modyfikację lub usunięcie któregoś z pięciu wymienionych uprawnień, to zostanie wyświetlony komunikat z informacją o zakazie wprowadzania takich zmian.
Przycisk DODAJ uruchamia ekran umożliwiający zdefiniowanie nazwy i opisu nowego uprawnienia. Jeśli podana nazwa jest poprawna, czyli nie została już wykorzystana przez inne uprawnienie i nie jest pusta, to uprawnienie zostanie dodane do systemu. Od tej pory nowe uprawnienie będzie widoczne przy definiowaniu praw dostępu dla katalogów i plików. Będzie je można również wykorzystać w aplikacjach (np. prawo do korzystania ze wspólnej drukarki).
Przycisk MODYFIKUJ uruchamia formatkę umożliwiającą zmianę nazwy i opisu uprawnienia. Wszystkie dowiązania do modyfikowanego uprawnienia zostaną zachowane.
Przycisk USUŃ pozwala na usunięcie wybranego uprawnienia. Wszystkie dowiązania do modyfikowanego uprawnienia zostaną usunięte.
Aplikacja do administracji bazą danych umożliwia nam naprawę informacji znajdującej się wewnątrz bazy dokumentów. Aplikacja ta pozwala nam na (por. rys. B.17):
Aplikacja służąca do administracji wyszukiwarką umożliwia indeksowanie plików znajdujących się w systemie. Indeksowane będą wyłącznie pliki zmodyfikowane po ostatnim indeksowaniu oraz jeszcze nieindeksowane.
Teoretycznie, indeksowanie plików powinno być uruchamiane po każdej zmianie wewnątrz bazy dokumentów. Zaleca się uruchamianie indeksowania raz dziennie.
Ankiety stworzone przy pomocy dołączonej aplikacji administratorskiej mogą zawierać jedno pytanie i maksymalnie dziesięć możliwych odpowiedzi.
Menu główne do administracji ankietami pozwala nam na (por. rys. B.18):
Do dodania nowych ankiet służy przycisk
![]() .
.
Dodanie nowej ankiety polega na zdefiniowaniu pytania i możliwych odpowiedzi. Dodatkowo musimy zdefiniwać parametry Type oraz Status (por. rys. B.19).
Pole Type może przyjmować następujące wartości:
Administrowanie istniejącymi ankietami umożliwia:
Większość czynności związanych z administrowaniem aplikacją ogłoszeniową można wykonać wykorzystując aplikację do zarządzania katalogami i plikami. Do czynności tych należą:
Generator raportów zanurzony w aplikacji administratorskiej pozwala na uzyskanie informacji o (por. rys. B.21):
W tej części pracy opisano zaawansowane czynności administratorskie.
Administrowaniem portalem zajmować się będzie najczęściej kilka osób. Narzędzie XMportal umożliwia zdefiniowanie tzw. lokalnych aministratorów. Mogą oni administrować tylko wybranymi podkatalogami portalu. Nie będą mogli niczego zmienić, ani nawet obejrzeć w tych częściach portalu, do których nie mają uprawnień. Uprawnienia do administracji konkretnymi katalogami można nadać jednemu użytkownikowi lub grupie użytkowników.
W dalszej części rozdziału przedstawimy sposób przypisania użytkownikowi uprawnienia do administracji katalogami.
Podstawowym narzędziem służącym do definiowania administratorów lokalnych jest aplikacja administratorska. Administratorów lokalnych definiować może wyłącznie administrator główny.
Pierwszym krokiem jest przypisanie nowym administratorom uprawnienia odczyt dla całego katalogu /admin/catalogs (por. rys. C.1). W tym celu należy zgodnie z instrukcją aplikacji administratorskiej, uruchomić nakładanie uprawnień dla katalogu /admin/catalogs.
Po wybraniu odpowiedniego użytkownika (lub grupy użytkowników) dodajemy mu uprawnienie Odczyt. Musimy również zaznaczyć opcję przypisania tego uprawnienia do wszystkich dokumentów podrzędnych.
Drugim krokiem jest przypisanie nowym administratorom uprawnienia administracja do katalogu, którym mają administrować.
Musimy wybrać katalog do którego chcemy przypisać administratorów. Następnie uruchamiamy menu do przypisywania uprawnień. Po wybraniu odpowiednich użytkowników (lub grup użytkowników) dodajemy im uprawnienie Administracja. Nie należy zaznaczać opcji przypisania uprawnienia do dokumentów podrzędnych (por. rys. C.2). Jest to spowodowane tym, że uprawnienie Administracja pozwala na administrowanie wybranym katalogiem i wszystkimi jego podkatalogami.
Do administrowania swoimi katalogami administrator lokalny wykorzystuje aplikację administratorską. Uruchamia ją wpisując adres portalu, a następnie ścieżkę /admin/catalogs. Pojawi mu się wtedy lista katalogów, którymi może administrować. Będzie ich tyle, do ilu ma przypisane uprawnienie Administracja (por. rys. C.3).
Naciśnięcie przycisku z wybranym katalogiem uruchamia standardową aplikację służącą do administrowania katalogami, jednak jest ona ograniczona tylko do wcześniej wybranego katalogu (por. rys. C.4).
Sposób wyświetlania katalogu jest zależny od definicji atrybutów Dokument główny oraz Arkusz XSLT. Pierwszy z wymienionych atrybutów wskazuje na plik wyświetlający zawartość katalogu. Drugi z atrybutów wskazuje na arkusz XSLT, definiujący sposób wyświetlania zawartości katalogu (należy go zdefiniować jeśli pierwszy plik generował wynik w postaci XML). Definiując parametry katalogu nie musimy wypełniać zawartości żadnego z tych atrybutów. Do wyświetlenia zawartości katalogu zostanie wtedy użyty standardowy plik index.php, index.xml lub index.html znajdujący się wewnątrz katalogu lub plik domyślny (zgodnie z regułami przedstawionymi w poprzedniej części pracy). Do przetworzenia języka XML zostanie wtedy użyty arkusz XSLT przywiązany do tego pliku.
W dalszej części rozdziału opisano metody niestandardowego wyświetlania zawartości katalogów.
W celu wyświetlenia zawartości katalogu wraz z informacją o zawartości podkatalogów, musimy zdefiniować atrybut głębokość. Atrybut ten definiuje się w pliku index.php.
Pierwszym krokiem jest skopiowanie pliku index.php do katalogu, który chcemy wyświetlić. Jest to konieczne, ponieważ modyfikacje wykonane na standardowym pliku index.php znajdującym się w głównym katalogu zmieniłyby sposób wyświetlania wszystkich katalogów, a nie tylko tego, który chcemy wyświetlić. Następnie nowy plik index.php musimy zarejestrować w bazie i zdefiniować atrybuty, identycznie jak dla standardowego pliku index.php (pole Typ przyjmuje wartość XML, pole Widoczność przyjmuje wartość Ukryty, pole Ochrona dostępu przyjmuje wartość Publiczny, a pole Arkusz XSLT wartość /homepage).
Następnie musimy zmodyfikować zawartość pliku index.php. Zmieniamy fragment kodu:
Kopiowanie pliku ani jego modyfikacja nie są konieczne, jeśli już raz zdefiniowaliśmy plik index.php wyświetlający zawartość katalogu o pożądanej głębokości. Wystarczy, jeśli w polu Dokument główny wpiszemy ścieżkę do tego pliku (można wtedy użyć ścieżek względnych, gdzie '/' oznacza katalog główny portalu).
Wyświetlając zawartość katalogów w sposób standardowy otrzymujemy listę katalogów, plików i dowiązań posortowanych według nazw w porządku alfabetycznym. Często chcielibyśmy, aby sortowanie odbyło się według innych atrybutów lub w odwrotnym porządku.
W tym celu należy skopiować plik catalogs_newerfirst.default.xsl z katalogu głównego do katalogu, który chcemy wyświetlić.
Wewnątrz pliku definiujemy sposób sortowania:
<xsl:template match="catalogs">
...
<xsl:sort select="@datetime" order="descending"/>
...
<!- Sposob sortowania plikow ->
<xsl:template match="files">
...
<xsl:sort select="@datetime" order="descending"/>
...
Kopiowanie pliku ani jego modyfikacja nie są konieczne, jeśli już raz zdefiniowaliśmy plik catalogs_newerfirst.default.xsl wyświetlający zawartość katalogu o wymaganym porządku. Wystarczy, jeśli w polu Arkusz XSLT wpiszemy ścieżkę do tego pliku.
Narzędzie XMportal umożliwia również zupełnie niestandardowe sposoby wyświetlania zawartości katalogów. Możemy samodzielnie napisać skrypty PHP lub strony HTML i przywiązać je do danego katalogu. Istotna jest reguła, że plik generujący stronę z zawartością katalogu powinien mieć nazwę index.php, index.xml lub index.html i znajdować się w katalogu, który chcemy wyświetlić. Drugi sposób to wskazanie na ten plik w atrybucie katalogu Dokument główny. Należy pamiętać, że plik ten powinien być zarejestrowany w bazie dokumentów. Jeśli plik generuje wynik w postaci XML, to należy w atrybucie Arkusz XSLT dowiązać do niego arkusz XSLT. Arkusz ten można dowiązać zarówno do pliku, jak i do katalogu. Przypisanie do pliku sprawi, że wszystkie katalogi wykorzystujące ten plik do wyświetlania swojej zawartości będą mogły wykorzystać ten wygląd. Przypisanie do katalogu zmienia wygląd tylko dla danego katalogu.
Przykładem aplikacji, która wyświetla zawartość katalogu w niestandardowy sposób, jest lista uchwał Rady Wydziału. Generowany na podstawie aplikacji plik index.xml ma następującą postać:
<uchwaly>
<uchwala
href="uchwala-2000-01.html"
nr="1"
data="24 lutego 2000"
temat="Temat uchwały nr 1"/>
<uchwala
href="uchwala-2000-02.html"
nr="2"
data="24 lutego 2000"
temat="Temat uchwały nr 2"
description=/>
<uchwala
href="uchwala-2000-03.html"
nr="3"
data="25 maja 2000"
temat="Temat uchwały nr 3"/>
dalsze uchwały
</uchwaly>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="uchwaly">
<table border="0" cellspacing="0" cellpadding="4">
<tr>
<th>Nr</th>
<th>Data</th>
<th>Temat</th>
</tr>
<xsl:apply-templates select="uchwala"/>
</table>
</xsl:template>
<xsl:template match="uchwala">
<tr>
<td nowrap="nowrap"><xsl:value-of select="@nr"/></td>
<td><xsl:value-of select="@data"/></td>
<td><a href="{@href}"><xsl:value-of select="@temat"/></a></td>
</tr>
</xsl:template>
</xsl:stylesheet>
W trakcie opisywania czynności administracyjnych często pisaliśmy o atrybutach Ochrona dokumentu i Widoczność. W tym rozdziale dokładnie opiszemy znaczenie tych atrybutów.
Atrybut Widoczność przyjmuje dwie wartości: widoczny i ukryty. Informacja, że dokument nie jest widoczny nie oznacza, że dokumentu nie da się wyświetlić. Jest to możliwe, ale chcemy to utrudnić. Dokumenty takie nie będą wyświetlone przy standardowych metodach prezentacji zawartości katalogu. Nie zostaną również przekazane jako wynik wyszukiwania. Do dokumentów niewidocznych możemy się jednak odwołać wpisując w przeglądarce ścieżkę do dokumentu. Jeśli przejdziemy pomyślnie procedurę autoryzacji, to dokument taki zostanie wyświetlony. W ten sposób została ,,ukryta'' aplikacja administratorska. Nie jest ona widoczna, więc osoby niepowołane nie powinny się dowiedzieć o jej istnieniu. Jednak osoby o uprawnieniach administratorskich po wpisaniu ścieżki /admin mogą ją uruchomić. Atrybut ukryty otrzymują również aplikacje boczne (otaczające dokument główny), których nie chcemy wyświetlać w oknie głównym.
Atrybut Ochrona dokumentu przyjmuje pięć różnych wartości. Wartość publiczny oznacza, że dokument ten może odczytać każdy. Dokument będzie wyświetlony na liście prezentującej zawartość katalogu i jako wynik wyszukiwania. Wartość wymaga zalogowania oznacza, że dokument jest dostępny tylko dla użytkowników zarejestrowanych w systemie. Odwołania do dokumentu będą widoczne wewnątrz katalogów i jako wynik wyszukiwania, ale jeśli użytkownik nie jest zautoryzowany w systemie, to dokument nie zostanie wyświetlony. Wartość chroniony oznacza, że dokument podlega ochronie i jest dostępny wyłącznie dla użytkowników, którzy mają przypisane prawo Odczyt do tego dokumentu. Dla pozostałych użytkowników dokument nie będzie wyświetlany wewnątrz katalogów ani jako wynik wyszukiwania. Wartość wewnętrzny oznacza, że dokument jest wewnętrznym dokumentem systemowym. Dokumentu takiego nie da się wyświetlić przez wpisanie pełnej ścieżki do dokumentu. Nie będzie on wyświetlony ani jako wynik wyszukiwania, ani jako zawartość katalogu. Wartość nowy oznacza, że dokument został niedawno dołączony do portalu i administrator nie zdążył jeszcze zdefiniować jego atrybutów. Nie podlega on wyszukiwaniu ani wyświetlaniu.
Ogłoszenia i listy dyskusyjne są pogrupowane w dwóch poziomach hierarchii. Pierwszy poziom jest bardzo ogólny (podział np. na ogłosznia i forum dyskusyjne). W dalszej części pracy będziemy nazywali ten podział kategoriami. Drugi poziom jest bardziej szczegółowy (podział np. na ogłoszenia studenckie, pracownicze i ogólne). W dalszej części pracy będziemy nazywali ten podział kanałami.
W rozdziale tym opiszemy sposób dodania nowych kategorii i kanałów.
W celu dodania nowej kategorii o nazwie np. forum dyskusyjne musimy najpierw utworzyć katalog /news/forum_dyskusyjne na dysku. Następnie należy do tego katalogu wgrać plik sendnews.php. Przechowuje on informacje o formatce wykorzystywanej do wysyłania ogłoszeń w danej grupie kanałów. Następnie wykorzystując aplikację administratorską, rejestrujemy nowy katalog i plik w bazie dokumentów (np. poprzez automatyczne wczytanie zawartości katalogu /news). Kolejnym krokiem jest zdefiniowanie informacji o nowym katalogu i pliku wewnątrz bazy dokumentów.
Jedynymi atrybutami, które trzeba ustawić dla katalogu /news/forum_dyskusyjne jest Ochrona dostępu na publiczny, dostępny po zalogowaniu lub chroniony (w zależności od potrzeb), oraz Widoczność na Widoczny.
W pliku sendnews.php należy zaznaczyć Typ pliku jako XML, Ochrona dostępu na publiczny, oraz Widoczność na ukryty. Parametr wskazujący na arkusz XSLT powinien wskazywać na plik /forms ,służący do wyświetlania formularzy (por. rys. C.5).
Pierwszym krokiem służącym do zdefiniowania nowego kanału jest utworzenie nowego katalogu wewnątrz wybranej kategorii. Następnie katalog ten należy zarejestrować wewnątrz bazy dokumentów.
Nowy kanał powinien mieć ustawiony atrybut Widoczność na Widoczny. Parametr wskazujący na sposób wyświetlania katalogu powinien wskazywać na plik /news/level2o.index.php. Parametr Ochrona dostępu ustawiamy w zależności od wymagań (por. rys. C.6).
Jeśli uznaliśmy, że dotęp do kanału powinien być ograniczony powinniśmy zdefiniować uprawnienia do tego kanału. Wykorzystujemy do tego standardową aplikację administratorską.
Na przedstawionym powyżej rysunku przedstawiono konfigurację kanału, w którym wysyłać ogłoszenia mogą użytkownicy należący do grup Administratorzy i Pracownicy, a czytać mogą użytkownicy należący do grup Administratorzy, Pracownicy oraz Studenci (por. rys. C.7).
This document was generated using the LaTeX2HTML translator Version 99.2beta8 (1.43)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 XMportal.tex
The translation was initiated by Janina Mincer-Daszkiewicz on 2002-05-23