


Next: SB-PRAM
Up: Maszyna typu PRAM
Previous: Opis maszyny typu PRAM
Spis rzeczy
Fork
Fork jest językiem programowania dla maszyn typu PRAM ([7]). Składniowo
język ten jest oparty na Pascalu.
Najbardziej popularną konstrukcją używaną podczas tworzenia i analizowania algorytmów
równoległych (por. [4]) jest konstrukcja
-
- for <indeks> := <war1> to <war2> pardo <instrukcje>
W wyniku jej działania na procesorach o indeksach od <war1> do <war2> równolegle
jest wykonywany blok programu zapisany tutaj jako <instrukcje>. Autorzy języka
Fork zrezygnowali z tej konstrukcji i jej podobnych (różniących się składnią,
ale syntaktycznie tożsamych), zastępując je konstrukcjami start oraz
fork.
Język ten definiuje pewien model maszyny równoległej, w której podstawową jednostką
budowy jest procesor logiczny. Każdy taki procesor posiada swój numer (indeks),
przy czym liczba procesorów oraz układ ich indeksów może zmieniać się podczas
wykonywania programu. W konkretnej implementacji takiej maszyny wszystkie procesory
logiczne są rozpraszane między procesory fizyczne. Ponadto maszyna nie jest
modelem typu SIMD, lecz SPMD7, więc mniej restrykcyjnym jeśli chodzi o synchronizację.
Do określania procesorów dostępnych przez program w danej chwili służy konstrukcja
-
- start [<war1>..<war2>] <instrukcje> endstart
Wartości <war1> i <war2> określają pierwszy i ostatni numer procesora logicznego,
na których będzie wykonywany program opisany jako <instrukcje>. Po zakończeniu
wykonywania tej konstrukcji jest przywracany poprzedni stan maszyny (liczba
i numeracja procesorów). Numer procesora jest dostępny w kodzie programu poprzez
,,#'', ale nie musi on być unikatowy dla procesora w obrębie maszyny.
Procesory można podzielić na grupy. Procesory należące do danej grupy wykonują
swój program synchronicznie (w obrębie danej grupy). Dwie różne grupy procesorów
mogą więc wykonywać różne części tego samego programu. Do tworzenia podgrup
służy konstrukcja
-
- fork [<war1>..<war2>] <instrukcje> endfork
Wartości <war1> i <war2> określają pierwszy i ostatni numer tworzonych grup,
<instrukcje> -- kod programu, który będzie przez nie wykonywany. W trakcie
uruchamiania programu tworzona jest automatycznie grupa o numerze 0 zawierająca
jeden procesor o indeksie 0. Numer grupy jest dostępny w programie poprzez ,,@''.
Faktycznie oznacza on numer podgrupy w danej grupie. Po napotkaniu konstrukcji
fork... procesor na podstawie swoich danych w sposób określony przez
programistę decyduje, do której grupy chce należeć (w szczególności mogą istnieć
grupy puste). Dodatkowo można w tym momencie zmienić indeks procesora (będzie
to teraz faktycznie numer procesora w danej grupie). Autorzy nie specyfikują
zachowania się programu w przypadku, gdy dwa procesory z danej grupy zdecydują
się na zmianę swojego indeksu na identyczny. Po zakończeniu wykonywania bloku
<instrukcje> przywraca się poprzednią hierarchię grup oraz numery procesorów.
Istnieją jeszcze inne możliwości podziału procesorów na grupy (w sposób niejawny)
za pomocą konstrukcji warunkowych if... oraz case... . W obu
przypadkach podział następuje na podstawie spełnienia (lub nie) odpowiednich
warunków.
Kolejną cechą różniącą Fork od języków zazwyczaj wykorzystywanych do analizy
teoretycznej są rodzaje zmiennych globalnych. Zmienne deklarowane w programie
jako dzielone mogą być dostępne dla wszystkich procesorów logicznych lub na
przykład tylko dla procesorów z danej grupy (w przypadku zadeklarowania ich
wewnątrz składni fork... endfork...).
Jak już zostało nadmienione, autorzy zrezygnowali z konstrukcji for...
pardo... . Tłumaczą to tym, że nie daje się ona w poprawny sposób wykorzystać
w przypadku zagnieżdżania. Oto przykład:
-
- 1: for i:=1 to m pardo
2: for j:=1 to n pardo
3: op(i,j);
Podczas próby wywołania funkcji w wierszu 3 nie otrzymamy 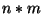 wywołań funkcji op. Wynika to z semantyki wykonania konstrukcji for...
pardo... , która przydziela odpowiednim procesorom kod programu do
wykonania.
wywołań funkcji op. Wynika to z semantyki wykonania konstrukcji for...
pardo... , która przydziela odpowiednim procesorom kod programu do
wykonania.
Istnieje jednak możliwość emulacji tej konstrukcji. W miejsce
-
- for i := <wyr 1> to <wyr 2> pardo <instrukcja>
należy użyć konstrukcji
-
- begin
-
- shared const a1 = <wyr 1>;
shared const a2 = <wyr 2>;
start [a1 .. a2]
-
- fork [a1 .. a2]
-
- @ = #;
# = 0;
begin
-
- shared var i : integer;
i := @;
<instrukcja>
end
endfork
endstart
end /* symulacja pardo */
Tworzy się w ten sposób a2-a1+1 grup jednoprocesorowych, procesor
znajdujący się w każdej z nich ma indeks 0 oraz dysponuje zmienną i oznaczającą
numer grupy.
Chociaż zastosowanie kombinacji konstrukcji start... oraz fork...
daje większe możliwości programistyczne, to jednak ogromna większość algorytmów
daje się w przejrzysty sposób zapisać za pomocą for... pardo... .
Użycie tej drugiej konstrukcji zazwyczaj upraszcza dodatkowo kod programu, zwalniając
programistę z konieczności pamiętania o rozdzieleniu procesorów do podgrup.
Next: SB-PRAM
Up: Maszyna typu PRAM
Previous: Opis maszyny typu PRAM
Spis rzeczy
Łukasz Maśko
2000-04-17