


Rozdział 3 Projekt i implementacja systemu
3.1 Ogólna
struktura systemu
Przedstawione w poprzednim rozdziale wymagania wobec systemu
determinują już częściowo jego architekturę. Jedną
z najważniejszych decyzji implementacyjnych, jakie należało podjąć,
był wybór sposobu prezentacji danych po stronie klienta. Było tu co
najmniej kilka możliwości.
Po pierwsze, można było stworzyć
rozwiązanie dedykowane dla mojego systemu. Pozwoliłoby to na najlepsze
dopasowanie cech programów klienckich do wymagań systemu. Z drugiej
strony rozwiązanie to ma sporo wad. Oprogramowanie klienckie należałoby
napisać od nowa i to w języku oferującym niezależność od
systemu operacyjnego (bo tego wymagamy od klienta). Praktycznie wchodzi
tu w grę tylko Java, nie zapewniająca najlepszej wydajności. Poza
tym trzeba by i tak generować oddzielny rodzaj danych do
wyświetlania w przeglądarce WWW. Wynika to z zadeklarowanej
w wymaganiach możliwości takiego dostępu do systemu. Mogłby on co
prawda oferować mniejszą funkcjonalność (np. konieczność ręcznego
odświeżania wartości parametrów).
Innym możliwym podejściem
jest zastosowanie przeglądarki WWW jako podstawowego oprogramowania
klienckiego. Rozwiązuje to problemy niezależności od systemu
operacyjnego, nie trzeba pisać i instalować oprogramowania
klienckiego. Takie rozwiązanie jest bardziej eleganckie i zgodne
z panującą obecnie tendencją do tworzenia aplikacji
wykorzystujących interfejs WWW. Umożliwia także czerpanie korzyści
z rozwoju technologii internetowych, nie zamyka systemu skazując go
na użycie specjalizowanych rozwiązań.
Jednak stosowany
w przeglądarkach język HTML niezbyt nadaje się do prezentacji
dynamicznej, interaktywnej grafiki. Umożliwia tylko wykorzystywanie
grafiki bitmapowej, wymagającej pobierania z serwera dużej ilości
danych. Tymczasem tworzone schematy mają charakter wektorowy
i lepiej by było, aby właśnie tak były prezentowane. Pozwala to
również na skalowanie i drukowanie bez utraty jakości.
Kłopotliwe byłoby także odświeżanie wartości parametrów. Niedopuszczalne
jest ściąganie całego, być może dużego obrazka w sytuacji, gdy
zmienił się w nim jeden napis. Nawet w szybkiej sieci lokalnej
nie dałoby się uniknąć widocznego odświeżania okna przeglądarki.
Wykorzystanie apletów Javy do prezentowania dynamicznej części schematu
oznaczałoby tak naprawdę tworzenie rozwiązania dedykowanego, tyle że
uruchamianego w przeglądarce WWW wyposażonej w maszynę
wirtualną Javy. Poza tym Java w przeglądarkach nie oferuje
wystarczającej stabilności.
Można sobie wyobrazić, że elementy
statyczne prezentowane są jako bitmapa w tle, a na niej
znajdują się wartości parametrów w postaci tekstowej. Dużo
ciekawsze efekty można jednak osiągnąć dopuszczając wpływ parametrów na
prezentowaną grafikę (np. termometr ze słupkiem rtęci pokazującym
temperaturę). Podobnie chcielibyśmy mieć możliwość umieszczania na
schemacie animacji i obszarów aktywnych (dowiązań). Tu także można
wyobrazić sobie generowanie animacji w postaci animowanych obrazków
w formacie GIF i użycie elementów <map/> HTML.
Jednak generowanie takiej strony byłoby rzeczą trudną i niektóre
efekty byłyby trudne lub niemożliwe do osiągnięcia.
Najlepiej
więc byłoby zmusić przeglądarkę do wyświetlania bezpośrednio
interaktywnej, dynamicznej grafiki wektorowej. Jednym ze sposobów jest
wykorzystanie wtyczek do wyświetlania stron wykonanych
w technologii Flash firmy Macromedia. Są one dostępne dla
wszystkich powszechnie używanych przeglądarek. Technologia ta jest dość
popularna właśnie między innymi ze względu na osiągane bardzo dobre
efekty wizualne, a także możliwość tworzenia stron dynamicznych
i interaktywnych. Z mojego punktu widzenia ma jednak także sporo
wad. Jest to format binarny, komercyjny produkt jednej firmy, dość
popularny, nie będący jednak standardem, jak np. HTML. O ile wtyczki są
bezpłatne, o tyle narzędzia do tworzenia stron kosztują sporo. Nie
ma także oczywiście żadnych narzędzi darmowych, rozpowszechniantch na
licencji pozwalającej na modyfikację kodu źródłowego, w tym na
przykład do generowania zawartości w technologii Flash po stronie
serwera HTTP.
Na zapotrzebowanie na prawdziwą grafikę
wektorową dla potrzeb WWW odpowiedziała w końcu instytucja najbardziej
do tego uprawniona -- World Wide Web Consortium (dalej będę się
posługiwał skrótem W3C). Pod koniec lat 90-tych rozpoczęła pracę nad
standardem SVG -- Scalable Vector Graphics. We wrześniu 2001 roku SVG
osiągnęła status rekomendacji, czyli oficjalnego starnardu W3C. Standard
definiuje oparty na XML język opisu grafiki wektorowej przeznaczonej do
stosowania w sieci Web. Więcej informacji o SVG znajduje się
w p. 3.2. Mimo
nienajlepszego poziomu rozwoju implemetacji SVG, możliwość wykorzystania
otwartego standardu oraz fakt, że docelowe zastosowanie SVG odpowiada
dokładnie moim potrzebom, zdecydowało o wyborze tego
rozwiązania.
Dodatkowym atutem jest oparcie SVG na XML, co
pozwala na proste i naturalne rozszerzanie SVG o dodatkowe
elementy, mieszanie z innymi typami danych (a więc osadzanie
w innych dokumentach XML), a także zapewnia otwartość
rozwiązania na przyszłe modyfikacje i ulepszenia.
Ponieważ, jak już pisałem, SVG nie ma jeszcze odpowiedniego wsparcia
w istniejących implementacjach, konieczne okazało się także
zapewnienie możliwości generowania zastępczej zawartości dla tych
użytkowników, którzy nie mogą lub nie chcą korzystać z przeglądarek
specjalizowanych do SVG lub odpowiednich wtyczek. Ponieważ ten sposób
prezentacji danych jest drugorzędny i stosowany raczej przez osoby
incydentalnie korzystające z systemu, uznałem za dopuszczalne
generowanie statycznej grafiki bitmapowej, z dodatkowymi
informacjami o dowiązaniach.
Mając wybrany format
prezentacji danych, należało się zastanowić nad formatem, w jakim
tworzone i przechowywane będą schematy po stronie serwera. Jednym z
możliwych rozwiązań jest stworzenie specjalizowanego języka wysokiego
poziomu opartego na XML, operującego takimi pojęciami jak rura, zawór,
miernik przepływu, pompa, obrotomierz itp. Schematy zapisane w tym
języku mogłyby być przekształcane na SVG automatycznie, np. za pomocą
procesora XSLT (XML Stylesheet Language Transformations -- więcej
o tym języku w p. 3.2). Rozwiązanie takie pozwalałoby
się poruszać na dość wysokim poziomie abstrakcji. Stracilibyśmy jednak
możliwość dowolnego kształtowania postaci graficznej schematu. Dodanie
nowego typu elementu oznaczałoby konieczność definiowania nowego
elementu języka. Poza tym należałoby wtedy stworzyć dedykowane narzędzia
do tworzenia schematów, co byłoby dość pracochłonne.
Zdecydowałem się więc na wykorzystanie bezpośrednio języka SVG,
wzbogaconego o rozszerzenia, które nazwałem Industry Schema Language
(ISL). Rozszerzenia te zrealizowane są w postaci przestrzeni nazw
XML (ang. XML namespace). Pozwalają one na wstawienie wartości
parametru jako zawartości elementu XML lub wartości atrybutu
elementu.
Wykorzystanie istniejącego języka rozwiązuje problem
narzędzi do tworzenia schematów i eksportu do (importu z) innych
formatów danych. Spośród kilku dostępnych darmowych edytorów SVG
wybrałem program Sodipodi, który lekko zmodyfikowałem do moich potrzeb.
Więcej informacji o Sodipodi znajduje się w p. 3.6. W razie potrzeby schematy można
tworzyć także za pomocą profesjonalnych programów do grafiki wektorowej,
takich jak Corel Draw czy Adobe Illustrator, których najnowsze wersje
pozwalają na import i eksport dokumentów w formacie SVG.
Kolejnym ważnym problemem do rozwiązania, była sprawa dostępu do
parametrów. Należało zaprojektować mechanizm, który byłby z jednej
strony na tyle ogólny, aby można go było połączyć z dowolnym
systemem typu SCADA, jak i na tyle dobrze dopasowany do systemu
SZARP, aby możliwa była jego implementacja bez zmian w tym
systemie.
Dodatkową trudność sprawia fakt, że mechanizm
powinien być niezależny od systemu operacyjnego, na którym działa system
bazowy. System SZARP działa pod kontrolą systemu operacyjnego GNU/Linux.
Tymczasem większość innych systemów SCADA wykorzystuje systemy Windows
(głównie wersje profesjonalne, a więc NT lub 2000). Jedynym
sensownym mechanizmem komunikacji międzyprocesowej niezależnym od
systemu operacyjnego (tzn. dostępnym w praktycznie każdym systemie
i funkcjonującym w środowisku heterogenicznym) jest protokół
TCP/IP.
W warstwie aplikacji można było zaprojektować własny
protokół lub wykorzystać np. różnego rodzaju mechanizmy RPC (ang.
Remote Procedure Call -- zdalne wywoływanie procedur). Jednak
rozwiązaniem prostszym, elastyczniejszym i dobrze przystosowanym do
przesyłania dużej ilości danych (a mamy przecież do czynienia
z grafiką) wydaje się protokół HTTP. Poza tym jest on powszechnie
używanym standardem, możemy korzystać z istniejących bibliotek
i narzędzi, co nie pozostaje bez wpływu na ilość pracy do wykonania
podczas implementacji.
Zdecydowałem się więc na implementację
prostego serwera HTTP, udostępniającego informację o parametrach
(dalej będę się posługiwał nazwą serwer parametrów). Informacja ta
generowana jest standardowo w postaci dokumentów XML. Jest to
oczywiście pewna rozrzutność, gdyż XML jest protokołem dość rozrzutnym
jeśli chodzi o ilość przesyłanych danych i narzut na przykład
przy pobieraniu wartości jednego parametru (a więc zwykle dwa bajty)
jest dość duży -- trzeba wygenerować kilkuwierszowy dokument. Jednak
przy wymaganej od systemu wydajności nie ma to żadnego znaczenia.
Pozwala za to na proste wklejanie uzyskanych w ten sposób danych do
schematów.
Serwer parametrów jest jedyną częścią systemu
zależną od konkretnego systemu SCADA czy innego źródła danych. Jego
zadaniem jest odczytanie konfiguracji bazowego systemu
i przekształcanie informacji o wartościach parametrów na
dokumenty XML wysyłane klientom. Poza tym ma on za zadanie przekazywanie
informacji w drugą stronę, od klienta do systemu bazowego --
w przypadku ustawiania wartości parametrów. Przy zadawaniu
parametrów zapewnia on bezpieczeństwo tej operacji przez autoryzację
HTTP i tunelowanie połączenia HTTP przez protokół SSL. Więcej
informacji o implementacji serwera parametrów znajduje się
w p. 3.5. We wcześniejszym p. 3.3 opisuję pokrótce najważniejsze
elementy architektury systemu SZARP, istotne z punktu widzenia
mojego systemu.
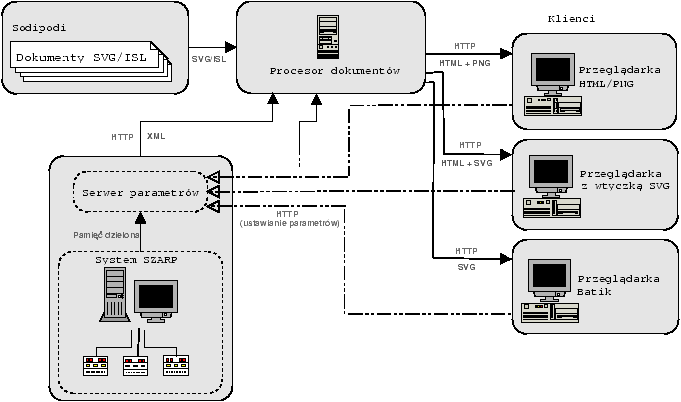
Rysunek 3.1: Ogólna architektura
systemu
Każdy prezentowany parametr jest związany z konkretnym udostępniającym go
serwerem parametrów. Zwykle serwer parametrów jest związany z jednym źródłem
danych (np. serwerem SZARP). Powiązanie takie w wykonanej implementacji wynika
między innymi z tego, że komunikacja między serwerem SZARP a serwerem
parametrów odbywa się przez pamięć dzieloną, a więc oba programy działają na
tej samej maszynie.
Możliwość prezentowania jednocześnie danych z różnych serwerów wymusza
powiązanie nazwy parametru z udostępniającym go serwerem. Naturalnym
rozwiązaniem jest tu
wykorzystanie systemu DNS -- nazw serwerów internetowych lub, równorzędnie,
adresów IP. Tak więc pełna nazwa parametru składa się z adresu internetowego
udostępniającego go serwera parametrów oraz nazwy parametru, unikatowej
w obrębie serwera. W związku z unikalnością nazw serwerów w sieci
Internet tak otrzymana pełna nazwa parametru jest jednoznaczna globalnie.
Ostatnim brakującym elementem systemu jest mechanizm pozwalający na pobranie
wartości parametrów z serwerów parametrów, wstawienie ich do zapisanych w
SVG/ISL schematów i wysłanie do zgłaszającego żądanie klienta jako SVG lub,
zastępczo, bitmapy. Ponieważ zarówno dane wejściowe, jak i przynajmniej jedna
z postaci
danych wyjściowych, są dokumentami XML, naturalne staje się wykorzystanie
do ich przetwarzania procesora XSLT, połączonego z serwerem HTTP. W ramach pracy
wykonałem dwie niezależne implementacje tego elementu systemu. Jedna
wykorzystuje kontener serwletów Javy Tomcat i serwer Cocoon. Druga jest moim
własnym rozwiązaniem, inspirowanym serwerem Cocoon. Obie pozwalają nie tylko na
automatyczne generowanie ze schematów dokumentów SVG i bitmap, ale
także innego rodzaju dokumentów, np. HTML. Więcej szczegółów na ten temat
zawiera rozdz. 3.7.1. Ten element systemu nazywam roboczo
procesorem dokumentów.
Ponieważ ustawianie wartości parametrów wymaga autoryzacji użytkownika i
szyfrowania połączeń, jest ono realizowane bezpośrednio na drodze
komunikacji klient -- serwer parametrów, z pominięciem procesora XSLT.
Jest to spowodowane między innymi przez brak obsługi szyfrowania SSL przez
biblioteki klienckie HTTP wykorzystywane przez obie implementacje
procesora dokumentów. Poza tym pozwala to uniknąć kłopotów z przekazywaniem
informacji o autoryzacji zarówno klienta, jak i serwera przez procesor XSLT.
Oczywiście to procesor dokumentów może generować stronę HTML, na której
znajduje się
formatka do wpisania nowej wartości parametru, jednak kliknięcie przycisku
Wyślij powinno inicjować komunikację bezpośrednio z serwerem parametrów.
Ostateczny kształt architektury systemu przestawiono na rys.
3.1. Podsumowując:
najniższą warstwę stanowi system SCADA lub inne źródło danych; w mojej
konkretnej implementacji jest to system SZARP. Nad nim znajduje się serwer
parametrów, o architekturze zależnej od konkretnego źródła danych. Prezentuje
on informacje o wartościach parametrów w postaci dokumentu XML, przez protokół
HTTP. Informacje te są pobierane przez procesor dokumentów, będący
połączeniem procesora XSLT i serwera HTTP. Są one wstawiane do przygotowanych
wcześniej przez użytkownika za pomocą edytora SVG + ISL schematów,
przekształcane na żądany format wyjściowy (na przykład SVG lub HTML +
PNG1)
i wysyłane do klienta.
3.2 Wykorzystane technologie
W pracy zastosowałem rozwiązania oparte na meta-języku XML (eXtensible
Markup Language).
Został on stworzony przez W3C jako uniwersalny język do
zapisywania danych różnych typów. W tej chwili ma już bardzo wiele zastosowań.
Oparty na nim XHTML jest najnowszą specyfikacją języka stosowanego do tworzenia
stron WWW. SOAP jest protokołem typu RPC opartym na XML. XBase pozwala na
tworzenie baz danych jako dokumentów XML. Istotnymi specyfikacjami nie będącymi
formalnie częścią XML-a, ale powszechnie używanymi w połączeniu z nim i
przyczyniającymi się do jego popularności, są specyfikację XML Namespaces
(pozwalająca na łączenie w jednym dokumencie XML danych różnych typów), XPath
i XPointer (określające sposób adresowania fragmentów dokumentów XML) oraz
XLink (służąca do opisywania połączeń między obiektami XML) [15].
Jednym z najczęstszych obecnych zastosowań XML-a jest używanie go do
zapisywania treści, które potem będą prezentowane na stronach WWW w postaci
dokumentów HTML lub innych. XML umożliwia oddzielenie treści dokumentu (jego
zawartości informacyjnej) od sposobu prezentacji. Ułatwia to zarządzanie
dużymi serwisami, umożliwia łatwe ich modyfikacje i generowanie z tych samych
informacji różnych dokumentów końcowych (np. stron WWW, dokumentów PDF i
innych).
Jest to także jednym z zadań XML w moim projekcie, gdzie schematy zapisane jako
dokumenty XML mają być prezentowane klientom w różnych postaciach, zależnie od
możliwości interfejsu, z którego korzystają.
Kluczowym mechanizmem w tego typu zastosowaniach jest mechanizm przekształcania
dokumentów XML na inne dokumenty. Do tego celu
służy język XSLT (XSL Transformations) [20].
Został on zaprojektowany jako język
pomocniczy wobec języka XSL (XML Stylesheet Language), służącego do
specyfikowania formatowania dokumentów XML. Podstawową rolą XSLT jest więc
określanie jak dokument XML ma być przekształcany na inny, sformatowany
dokument. XSLT może być jednak używany niezależnie od XSL. I choć jego autorzy
zastrzegają się, że nie był on tworzony jako język transformacji XML ogólnego
przeznaczenia, to ma dość dużą siłę wyrażania i jest powszechnie używany, np.
właśnie do generowania stron WWW z dokumentów XML. W moim projekcie okazał się
wystarczającym narzędziem do obróbki schematów.
Szablon XSLT składa się z zestawu zasad określających sposób przekształcania
elementów XML. Pojedyncza zasada zawiera wzorzec, do którego musi pasować
element,
aby zostać przez nią przekształcony, oraz z zawartości, określającej sposób
przekształcania elementu. Wzorzec jest wyrażeniem
XPath [18][19], co
umożliwia
wybieranie elementów na podstawie ich nazw, wartości atrybutów jak i położenia
wobec innych elementów w drzewie (bo dokument XML ma strukturę drzewa).
Zawartość określa, jak ma wyglądać przekształcony element. Może ona składać się
z części oryginalnego elementu, innych elementów (w tym zawartych w innych
dokumentach) oraz różnego rodzaju konstrukcji specyficznych dla XSLT, jak na
przykład instrukcji sterujących. Możliwość odwoływania się do innych
dokumentów, być może dostępnych przez sieć, była kluczowa dla projektowanego
systemu. Umożliwiła zastępowanie odwołań do wartości parametrów przez te
wartości, czytane z dokumentów XML udostępnianych przez serwer parametrów.
Więcej o szczegółach wykorzystania XSLT znajduje się w p.
3.7.1.
Inną bardzo ważną dla systemu technologią, także należącą do rodziny XML, jest
język opisu grafiki wektorowej SVG -- Scalable Vector Graphics. Został on także
opracowany przez World Wide Web Consortium i obecnie (od września 2001 roku)
ma status rekomendacji,
czyli oficjalnego standardu W3C. W pracach nad specyfikacją uczestniczyli
przedstawiciele zarówno dużych firm z ogólnie pojętej branży informatycznej
(takich jak Microsoft, IBM, Sun, Hewlett-Packard, Apple, Xerox, Nestscape),
jak i specjalizujących się w grafice (Corel, Adobe, Kodak). Ciekawostką może
być obecność wśród autorów przedstawicieli firmy Macromedia -- SVG wydaje się
bezpośrednią konkurencją dla sztandarowego produktu tej firmy, technologii
Flash [21].
SVG służy do opisu dwuwymiarowej wektorowej i mieszanej, wektorowo-rastrowej
grafiki. Wykorzystuje inne technologie XML-owe, takie jak XLink, XPointer, CSS
(Cascading Stylesheets -- arkusze stylów) i DOM2
(Document Object Model)2. Może
być łączony z językiem SMIL (Synchronized Multimedia Integration Language).
Został pomyślany jako standard prezentowania grafiki wektorowej w
przeglądarkach WWW. Umożliwia tworzenie dokumentów animowanych, bądź przy
wykorzystaniu
animacji deklaratywnych, bądź za pomocą skryptów modyfikujących
strukturę dokumentu (DOM). Dokumenty SVG mogą być w pełni interaktywne,
modyfikując swoją zawartość w odpowiedzi na działania użytkownika, także takie
jak zmiana powiększenia dokumentu. Każdy obiekt może być dowiązaniem.
Bez problemu można łączyć w jednym
dokumencie SVG, XHTML, MathML i ewentualne inne XML-owe języki prezentacji
danych. Standard przewiduje też możliwość rozszerzania języka przez
użytkownika, na potrzeby konkretnej aplikacji.
SVG udostępnia wszystkie podstawowe kształty graficzne, a więc linie, okręgi,
wielokąty i różnego rodzaju krzywe. Pozwala na bogate formatowanie tekstu,
łącznie z opisywaniem go na krzywej. Umożliwia stosowanie różnego rodzaju
wypełnień, zarówno pełnym kolorem, jak i gradientowych, czy też wypełniania
wzorcem rastrowym lub wektorowym. Obiekty można grupować, ustalać ich wzajemne
położenie, przenikanie, stopień przezroczystości, czy też stosować do nich
filtry graficzne -- standardowe lub samodzielnie definiowane. Bogactwo
specyfikacji czyni więc z SVG pełnowartościowy język opisu grafiki wektorowej.
Z drugiej strony implementacja całości specyfikacji jest trudna i pracochłonna.
Do dziś, mimo kilku lat istnienia języka (choć dopiero przez rok
w postaci oficjalnego
standardu), nie powstała żadna implementacja, spełniająca w 100 procentach
całą specyfikację.
Najpopularniejszą przeglądarką SVG jest w tej chwili Adobe SVG Viewer 3.0,
działający na zasadzie wtyczki do przeglądarki WWW.
Oferuje on stosunkowo dobry stopień realizacji specyfikacji. Brakuje jednak
pełnego wsparcia dla modyfikacji dokumentu przez skrypty. Istnieją wersje dla
przeglądarek pracujących pod kontrolą systemów operacyjnych Windows, MacOS i
GNU/Linux (tylko Mozilla). Starsza wersja wtyczki (2.0) jest standardowo
dostępna w niektórych nowszych
wersjach Internet Explorera. Wtyczkę można ściągnąc
bezpłatnie ze stron Adobe, choć oczywiście kod źródłowy nie jest dostępny.
Firma Adobe jest zdecydowanie liderem we wspieraniu rozwoju standardu SVG.
Możliwość edycji dokumentów SVG, w tym także animacji, posiadają programy Adobe
Illustrator i Adobe GoLive!. Podobne możliwości mają także najnowsze
wersje konkurencyjnego programu CorelDraw. Obsługa SVG w tych
najpopularniejszych obecnie programach do obróbki grafiki wektorowej dobrze
rokuje przyszłości języka.
Możliwość eksportu grafiki w formacie SVG jest dostępna także w najnowszych
wersjach większości darmowych programów graficznych, wchodzących w skład
popularnych dystrybucji systemu Linux, takich jak np. Sketch czy Kontour (część
pakietu KOffice). Zwykle gorzej jest z poprawnym odczytywaniem dokumentów SVG.
Pozytywnie na tym tle wypada będący częścią projektu GNOME program Sodipodi,
który wybrałem jako podstawowe narzędzie edycyjne dla tworzonego przeze
mnie systemu. Więcej informacji o wykorzystaniu Sodipodi znajduje się w p.
3.6.
Innym ważnym projektem związanym z implementacją SVG jest projekt Batik,
prowadzony przez Apache Foundation. Batik to zestaw bibliotek w Javie, na
podstawie których zbudowano między innymi najlepszy (przynajmniej z dostępnych
bezpłatnie) rasterizer SVG, a także przeglądarkę. Najnowsza dostępna wersja
przeglądarki Batik, 1.5, w chwili pisania pracy znajduje się jeszcze w fazie
beta, niemniej jednak oferuje najpełniejszą realizację specyfikacji.
Ograniczenia związane są głównie z tym, że niestety Batik jest tylko
przeglądarką SVG, a więc nie wspiera wzajemnego
zagłębiania dokumentów SVG, XHTML, czy MathML. Bardziej obiecujący pod tym
względem jest projekt Mozilla SVG, czyli implementacja SVG bezpośrednio w
przeglądarce Mozilla. Niestety, w tej chwili nie rozwija się on zbyt
dynamicznie i implementowana jest poprawnie tylko niewielka część
specyfikacji.
Dostępnych jest wiele innych narzędzi, zarówno komercyjnych, jak i darmowych.
Są wśród nich zarówno przeglądarki, edytory, narzędzia do generowania
SVG po stronie serwera WWW,
jak i wiele konwerterów z innych
formatów, np. z dokumentów programu AutoCAD czy map cyfrowych. W miarę pełną i
aktualną listę implementacji można znaleźć na stronach W3C [14].
Standard SVG jest nadal rozwijany. W tej chwili dostępne są już wersje 1.1 i
1.2 specyfikacji. Wprowadzają one między innymi modularyzację SVG, która ma
umożliwić łatwiejszą implementację podstawowego zakresu funkcji, głównie z
myślą o urządzeniach przenośnych.
Można by chyba zaryzykować stwierdzenie, że SVG trafił w potrzeby
rynku, a mimo początkowych trudności z implementacją, przekroczona została
pewna masa krytyczna, powyżej której będzie on zyskiwał coraz większą
popularność i będzie powstawać coraz więcej implementacji.
Stosowanie w projekcie standardowych rozwiązań pozwoliło mi na duże
uproszczenie implementacji, przez możliwość korzystania z gotowych elementów,
zarówno programów, jak i bibliotek programistycznych. Miałem także komfort
korzystania ze sprawdzonych rozwiązań, bez ryzyka popełnienia poważnych błędów
projektowych, np. przy specyfikowaniu formatów używanych dokumentów. Cenną cechą
rozwiązań opartych na XML jest prostota ich modyfikacji, rozszerzania, łączenia
z innymi systemami i dostosowywania do nowych zadań.
3.3 System SZARP -- źródło
danych
Wykonana implementacja
systemu wizualizacji korzysta z systemu SZARP jako źródła danych. I
mimo, że jednym z założeń projektu jest możliwość współpracy
z jak najszerszą klasą systemów typu SCADA i innych, to
krótkie omówienie budowy i cech systemu SZARP jest istotne dla
wyjaśnienie niektórych przyjętych rozwiązań, zwłaszcza dotyczących
wykonanej implementacji. Poza tym pozwala to na zaprezentowanie
przykładowego systemu SCADA.
Geneza systemu sięga lat
80-tych [8]. W roku
1983 powstała firma Praterm, zajmująca się automatyzacją ciepłownictwa.
Początkowo wykorzystywała urządzenia elektromechaniczne, a od 1989
roku mikroprocesorowe sterowniki przemysłowe. Wkrótce okazało się, że
dla potrzeb prowadzenia różnego rodzaju analiz potrzebna jest
rejestracja wartości parametrów, charakteryzujących przebieg procesu
technologicznego w ciepłowni. W roku 1991 powstał pierwszy program,
napisany w Turbo Pascalu pod DOS-em, rejestrujący dane zbierane
przez łącza RS-232. W miarę rozwoju do systemu dodawano kolejne
aplikacje, SZARP został też przeniesiony na platformę UNIX (kolejno były
to systemy USL Unix SVR4.2 firmy Consensys, Novell UnixWare 1.1
i 2.03, SCO UnixWare 2.1). W roku 1994 Piotr Branecki i Lucjan
Przykorski obronili na Wydziale Elektroniki i Technik Informatycznych
Politechniki Warszawskiej pracę ,,System zbierania danych
i sterowania wolnozmiennych procesów technologicznych
o rozproszonych punktach kontrolno-pomiarowych'', dotyczącą
SZARP-a. W 1996 roku nie posiadający dotychczas nazwy system został
oficjalnie nazwany ,,System Zbierania, Archiwizacji i Prezentacji
Danych SZARP v2.0'' (wersja 1.0 to wersja pracująca pod DOS-em). W roku
1998 system przeniesiono na Linuksa i oznaczono numerem wersji
2.1. W tej chwili system jest zainstalowany w 23 ciepłowniach
w 20 miastach w całej Polsce.
System nigdy nie był
oferowany jako samodzielny produkt. Zawsze stanowił część kompleksowej
oferty modernizacji ciepłowni i służył do osiągnięcia określonych
efektów ekonomicznych, takich jak zmiejszenie zużycia opału czy energii
elektrycznej.
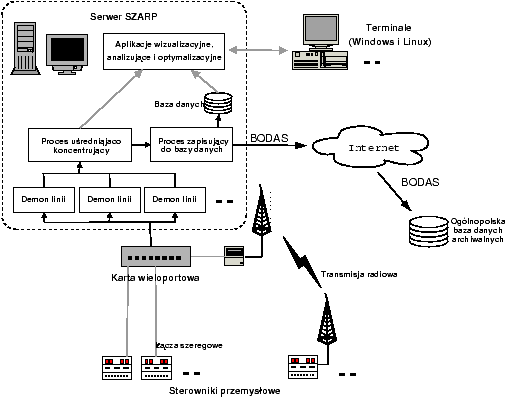
Rysunek 3.2: Uproszczony schemat architektury
systemu SZARP
Obecnie
w architekturze systemu można wyróżnić kilka warstw [4].
Najniższą stanowią
mikroprocesorowe programowalne sterowniki przemysłowe. Wykonują one
programy technologiczne, bezpośrednio sterujące przebiegiem procesu
technologicznego. Poza tym udostępniają w postaci cyfrowej informacje
o wartościach kontrolowanych parametrów.
Dane ze sterowników są transmitowane za pomocą łączy szeregowych różnego typu
lub łączy radiowych do wieloportowej karty podłączonej do komputera klasy PC
-- serwera systemu SZARP. Jest to maszyna średniej klasy, wyposażona zwykle w 64
do 256 MB pamięci RAM i dysk (najczęściej SCSI) o pojemności kilku do
kilkudziesięciu GB. Jedynym specjalnym wyposażeniem komputera jest karta
wieloportowa, zwykle typu Specialix lub Moxa, czasem także pyłoszczelna obudowa
i specjalna przemysłowa myszka i klawiatura. Związane jest to z dużym
zapyleniem ciepłowni.
Dodatkowym wyposażeniem jest
często UPS. Komputer działa pod kontrolą systemu operacyjnego RedHat Linux.
Do każdego z obsługiwanych portów szeregowych przyporządkowany jest program,
zwany demonem linii. Podstawowym jego zadaniem jest zmiana formatu danych ze
specyficznego dla protokołu obsługiwanego przez dany sterownik do wspólnego dla
całego systemu. Przetworzone dane są wstawiane przez demony linii do segmentu
pamięci dzielonej, utworzonego przez program należący do następnej warstwy
systemu -- centralny proces uśredniająco-koncentrujący.
Na danym komputerze istniej tylko jeden taki proces.
Zbiera on dane wstawiane
do pamięci dzielonej przez demony linii, wylicza średnie kroczące oraz tzw.
parametry definiowalne (czyli wyliczane na podstawie innych) oraz udostępnia te
dane procesom wyższych warstw, także poprzez pamięć dzieloną. Synchronizacja
dostępu do segmentów pamięci dzielonej odbywa się za pomocą semaforów,
w klasycznym schemacie czytelników i pisarzy.
Kolejnym istotnym elementem systemu jest program zapisujący dane do bazy. Co 10
minut zapisuje on odczytane z segmentu pamięci procesu uśredniającego średnie
10-minutowe do
bazy w formacie dBase IV. Przeliczane i zapisywane są także średnie 8-godzinne,
dobowe, tygodniowe i miesięczne. Program wyposażony jest w funkcje
automatycznego naprawiania uszkodzonych plików i odtwarzania danych z
tworzonych kopii zapasowych. Ilość generowanych przez system danych nie jest
zbyt duża. Rejestracja jednego parametru przez okres jednego roku wymaga
stu kilkudziesięciu kilobajtów miejsca na dysku. W obsługiwanych systemach
parametrów jest zwykle kilkaset do kilku tysięcy.
Interesującą funkcją programu jest system BODAS (Baza Ogólnopolska Danych
Archiwalnych Systemu SZARP). Dane z wszystkich posiadających połączenie
z Internetem ciepłowni są transmitowane do serwera w siedzibie firmy Praterm
w Warszawie. Przesyłane są tylko dane dodane lub zmodyfikowane. Rozwiązanie
działa zarówno dla ciepłowni posiadających łącza SDI (wtedy aktualizacja
następuje co 10 minut), jak i przy pomocy dostępu przez modem
(w tym wypadku aktualizacja zwykle raz na dobę). System BODAS pozwala na
przeglądanie danych archiwalnych z wszystkich obsługiwanych systemów
w siedzibie firmy Praterm oraz znacząco zwiększa szansę odzyskania większości
danych w przypadku np. awarii dysku w serwerze. BODAS jest wykorzystywany także
lokalnie, jeśli zachodzi potrzeba przeglądania danych z bazy serwera na innym
komputerze, np. drugim serwerze czy terminalu linuksowym.
Wszystkie pozostałe programy wchodzące w skład systemu korzystają z danych
przygotowywanych albo przez proces uśredniający (i odczytywanych z pamięci
dzielonej), albo też odczytywanych z bazy danych.
Do programów tych należą różnego rodzaju programy analizujące i optymalizujące,
działające w tle. Do innej klasy należą programy służące do prezentacji danych,
zarówno archiwalnych jak i bieżących. Jednym z takich programów jest też
tworzony w ramach pracy magisterskiej system wizualizacji.
Część z programów prezentacji danych została napisana w C, z wykorzystaniem
bibliotek Motiff. Są one uruchamiane albo bezpośrednio na serwerze, albo na
terminalu linuksowym, albo z terminala działającego pod kontrolą system
operacyjnego Windows, z wykorzystaniem emulatora X terminala. Część nowszych
programów jest napisana w języku skryptowym Tcl/Tk, dostępnym zarówno pod
Linuksem, jak i pod Windows.
Uproszczony schemat architektury systemu SZARP przestawia rys. 3.2.
W tego typu dość skomplikowanym systemie istotna jest łatwość i elastyczność
konfiguracji. O ile zastosowanych w systemie SZARP rozwiązań jest dość wygodna
(np. konfiguracja na
wszystkich serwerach i terminalach w obrębie jednej ciepłowni może być
jednakowa), to ogólnie konfiguracja systemu jest dość skomplikowana, a niektóre
rodzaje modyfikacji są żmudne i pracochłonne. Zmiana tego faktu
będzie
prawdopodobnie w najbliższym czasie jeden z podstawowych kierunków rozwoju
systemu.
W moim projekcie korzystam z bibliotek, będących częścią systemu SZARP. Jedną
z nich jest prosta biblioteka umożliwiająca zbierania i przechowywanie
informacji o ważnych zdarzeniach w systemie, druga to
biblioteka obsługująca pliki konfiguracyjne systemu SZARP. Obie biblioteki są
mojego autorstwa (chociaż druga korzysta z wcześniej napisanego kodu). Mogą one
być używane niezależnie od pozostałych części SZARP-a i zostały dołączone do
kodu źródłowego projektu.
3.4 Biblioteka serwera HTTP
Zarówno serwer parametrów, jak i procesor dokumentów są serwerami HTTP.
Pojawiło się więc pytanie, w jaki sposób zrealizować tą część funkcjonalności
programów. Nie istnieją w tej chwili darmowe biblioteki serwerowe HTTP.
Należało więc albo skorzystać z gotowych rozwiązań przez napisanie programów w
postaci skryptów CGI lub modułów serwera Apache, albo też stworzyć
własne rozwiązanie.
Zdecydowałem się na to drugie rozwiązanie, ze względu na to, że nie
chciałem wymuszać
na użytkownikach instalacji i konfiguracji serwera Apache. Uznałem, że lepiej
będzie, jeśli oba programy będą miały postać samodzielnych aplikacji.
Niejako więc przy okazji, jako produkt uboczny pracy, powstała biblioteka
serwerowa HTTP, napisana w C++. Wybór języka został podyktowany wydajnością
i koniecznością
współpracy z serwerem parametrów, który musi czytać dane z pamięci
dzielonej (a więc najwygodniej było go napisać w C lub C++). Zaś napisanie
biblioteki w C++, a nie C, pozwoliło na stworzenie obiektowego interfejsu,
łatwiejszego w użyciu i modyfikacji. Podstawową wadą użycia języka tak niskiego
poziomu jest oczywiście podatność na trudno wykrywalne błędy związane z
zarządzaniem pamięcią. Ze względów wydajnościowych oraz ewentualnej
przenośności biblioteki nie wykorzystywałem zaawansowanych funkcji języka C++,
takich jak szablony (ang. templates), wielokrotne dziedziczenie czy
wyjątki.
Protokół HTTP jest dość rozbudowany. Nie była moim celem ani ambicją pełna
implementacja protokołu. Jedynym kryterium doboru implementowanych funkcji HTTP
była ich użyteczność dla zastosowania w moim projekcie i bezproblemowa
współpraca biblioteki
z najczęściej spotykanymi na rynku przeglądarkami, głównie Internet
Explorer, Netscape Navigator, Mozilla (w różnych odmianach) i Lynx.
Oto krótka lista implementowanych funkcji protokołu HTTP:
-
Obsługa żądań GET protokołu w wersji 1.0 i 1.1.
-
Obsługa opcji podawanych w ścieżce dostępu do żądanego zasobu (po znaku
?).
-
Obsługa połączeń typu Close i Keep-Alive.
-
Obsługa autoryzacji połączenia HTTP Basic.
-
Obsługa przekierowań (nagłówka Location).
-
Obsługa kompresji wysyłanych danych (nagłówek Content-Coding).
-
Obsługa nagłówka Expires.
Ta lista nie wyczerpuje wymagań, jakie specyfikacja protokołu HTTP [7]
stawia wobec implementacji bezwarunkowo zgodnych
(ang. unconditionally compliant) lub warunkowo zgodnych
(ang. conditionally compliant). Na przykład
specyfikacja wymaga, aby serwer HTTP/1.1 obsługiwał także żądania
HEAD. Poza tym moja implementacja jest mniej rygorystyczna niż zakłada
specyfikacja i uznaje za poprawne niektóre żądania klienta, które w świetle
specyfikacji poprawne nie są (np. żądania GET HTTP/1.1 bez nagłówka
Host).
Biblioteka nie ma właściwie żadnego wsparcia dla obsługi schowków, zarówno po
stronie serwera, serwera proxy, jak i przeglądarki. Wynika to
ze specyfiki projektu, w którym przecież prezentowane dane i tak co kilka sekund
się zmieniają, nie ma więc potrzeby ani sensu ich przechowywać. Jedynym
wsparciem dla schowka po stronie klienta jest obsługa nagłówka
Expire. Z jednej strony służy on do wymuszenia na przeglądarce
ściągania z serwera nowych wersji stron zawierających dynamiczne dane, z
drugiej strony może poinformować przeglądarkę, że powinna trzymać w schowku
niektóre dane, np. statyczne elementy grafiki stron WWW.
Biblioteka obsługuje nie tylko zwykłe połączenia HTTP, ale także połączenia
tunelowane z użyciem protokołów SSL (Secure Sockets Layer) w wersji 2 i 3,
oraz TLS 1.0 (Transport Layer Security). Korzysta w tym celu z biblioteki
OpenSSL [11].
Obsługa szyfrowanych połączeń w połączeniu z obsługą autoryzacji
HTTP Basic pozwala na zapewnienie pełnej kontroli dostępu i poufności
przesyłanych danych.
Klasa odpowiedzialna za autoryzację użytkowników jest oczywiście elementem
wymiennym. Klasa używana standardowo w projekcie zapewnia kontrolę
dostępu na poziomie elementów ścieżki dostępu do żądanego zasobu.
Przez
elementy ścieżki dostępu rozumiem fragmenty ścieżki oddzielone znakami ukośnika
/. Zazwyczaj będą to katalogi i pliki, w serwerze parametrów będą to
grupy parametrów i parametry (zobacz opis serwera parametrów w rozdziale
3.5).
Każdemu elementowi może być przyporządkowana
dowolna liczba użytkowników, którym pozwalamy na dostęp do elementu i wszystkich
elementów podrzędnych (a więc np. do podkatalogów i plików w katalogu lub
wszystkich parametrów z grupy). Opis praw dostępu trzymany jest w jednym pliku,
o formacie opisanym w dodatku D.1.3.
Poza nazwą użytkownika wymagane jest także hasło. Sprawdzanie użytkownika i
hasła
przeprowadza się z użyciem systemowych mechanizmów PAM (Pluggable
Authentication Modules), co pozwala na użycie różnych mechanizmów autoryzacji
bez modyfikacji w programie. Powinna być to jednak autoryzacja korzystająca
z nazwy użytkownika i hasła,
gdyż taki schemat jest używany przez protokół HTTP.
Autoryzacja jest
wymagana tylko przy próbach zapisu, czyli jeżeli w ścieżce dostępu do
zasobu pojawi się opcja put. Jest więc zdefiniowany tylko jeden rodzaj operacji na zasobie (nie ma oddzielnych praw dla odczytu, zapisu itp.).
Przeglądarki po pierwszej autoryzacji użytkownika wysyłają nazwę
użytkownika i hasło przy każdym następnym odwołaniu do strony. Aby zapobiec
sytuacji, w której użytkownik po przeprowadzonej autoryzacji zostawia
komputer bez opieki bez wyłączania przeglądarki lub zmiany strony, po zadanym
czasie autoryzacja wygasa. Jest to realizowane przez wysyłanie
fałszywej informacji o nieudanej autoryzacji, jeżeli poprzedni dostęp do
strony odbył się dawniej niż zadany czas temu. Użytkownik musi ponownie
wprowadzić nazwę użytkownika i hasło, co pozwala stwierdzić, czy z przeglądarki
nadal korzysta osoba uprawniona.
Taka
implementacja wynika z wymagań serwera parametrów. Jeśli potrzebny byłby
inny system kontroli dostępu, to konieczne byłoby
przedefiniowanie klasy odpowiedzialnej za kontrolę dostępu.
Dodatkowo, biblioteka dość niestandardowo obsługuje niektóre postacie ścieżek
dostępu podawane przez klienta. Za ścieżkę dostępu uznawana jest tylko część do
napotkania znaku @. To co jest po nim (a przed opcjami, czyli znakiem
?) jest traktowane specjalnie -- jako nazwa atrybutu elementu XML.
Zachowanie to, mimo że niestandardowe, nie powinno przeszkadzać w aplikacjach
nie korzystających z niego, gdyż zwykle ścieżki dostępu do zasobów w sieci WWW
nie zawierają znaków @.
Biblioteka ma klasyczną architekturę serwera
wielowątkowego. Główny wątek nasłuchuje na zadanym porcie. Po zaakceptowaniu
połączenia przekazuje je do wątku obsługującego połączenie. Wątków takich może
być nie więcej niż liczba podana w konfiguracji serwera. Wątki tworzone
są na żądanie, ale tylko raz -- wątek, który zakończył obsługę połączenia jest
przenoszony do puli wolnych i budzony ponownie w razie potrzeby. Jest to
rozwiązanie szybsze niż tworzenie nowego wątku przy każdym nowym połączeniu.
Wątki obsługują połączenia asynchronicznie, za pomocą funkcji select().
W pliku konfiguracyjnym można określić tzw. timeout, czyli czas, po
jakim połączenie jest zamykane w przypadku braku aktywności. Jeżeli klient
sobie tego zażyczył, obsługiwane są połączenia typu Keep-Alive
(domyślne dla protokołu HTTP w wersji 1.1).
Połączenia takie nie są zrywane po zakończeniu
transmisji danych, co pozwala na przesyłanie dalszych danych do przeglądarki za
pomocą tego samego połączenia TCP/IP, bez konieczności negocjowania
nowego [7].
Biblioteka implementuje prostą strategię zapobiegania wykorzystaniu całej puli
wątków przez połączenia typu Keep-Alive. Jeżeli liczba wątków
aktywnych przekroczy 80 procent maksymalnej, to
po zakończeniu transmisji danych połączenia się zamyka.
Mimo formalnego
braku zgodności biblioteki z wymaganiami stawianymi przez specyfikację
protokołu HTTP, starałem się, aby zachowanie biblioteki było czytelne dla
aplikacji klienckich, między innymi przez ustawianie odpowiednich kodów błędów
(w tym oznaczających brak implementacji danej funkcji).
Najważniejsze klasy wchodzące w skład biblioteki to:
-
Klasa Server jest główną klasą, przyjmującą połączenia na zadanym
porcie i przekazującą je do obiektu typu AbstractConnectionHandler.
Nie ma potrzeby przedefiniowywania tej klasy w aplikacjach użytkownika.
-
Klasa ConfigLoader służy do przekazania do biblioteki opcji
konfiguracyjnych, takich jak numer portu, maksymalna liczba jednocześnie
obsługiwanych połączeń, ścieżka do pliku z opisem praw dostępu do zasobów
serwera i tym podobne. Ta implementacja korzysta z biblioteki
libparNT, będącej
częścią systemu SZARP. Format pliku konfiguracyjnego opisano w dodatku
A.1.
-
Klasa ConnectionHandler jest odpowiedzialna za obsługę konkretnego
połączenia z klientem. Uruchamia wątek odpowiedzialny za obsługę połączenia,
odbiera i parsuje żądanie klienta, przekazuje je do klasy odpowiedzialnej za
przygotowanie odpowiedzi, przekazuje odpowiedź klientowi. Podklasa
AuthConnectionHandler obsługuje transmisje tunelowaną z użyciem
protokołów SSL/TLS, przeprowadza także autoryzację użytkownika.
-
Klasa ConnectionCounter jest licznikiem otwartych połączeń (pełniąc
rolę semafora używanego przez klasę Server), a poza tym przechowuje
pulę
wolnych wątków do obsługi połączeń.
-
Klasa AccessManager służy do autoryzacji użytkownika według opisanego
wcześniej schematu, z użyciem PAM.
-
Klasa AbstractContentHandler jest abstrakcyjną klasą, odpowiedzialną
za przygotowanie odpowiedzi na żądanie klienta. Aplikacja musi dostarczyć
odpowiednią podklasę, realizującą pożądaną funkcjonalność. Podklasa musi
przedefiniować metodę create, która otrzymuje jako parametry obiekt
klasy
HTTPRequest, reprezentujący sparsowane żądanie klienta, oraz obiekt
klasy HTTPResponse, którego pola metoda musi wypełnić przygotowując
odpowiedź dla klienta. Klasa zawiera też metodę
set, wywoływaną, gdy żądanie klienta zawiera opcję put.
W założeniu ma ona służyć do transmisji danych od klienta do serwera, np. przy
ustawianiu wartości parametru w serwerze parametrów. To, do czego metodę
wykorzysta konkretna aplikacja, zależy tylko od niej.
Przykładowy program korzystujący z biblioteki mógłby wyglądać tak (opuszczono
kontrolę błędów i niektóre mniej istotne fragmenty):
class MyContentHandler : public AbstractContentHandler {
public :
XSLTContentHandler(void) { };
virtual void create(HTTPRequest *req, HTTPResponse *res)
{
res->content = strdup("To jest odpowiedź");
res->content_length = strlen(res->content);
}
virtual int set(HTTPRequest *req) { return 0; };
};
int main(int argc, char **argv)
{
ConfigLoader *cloader;
Server *server;
ConnectionHandler *ch;
AbstractContentHandler *conh;
// Wczytaj informacje z pliku konfiguracyjnego i wiersza poleceń.
cloader = new ConfigLoader("plik.konf", "sekcja_w_pliku_konf",
&argc, argv);
// Utwórz obiekt odpowiedzialny za odpowiadanie na żądania klienta
conh = new MyContentHandler();
// Inicjowanie obsługi połączeń, ustaw timeout dla połączeń
ch = new ConnectionHandler(conh, cloader->getInt("timeout", 30));
// Inicjowanie serwera, argumentami są port, obiekt obsługujący
// połączenia oraz maksymalna liczba połączeń
server = new Server(cloader->getInt("port", 8081),
ch,
cloader->getInt("max_cons", 20));
// Uruchom serwer
server->start();
}
Stworzona biblioteka miała służyć konkretnym celom -- implementacji programów
wchodzących w skład mojego systemu -- i dobrze spełnia swoje zadanie,
współpracując bez problemów z przeglądarkami oraz bibliotekami klienckimi HTTP
(takimi jak NanoHTTP wchodząca w skład biblioteki libxml2).
Przy okazji powstało narzędzie ogólniejsze, niezależne od reszty projektu,
mogące służyć do implementacji
innych prostych, niewielkich serwerów HTTP. Zaletą biblioteki jest proste API,
małe rozmiary i
obsługa transmisji szyfrowanych. Główną wadą jest niewielki zakres
zaimplementowanej funkcjonalności protokołu HTTP i specyfika niektórych
rozwiązań (głównie kontroli dostępu).
3.5 Serwer parametrów
Serwer parametrów jest jednym z istotniejszych elementów całego systemu.
Zapewnia on łącze między bazowym systemem typu SCADA,
związanym z konkretną architekturą sprzętową, a wyższymi warstwami,
wykorzystującymi technologie oparte na XML. W opisie skoncentruję się na
wykonanej implementacji, przystosowanej do współpracy z systemem SZARP, a
dopiero na końcu poświecę kilka słów możliwościom dostosowywania programu do
współpracy z innym źródłem danych.
Ze względu na konieczność korzystania z pamięci dzielonej oraz napisanej w C++
biblioteki serwerowej (p. 3.4) serwer parametrów
napisano w prostym C++, bez obsługi wyjątków (co pozwala na tworzenie
przez kompilator szybszego i bardziej zwartego kodu).
Informacje o parametrach są czytane z pamięci dzielonej procesu
uśredniająco-koncentrującego systemu SZARP.
W tym celu przy starcie program
czyta pliki konfiguracyjne systemu SZARP i buduje wewnętrzną reprezentację
zbioru obecnych w systemie parametrów w postaci drzewa XML3.
Wartości
parametrów, o ile są dostępne, są czytane tylko na żądanie klientów, ale nie
częściej niż co zadany czas odświeżania (standardowo w systemie SZARP jest to 10
sekund) -- wartości parametrów mogą więc być
buforowane przez program. Przed udostępnieniem
informacji o wartościach parametru muszą one zostać przekształcone do postaci
tekstowej zgodnie z dodatkowymi informacjami uzyskanymi z plików
konfiguracyjnych (a więc np. liczbą miejsc po przecinku czy też reprezentacją
wartości w postaci napisów ,,Tak'' i ,,Nie'').
Segment pamięci dzielonej jest przy każdym odczycie na nowo podłączany do
przestrzeni adresowej programu. Jest to rozwiązanie wolniejsze, ale pozwala na
przetrwanie bez szkody ewentualnych przerw w działaniu procesu udostępniającego
dane. Synchronizacja dostępu do pamięci dzielonej jest wykonywana za pomocą
semaforów.
W systemie SZARP parametry przechowuje się w jednowymiarowej tablicy. Jednak
dla potrzeb różnego rodzaju programów prezentujących ich wartości, grupuje się
je logicznie w strukturę drzewiastą. Strukturę tą wyznaczają pełne nazwy
parametrów, składające się z części oddzielonych dwukropkami. Struktura
drzewiasta jest budowana na podstawie wspólnych części nazw. Np. parametry
Kocioł 1:Sterownik:temperatura zadana i Kocioł
1:Sterownik:aktualne wysterowanie falownika rusztu można traktować jako
liście w drzewie, których ojcem jest węzeł Sterownik, będący synem
węzła Kocioł 1, który jest synem węzła głównego (korzenia)
drzewa. Taka struktura logiczna ułatwia zarządzanie i przeglądanie informacji o
parametrach, umożliwiając np. automatyczne tworzenie zestawień parametrów
dotyczących danego kotła.
Naturalnym rozwiązaniem było przeniesienie tej struktury także do serwera
parametrów. Ponieważ jednak serwer parametrów nie ma być związany z konkretnym
systemem SCADA oraz ponieważ takie rozwiązanie jest bardziej naturalne z punktu
widzenia przeglądarek WWW, zdecydowałem się na zastąpienie znaku :
znakiem /, zwłaszcza że dwukropek w URI4
pełni już inną funkcję --
poprzedza numer portu. W razie potrzeby z takiej postaci nazwy parametru można
oczywiście bez problemu uzyskać nazwę oryginalną (i to właśnie robi program,
wyszukując zadanych parametrów). Nazwy w tej postaci przekazywane są
bezpośrednio do serwera parametrów w żądaniach HTTP. Tak więc, aby uzyskać
informację o jednym z poprzednio prezentowanych przykładowych parametrów,
należałoby wpisać w przeglądarce adres
http://adres.serwera:port/Kocioł 1/Sterownik/temperatura zadana.
Z każdym parametrem związanych jest kilka informacji. Właściwie zawsze będzie to
nazwa (choć ta określana jest już przez ścieżkę dostępu) oraz aktualna wartość,
zwykle także symbol jednostki, w jakiej wyrażona jest wartość parametru. W
systemie SZARP dodatkowo mogą to być różne postacie skrócone nazwy, numer
rekordu w bazie danych, indeks parametru w pamięci dzielonej.
W związku z reprezentacją parametrów w postaci drzewa XML, naturalne było
reprezentowanie tych informacji jako atrybutów elementu. Aby więc uzyskać
informację o wartości parametru, należałoby podać adres w postaci:
http://adres.serwera:port/Kocioł 1/Sterownik/temperatura zadana@value.
Inne możliwe nazwy atrybutów to unit (nazwa używanej jednostki),
short_name (skrócona nazwa parametru), full_name
(pełna nazwa, z
dwukropkami), ipc_ind indeks parametru w pamięci dzielonej i
prec -- ilość miejsc po przecinku w reprezentacji parametru.
Użycie znaku @ jest zgodne z notacją dostępu do atrybutów
elementów w wyrażeniach XPath.
Taki sam efekt można by uzyskać stosując do całego dokumentu
udostępnianego przez serwer parametrów wyrażenie /Kocioł
1/Sterownik/temperatura zadana[@value] (z dokładnością do spacji).
Spacje stanowią problem, ponieważ normalnie nie mogą wchodzić w skład zapytania
przekazywanego do serwera. Niektóre przeglądarki zastępują spacje odpowiednimi
sekwencjami znaków %kod. Niestety nie wszystkie potrafią to
robić.
Problem stanowią także niektóre inne znaki, np. znak ukośnika /, który
w systemie SZARP może występować w nazwie parametru, natomiast w URI ma
specjalną funkcję. Podobny problem występuje wtedy,
gdy w nazwie parametru występują
polskie literki. Trudno przewidzieć czy i jak (np. w jakim kodowaniu) zostaną
przekazane przez przeglądarkę.
W związku z tym przy podawaniu zapytania do serwera znaki takie jak spacja,
ukośnik itp. można zastąpić znakiem podkreślenia. Zaś polskie litery można
zastąpić ich angielskimi odpowiednikami (ą przez a itp.).
Dopuszczalne jest także kodowanie w postaci %kod (polskie
litery w kodowaniu ISO-8859-2). Przykładowe ścieżki mogą więc mieć postać
http://adres.serwera:port/Kociol_1/Sterownik/temperatura_zadana@value.
Dokumenty generowane przez serwer parametrów mają służyć głównie jako dane
wejściowe dla procesora XSLT, muszą więc być dokumentami XML. Przydatna byłaby
jednak także możliwość bezpośredniego dostępu do informacji o parametrach z
przeglądarki, a więc przekazywanie informacji w postaci dokumentów HTML. Rodzaj
generowanego dokumentu można wybrać przez podanie w ścieżce dostępu opcji
output, która może przyjąć wartość xml, html lub
text. W tym ostatnim przypadku generowany jest także dokument XML, ale
z opisem typu zawartości text/plain, co pozwala na bezproblemowe
wyświetlenie go także w przeglądarkach nie obsługujących XML.
Domyślnie (bez podania opcji output) generowany jest dokument HTML
zawierający dowiązania do nadrzędnego węzła drzewa i węzłów lub parametrów
podrzędnych (jeżeli wyświetlamy informacje o grupie parametrów) lub opis
parametru z wartościami atrybutów (jeżeli podana ścieżka dostępu identyfikuje
parametr).
Jeśli żądamy informacji o atrybucie, to domyślnie generowany jest dokument XML.
Jeżeli podaliśmy ścieżkę do jakiegoś węzła w drzewie i opcję
output=xml, to
otrzymamy dokument zawierający poddrzewo z korzeniem w podanym węźle.
Tak więc po wpisaniu http://adres.serwera:port będziemy mogli
rozpocząć przeglądanie parametrów w postaci HTML od głównego węzła drzewa
parametrów, a wpisując http://adres.serwera:port/Kociol_1?output=xml
otrzymamy informację o wszystkich parametrach dotyczących kotła 1 w postaci
dokumentu XML.
Poza udostępnianiem informacji o wartościach parametrów, serwer parametrów ma
też umożliwiać sterowanie procesem przez zadawanie wartości parametrów.
Ponieważ program obsługuje tylko żądania HTTP GET, więc przekazywanie
zadanej wartości parametru odbywa się przez użycie opcji o nazwie put.
Ze względu na wymagania bezpieczeństwa, opisane w p.
2.9, wymaga to autoryzacji użytkownika i użycia
połączenia szyfrowanego, za pomocą SSL.
Można więc zadać wartość parametru
wpisując w przeglądarce adres
https://adres.serwera :port_ssl/Kociol_1/Sterownik/temperatura_zadana@value?put=67.3.
Po zaakceptowaniu przez przeglądarkę certyfikatu serwera i podaniu przez
użytkownika odpowiedniego identyfikatora i hasła serwer parametrów
wstawia do pamięci dzielonej procesu uśredniającego żądaną wartość. Przekazanie
jej do sterownika przemysłowego jest już zadaniem systemu SZARP.
Dzięki możliwości generowania informacji w formacie HTML serwer parametrów,
jako program paramd, stał się samodzielnym i dość przydatnym elementem
systemu SZARP. Pozwala na zdalne sprawdzanie wartości parametrów bez
potrzeby posiadania specjalizowanego oprogramowania klienckiego. Instalacja
programu nie wymaga żadnych zmian w konfiguracji systemu. Domyślnie przyjmowane
wartości opcji konfiguracyjnych zapewniają sprawne działanie. Poza tym
wykorzystanie go jako interfejsu dla innych aplikacji systemu pozwoliłoby w
przyszłości na rozwiązanie problemu dostępu jednocześnie do parametrów
zbieranych przez różne serwery SZARP.
Program jest zainstalowany i działa w około 10 ciepłowniach w całej
Polsce, w tym tylko w jednej jako część całego systemu wizualizacji -- w
pozostałych samodzielnie.
Czas obsługi
żądania dotyczącego pojedynczego parametru na komputerze z procesorem z zegarem
około 1 GHz wynosi poniżej 1 milisekundy, a w przypadku wysyłania drzewa
informacji o wszystkich parametrach np. ciepłowni w Bytowie
(około 100 parametrów,
wielkość pliku wyjściowego 18 KB) wynosi około 5 ms. Wartości te mierzono
przy użyciu lokalnego interfejsu sieciowego, a więc bez opóźnień związanych z
przesyłaniem przez sieć.
Dodatek D.1 zawiera dokumentację użytkownika
programu, a B.1 dokładny opis formatów generowanych
dokumentów XML.
Dostosowanie programu do innego źródła danych powinno być dość proste. Jedynym
wymaganiem jest posiadanie przez parametry nazwy, unikatowej w obrębie
pojedynczej instalacji, która może być zamieniona na jednoznaczny identyfikator
liczbowy.
Należałoby napisać nową implementację abstrakcyjnej klasy ParamLoader,
która jest odpowiedzialna za wczytanie informacji konfiguracyjnych
o parametrach i utworzenie drzewa parametrów, oraz klasy ParamReader,
definiującej metody update, getValue i setValue
(odpowiedzialne odpowiednio za odświeżenie informacji o wartościach parametrów,
pobranie i ustawienie wartości). Moglibyśmy także chcieć generować inną postać
dokumentów HTML, co wymagałoby przedefiniowania jednej metody w klasie
ParamTree.
3.6 Tworzenie schematów.
3.6.1 Format dokumentów ISL
Tak jak już napisałem wcześniej, w p. 3.1,
danymi prezentowanymi przez mój system są schematy, czyli rysunki (dokumenty)
zapisane w SVG, wzbogacone o informacje konieczne do reprezentowania wartości
parametrów. Ten zestaw rozszerzeń nazwałem roboczo Industry Schema
Language, w skrócie ISL. Określenia dokumenty ISL używam także ogólnie
do określenia schematów, w przeciwieństwie do dokumentów SVG, które mogą
być jedną z form prezentacji wygenerowaną ze schematów.
Dla potrzeb projektu zdefiniowałem przestrzeń nazw XML, o następującym URI:
http://www.praterm.com.pl/ISL/params.
Dalej do identyfikacji tej
przestrzeni nazw używam prefiksu isl, choć sam prefiks ma znaczenie
tylko w powiązaniu z URI i może być dowolny [17].
Podstawową formą prezentowania wartości parametrów jest reprezentacja tekstowa,
a więc umieszczanie na rysunku tekstowej informacji o wartości parametru.
Realizowane jest to przez dodanie do elementu tekstowego atrybutu
isl:uri, którego wartością jest pełna ścieżka dostępu do atrybutu
parametru (w postaci opisanej w p. 3.5).
Użycie takiej
konstrukcji oznacza, że w dokumencie wyjściowym zawartość elementu XML należy
zastąpić przez tekstową reprezentację wartości atrybutu. Przykładowy dokument
ISL, który po przetworzeniu będzie zawierał napis z wartością parametru, mógłby
więc wyglądać następująco:
<?xml version="1.0" standalone="yes"?>
<svg
width="100"
height="100"
xmlns:isl="http://www.praterm.com.pl/ISL/params"
xmlns="http://www.w3.org/2000/svg">
<text
style="font-family:Helvetica; font-size:12.0;"
x="10.0"
y="20.0"
isl:uri=
"http://213.76.238.20:8081/Siec/Sterownik/temperatura_zewnetrzna@value"
id="text01">Ten tekst zostanie zastąpiony przez wartość parametru</text>
</svg>
Obecność atrybutu id w elemencie, mimo że nie jest wymagana przez
specyfikację SVG, jest konieczna w elementach zależnych od parametrów do
działania automatycznego odświeżania parametrów (zobacz p.
3.7.1).
Specyfikowanie pełnej ścieżki dostępu do parametru
pozwala na pełną przenośność dokumentów -- wygląd
schematu nie zależy od miejsca, w którym jest on przetwarzany. Zaś włączenie do
ścieżki także nazwy atrybutu pozwala na niezależność schematów od konkretnej
implementacji serwera parametrów, gdyż nie wszystkie systemy muszą udostępniać
ten sam zestaw atrybutów dla parametrów. Poza tym zazwyczaj informacja o
aktualnej wartości nie jest jedyną, jaką chcemy wyświetlać. Zamiast np.
wstawiać na stałe do schematu nazwy jednostek, bezpieczniej i bardziej
uniwersalnie jest użyć atrybutu unit.
Ze względu na częste użycie kombinacji atrybutów wartość i
jednostka zdefiniowano także wirtualny atrybut v_u,
który oznacza wstawienie jako zawartości elementu wartości atrybutów
value i unit, przedzielonych pojedynczą spacją.
Poza tekstową reprezentacją wartości parametrów chcielibyśmy mieć możliwość
także innego typu reprezentacji wartości. Drugim dostępnym sposobem jest
uzależnienie od wartości parametru wartości atrybutu elementu SVG, a więc np.
rozmiarów czy położenia elementu. Efekt taki uzyskuje się przez zdefiniowanie w
elemencie, poza atrybutem isl:uri także atrybutu isl:target.
Jego wartością jest nazwa atrybutu, którego wartość ma być zastąpiona przez
wartość atrybutu parametru. Dodatkowe atrybuty elementu SVG, isl:shift
i isl:scale, pozwalają na przeskalowanie i przesunięcie tworzonej
wartości. Wartość atrybutu, o nazwie będącej wartością atrybutu
isl:target jest więc zastępowana przez wartość
i × isl:scale + isl:shift, gdzie i oznacza
wartość atrybutu parametru pobraną z serwera parametrów.
Na przykład, jeżeli chcemy uzależnić położenie elementu od wartości
atrybutu parametru, przy czym element chcemy przesunąć w prawo od punktu (100,
100) o wartość atrybutu podzieloną przez 2, to kod elementu może wyglądać
tak:
<rect
x="100" y="100" width="50" height="50" style="fill:#FF0000"
isl:uri=
"http://213.76.238.20:8081/Siec/Sterownik/temperatura_zewnetrzna@value"
isl:target="x" isl:scale="0.5" isl:shift="100"/>
Rysunek 3.3 przestawia przykład wykorzystania tych konstrukcji
-- słupek rtęci w termometrze pokazuje wartość zależną od mierzonej
temperatury. Dodatkowo temperatura jest wyświetlana w postaci
tekstowej5.
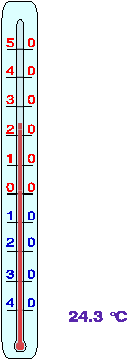
Rysunek 3.3: Przykład wykorzystania atrybutów zależnych od wartości parametrów
Jeżeli rysowany schemat zawiera
dowiązania, to zaleca się użycie w elemencie <a/>
(oznaczającym dowiązanie) atrybutu isl:link-coords. Jego
wartością są cztery współrzędne wyznaczające prostokąt -- obszar aktywny
związany z dowiązaniem. Atrybut ten nie jest wykorzystywany przy
prezentacji danych w postaci SVG (wtedy obszarem aktywnym jest element
zawarty w elemencie <a/>). Niestety wyznaczenie
pozycji i rozmiarów elementu SVG nie jest możliwe bez parsowania
być może całego dokumentu. W związku z tym procesor XSLT
przetwarzający schematy potrzebuje pomocy w wyznaczeniu pozycji
dowiązania jeżeli jest generowany inny typ dokumentu (np. bitmapa),
który sam takich informacji nie zawiera. Jeżeli atrybutu nie ma, to
procesor próbuje obejść ten problem w inny sposób (więcej na ten
temat w p. 3.7.1).
Zaprezentowany prosty zestaw rozszerzeń okazał się wystarczający do
stworzenia schematów w ramach wykonanego wdrożenia systemu
wizualizacji. W razie potrzeby można go łatwo rozszerzyć (np.
o możliwość obrotu elementu zależnie od wartości parametru czy też
uzależnienie od niej koloru elementu). Modyfikacje takie nie wymagają
zmian w kodzie żadnej części systemu. Należy dodać jedynie obsługę
nowych atrybutów (lub elementów) do szablonów XSLT. Prawdopodobnie
szablony te będą modyfikowane w miarę pojawiania się
zapotrzebowania na konkretne efekty wizualne. Wydaje się jednak, że
zaprojektowany schemat rozszerzeń jest na tyle elastyczny, że powinien
umożliwić realizację właściwie dowolnych efektów.
Rysunek 3.4 przedstawia bardziej złożony schemat,
prezentujący ciepłownię w Bytowie6. Dokładny opis
rozszerzeń ISL zawiera dodatek B.2.
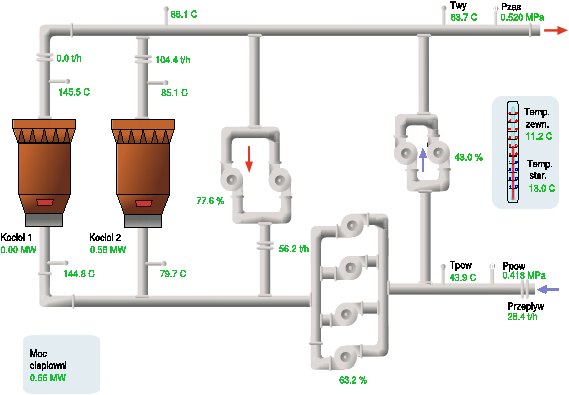
Rysunek 3.4: Schemat ciepłowni w Bytowie
z wartościami parametrów
3.6.2 Edytor SVG/ISL
Jedną z pożądanych cech systemu ma być możliwość graficznej edycji
schematów (por. rozdz. 2.12). Zwłaszcza że dokumenty SVG,
przez wykorzystanie krzywych, wypełnień gradientowych itp., są zbyt złożone do
edycji ręcznej.
Jednym z powodów wybrania SVG jako języka do tworzenia schematów była możliwość
korzystania z istniejących programów. Zależało mi, aby było to
narzędzie darmowe. Po pierwsze dlatego, że w pozostałej części projektu używam
bezpłatnego oprogramowania, szkoda więc byłoby, gdyby za możliwość
wygodnej edycji
schematów użytkownik miał płacić. Po drugie, użycie programów z dostępnym kodem
źródłowym pozwala na zaprojektowanie rozszerzeń do edycji elementów z
przestrzeni nazw isl, a więc związanych z parametrami.
Bezpłatne narzędzia istnieją, nie dorównują jednak takim programom jak np.
Adobe Illustrator, uważany powszechnie za najlepszy program do edycji SVG
(firma Adobe była jedną z pierwszych, które
poważnie zajęły się implementowaniem SVG, jeszcze na długo przed tym,
zanim stał
się oficjalnym standardem).
Poszukiwania doprowadziły mnie do programu Sodipodi. Program jest rozwijany
w ramach projektu Gnome, od 1999 roku. Jego autorem i głównym realizatorem jest
Lauris Kaplinski, związany przejściowo między innymi z firmą Ximian, która
zajmuje się rozwojem projektu Gnome. Wybór Sodipodi podyktowany został
tym, że spośród dostępnych programów Open Source implementuje on największą
część specyfikacji. W szczególności SVG jest dla niego formatem natywnym. Wiele
innych programów pozwala tylko na eksport do SVG, co powoduje konieczność
trzymania dwóch wersji schematów (oryginalny plik i wyeksportowany SVG) oraz
problemy z obsługą rozszerzeń ISL.
Programowi Sodipodi sporo brakuje jeszcze do doskonałości. Nie obsługuje on
całej
funkcjonalności SVG. Brakuje mu między innymi filtrów i wypełnień wzorcem, nie
ma wsparcia dla wielokrotnego użycia elementów (co może znacznie zmniejszać
rozmiary pliku z obrazkiem). Ma trochę błędów w renderowaniu obrazków (choć da
się każdy element narysować tak, żeby zarówno w Sodipodi, jak i w Adobe SVG był
renderowany tak samo). Kłopotliwe dla polskiego użytkownika są problemy z
polskimi znakami -- nie są one renderowane poprawnie i nie można ich
bezpośrednio wprowadzać (trzeba korzystać z mechanizmu kopiuj/wklej X serwera
lub
edytować plik ręcznie).
Z drugiej strony program posiada na tyle bogaty i dobrze opracowany zestaw
narzędzi, że pozwala na skupienie się na projektowaniu schematów, a nie
na walce z samym programem, co zdarza się w wypadku innych narzędzi
znajdujących się w początkowej fazie rozwoju. Program posiada też polską
wersję językową.
Konieczność dodania do programu narzędzi pozwalających na edycję elementów ISL
wiązała się z kilkoma problemami.
Ponieważ Sodipodi jest projektem cały czas rozwijającym się, nie mogłem
bezkarnie modyfikować programu w nadziei, że przygotowane przeze mnie łaty będą
pasować do kolejnych wersji. Z drugiej strony nie chciałem się ograniczać do
aktualnie dostępnej wersji programu, aby móc korzystać z nowości i usprawnień
wprowadzanych w nowych wersjach.
Zdecydowałem się więc na formułę zmian, która pozwoliła na dołączenie moich
poprawek do oficjalnej dystrybucji Sodipodi. Sodipodi w wersji 0.24 posiadał
niedziałający edytor XML, który w założeniu miał pozwalać na dowolną edycję
dokumentu, przez operowanie bezpośrednio na drzewie XML. Korzystając z
zaprojektowanego wcześniej układu okienka edytora, napisałem kod odpowiedzialny
za edycję drzewa. Działanie edytora wymagało także kilku zmian w innych
fragmentach programu, np. związanych z obsługą innych niż SVG przestrzeni nazw.
Przy okazji znalazłem i usunąłem kilka błędów. Napisany przeze mnie kod wysłałem
autorowi programu i został on dołączony do oficjalnego kodu
programu7.
Tworzenie schematu w programie Sodipodi polega więc na tworzeniu rysunku o
wielkości odpowiadającej pożądanej wielkości schematu, za pomocą standardowych
narzędzi dostępnych w wektorowych programach graficznych. Aby
wstawić tekstową
wartości parametru, należy najpierw utorzyć dowolny napis,
w miejscu gdzie ma być wstawiona wartość.
Po zaznaczeniu tego napisu otwieramy okno
edytora XML (dostępne z menu kontekstowego prawego przyciska myszki, opcja Dialogs). W polu edycji atrybutów wciskamy przycisk Add i wpisujemy
nazwę atrybutu (isl:uri) oraz wartość -- ścieżkę dostępu do atrybutu
parametru. Należy się jeszcze upewnić, czy w głównym elemencie dokumentu
znajduje się deklaracja przestrzeni nazw ISL, czyli atrybut o nazwie xmlns:isl i wartości http://www.praterm.com.pl/ISL/params. Jeśli go nie
ma, należy go w analogiczny sposób dodać.
Podobnie przez dodawanie atrybutów do elementu w edytorze XML, ustawiamy
zależność atrybutu od wartości parametru oraz pozycję dowiązania
(zobacz p. 3.6.1).
Użyteczną cechą Sodipodi jest to, że do każdego elementu dołącza on unikatowy
identyfikator w postaci atrybutu id, co jest niezbędne do działania
automatycznego odświeżania wartości parametrów w schematach (szczegóły
w p. 3.7.1).
Wersja Sodipodi znajdująca się obecnie (w chwili pisania pracy) w repozytorium
CVS jest niestabilna. W związku z tym w projekcie używam własnej wersji,
opartej na wersji 0.24 i częściowo 0.25, z kilkoma drobnymi poprawkami. Kod
źródłowy tej wersji, oznaczonej przez mnie symbolem 0.25-isl jest
obecny na dołączonej do pracy płycie CD.
Mimo że Sodipodi posiada jeszcze sporo błędów i niedociągnięć, jest dość
wygodnym i funkcjonalnym narzędziem do tworzenia schematów. Za jego pomocą
stworzone zostały wszystkie prezentowane w ramach projektu rysunki, między
innymi schematy ciepłowni w Ełku i Bytowie. Szkoda tylko, że w ostatnich
miesiącach tempo rozwoju projektu Sodipodi wyraźnie osłabło.
Przydatna byłaby w przyszłości możliwość dodawania wartości parametrów np. na
zasadzie wyboru parametru z listy, zamiast wymaganego obecnie wpisywania nazwy
parametru jako wartości odpowiedniego atrybutu. Wymagałoby to jednak poważnych
ingerencji w kod programu, które nie mają sensu na obecnym etapie jego rozwoju.
3.7 Procesor dokumentów
3.7.1 Zadania procesora XSLT
Jądrem całego systemu wizualizacji jest serwer HTTP połączony z procesorem
XSLT. Jego zadaniem jest przygotowywanie dokumentów prezentowanych
oprogramowaniu klienckiemu. Dokumenty te są generowane na podstawie
stworzonych przez użytkownika schematów i ewentualnie innych dokumentów oraz
informacji o wartościach parametrów, pobieranych z serwera parametrów.
W najprostszym przypadku procesor ma za zadanie jedynie wstawić wartości
atrybutów elementów pobranych z serwera parametrów do schematu, tworząc w ten
sposób statyczny dokument SVG, reprezentujący stan procesu w chwili
wygenerowania dokumentu SVG. Zadanie to może zrealizować stosunkowo prosty
szablon, korzystający ze zdefiniowanej w XSLT funkcji document(),
która pozwala na wstawienie do szablonu całości lub części innego dokumentu,
być może pobranego wcześniej z sieci. W ten właśnie sposób procesor XSLT
pobiera wartości dokumentów od serwera parametrów.
Możliwe były tu dwie strategie. Zwykle jeden schemat zawiera wiele odniesień
do parametrów. Można było pobierać z serwera parametrów dokument z wartościami
wszystkich parametrów, a potem wyłuskiwać wartości odpowiednich atrybutów za
pomocą wyrażeń XPath. Drugie podejście, to pobieranie tylko wartości atrybutu,
ale za to przy przetwarzaniu każdego odwołania do jakiegoś parametru. To
drugie rozwiązanie jest nieco prostsze w implementacji. Poza tym nie ma
znaczenia, czy wszystkie parametry pochodzą z tego samego serwera. Pierwsze
rozwiązanie może oznaczać mniejszą liczbę koniecznych transmisji -- tylko po
jednej z każdego serwera. Zwykle jednak ilość przesłanych danych i tak będzie
większa, bo przesyłamy informacje o wszystkich parametrach, a na pojedynczym
schemacie jest ich zwykle tylko kilkanaście.
Wybrałem więc rozwiązanie drugie, czyli oddzielną transmisję małej ilości
danych dla każdego odwołania do parametru. Oczywiście, ponieważ całe
rozwiązanie jest zapisane w formie szablonu XSLT, w razie potrzeby jest to
proste do modyfikacji (gdyby okazało się, że jednak szybciej jest pobrać
jednorazowo pełną informację o wartościach parametrów).
Statyczny SVG to jednak nie wszystko, co chcielibyśmy uzyskiwać od procesora
dokumentów. Potrzebne są także schematy dynamiczne, przy czym odświeżaniu
miałaby ulegać tylko część schematu związana z parametrami.
Opracowanie sposobu implementacji tego częściowego odświeżania dokumentów było
jedną z trudniejszych koncepcyjnie części pracy. Wymyślone przeze mnie
rozwiązanie wykorzystuje pewne specyficzne cechy SVG. Mianowicie, w SVG
istnieją elementy <use/>. Element taki musi posiadać atrybut
xlink:href8, będący wyrażeniem XPath wskazującym na inny element
(zazwyczaj dowiązaniem do niego, wykorzystującym atrybut id). Zamiast
elementów <use/> będzie rysowany element wskazywany przez atrybut.
Oczywiście może to być także element z innego dokumentu, obecnego na innym
serwerze.
Pierwsza część rozwiązania polega więc na rozdzieleniu fragmentów schematu
zależnych od parametrów od reszty. Fragmenty zależne od parametrów są
grupowane w jednym dokumencie, który nazywam dokumentem z definicjami. W
drugim dokumencie znajdują się odwołania do tych definicji za pomocą elementu
<use/> oraz pozostała, statyczna część schematu.
Poza tym w dokumencie tym procesor XSLT umieszcza skrypty w języku ECMAScript [6].
Skrypty te generowane są automatycznie. Co 10 sekund usuwają one kolejno
wszystkie elementy <use/> i wstawiają je na nowo, ale ze zmienioną
wartością atrybutu xlink:href. Zmieniona wartość wskazuje tak
naprawdę na ten sam element, w tym samym dokumencie. Konieczna jest jednak
drobna zmiana w ścieżce dostępu, żeby klient nie skorzystał przypadkiem z
dokumentu obecnego w schowku (lokalnym lub serwera proxy).
Usunięcie i dodanie elementu <use/> zmusza oprogramowanie klienckie do
ponownego pobrania informacji o wskazywanym elemencie z dokumentu z
definicjami i narysowania go na nowo. Powoduje to wstawienie nowych wartości
parametrów, pobranych z nowo utworzonego dokumentu z definicjami.
Oczywiście cały ten proces działa tylko przy założeniu, że oprogramowanie
klienckie posiada odpowiednie wsparcie dla dynamicznej modyfikacji struktury
dokumentu przez skrypty (zgodnie ze specyfikacją SVG). Niestety nie ma go na
przykład Adobe SVG Viewer w wersji 3.0. Jedyną przeglądarką SVG, w której
udało się uzyskać automatyczne odświeżanie parametrówi, jest przeglądarka
Batik, tworzona przez Apache Foundation, w wersji 1.5 (więcej informacji o
przeglądarkach w rozdz. 3.8).
Teoretycznie, według specyfikacji SVG, nie byłoby konieczne usuwanie i ponowne
dodawanie elementu <use/>. Powinna wystarczyć sama zmiana atrybutu
xlink:href. Niestety takiej funkcjonalności nie udało mi się uzyskać
w żadnej z dostępnych przeglądarek.
Szablony realizujące dynamiczne odświeżanie parametru, a więc generujące część
definicyjną schematu oraz część z pozostałymi elementami i skryptami, były więc
pisane w myślą o przeglądarce Batik. Jedną z cech Batika jest
przechowywanie ściągniętych dokumentów w lokalnym schowku, co
zmusza do sztucznej zmiany dowiązań do dokumentów z definicjami. Zmiana ta
polega na dołączaniu do dowiązania ignorowanej przez serwer części zawierającej
licznik odwołań.
Zaletą takiego
zachowania jest natomiast to, że każdy dokument z definicjami jest ściągany
tylko raz, ponieważ w danym momencie wszystkie odwołania do parametrów używają
tej samej wartości licznika. Po kolejnych 10 sekundach skrypty zwiększą
licznik o 1 i znów dokument z definicjami zostanie ściągnięty tylko raz, przy
pierwszej modyfikacji odnoszącego się do niego elementu. Kolejne odwołania
będą korzystały z wartości w schowku.
Statyczny i dynamiczny SVG nie wyczerpują wszystkich wymagań dotyczących
prezentacji danych. Duża klasa użytkowników (przynajmniej tych oglądających
schematy okazjonalnie) nie będzie dysponowała przeglądarką obsługującą SVG.
Konieczna jest więc także możliwość prezentowania schematu w postaci bitmapy.
Oczywiście samo generowanie bitmapy nie jest zadaniem procesora XSLT, ale
jakiegoś programu renderującego SVG, natomiast przydatna byłaby integracja
tego programu z będącym częścią procesora dokumentów serwerem HTTP.
Aby generowanej bitmapie stworzyć odpowiednie otoczenie (a więc np.
możliwość umieszczenia dowiązań), jest ona zagłębiana w dokumencie HTML.
Dokument ten generowany jest przez procesor XSLT z pliku źródłowego,
zawierającego uproszczony dokument HTML. Do dokumentu tego procesor dodaje
nagłówek z tytułem i pasek nawigacyjny. Pozwala to na automatyczne nadawanie
dokumentowi odpowiedniego wyglądu i rozdzielenie formatowania dokumentu i jego
treści.
Poza innymi elementami HTML dokument
ten może zawierać element <isl:schema/>, powodujący wstawienie do
dokumentu HTML schematu określonego przez atrybut
src9.
Dodatkową zaletą takiego rozwiązania
jest możliwość generowania dokumentu, który będzie
poprawnie wyświetlany zarówno w przeglądarkach obsługujących SVG, jak i nie
posiadających tej
funkcji. W ogólnym przypadku stwierdzenie, czy przeglądarka potrafi wyświetlać
SVG, nie jest łatwe. Wymaga to m.in. odpytywania przeglądarki
o obsługiwane wtyczki, np. za pomocą skryptów.
Będzie się to odbywało inaczej w każdym modelu przeglądarki.
Tymczasem procesor XSLT generuje na miejsce elementu <isl:schema/>
element <object/>. Zgodnie ze specyfikacją HTML 4.01 [16],
zawiera on dowiązanie
do obiektu (w tym wypadku dokumentu SVG) wraz z opisem jego
typu. Jeżeli przeglądarka nie obsługuje obiektów danego typu, to powinna
rozpocząć parsowanie zawartości elementu <object/>. Jako zawartość
przygotowany przeze mnie szablon wstawia odnośnik do obrazka, będącego bitmapową
reprezentacją schematu. Obrazek dodatkowo jest wyposażony w mapę (element
<map/> HTML), co pozwala na emulowanie zachowania dowiązań
występujących na oryginalnym schemacie. Dowiązania są umieszczane na mapie tylko
wtedy, gdy mają dodany przez autora schematu atrybut określający
ich położenie na
obrazku w punktach (zobacz p. 3.6.1). Jeżeli atrybutu
brak, to dowiązanie jest dołączane nad obrazkiem w postaci tekstowej.
W rezultacie, jeśli przeglądarka obsługuje SVG,to
użytkownik otrzymuje stronę HTML
z zagłębionym statycznym obrazkiem SVG (z ewentualnymi dowiązaniami).
Jeżeli nie, to
użytkownik widzi obrazek rastrowy. Jeżeli autor schematu o to zabrał, to
dowiązania są
dostępne bezpośrednio z obrazka, podobnie jak w SVG. Lista dowiązań bez
odpowiednich atrybutów określających ich położenie na obrazku jest dostępna
powyżej obrazka w postaci tekstowej.
Przewaga SVG na bitmapą polega nie tylko na możliwości dowolnego powiększania
wybranego fragmentu obrazu, przesuwania go i lepszej obsłudze dowiązań,
ale także
na zwykle mniejszych rozmiarach obrazków. Przeciętnie schemat w postaci SVG
spakowany algorytmem LZ77 [5] (używanym przez popularny program
GNU zip
i obsługiwanym przez większość przeglądarek)
ma rozmiar około 10 razy mniejszy niż odpowiadająca mu grafika w formacie
PNG. Poza tym oczywiście tylko użycie SVG umożliwia automatyczne
odświeżanie wartości parametrów.
Poza przetwarzaniem dokumentów przez procesor XSLT, generowaniem
grafiki bitmapowej z dokumentów SVG oraz udostępnianiem tych dokumentów przez
serwer HTTP, procesor dokumentów powinien zapewnić wygodne środowisko
pozwalające na budowanie struktury serwisu WWW. Serwis taki może składać się
z wielu połączonych ze sobą dowiązaniami schematów i innych dokumentów --
wspomnianych dokumentów HTML/ISL, innych dokumentów HTML, elementów grafiki
do budowania stron oraz plików konfiguracyjnych określających wzajemne
powiązania dokumentów i sposób ich przetwarzania przez procesor XSLT. W
szczególności chcielibyśmy mieć możliwość dowolnego dodawania i modyfikowania
szablonów XSLT.
W podrozdziałach 3.7.2 i 3.7.3 opisuję
dwie
wykonane implementacje procesora dokumentów, pierwszą z wykorzystaniem
istniejącego oprogramowania, a drugą napisaną od podstaw przeze mnie. Dodatek
C zawiera wykorzystywane w systemie
szablony XSLT.
3.7.2 Implementacja z wykorzystaniem serwera Apache Cocoon
Początkowo zakładałem samodzielną implementację procesora dokumentów,
realizującego funkcjonalność opisaną w p. 3.7.1.
Natknąłem się jednak na gotowe oprogramowanie, wykonujące zadania, jakie
postawiłem przed procesorem dokumentów. Oprogramowaniem tym jest Cocoon,
tworzony w ramach projektu Apache.
Autorzy określają Cocoona jako XML publishing framework [9], co
można by przetłumaczyć jako zestaw narzędzi do publikowania dokumentów XML.
Projekt został rozpoczęty w 1999 roku, obecnie dostępna jest wersja 2 Cocoona.
Cocoon jest bardzo złożonym systemem, zapewniającym komplet narzędzi i usług
do budowania serwisów WWW opartych na technologii XML. Pozwala na eleganckie
rozdzielenie logiki serwisu, jego zawartości, wyglądu i samego zarządzania
serwisem. Podstawową technologią
jest XSLT, ale Cocoon potrafi dużo więcej.
Cocoon jest napisany w Javie i zazwyczaj używany się go jako aplikacji
kontenera serwletów
(ang. servlet container), np. Tomcata [10], także
tworzonego w ramach projektu Apache.
Żądanie przekazane np. przez Tomcata do Cocoona jest przetwarzane w dynamicznym
potoku (ang. pipeline). Sposób przetwarzania żądania może zależeć od
typu przeglądarki, podanego adresu i przekazanych opcji. Czytane podczas
przetwarzania potoku dokumenty źródłowe XML przechodzą przez szereg faz
przetwarzania. W najprostszym przypadku mogą być odczytane z dysku i wysłane do
klienta. W bardziej skomplikowanym, po drodze przechodzą szereg przekształceń,
dokonywanych między innymi przez procesor XSLT, a na końcu mogą zostać
przekształcone przez obiekt serializujący (czyli produkujący postać końcową,
niekoniecznie będącą dokumentem XML, ale np. obrazkiem). W czasie przetwarzania
żądania mogą być wykonywane odpowiednio zdefiniowane akcje (np. aktualizacja
informacji w bazie danych).
Cocoon w pełni wykorzystuje możliwości dynamicznego ładowania kodu, oferowane
przez Javę. Oferuje łatwą integrację z JSP (Java Server Pages)
i komunikację z bazami danych.
Plik konfiguracyjny opisuje drogę, jaką przebywają generowane dokumenty. Na
początku zawiera deklaracje używanych elementów. Są wśród nich obiekty służące
do odczytywania danych z dysku, pobierania z sieci i bazy danych, transformacji
dokumentów z użyciem XSLT, XInclusions10 i innych, generowania danych
binarnych, obsługi błędów i wykonywania wielu innych akcji. Deklaracja każdego
z elementów zawiera, poza różnego rodzaju opcjami, także ścieżkę dostępu do
skompilowanej klasy Javy realizującej funkcjonalność elementu. Pozwala to na
proste wykorzystanie nie tylko bogatego zestawu gotowych elementów, ale także
dołączanie własnych klas.
Najważniejszą częścią konfiguracji są opisy potoków, w jakich przetwarzane są
dokumenty. Na początku opisu znajdują się warunki,
jakie musi spełniać żądanie, aby trafić do
danego potoku (najczęściej jest to odpowiednia postać URI). Następnie
opisany jest przebieg
przetwarzania dokumentu przez zdefiniowane wcześniej elementy.
W miarę możliwości wszystkie używane elementy trzymane są w postaci
skompilowanego kodu Javy, co zwiększa szybkość ich przetwarzania. Poza tym
Cocoon zawiera zaawansowany system zarządzania buforowaniem dokumentów.
Szczególnie atrakcyjną z mojego punktu widzenia cechą Cocoona jest wbudowana
obsługa SVG. Standardowo w systemie dostępny jest obiekt serializujący SVG,
czyli przekształcający dokument SVG w grafikę w jednym z powszechnie używanych
formatów, np. PNG. Używa on wspominanego już pakietu Batik, zapewniającego
renderowanie wszystkich wymienionych przez specyfikację elementów SVG.
Oczywiście do moich potrzeb wystarczało wykorzystanie tylko niewielkiej części
możliwości Cocoona, zwłaszcza że generowałem stosunkowo niewielką liczbę
dokumentów, wykorzystując właściwie tylko procesor XSLT.
Ponieważ z tych samych źródeł (schematów w SVG/ISL) miałem generować różne
rodzaje dokumentów wyjściowych, zdecydowałem się na rozróżnianie ich przez
prefiks dodawany do ścieżki dostępu do zasobu. Ma to tę przewagę nad
wykorzystaniem rozszerzeń plików, że ułatwia tworzenie dowiązań
względnych. Gdybym
wykorzystywał rozszerzenia, musiałbym modyfikować dowiązania wewnątrz
dokumentów,
tak aby to samo dowiązanie w dokumencie schemat1.svg wskazywało na schemat2.svg, a w dokumencie schemat1.html na schemat2.html.
Tymczasem jeżeli mam dokument o ścieżce dostępu svg/schemat1.isl, to
mogę w nim umieścić link do dokumentu svg/schemat2.isl po prostu przez
podanie nazwy schemat2.isl. Ten samo dowiązanie będzie poprawne
w dokumencie
HTML, wskazując na dokument html/schemat2.isl.
Musiałem przyjąć jakąś ogólną strukturę układu dokumentów źródłowych, wspólną
dla wszystkich potencjalnych instalacji, co pozwoliłoby na utworzenie
uniwersalnego pliku konfiguracyjnego. Chciałem także, aby struktura pozwoliła
na trzymanie na jednym fizycznym serwerze konfiguracji dla wielu obiektów,
czyli konkretnych instalacji systemu wizualizacji. Struktura ta ostatecznie
wygląda następująco:
-
W głównym katalogu konfiguracji znajduje się plik sitemap.xmap z opisem
konfiguracji.
-
W podkatalogu stylesheets znajdują się szablony XSLT wykorzystywane do
generowania dokumentów.
-
W podkatalogu resources znajdują się zasoby wspólne dla wszystkich
obiektów, np. w podkatalogu resources/images obrazki wykorzystywane przez
szablony generujące dokumenty HTML.
-
Każdy obiekt posiada oddzielny podkatalog, np. katalog byto zawiera dane
dla ciepłowni w Bytowie. Standardowo wyświetlanie rozpoczyna się od
podkatalogu main (który może być oczywiście dowiazaniem do jakiegoś
innego katalogu).
-
W katalogu obiektu znajduje się plik menu.xml, zawierający dowiązania
dostępne w pasku nawigacyjnym stron HTML dla danego obiektu.
-
W katalogu obiektu w podkatalogu docs znajdują się dokumenty SVG/ISL
i HTML/ISL dla konkretnego obiektu.
-
W katalogu obiektu w podkatalogu resources znajdują się dokumenty dla
danego obiektu nie podlegające przetworzeniu przez procesor XSLT (np. obrazki
i dokumenty HTML).
Użytkownik odwołuje się do dokumentów przez podanie ścieżki dostępu w postaci:
http://adres_serwera/nazwa_obiektu/rodzaj_dokumentu/nazwa_dokumentu
Nazwa obiektu jest tożsama z nazwą katalogu, domyślnie jest to main.
Rodzaj dokumentu może być jednym z:
-
html -- dokument HTML generowany ze schematu,
-
png -- obrazek PNG generowany ze schematu,
-
svg -- statyczny dokument SVG generowany ze schematu,
-
dsvg -- dynamiczny dokument SVG (ze skryptami, dla przeglądarki Batik).
Możliwych jest jeszcze kilka innych wartości, koniecznych np. do obsługi
dokumentów z definicjami przy automatycznym odświeżaniu parametrów (zobacz
p. 3.7.1). Nie będą one jednak raczej wpisywane przez
użytkowników w przeglądarce. Domyślnie generowane są dokumenty HTML. Jedynie
w przypadku przeglądarki Batik użytkownik będzie musiał dodać prefiks svg
lub dsvg, aby przeglądać bezpośrednio dokumenty SVG, gdyż Batik nie
obsługuje HTML (zobacz 3.8).
Dodatek A.2
zawiera cały plik
konfiguracyjny opisujący strukturę serwisu. Struktura pliku menu.xml jest
opisana w dodatku A.3.
Przyjęte rozwiązania pozwalają na bardzo łatwe rozbudowywanie i modyfikację
serwisu. Dodanie nowego obiektu (zestawu schematów) wiąże się z utworzeniem
nowego katalogu. Nowe schematy wystarczy skopiować do odpowiedniego dokumentu i
ewentualnie dodać wpis do pliku menu.xml. Nie wymaga to żadnych zmian
w plikach konfiguracyjnych.
Pod względem instalacji i konfiguracji procesor dokumentów korzystający z
serwera Apache Cocoon jest zupełnie niezależny od pozostałych części systemu
wizualizacji. Ze względu na wykorzystanie Javy może być także uruchamiany na
komputerze z innym niż Linux systemem operacyjnym. Dodatkowo, duże możliwości
Cocoona pozwalają na budowę na jego podstawie bardziej skomplikowanego serwisu
WWW
dla obsługiwanego obiektu przemysłowego i ewentualną jego integrację z systemem
wizualizacji.
Próbna wersja systemu z Cocoonem działała przez kilka tygodni na
serwerze firmy Praterm w Warszawie. Niestety, ta testowa instalacja wykazała,
że rozwiązanie to nie spełnia części postawionych wymagań.
Autorzy Cocoona twierdzą, że został on napisany z dużą dbałością o wydajność
i zużycie pamięci, między innymi przez przekompilowywanie używanych
dokumentów oraz używanie parserów XML typu SAX, nie wymagających wczytywania do
pamięci całego dokumentu. Ma to zapewnić możliwość przetwarzania jednocześnie
wielu olbrzymich dokumentów przy niewielkim zużyciu pamięci [9].
Niestety wnioski z instalacji testowej są zgoła odmienne. Pierwszą sprawą
rzucającą się w oczy jest olbrzymie zapotrzebowanie na pamięć. W systemie
z zainstalowaną pamięcią operacyjną o wielkości 256 MB, oraz partycją wymiany
(ang. swap)
o wielkości 500 MB, działanie Cocoona powodowało nie tylko olbrzymie
spowolnienie pracy systemu przez intensywne korzystanie z partycji wymiany, ale
także zgłaszanie przez maszynę wirtualną Javy komunikatów o braku pamięci.
Stabilność działania całości także nie jest najlepsza. Cocoon potrzebuje sporo
czasu po uruchomiwniu, żeby zacząć poprawnie działać.
W czasie pierwszym kilku odwołań po starcie
zdarzają się dziwne błędy, typu nieprzekazywanie parametrów do procesora XSLT.
W czasie późniejszej pracy także zdarza mu się czasami odesłać przeglądarce
pusty dokument, co zapewne w większości przypadków wiąże się z kłopotami z
pamięcią.
Do działania konwersji SVG do grafiki bitmapowej w systemach typu UNIX
potrzebny jest działający
X serwer (wykorzystują go klasy Javy używane przez Batika do tworzenia
grafiki11).
Jest to problemem, jeżeli chcemy, aby Cocoon był uruchamiany automatycznie przy
starcie, między innymi ze względu na problemy z autoryzacją Batika wobec
X serwera. Może to wymagać modyfikacji skryptów startowych systemu.
Sama instalacja Cocoona nie jest prosta. Wymaga zainstalowania wcześniej maszyny
wirtualnej Javy oraz Tomcata. Nie wszystkie kombinacje wersji trzech wymaganych
elementów chcą ze sobą poprawnie współpracować (między innymi używana przeze
mnie wersja Cocoona 2.0.1 nie chciała działać z Javą w wersji 1.4 oraz Tomcatem
nowszym niż 4.0.1). Obie wykonane przeze mnie instalacje, na dwóch różnych
komputerach z systemem GNU/Linux, wymagały ręcznych ingerencji, wykraczających
poza kroki opisane w dokumentacji serwera.
Część z tych problemów wynika prawdopodobnie z nienajlepszego opracowania
linuksowych wersji maszyny wirtualnej Javy (które są np. przez firmę Sun
traktowane nieco po macoszemu w stosunku do wersji przeznaczonych dla systemów
Windows). Problem z pamięcią można by prawdopodobnie rozwiązać przez dokupienie
większej ilości pamięci, oraz, być może, użycie innych wersji elementów
systemu. Ogólnie nie wystawia to jednak
najlepszego świadectwa dojrzałości Javy jako
narzędzia do tworzenia dużych i skomplikowanych systemów.
O ile praca wykonana przy dostrajaniu systemu mogłaby być do
zaakceptowania w przypadku pojedynczej instalacji, to staje się poważnym
kłopotem jeśli chcemy wykonać ich więcej. Zgodnie z wymaganiami
opisanymi w p. 2.10, dotyczącymi instalacji systemu
na istniejącym sprzęcie, być może nienajwyższej klasy,
wymagania pamięciowe Cocoona
także wydają się trudne do zaakceptowania.
W tej sytuacji, po zebraniu doświadczeń z dwoma wykonanymi instalacjami systemu
wizualizacji z serwerem Cocoon, podjąłem decyzję o implementacji własnego
rozwiązania. Powinno one mieć, być może kosztem mniejszej funkcjonalności,
nieduże wymagania sprzętowe i charakteryzować się prostotą instalacji.
Własną implementację procesora dokumentów opisuję w p.
3.7.3. To właśnie rozwiązanie było podstawą do wykonanego
w ramach pracy wdrożenia.
Możliwość wykorzystania Cocoona nadal pozostaje otwarta. Może być on
użyty jako część systemu wizualizacji tam, gdzie większe wymagania wobec
funkcjonalności oraz opisane niedostatki drugiego proponowanego rozwiązania,
uzasadniają większe nakłady na sprzęt, instalację i konfigurację systemu.
3.7.3 Implementacja własnego procesora dokumentów opartego na XSLT
Przystępując do samodzielnej implementacji procesora dokumentów miałem bardzo
dokładnie określony obraz tego, co chciałem uzyskać. Zaproponowana przez
Cocoon struktura konfiguracji i ustalony przeze mnie schemat tworzenia serwisu
okazał się wygodny i dobrze spełniający wymagania dotyczące łatwości
modyfikowania i dodawania nowych schematów. Także przygotowane przeze mnie
szablony XSL zakładały w pewien sposób konkretny układ dokumentów źródłowych,
między innymi przy obsłudze dowiązań względnych.
Zdecydowałem więc, że mój program będzie musiał emulować wykorzystywaną przeze
mnie część funkcjonalności Cocoon, korzystając z takiego samego schematu
rozmieszczenia dokumentów źródłowych i tych samych szablonów. Pozwala to także
na swobodną podmianę używanego procesora dokumentów z mojego rozwiązania na
serwer Cocoon i odwrotnie.
Rozważałem także możliwość wykorzystania bezpośrednio plików konfiguracyjnych
Cocoona sitemap.xmap, ale odrzuciłem ostatecznie to rozwiązanie. Pliki te
są dość rozbudowane i dotyczą także funkcjonalności, której nie miałem zamiaru
implementować. W szczególności istotną ich częścią są ścieżki do skompilowanych
klas Javy, które w moim rozwiązaniu nie mogłyby być obsługiwane w żaden
rozsądny sposób.
Poza tym pojawiła się także potrzeba dodania rozszerzeń,
specyficznych dla mojego programu, a związanych np. z obsługą schowka, który
w Cocoonie jest obsługiwany na nieco innym poziomie (w plikach konfiguracyjnych
cocoon.xconf).
Ponieważ głównym powodem pisania programu były wymagania wydajnościowe,
naturalnym wyborem języka programowania było C. Podobnie jak w wypadku serwera
parametrów, ze względu na łatwiejszą modyfikację programów obiektowych
ostatecznie jest to proste C++. Umożliwiło to także wykorzystanie napisanej
wcześniej biblioteki do realizacji funkcjonalności serwera HTTP (opis
biblioteki znajduje się w p. 3.4).
Oferowaną przez program funkcjonalność można najłatwiej opisać przez
prześledzenie struktury pliku konfiguracyjnego programu. Ścieżka do tego pliku
jest zapisana w głównym pliku konfiguracyjnym systemu SZARP.
Struktura pliku konfiguracyjnego inspirowana jest rozwiązaniami zastosowanymi w
Cocoonie. Oparta jest na potokach opisujących sposób przetwarzania żądań
klienta i ma postać dokumentu XML.
Decyzja o wyborze konkretnego potoku oparta jest na związanym z nim wyrażeniu
regularnym, do którego dopasowywana jest podana przez klienta ścieżka (URI). Po
podjęciu decyzji o wyborze potoku, zależnie od jego postaci, może być wykonanych
kilka różnych akcji:
-
Jeżeli potok zawiera element <redirect-to/> z atrybutem uri,
to do klienta jest wysyłana odpowiedź HTTP zawierająca przekierowanie na
wskazany przez atrybut adres. Wartość atrybutu może zawierać ciągi znaków
o postaci \n, gdzie n jest cyfrą 0 -- 9.
Wystąpienia takich
napisów zamieniane są na fragmenty podanego przez klienta URI, opisane przez
podwyrażenia związanego z potokiem wyrażenia regularnego, o kolejnym numerze
określonym przez n (\0 oznacza całe wyrażenie).
Tak więc np. poniższy fragment pliku konfiguracyjnego spowoduje
przekierowywanie żądań zawierających nazwę obiektu na odpowiedni plik index.html w podkatalogu obiektu:
<map:match pattern="^\([^/.]*\)[/]\?$">
<map:redirect-to uri="\1/index.html"/>
</map:match>
-
Wystąpienie elementu <read/> powoduje wysłanie do klienta dokumentu
ściągniętego z sieci lub przeczytanego z dysku. Położenie dokumentu określa
atrybut uri, na którym także dokonywane są ewentualne
podstawienia fragmentów URI. Atrybut mime-type
określa deklarowany przez
serwer rodzaj zawartości dokumentu. Jeżeli atrybutu nie ma, a dokument jest
ściągany z sieci, to jest używany typ otrzymany od serwera, z którego
pobrano dokument.
Jeżeli zaś dokument jest odczytywany z dysku, to domyślnie wysyła się go
jako dokument HTML. Na atrybucie wartości mime-type także
dokonywane są podstawienia za napisy \n.
Ponieważ program i używana biblioteka serwerowa HTTP nie zapewnia mechanizmów
obsługi schowka, przydatny może być atrybut expire. Określa on czas (w
sekundach) deklarowanej przez serwer ważności dokumentu, co można wykorzystać do
zabezpieczenia przed niepotrzebnym ściąganiem przez klientów dokumentów
statycznych. Domyślnie czas ten wynosi 10 sekund, co jest wartością odpowiednią
dla dynamicznych dokumentów z wartościami parametrów.
Przykładowa reguła
odczytująca z dysku obrazki mogłaby wyglądać następująco:
<map:match pattern="^[^./]\+/images/\([^/.]\+\)\.\([^./]\+\)$">
<map:read uri="resources/images/\1.\2" mime-type="image/\1"
expire="3600"/>
</map:match>
Rodzaj obrazka ustalany jest dynamicznie, zależnie do rozszerzenia żądanego
pliku.
-
Ostatnią i najważniejszą możliwością jest umieszczenie elementu <generate/>. Oznacza to rozpoczęcie przetwarzania dokumentu przez procesor
XSLT. Podstawiany atrybut uri zawiera URI dokumentu źródłowego.
Następnie może wystąpić dowolna liczba (być może 0) elementów <transform/>. Ich atrybut src określa ścieżkę do pliku z szablonem XSLT,
za pomocą którego będzie przetworzony dokument. Dokument wyjściowy jest
przesyłany dalej, na przykład do przetworzenia przez następny element <transform/>. Do procesora XSLT mogą być przekazywane parametry. Deklaracja
parametrów odbywa się przez umieszczenie wewnątrz elementu <transform/>
elementów <param/>. Ich atrybuty name i value określają
odpowiednio nazwę i wartość parametru. Na atrybucie value dokonywane są
podstawienia fragmentów URI. Umieszczenie elementu <use-request-parameters/> spowoduje przekazanie do procesora XSLT jako
parametrów także opcji podanych przez klienta w żądaniu HTTP.
Ostatnim elementem musi być element <serialize/>. Jego atrybut type
określa nazwę używanego serializatora, czyli obiektu odpowiadającego za
ostateczne przekształcenie dokumentu do dowolnej postaci (w tym binarnej).
Użyte serializatory muszą być wcześniej w pliku konfiguracyjnym zadeklarowane
przez użycie elementu <serializer/>. Jego atrybutami są nazwa, typ
generowanego dokumentu oraz funkcja serializująca. Nazwa (atrybut name)
identyfikuje serializator i jest wykorzystywana później przez elementy <serialize/>. Typ (atrybut mime-type)
określa deklarowany przez serwer typ MIME
dokumentu. Funkcja (atrybut function)
służy do identyfikacji fragmentu kodu programu
odpowiedzialnego za działanie serializatora. Nie jest możliwe, jak to było w
przypadku napisanego w Javie Cocoona, dynamiczne ładowanie odpowiednich klas.
Funkcje serializujące muszą być więc wcześniej zarejestrowane w kodzie
programu. Dodanie własnej funkcji, o odpowiednio zdefiniowanym prototypie jest
proste, ale wymaga przekompilowania programu.
Ostatnim możliwym atrybutem
elementu <serializer/> jest atrybut compression, określający
stopień kompresji, jakiej mają być poddane dane wyjściowe. Wartość 9 oznacza
najwyższą kompresję, wartość 0 (domyślna) -- brak kompresji. Używana jest
biblioteka zlib, oferująca kompresję w formacie GNU zip.
Standardowo w programie obecne są dwie funkcje serializujące. Pierwsza po prostu
kopiuje dane na wyjście, używana jest więc przy generowaniu różnego typu
dokumentów XML (SVG i HTML). Druga zamienia dokument SVG na obrazek PNG.
Deklaracja standardowego serializatora HTML wygląda więc następująco:
<map:serializer name="html" mime-type="text/html; charset=UTF-8"
function="xml"/>
Tak zaś może wyglądać reguła tworząca z dokumentów HTML/ISL wyjściowe
dokumenty HTML:
<map:match pattern="\([^./]\+\)/\([^./]\+\)\.\(html\|isl\)">
<map:generate uri="\1/docs/\2.html"/>
<map:transform src="stylesheets/embed_isl2doc.xsl">
<map:param name="name" value="\1/\2.html"/>
</map:transform>
<!-- page layout -->
<map:transform src="stylesheets/doc2html.xsl">
<map:param name="object" value="\1"/>
</map:transform>
<map:serialize type="html"/>
</map:match>
Formalny opis formatu pliku konfiguracyjnego programu jest zawarty w dodatku
A.4. Wszelkie informacje o błędach
w konfiguracji zapisywane są w dziennikach programu.
Struktura samego programu jest dość prosta. Podczas wczytywania pliku
konfiguracyjnego tworzone są obiekty odpowiednich klas Macher, Transformer i Serializer, odpowiadające elementom <match/>, <transform/> i <serializer/> z pliku konfiguracyjnego.
Do parsowania dokumentów XML oraz jako biblioteka kliencka HTTP (do pobierania
dokumentów źródłowych z sieci) wykorzystywana jest biblioteka libxml2 [12]. Do transformacji XSLT używam biblioteki libxslt [13]. Aby przyspieszyć przetwarzanie dokumentów, szablony
XSLT wczytywane są raz, przy pierwszym odwołaniu i przechowywane w postaci
prekompilowanej. Żądania klientów parsowane są przez bibliotekę HTTP
i przekazywane do obiektu, który wybiera odpowiedni pasujący potok i zleca mu
przetworzenie dokumentu. Wygenerowany dokument lub informacja o przekierowaniu
zwracane są do biblioteki HTTP, która wysyła odpowiedź do klienta.
Źródłowe dokumenty XML wczytywane są do pamięci i tam przetrzymywane oraz
przetwarzane. Skutkuje to dość szybką pracą programu, ale powoduje ograniczenie
wielkości przetwarzanych dokumentów przez dostępną pamięci operacyjną.
W zastosowaniu programu jako części systemu wizualizacji nie powinno to być
problemem, gdyż przetwarzane dokumenty nie są bardzo duże, może to mieć
natomiast znaczenie przy ewentualnych innych zastosowaniach.
Jednym z większych problemów, jakie napotkałem w trakcie pisania programu, była
realizacja rasteryzacji SVG. Samodzielne jej napisanie przekracza znacznie
objętość pracy magisterskiej. Okazało się także, że nie
ma dostępnych żadnych darmowych bibliotek w języku C. Istnieją właściwie
tylko dwie biblioteki, Batik oraz SVGToolkit, obie napisane w Javie. Ze
względu na problemy opisane w rozdziale o Cocoonie (3.7.2),
nie chciałem jednak korzystać z rozwiązań w Javie.
Ostatecznie udało mi się napisać funkcję eksportującą dokument SVG
do formatu PNG z wykorzystaniem kodu używanego przeze mnie edytora
Sodipodi (zob. p. 3.6.2). Niestety rozwiązanie to
ma szereg wad:
-
Nie udało mi się połączyć kodu Sodipodi z moim programem. Powodem jest
wykorzystywanie przez Sodipodi biblioteki libxml w wersji 1,
niekompatybilnej z używaną przeze mnie wersją 2. Musiałem więc wykonywać
rasteryzację z użyciem zewnętrznego programu, stworzonego przeze mnie na
podstawie Sodipodi (program nazwałem Sodipng).
Zaletą takiego rozwiązania jest uniezależnianie się od niestabilności Sodipodi
(błąd w zewnętrznym programie nie ma wpływu na stabilność reszty
systemu). Wadą jest mniejsza szybkość działania, spowodowana koniecznością
uruchamiania za każdym razem zewnętrznego programu.
-
Mimo, że program Sodipng wykorzystuje niewielką część funkcjonalności Sodipodi,
musiał zostać połączony z całością kodu. Wynika to z gęstej sieci
wzajemnych powiązań w plikach nagłówkowych. Rezultatem jest spory rozmiar kodu
programu, a więc także wolniejsze działanie.
-
Algorytm rasteryzujący Sodipodi posiada kilka drobnych błędów. Co gorsza,
jakość generowanego obrazu pogarsza się, jeśli rasteryzacja wykonywana jest bez
podłączenia do X serwera (a tak jest w programie Sodipng). Błędy objawiają się
widocznymi wadami wygenerowanej grafiki (np. zanik niektórych elementów
schematu). Występują tylko w niektórych schematach, choć trudno to wcześniej
(przy tworzeniu schematu) przewidzieć. Część błędów nie pojawia się w nowszych
przeglądarkach WWW, lepiej obsługujących format PNG.
-
Używany przez Sodipodi parser XML (z biblioteki libxml w wersji 1)
niepoprawnie parsuje generowany przez bibliotekę libxslt dokument XML,
jeśli występują w nim polskie litery i inne znaki poza standardowym zestawem
ASCII (o kodach do 128). W związku z tym polskie litery muszą być zamieniane
przez funkcję serializującą na angielskie odpowiedniki, zwłaszcza że Sodpodi
nie postrafi też poprawnie renderować czcionek w kodowaniu innym niż
ISO-8859-1.
Wady te nie dyskwalifikują rozwiązania. Być może jednak, jeśli okażą się bardzo
uciążliwe dla użytkowników, konieczne będzie inne rozwiązanie problemu
rasteryzacji SVG, na przykład z wykorzystaniem jednak któregoś z rozwiązań
wykorzystujących Javę.
Konieczność instalacji programu Sodipng komplikuje nieco instalację całego
systemu. Na szczęście, poszczególne elementy systemu są od siebie niezależne.
W szczególności procesor dokumentów będzie działał bez programu Sodipng,
niedostępne będzie jedynie generowanie zastępczej postaci schematów -- grafiki
w formacie PNG.
Instalacja i konfiguracja procesora dokumentów,
zgodnie z wymaganiami, nie wymaga zmian
w konfiguracji pozostałych elementów systemu. Konieczne jest jedynie dodanie
parametru map_file do głównego pliku konfiguracyjnego systemu SZARP.
Parametr ten wskazuje położenie pliku konfiguracyjnego programu.
Średni czas przetwarzania żądania klienta na komputerze z zegarem około 1 GHz
wynosił podczas testów od poniżej 1 milisekundy (dla czytanych z dysku małych
dokumentów), do kilku milisekund dla prostych generowanych dokumentów
HTML. Generowanie bardziej skompilowanych schematów zajmowało do około 200 ms
(dla schematów takich jak ten na stronie
??). Jedynie generowanie grafiki PNG za pomocą programu Sodipng
jest dość wolne, dla prezentowanego schematu czas wynosił od pół do półtorej
sekundy. Podane czasy nie uwzględniają czasu potrzebnego na przesłanie
dokumentu przez sieć.
Zastosowania programu, nazwanego przeze mnie xsltd, nie ograniczają się
tylko do tworzonego w ramach pracy systemu wizualizacji. Może on także służyć
do budowania innego typu serwisów WWW, wymagających przetwarzania dokumentów XML
za pomocą szablonów XSLT. Zaadoptowany z Cocoona schemat konfiguracji jest
bardzo elastyczny, umożliwia dobre oddzielenie struktury logicznej serwisu
(opisanej w pliku konfiguracyjnym) od zawartości dokumentów (zapisanej w samych
dokumentach) i ich wyglądu (opisanych przez szablony XSLT). Dodawanie i
modyfikacja dokumentów nie wymagają restartowania programu. Jedynie zmiany w
szablonach zostaną uwzględnione dopiero przy ponownym uruchomieniu programu.
Niewielkie w porównaniu z Cocoonem możliwości programu w części
zastosowań są w pełni rekompensowane przez łatwość instalacji, szybkość
działania i nieduże wymagania pamięciowe.
3.8 Oprogramowanie klienckie
Zgodnie z założeniami przedstawionymi w p. 3.1
oprogramowaniem klienckim dla tworzonego systemu mają być standardowe
przeglądarki WWW. Wykorzystanie pełnych możliwości systemu wymaga jednak użycia
przeglądarki obsługującej SVG.
SVG jest technologią stosunkowo młodą. Przyjemność z pracy z nowymi
technologiami jest niestety często okupowana problemami, jakie towarzyszą
,,wiekowi młodzieńczemu'' tych rozwiązań. Specyfikacja SVG wydaje się dobrze
skonstruowana. Wielu specjalistów uważa, że jest to jedna z
najważniejszych
opracowanych ostatnio technologii dotyczących Internetu, która może poważnie
wpłynąć na sposób korzystania z sieci, uwalniając użytkowników od
nadal tekstowego w swojej istocie świata HTML12.
Ze względu na złożoność specyfikacji największym problemem nadal jest
niewystarczająca liczba implementacji, zwłaszcza tych obsługujących pełny zakres
funkcjonalności opisanej w specyfikacji, na przykład modyfikację dokumentu
przez manipulowanie jego modelem obiektowym (ang. Document Object Model).
W moim projekcie przewidziałem zastosowanie 3 typów rozwiązań po stronie
klienta, odpowiadających różnym poziomom obsługi SVG:
-
Brak obsługi SVG -- niestety nadal jest to stan najczęściej spotykany wśród
użytkowników Internetu. Zastępczo klienci tacy otrzymują statyczne bitmapy
generowane na podstawie schematów. Użycie map HTML emuluje część
funkcjonalności SVG związanej z dowiązaniami.
Grafika bitmapowa jest generowana w formacie PNG.
Z innym popularnym formatem, GIF (Graphics Interchange Format)
związane są problemy natury prawnej13. Niektóre przeglądarki mają
problemy z poprawnym wyświetlaniem grafiki PNG. Dotyczy to np. przeglądarek
Netscape Navigator w wersji linuksowej, do najnowszej dostępnej w chwili
pisania pracy wersji 4.79
włącznie. Poprawnie PNG wyświetlają przeglądarki Internet Explorer oraz
Mozilla.
Netscape ma też poważne problemy z obsługą wielu elementów specyfikacji HTML
4.01. Dlatego też część grafiki wchodzących w skład systemu stron HTML
renderowana jest niepoprawnie. Oczywiście jest to kwestia dopracowania
szablonów. Na razie, ze względu na niewielką popularność tej przeglądarki, nie
zajmowałem się tym problemem.
-
Obsługa SVG przez użycie bezpłatnej wtyczki
Adobe SVG Viewer 3.0 [1] jest najpopularniejszym
wśród internautów i właściwie jedynym powszechnie dostępnym sposobem obsługi
SVG. Firma Adobe, dzięki pracy nad wtyczką, oraz opracowaniu dobrego narzędzia
do tworzenia grafiki SVG jakim jest Adobe Illustrator 10, wydaje się
najaktywniejszą z firm zajmujących się implementacją SVG. To właśnie wtyczka
Adobe ma szansę na popularyzację SVG wśród użytkowników sieci.
Obecna wersja współpracuje z przeglądarkami dla systemów Windows i MacOS.
Dostępnych jest wiele wersji językowych (polska tylko niestety w wersji 2.0).
Wersja dla Linuksa działa tylko z niektórymi wersjami Mozilli (np. 0.9.9)
i firma nie oferuje dla niej pomocy ani wsparcia technicznego. Dostępna jest
jedynie wersja binarna, w postaci biblioteki dzielonej. Wymaga ona bibliotek
glibc w wersji 2.2 (a więc działa np. w dystrybucji Red Hat od wersji 7.1).
We współpracy z przeglądarką Mozilla 0.9.9 wtyczka przy pierwszym uruchomieniu
wymaga zwykle przeładowania strony, poza tym działa stabilnie.
W połączeniu z przeglądarką
Internet Explorer wtyczka nie obsługuje poprawnie elementów
<object/> w dokumentach HTML. Wygląda to tak, jakby rozpoczynała
pobieranie dokumentu, ale nie kończyła go. Do serwera nie jest wysyłane żadne
żądanie. W efekcie opisane w p. 3.7.1 automatyczne
wybieranie zawartości przy wyświetlaniu dokumentów HTML/ISL
nie działa w obecności wtyczki. Obejściem tego problemu
jest generowanie specjalnej wersji stron dla Internet Explorera z wtyczką,
zawierającej zamiast elementu <object/> element <embed/>.
Wybranie tej wersji wymaga ingerencji użytkownika (przez kliknięcie na
dowiązanie umieszczone pod schematem). Dalej obsługa jest już przezroczysta dla
użytkownika, tzn. wybieranie każdego kolejnego dowiązania będzie powodowało
pobieranie z serwera zmodyfikowanej wersji stron. Mechanizm ten jest
realizowany przez odpowiednie wpisy w pliku konfiguracyjnym Cocoona lub
programu xsltd (zob. dodatki A.2
i A.4).
Wtyczka implementuje poprawnie wszystkie wymienione w specyfikacji elementy
graficzne SVG, w tym animacje deklaratywne. Niestety, nie obsługuje poprawnie
części modyfikacji obiektu przez skrypty, w tym dodawania i usuwania elementów.
Poza tym nie pozwala na umieszczanie w elementach <use/> odwołań do
elementów spoza aktualnego dokumentu (zob. p. 3.7.1).
To wszystko powoduje, że w przeglądarce nie działa mechanizm automatycznego
odświeżania wartości parametrów.
Ogólnie obsługa SVG za pomocą wtyczki raczej nie daje nadziei na pełną
integrację SVG z innymi rozwiązaniami XML. W świetle opracowanych przez W3C
założeń, powinno być możliwe np. wstawienie do dokumentu SVG równania
zapisanego w języku MathML lub całego dokumentu XHTML, opisanie go na krzywej
i zastosowanie do wynikowego obiektu filtru graficznego. Uzyskanie takich
efektów wymaga jednak raczej natywnego wsparcia dla SVG w mechanizmie
renderującym przeglądarki.
Mimo wszystko, z braku innych rozwiązań, Adobe SVG Viewer będzie zapewne
rozwiązaniem najczęściej używanym przez użytkowników, którzy nie wymagają
odświeżania parametrów, a chcieliby tylko przejrzeć obrazki.
-
Przeglądarka Batik jest najbardziej wyspecjalizowanym z używanych klientów.
Podobnie jak wtyczka Adobe, poprawnie wyświetla wszystkie elementy graficzne.
Testowana przeze mnie wersja
1.5beta1 obsługuje większość modyfikacji struktury
dokumentu przez skrypty. W połączeniu z poprawną obsługą elementów <use/>
pozwoliło to na implementację automatycznego odświeżania parametrów (więcej
szczegółów w p. 3.7.1). W przeciwieństwie do wtyczki
Adobe nie działają jednak animacje deklaratywne.
Ponieważ Batik jest napisany w Javie, bez problemu działa na większości
popularnych systemów operacyjnych. Niestety, jest dużą aplikacją, więc
korzystanie z niego na starszych komputerach może być uciążliwe. Zasobem
krytycznym jest tu pamięć, co jest dość charakterystyczne dla aplikacji w Javie.
Z drugiej strony wymagania te nie wybiegają poza oczekiwania współczesnych
graficznych interfejsów użytkownika.
Obecne wersje Batika posiadają sporo błędów. Niepoprawnie obsługują np.
dokumenty czytane z dysku. Szablon generujący dynamiczne schematy musi
wstawiać wszystkie dynamicznie modyfikowane elementy w dodatkowy element <g/> (grupowanie obiektów), gdyż inaczej modyfikacje nie działają. Pojawiają
się jednak nowe, lepsze wersje programu, a powaga prowadzącej projekt
instytucji (The Apache Software Foundation) gwarantuje, że nadal będzie on
rozwijany.
Największą wadą Batika jest ograniczenie przeglądarki tylko do obsługi SVG,
a więc niemożność oglądania za jego pomocą innych wchodzących w skład serwisu
WWW dokumentów. Implementacja innych języków nie jest też (przynajmniej na
razie) w ogóle planowana. Z uwagi jednak na fakt, że tylko Batik umożliwia
implementację automatycznego odświeżania wartości parametrów, to właśnie on
powinien być traktowany jako główna i docelowa aplikacja kliencka systemu.
Ponieważ zaimplementowane w ramach projektu rozwiązania, także te realizujące
automatyczne odświeżanie parametrów, są zgodne z oficjalnymi specyfikacjami
standardów W3C, jest nadzieja, że system będzie odnosił bezpośrednie korzyści
z rozwoju dostępnych implementacji SVG. Pojawienie się przeglądarek
wykorzystujących pełnię możliwości oferowanych przez SVG i inne pokrewne
technologie jest zapewne tylko kwestią czasu. Być może więc opisane w tym
rozdziale problemy techniczne, które miały dość spory wpływ na kształt
implementacji projektu, za kilka lat będą mogły być traktowane wyłącznie
jako historyczne
ciekawostki.
- 1
- Portable Network Graphics -- format skompresowanej grafiki
bitmapowej używanej powszechnie w Internecie [3].
- 2
- Document Object Model -- niezależny od
platformy i języka programowania interfejs, pozwalający programom i skryptom na
dostęp i modyfikację treści i struktury dokumentu XML.
- 3
- Do
obsługi XML wykorzystywana jest biblioteka libxml2, dostępna
pod adresem http://www.xmlsoft.org [12].
- 4
- Uniform Resource
Identifier -- identyfikator określający położenie zasobu w sieci WWW, jego
postać określa dokument RFC 2396.
- 5
- Przykład
ten można obejrzeć pod adresem http://www.praterm.com.pl:8180/test/termometr.html.
Wyświetlana jest temperatura powietrza w Pasłęku.
- 6
- Schemat dostępny jest też pod adresem
http://213.76.238.20:8083.
- 7
-
Oficjalna strona projektu Sodipodi to http://sodipodi.sourceforge.net.
Repozytorium CVS znajduje się na serwerze anoncvs.gnome.org,
moduł sodipodi. Wpis w pliku ChangeLog dotyczący
moich zmian znajduje się pod datą 4 maja 2002 roku.
- 8
- Identyfikator przestrzeni nazw xlink
musi być związany z URI http://www.w3.org/1999/xlink oznaczającą
przestrzeń nazw XLink.
- 9
- Dokumenty takie będę dalej nazywał dokumentami
HTML/ISL. Dokładna specyfikacja ich formatu jest podana w dodatku
B.3.
- 10
- XML Include -- rekomendacja
World Wide Web Consortium, określająca sposób tekstowego włączania
dokumentów XML do innych dokumentów XML.
- 11
- Wymaganie to nie występuje, jeśli korzystamy z Javy w wersji
1.4. Nie jest ona jednak do końca zgodna z poprzednimi wersjami, może wymagać
przekompilowania programów.
- 12
- Wybór
najważniejszych artykułów, informacje o powstajacych
implementacjach i inne ciekawostki dotyczące SVG można znaleźć na
stronach World Wide Web Consortium, http://www.w3c.org.
- 13
-
Używany w formacie GIF algorytm kompresji LZW (Lempel-Ziv-Welsh)
jest opatentowany przez UniSys. Dlatego też oprogramowanie tworzące
grafikę w formacie GIF podlega opłacie patentowej na rzecz
właściciela patentu. Patent obejmuje tylko oprogramowanie, które
dokonuje zarówno kompresji jak i dekompresji, teoretycznie więc
oprogramowanie tylko dekompresujące nie jest nim objęte. UniSys
w przeszłości nie zgadzał się z taką interpretacją zapisów we
wniosku patentowym. Informacje na podstawie: Graphics File Format FAQ:
General Graphics Format Questions,
http://www.ora.com/infocenters/gff/gff-faq/.