Design of the Munin Distributed Shared Memory System. John B. Carter. Appeared in Journal of Parallel and Distributed Computing, September 1995.
Techniques for Reducing Consistency-Related Communication in Distributed Shared Memory Systems. John B. Carter, University of Utah; John K. Bennett and Willy Zwaenepoel, Rice University. A version of this paper appeared in TOCS August '95.
Ze względów wydajnościowych przy realizacji dostępu do pamięci dzielonej korzysta się z:
lokalnych pamięci podręcznych - każdy proces ma lokalnego zarządcę kopii; w realizacji opartej na stronicowaniu rolę tę pełni jądro systemu operacyjnego, a w realizacji z dzielonymi obiektami - same procesy (kiedy wykonują kod procedur bibliotecznych),
buforowania operacji pisania - amortyzując koszt komunikacji przez rozkładanie go na wiele operacji pisania.
W pewnych sytuacjach jest do przyjęcia pewien stopień niespójności danych. Najczęściej jednak aplikacje mają pewne oczekiwania co do sposobu, w jaki powinna się zachowywać pamięć.
Przykład (inicjalnie a = b = 0):
Proces 1 Proces 2
br:=b; a := a+1;
ar:=a; b := b+1;
if (ar>=br) then
print("OK");
Nie stosuje się żadnej synchronizacji na poziomie aplikacji.
Jakich kombinacji wartości można intuicyjnie oczekiwać:
ar = 0, br = 0
ar = 1, br = 0
ar = 1, br = 1
Czyli zawsze ar >= br i proces 1 wydrukuje OK.
Realizacja pamięci dzielonej może jednak dopuszczać sytuację, gdy aktualizacja zmiennych a i b jest dostarczana zarządcy kopii używanych przez proces 1 w zmienionej kolejności.
Modele spójności pamięci różnią się odpowiedzią na następujące pytanie: jeśli ma nastąpić czytanie komórki pamięci, to które ze skutków zapisywania tej komórki kandydują ze swoimi wartościami jako możliwe wyniki czytania?
Model spójności jest zasadniczo kontraktem między procesami a pamięcią. Zgodnie z tym kontraktem jeśli procesy zgodzą się podporządkować pewnym zasadom, to pamięć obiecuje zachowywać się poprawnie.
Przyjmijmy następującą notację:

Rysunek: zachowanie z punktu (a) jest zgodne z modelem spójności ścisłej, a zachowanie z punktu (b) nie jest zgodne. (źródło: Tanenbaum, Distributed Systems)
Do głównych modeli spójności dających się praktycznie urzeczywistniać w implementacjach pamięci dzielonej należą: spójność sekwencyjna i modele oparte na spójności słabej.
Spójność sekwencyjna:
Wynik dowolnego wykonania operacji na pamięci jest równoważny temu, co otrzymuje się przy spełnieniu następujących warunków:
operacje dotyczące pamięci i należące do różnych procesów są wykonywane w pewnej określonej kolejności;
operacje każdego pojedycznego procesu są wykonywane w porządku określonym przez jego program.
Oznacza to w szczególności, że każdy przeplot operacji czytania i pisania pochodzących od poszczególnych procesów jest akceptowalnym zachowaniem, ale wszystkie procesy muszą widzieć dokładnie taki sam przeplot.

Rysunek: zachowanie z punktu (a) jest zgodne z modelem spójności sekwencyjnej, a zachowanie z punktu (b) nie jest zgodne. (źródło: Tanenbaum, Distributed Systems)
Spójność sekwencyjna jest podobna do szeregowalności na zasadzie jednej kopii (dotyczącej transakcji): skutki transakcji wykonywanych przez różnych klientów na zwielokrotnionych obiektach danych będą takie same, jak gdyby wykonywano je po jednej w danej chwili na pojedynczych obiektach danych.
Taki model spójności pamięci można zrealizować za pomocą jednego serwera utrzymującego wszystkie dane dzielone i obsługującego żądania procesów dotyczące operacji czytania i pisania (serwer utrzymywałby globalne uporządkowanie operacji na pamięci).
Spójność słaba:
(1) W tym modelu zakłada się, że nie wszystkie operacje na pamięci muszą być spójne sekwencyjnie, wystarczy, że warunek ten będą spełniały operacje synchronizacyjne. Osłabienie spójności dotyczy więc typu dostępu. (2) Proces nie będzie dopuszczony do zmiennej synchronizacyjnej zanim wszędzie nie zakończy się wykonanie wszystkich poprzedzających operacji pisania. (3) Proces nie będzie dopuszczony do żadnej operacji czytania i pisania zanim nie zakończy się wykonanie wszystkich poprzedzających operacji na zmiennych synchronizacyjnych.
Zgodnie z wymaganiem (1) wszystkie procesy widzą wszystkie operacje na zmiennych synchronizacyjnych w tej samej kolejności. Zgodnie z wymaganiem (2) synchronizacja flushes the pipeline - wymusza wszędzie dokończenie wszystkich rozpoczętych lub nawet gdzieś lokalnie zakończonych, ale nie wszędzie rozpropagowanych operacji pisania. Zgodnie z wymaganiem (3) kiedy wykonuje się operację na danych wszystkie wcześniejsze operacje synchronizacyjne musiały się już zakończyć.
W odróżnieniu od innych modeli spójności, słaba spójność wymusza spójność grupy operacji, a nie pojedynczych zapisów i odczytów.
Obiekty mogą mieć wartości niespójne podczas pobytu procesu w sekcji krytycznej, ale wtedy są niedostępne dla innych procesów.

Rysunek: zachowanie z punktu (a) jest zgodne z modelem spójności słabej, a zachowanie z punktu (b) nie jest zgodne. (źródło: Tanenbaum, Distributed Systems)
Problem ze słabą spójnością polega na tym, że gdy ktoś sięga do zmiennej synchronizacyjnej to, nie wiadomo, czy robi to, gdyż skończył zapisywać współdzielone zmienne, czy też gdyż zaraz zacznie je czytać. W rezultacie trzeba wykonać akcję wymaganą w obu przypadkach, czyli rozpropagować operacje zapisu do wszystkich lokalnych kopii i zebrać wszystkie zapisy wykonane na lokalnych kopiach. W celu rozróżnienia tych dwóch przypadków potrzeba dwóch rodzajów zmiennych synchronizacyjnych lub operacji.
Zapewnia je spójność na wyjściu (lub zwalniania, ang. release consistency). Operacja acquire oznacza chęć wejścia do sekcji krytycznej, a operacja release wyjście z sekcji krytycznej.
Spójność na wyjściu gwarantuje, że kiedy proces wykona acquire, wszystkie lokalne kopie chronionych danych zostaną uzgodnione ze zdalnymi kopiami. Podczas wykonywania release zmodyfikowane dane chronione są propagowane do innych kopii. Wykonanie acquire nie gwarantuje, że lokalne modyfikacje zostaną natychmiast wysłane do zdalnych kopii. Podobnie wykonanie release nie gwarantuje importu zmian z innych kopii.

Rysunek: zachowanie zgodne z modelem spójności na wyjściu. (źródło: Tanenbaum, Distributed Systems)
Zgodność na wejściu (ang. entry consistency) wymaga, aby KAŻDA zwykła zmienna dzielona była związana z pewną zmienną synchronizacyjną. Gdy na zmiennej synchronizacyjnej jest wykonywana operacja acquire, tylko dane związane z tą zmienną synchronizacyjną są uzgadniane.

Rysunek: zachowanie zgodne z modelem spójności na wejściu. (źródło: Tanenbaum, Distributed Systems)
W tej tabeli opisano modele spójności nie korzystające z operacji synchronizacyjnych:
| Spójność | Opis |
| Ścisła | Absolutne uporządkowanie w czasie wszystkich operacji na zmiennych dzielonych |
| Sekwencyjna | Wszystkie procesy widzą wszystkie operacje na zmiennych dzielonych w tej samej kolejności. Operacje te nie są uporządkowane w czasie |
W tej tabeli opisano modele spójności korzystające z operacji synchronizacyjnych:
| Spójność | Opis |
| Słaba | Można zakładać, że zmienne dzielone są uzgodnione jedynie po wykonaniu synchronizacji |
| Na wyjściu | Zmienne dzielone są uzgadniane podczas opuszczania sekcji krytycznej |
| Na wejściu | Zmienne dzielone związane z sekcją krytyczną są uzgadniane na wejściu do sekcji krytycznej |
Aktualizacja przy zapisywaniu:
Aktualizacje wykonywane przez proces mają zasięg lokalny i są rozsyłane do wszystkich innych zarządców kopii posiadających kopie aktualizowanego obiektu, którzy natychmiast zmieniają swoje kopie. Czytanie odbywa się bez wymiany komunikatów. Model: wielu czytelników, wielu pisarzy.
Spójność sekwencyjną można uzyskać stosując rozsyłanie komunikatów zapewniające ich całkowite uporządkowanie. Gwarantuje ono, że we wszystkich procesach kolejność aktualizacji jest taka sama.
Unieważnianie przy zapisywaniu:
Jest stosowane powszechnie w modelu z wieloma czytelnikami i jednym pisarzem. Obiekt dostępny do czytania można kopiować bez ograniczeń. Jeśli proces spróbuje go zapisać, to najpierw rozsyła się do posiadaczy kopii komunikat z żądaniem unieważnienia i dopiero po uzyskaniu od nich potwierdzeń może nastąpić pisanie. Na czas pisania blokuje się dostęp do obiektu innym procesom. Po pewnym czasie pisarz oddaje sterowanie i po rozesłaniu aktualizacji dostęp uzyskują inne procesy.
Schemat ten zapewnia spójność sekwencyjną. W modelu spójności zwalniania opóźnia się rozsyłanie unieważnień.
Prace na ten temat pochodzą z 1986 roku (Li & Hudak). W DSM przestrzeń adresowa jest podzielona na strony, a strony są rozproszone po różnych komputerach. Kiedy CPU odwołuje się do strony, która nie jest dostępna lokalnie, jest generowane przerwanie braku strony i system operacyjny sprowadza stronę ze zdalnej pamięci i restartuje instrukcję (czyli tak jak w standardowej pamięci wirtualnej, tylko, że rolę pamięci dyskowej pełni zdalny RAM).
Rysunek: stronicowany DSM (źródło: Tanenbaum, Distributed Systems)
Podstawowe cechy stronicowanego DSM:
Algorytmy stosujące unieważnianie przy zapisywaniu korzystają z ochrony stron do wymuszania spójności. Procesy czytające dostają wyłączne prawo do czytania, piszące - wyłączne prawo do czytania i pisania.
Proces mający najnowszą wersję strony p: właściciel(p).
Zbiór procesów mających kopie strony p: zbiór_kopii(p).
Procedura obsługi błędu strony, gdy proces Pw próbuje pisać na stronie p, do której nie ma żadnego dostępu lub dostęp tylko do czytania:
strona zostaje przesłana do jądra procesu Pw, jeśli nie ma ono jeszcze aktualnej kopii przeznaczonej tylko do czytania
wszystkie inne kopie zostają unieważnione - cofa się wszystkie prawa dostępu do wszystkich stron ze zbioru zbiór_kopii(p)
zbiór_kopii(p) := {Pw}
właściciel(p) := Pw
jądro odwzorowuje stronę z prawami do czytania i pisania w przestrzeni adresowej procesu Pw, po czym wznawia jego działanie.
Procedura obsługi błędu strony, gdy proces Pr próbuje czytać stronę p, do której nie ma prawa dostępu:
kopiuje się stronę z procesu właściciel(p) do jądra procesu Pr
jeśli bieżący właściciel jest pisarzem, to pozostaje właścicielem strony, z prawem tylko do czytania.
zbiór_kopii(p) := zbiór_kopii(p) + {Pr}
jądro odpowiedzialne za proces Pr odwzorowuje w jego przestrzeń adresową stronę z prawem tylko do czytania, po czym wznawia działanie procesu.
Protokół unieważniania:
Algorytm scentralizowanego zarządcy:
Jeden serwer (zarządca) pamięta adres właściciel(p) dla każdej strony p.
Zbiór_kopii(p) przechowuje się w jądrze właściciela strony.
Lokalne jądro po wystąpieniu błędu strony wysyła do zarządcy komunikat z numerem strony i żądanym typem dostępu (klient czeka na odpowiedź).
Zarządca odszukuje właściciela i przekazuje mu zamówienie (w przypadku żądania pisania czyni klienta nowym właścicielem).
Poprzedni właściciel przesyła stronę klientowi.
W przypadku próby pisania wysyła mu też zbiór_kopii(p), a ten wykonuje unieważnienie (czeka na potwierdzenia).
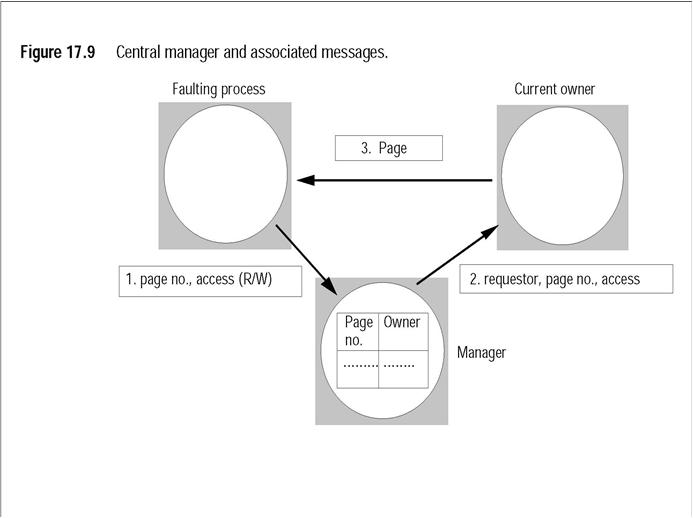
Rysunek: Centralny zarządca i rozsyłane komunikaty (źródło: Coulouris i in., Distributed Systems)
Implementacja zarządcy, która pozwala rozwiązać problem wąskiego gardła:
Zbiór zarządców, każdy odpowiada za pewien ustalony podzbiór zbioru stron - zbyt nieelastyczne.
Właściciela strony odnajduje się za pomocą rozsyłania grupowego - kosztowne, problem z obsługiwaniem przeterminowanych zamówień na strony.
Dynamiczny algorytm zarządcy rozproszonego
Prawo własności strony jest przenoszone między jądrami. Każde jądro utrzymuje dla każdej strony p informację: ewentualny_właściciel(p) (na początku jest to dokładna informacja). Faktycznego właściciela odnajduje się za pomocą łańcucha kolejnych wskaźników. Uaktualnianie wskaźników odbywa się następująco:
Gdy jądro przekazuje prawo własności strony p innemu jądru, wówczas uaktualnia wartość ewentualny-właściciel(p) tak, aby wskazywała odbiorcę.
Gdy jądro obsługuje zamówienie unieważnienia strony p, wówczas uaktualnia wartość ewentualny_właściciel(p) tak, aby wskazywała na zamawiającego.
Gdy jądro otrzymuje zamówiony dostęp do czytania strony p, wówczas uaktualnia wartość ewentualny_właściciel(p) tak, aby wskazywała dostawcę strony.
Gdy jądro otrzymuje zamówienie na stronę p, której nie jest właścicielem, wówczas przekazuje je dalej pod adres pamiętany jako ewentualny_właściciel(p), a zmiennej ewentualny_właściciel(p) nadaje wartość zamawiającego.
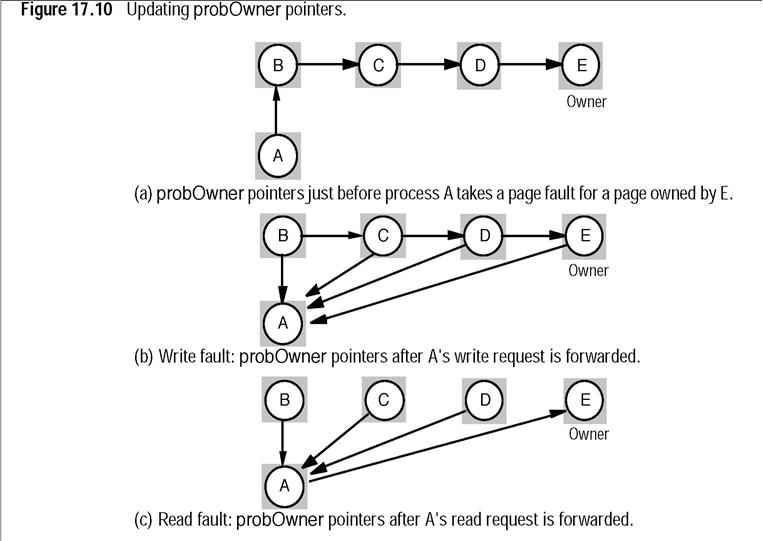
Rysunek: Uaktualnianie wskaźników do ewentualnych właścicieli (źródło: Coulouris i in., Distributed Systems)
Okresowo można rozgłaszać aktualne położenie właściciela.
Spójność zwalniania jest słabsza od spójności sekwencyjnej, ale jest tańsza w realizacji i semantycznie akceptowalna dla programistów.
Operacje synchronizacyjne w systemie Munin: acquireLock, releaseLock, waitAtBarrier.
Program musi stosować synchronizację, aby zapewnić, że aktualizacje staną się widoczne dla innych procesów. Rozsyłanie aktualizacji można odwlekać do wykonania zwolnienia, można je zbierać i przesyłać w jednym komunikacie, można przesyłać tylko ostateczną wartość każdego z obiektów danych.
Realizacja spójności zwalniania w systemie Munin:
Do nadzorowania aktualizowanych stron wykorzystuje się kod biblioteczny. Jądro systemu V pozwala na wykonywanie zmian w tablicach stron procesów z poziomu użytkownika - wykorzystuje się to do nadawania i odbierania prawa do zapisu. System Munin obejmuje ochroną przed zapisem każdą nowo nabytą stronę i odnotowuje identyfikator strony w procedurze obsługi błędu strony, wykonywanej z poziomu użytkownika.
System Munin wysyła informacje aktualizujące lub unieważniające dopiero po zwolnieniu sekcji krytycznej.
Programista może wykonywać adnotacje kojarzące zmienne synchronizacyjne z określonymi obiektami danych. Adnotacje są przenoszone w tym samym komunikacie, który przekazuje prawo wejścia do sekcji krytycznej - odbiorca może skopiować potrzebne mu dane.
W systemie Munin zrealizowano różne protokoły spójności stosowane w odniesieniu do poszczególnych obiektów danych. Programistom dostarczono mały standardowy zbiór adnotacji do zastosowania do obiektów danych (standardowe zestawy parametrów tych protokołów):
Tylko czytanie. Po nadaniu wartości początkowych nie wolno obiektu aktualizować, można go swobodnie kopiować.
Obiekt migrujący. Będzie potrzebnych kilka dostępów do obiektu, w tym aktualizacja. System przydzieli prawo do czytania i do pisania. Używane wewnątrz rejonu krytycznego, migrują z maszyny do maszyny przy wejściu i wyjściu z rejonu, nie posiadają kopii.
Dzielone zapisy. Pozwala na współbieżną aktualizację tego samego obiektu danych, gdy różne procesy aktualizują różne części tego obiektu (np. różne podtablice tej samej tablicy). Munin w procedurze obsługi błędu kopiuje stronę tuż przed jej lokalnym uaktualnieniem, a później rozsyła tylko różnice między wersjami.
Producent-konsument. Obiekt danych jest dzielony przez stały zbiór procesów, z których tylko jeden go uaktualnia.
Redukcja. Obiekt danych jest zawsze zmieniany wg następującego porządku: rezerwacja, czytanie, aktualizacja, zwolnienie. Obiekty takie są pamiętane przez stałego właściciela, aktualizacje są przesyłane do właściciela, który rozsyła je dalej.
Wynik. Wiele procesów (roboczych) aktualizuje części obiektu danych, jeden proces (główny) czyta całość. Wystarczy przekazywać aktualizacje do procesu głównego.
Postępowanie konwencjonalne. Każda zapisywana zmienna jest dostępna tylko w jednej kopii i przesyłana od procesu do procesu na żądanie (zwykły protokół unieważniania).
Procesy na wielu maszynach współdzielą abstrakcyjną przestrzeń wypełnioną obiektami. Zarządza nimi automatycznie system wykonawczy języka programowania. W szczególności decyduje o położeniu obiektów.
Korzyści:
Możliwość rozbudowania dowolnego języka o zestaw prymitywów synchronizacyjnych (np. C-Linda, Fortran-Linda).
Przestrzeń krotek i operacje na krotkach:
("abc", 2, 5)
("macierz-1", 1, 6, 3.14)
("rodzina", "jest siostrą", "Alicja", "Elżbieta")
out("abc", 2, 5) - wstawia krotkę do przestrzeni
in("abc", 2, i) - wyjmuje krotkę z przestrzeni
read("abc", 2, i) - sprawdza istnienie krotki w przestrzeni
Paradygmat programowania: model powielonych pracowników
out("pula-zleceń", "zlecenie")
in("pula-zleceń", moje-zlecenie)
Implementacja:
Preprocesor czyta program w Lindzie i przekształca go w program w języku bazowym. Operacje na krotkach są realizowane podczas wykonania programu przez system wykonawczy Lindy.
Problemy:
Każda krotka ma sygnaturę typu (uporządkowana lista typów pól). Pierwsze pole jest zwykle napisem. Dzieli się przestrzeń krotek na podprzestrzenie o tej samej sygnaturze i pierwszym polu. Pozwala to ograniczyć (a więc usprawnić) przeszukiwanie. Każdą podprzestrzeń organizuje się jako tablicę haszującą z i-tym polem krotki jako kluczem.
W multiprocesorze: podprzestrzenie można zaimplementować jako tablice haszujące w pamięci wspólnej. Na czas wykonania in i out blokuje się dostęp do podprzestrzeni.
W multikomputerze: jeśli jest dostępne rozgłaszanie, to powiela się w całości podprzestrzenie na wszystkich maszynach. Podczas realizacji out rozgłasza się nową krotkę i wprowadza do każdej podprzestrzeni. Podczas realizacji in pobiera się ją z lokalnej podprzestrzeni i usuwa z pozostałych maszyn (dwufazowe wykonanie, ang. two-phase commit).
Inne rozwiązanie: out wykonuje się lokalnie, in powoduje rozgłoszenie wzorca krotki. Jeśli zostanie przesłana więcej niż jedna krotka, to nadmiarowe traktuje się jak lokalne out.
Inne rozwiązanie: częściowe powielanie - połączenie dwóch poprzednich metod (wszystkie maszyny tworzą logiczną macierz: out jest rozgłaszane wzdłuż wiersza tej macierzy, a in wzdłuż kolumny).
Współdzielone obiekty
Dozory: jeśli wszystkie dozory danej operacji są fałszywe, to wstrzymuje się proces do czasu, aż jeden stanie się prawdziwy. Następnie wykonuje się blok instrukcji związany z prawdziwym dozorem.
OBJECT IMPLEMENTATION stack;
top: integer;
stack: ARRAY [integer 0..N - 1] OF INTEGER;
OPERATION push(item: integer);
BEGIN
GUARD top < N DO
stack[top] := item;
top := top + 1;
END
OPERATION POP(): integer;
BEGIN
GUARD top > 0 DO
top := top - 1;
RETURN stack[top];
END:
BEGIN
top := 0;
END;
Tworzenie procesów: fork tworzy na wskazanym procesorze proces wykonujący wskazaną procedurę; można mu przekazać obiekt jako parametr. System wykonawczy realizuje iluzję pamięci dzielonej. Operacje na obiektach dzielonych są atomowe, wzajemnie wykluczające się i sekwencyjnie zgodne (jeśli dwa niezależne procesy wstawią na stos, odpowiednio, 3 i 4, to każdy inny proces wykonujący top zauważy na stosie to samo.
s: stack;
for i in 1..n do fork proc(s) on i; od;
Każdy z obiektów może być (niezależnie od innych) w stanie: pojedynczy lub powielony; stan obiektu może się zmieniać. Obiekt powielony jest obecny na wszystkich maszynach, na których znajduje się używający go proces. Możliwe przypadki:
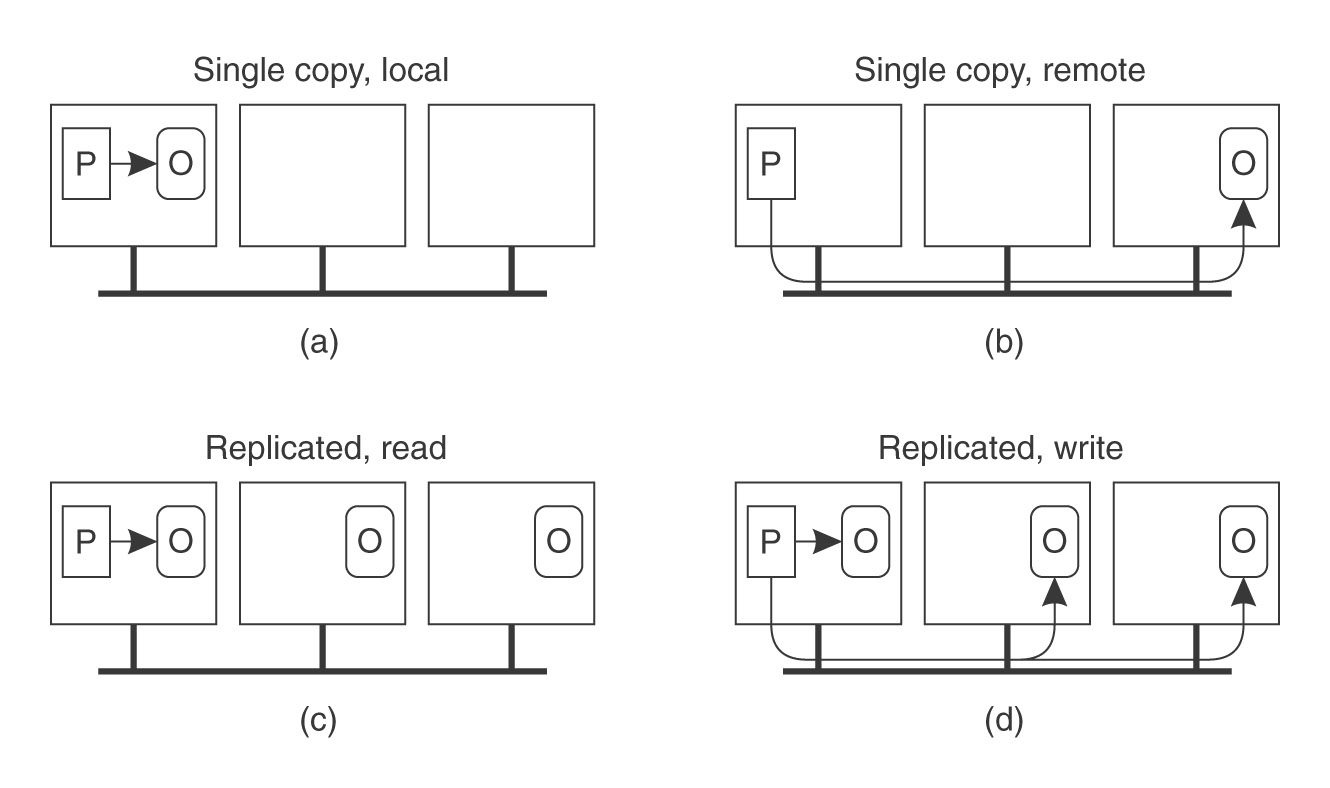
Rysunek: operacje na obiektach (źródło: Tanenbaum, Distributed Systems)
| ©Janina Mincer-Daszkiewicz |