Większość materiału umieszczonego w danym rozdziale poświęcona jest NFS w wersji 4 (na razie znany jest sam protokół, bez jakiejkolwiek implementacji). Wersja 3.0 była omawiana na wykładzie.
Od początku swego istnienia, w latach 80., system NFS był ogromnym sukcesem. Sprawiły to zapewne przenośność i prostota przyjętych rozwiązań. Podstawowe cele, jakie postawili sobie projektanci firmy Sun to:
NFS v4 ma być rozwinięciem poprzednich wersji, będzie się jednak znacząco różnić w kilku podpunktach od swych poprzedników. Prace nad wersją 4.0 prowadzone są od 1998 roku przez IETF (ang. Internet Engineering Task Force), kiedy to Sun Microsystems zrzekł się pełnej kontroli nad opracowywaniem nowej wersji. Generalnie, można powiedzieć, że wersja 4.0 ma rozwiązać większość problemów i zastrzeżeń, jakie są do wersji 3.0, a więc:
Oczywiście protokół w wersji 4.0 pozostanie kompatybilny z poprzednimi
wersjami.
Jak widać podstawowy problem, to przystosowanie NFS do działania w Internecie.
Podstawowe cechy NFSv4 oraz różnice z NFSv3:
Wymienione tu pokrótce aspekty NFSv4 zostaną szerzej omówione w dalszych rozdziałach.
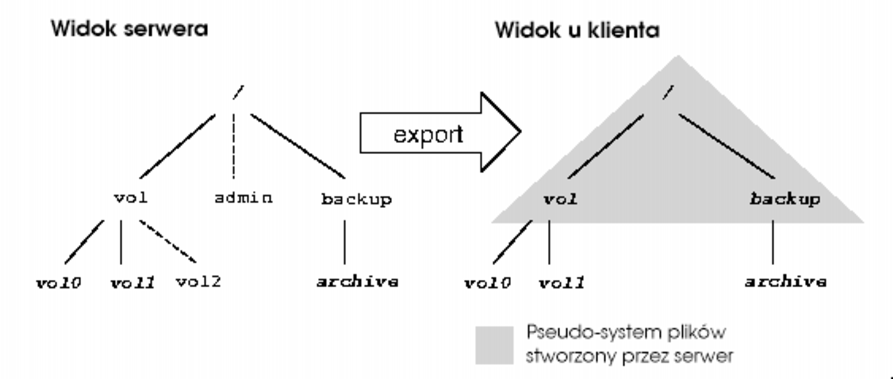
W NFSv4 jak w poprzednich wersjach serwer eksportuje różne systemy plików, jednak dla klienta jest to jeden spójny obraz, co bardzo ułatwia przechodzenie po drzewie systemu plików.
Wprowadzenie procedur COMPOUND jest znaczącą innowacją wprowadzoną w wersji 4.0.
Tego typu procedury pozwalają na grupowanie tradycyjnych operacji na plikach w jedno
żądanie, które zostanie wysłane do serwera po sieci. Tak więc protokół NFSv4 nie
implementuje już każdej akcji jako odrębnej procedury RPC, lecz działa na operacjach,
które składają się na część procedury COMPOUND. Została oczywiście zachowana
zgodność funkcjonalna z poprzednimi wersjami. Obsługa błędów po stronie serwera
również nie jest trudna: serwer wykonuje polecenia dopóki w wykonaniu któregoś
nie nastąpi błąd, jeśli tak to przerywa obsługę konkretnego żądania i zwraca błąd
klientowi.
Można powiedzieć, że de facto jedynymi procedurami RPC pozostały procedury NULL
oraz COMPOUND.
Nowymi operacjami wprowadzonymi dopiero w wersji 4.0 są stanowe operacje OPEN
i CLOSE. Jest to tym większa nowość, gdyż, jak wiadomo, serwer NFS był wcześniej
bezstanowy i była to jedna z jego głównych zalet (łatwość w usuwaniu awarii).
Dzięki wprowadzeniu owej stanowości osiągnięto atomowość operacji na plikach i zgodność
z Windows'ową semantyką. Ponadto możliwe jest wprowadzenie delegowania, a co za tym idzie
także ,,agresywnego'' cache'owania po stronie klienta (klient na czas delegacji dostaje
wyłączność na działania na danym pliku, dzięki czemu może on wykonywać wszystkie
operacje lokalnie, co jest szybsze i nie zajmuje czasu pracy serwera).
Aby zilustrować wygodę i zwiększenie szybkości dzięki użyciu funkcji COMPOUND i pozbyciu się protokołu Mount prześledźmy przykład.
mount bayonne:/export/vol0 /mnt dd if=/mnt/home/data bs=32k count=1 of=/dev/null
Chcemy zamontować zdalny system plików i przeczytać 32KB z pliku.
NFSv3
PORTMAP C GETPORT (MOUNT) PORTMAP R GETPORT MOUNT C Null MOUNT R Null MOUNT C Mount /export/vol0 MOUNT R Mount OK PORTMAP C GETPORT (NFS) PORTMAP R GETPORT port=2049 NULL NULL FSINFO FH=0222 FSINFO OK GETATTR FH=0222 GETATTR OK LOOKUP FH=0222 home LOOKUP OK FH=ED4B LOOKUP FH=ED4B data LOOKUP OK FH=0223 ACCESS FH=0223(read) ACCESS OK (read) READ FH=0223 at 0 for 32768 READ OK (32768 bytes)NFSv4
PUTROOTFH
LOOKUP "export/vol0"
GETFH
GETATTR
PUTROOTFH OK CURFH
LOOKUP OK CURFH
GETFH OK
GETATTR OK
PUTFH
OPEN "home/data"
READ at 0 for 32768
PUTFH OK CURFH
OPEN OK CURFH
READ OK (32768 bytes)
Jak wiadomo protokół NFS związuje z każdym plikiem i katalogiem uchwyt pliku (ang. file
handle). Zazwyczaj uchwyt pliku zawiera identyfikator systemu plików (ang. file system ID),
numer i-węzła oraz numer pokolenia (ang. generation number). Rozwiązanie to jest
niewystarczające w nie-UNIXowych systemach plików, gdzie identyfikacja odbywa się poprzez
ścieżkę. Dlatego też w NFSv4 wprowadzono drugi rodzaj uchwytu- zmienny (ang. volatile
handler).
W związku ze stanowością serwera i wbudowaniem blokad w protokół wprowadzono odpowiednie
struktury danych: identyfikator klienta (ang. client ID) oraz stanu (ang. state ID).
Dzięki temu możliwa jest identyfikacja klientów jak też powrót do normalnego działania
po awarii.
Atrybuty dla operacji zostały w NFSv4 określone dużo elastyczniej niż w poprzednich wersjach,
a mianowicie wprowadzono 3 rodzaje atrybutów:
Blokady zostały w wersji 4 wbudowane w protokół NFS. Powrót po awarii będzie dzięki temu
ułatwiony (w przeciwieństwie do używanego wcześniej NLM). Działanie blokad zasadza się na
okresach wyłączności kontrolowania stanu pliku (ang. leases). Serwer daje wyłączność
klientowi na pewien czas, podczas którego nie może udzielić jej innemu klientowi.
Jeśli klient chce ponowić blokadę musi się jeszcze raz zwrócić do serwera.
Klientom udostępniono również żądanie, podczas otwierania pliku, wyłączności na możliwość
jego otwierania (ang. share reservation).
Zwiększenie bezpieczeństwa jest jednym z podstawowych zadań, jakie stoją przed projektantami NFSv4, gdyż w obecnie stosowanym rozwiązaniu mechanizmy uwierzytelniające (AUTH_NULL, AUTH_UNIX, AUTH_KERB) nie sprawdzają się na poziomie sieci rozległych. Problem powinno rozwiązać użycie RPCSEC_GSS oparte na GSS-API (Generic Security Service), które pozwala na dodawanie nowych mechanizmów bezpieczeństwa bez konieczności tworzenia na nowo aplikacji NFS. Ponadto NFSv4 wymusza tworzenie aplikacji zgodnych z mechanizmem Kerberos wersja 5 oraz LIPKEY (The Low Infrastructure Public Key).
Użytkownicy i grupy są identyfikowani w NFSv4 jako: