System RFS został stworzony w AT&T. Początkowo działał on na systemie SVR3 UNIX, lecz szybko RFS przebudowano i zintegrowano z interfejsem węzłów wirtualnych (w wersji SVR4). Tutaj omówimy właśnie tę implementację RFS.
Podstawowe założenia to:
Właściwości architektury RFS:
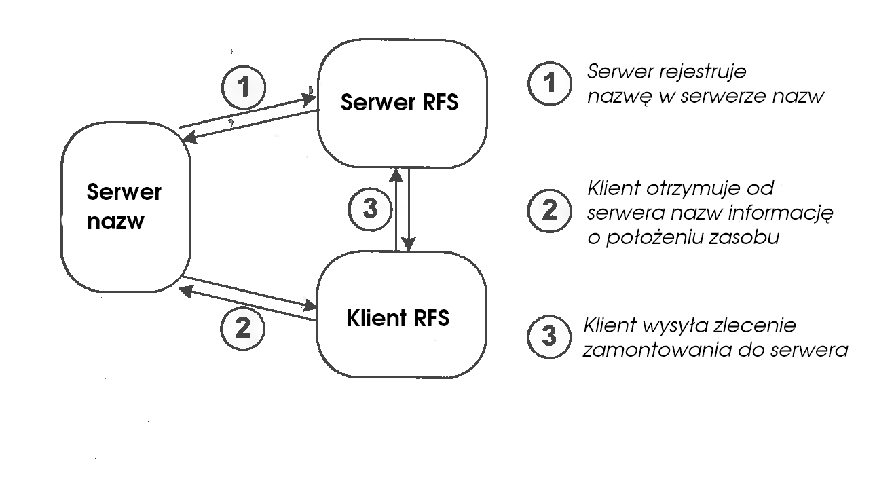
Operację montowania obsługuje się oddzielnie za pomocą montowania zdalnego. Używany jest wtedy serwer nazw.
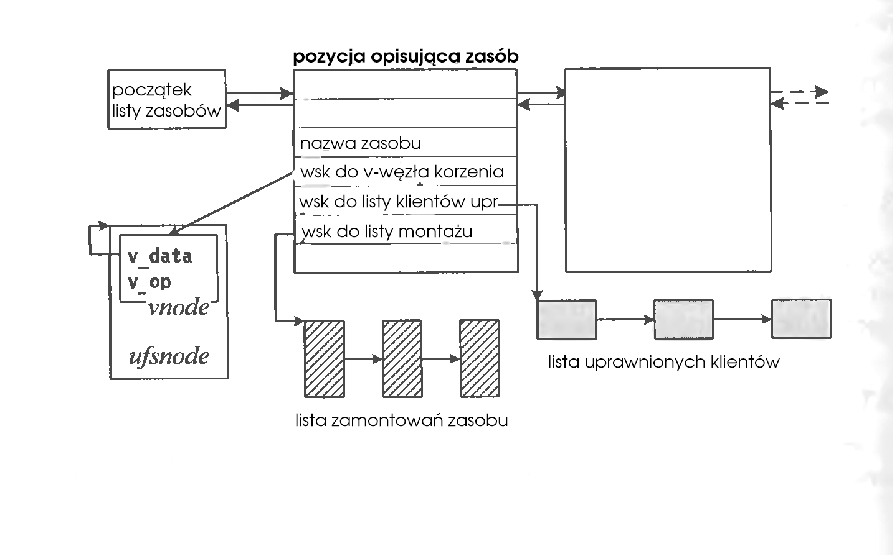
Aby klienci mogli zamontować katalog, serwer musi go najpierw wyeksportować, robi to przy użyciu funkcji advfs (w nowszych wersjach podfunkcji funkcji rfsys). Wywołanie tej funkcji stworzy w liście zasobów jądra odpowiednią pozycję dla zadanego katalogu.
Teraz klient może wywołać polecenie mount, w którym najpierw zostanie odpytany serwer nazw o położenie pliku w sieci, a potem zostanie wysłane do zadanego serwera żądanie zamontowania danego pliku bądź katalogu. Jeśli klient ma prawo do korzystania z danego zasobu serwer zwróci identyfikator zamontowania. Klient z kolei, kończy montowanie poprzez konfigurację v-węzła, gdzie zostaje zapamiętana struktura deskryptor przesyłu (ang. send descriptor). W deskryptorze przesyłu pamiętany jest uchwyt pliku i informacje o obwodzie wirtualnym.
Klient może odwoływać się do pliku RFS za pomocą nazwy ścieżkowej bądź deskryptora pliku. Ponieważ
protokół RFSv2 pozwala na montowanie innych systemów plików na katalogach RFS, to podczas analizy
ścieżkowej trzeba analizować każdą składową osobno. Gdy klient uzyska już uchwyt pliku, będzie
go zawsze przekazywać przy żądaniu operacji na pliku.
W serwerze utrzymywana jest dynamiczna pula procesów-demonów, które obsługują każde zlecenie osobno.
Gdy przybywa nowe zlecenie tworzony jest nowy proces, gdy nie ma dostępnych. Serwer działa jako
jeden lub kilka demonów, które wykonują się w trybie jądra. Demony są szeregowane tak jak inne
procesy.
Ponieważ system RFS wspiera całą semantykę UNIXową wprowadzono również możliwość przesłania sygnału. Jądro klienta po otrzymaniu sygnału wysyła do serwera zlecenie sygnału (ang. signal request). Serwer po jego otrzymaniu przekazuje sygnał do właściwego demona.
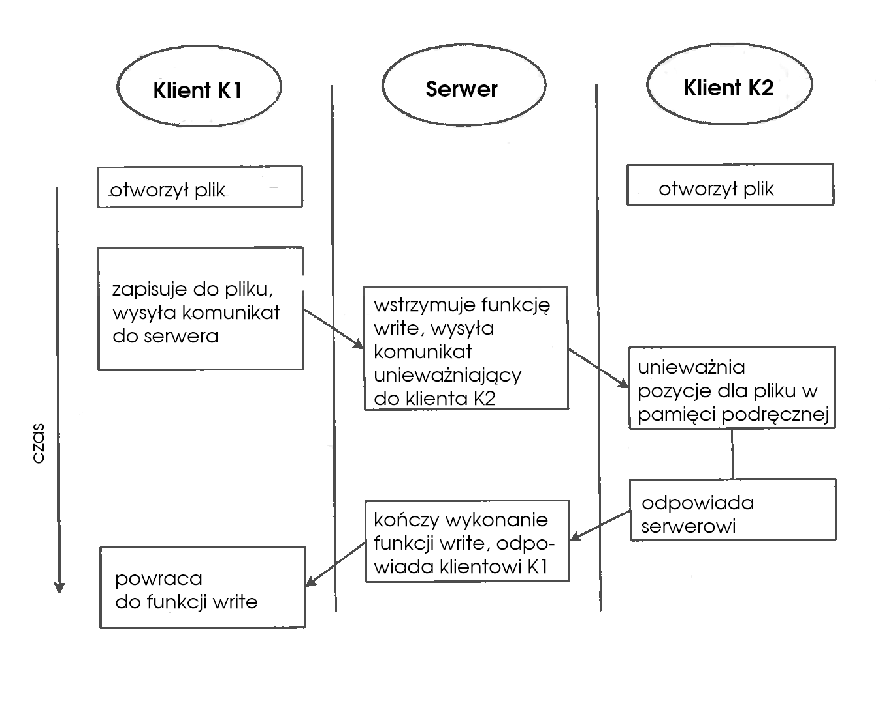
Ze względu na wydajność system RFS wspiera buforowanie danych po stronie klienta. Ponieważ jednak semantyka systemu RFS jest UNIXowa, należało zadbać, aby pamięć podręczna klientów była zawsze aktualna. Osiągnięto to dwojako:
O spójność danych pamięci podręcznej dba serwer (jeśli plik jest współdzielony przez wielu klientów) lub klient (jeśli mamy do czynienia ze współdzieleniem przez różne procesy tego samego klienta). Gdy jakiś klient wykona operację write, wtedy rozsyłany jest komunikat do wszystkich innych klientów mających ten plik otwarty, że buforowane dane są nieaktualne. Pozostali klienci czytają dane bezpośrednio z serwera, dopóki plik będzie modyfikowany. Natomiast klient mający plik zamknięty może używać buforowanych danych, gdy numer wersji pliku w buforze zgadza się z tym zwróconym przez serwer w wyniku operacji otwierania.