| 13. Kronika na przykładzie NTFS | ||
|---|---|---|
 | Chapter 13. Kroniki |  |
| 13. Kronika na przykładzie NTFS | ||
|---|---|---|
| | Chapter 13. Kroniki | |
W rozdziale tym postaram się dokładnie opisać sposób realizacji mechanizmu kronikowania w systemie plików NTFS (został on zaczerpnięty wraz z obrazkami z książki [Internals]).
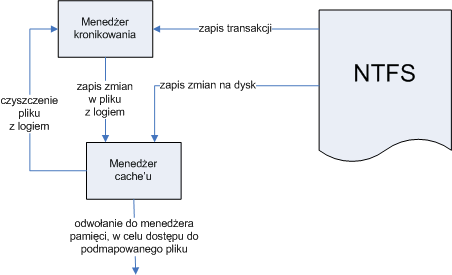
W przypadku NTFS, mamy do czynienia z sytuacją podobną jak w ext3, funkcje kroniki realizowane są przez odrębny moduł, powiązania między modułami wyglądają w sposób następujący:
Ja widać system plików odwołuje się do modułu odpowiadającego za kronikowanie, zapewniającego abstrakcję kroniki i udostępniającego systemowi plików proste operacje na transakcjach. Sam menedżer kronikowania korzysta z menedżera cache'u w celu dostępu do pliku, gdzie zachowuje właściwe dane związane z kroniką.
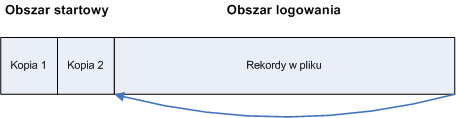
Plik z kroniką w systemie NTFS składa się z dwóch części:
obszar startowy - są przechowywane dwie kopie danych startowych na wypadek, gdyby jedna z nich stała się niedostępna lub nieczytelna. Zawierają one m.in. takie informacje jak początek obszaru w pliku, od którego powinny być przeglądane rekordy w trakcie odzyskiwania systemu
cykliczny zapis rekordów - zawiera on rekordy dotyczące transakcji wykonywanych przez system plików. Menedżer logu sprawia, że obszar ten wydaje się nieskończony poprzez cykliczny zapis w tym obszarze, używa też logicznych numerów sekwencyjnych (LSN) do identyfikacji numerów rekordów w pliku (NTFS używa 64 bitowych liczb do reprezentacji tych numerów)
System wykonuje operację jednocześnie gwarantując, że system plików może być zawsze odzyskany do stanu spójnego w następujący sposób:
NTFS prosi menedżera kronikowania, aby zapisał w logu (również cache'owanym przez menedżera cache'u) transakcje, które będą modyfikowały strukturę woluminu.
System plików modyfikuje właściwe dane (również w cache'u)
Menedżer cache'u wysyła żądanie do menedżera kronikowania, aby zapisał dane dotyczące transakcji na dysk.
Po zapisie na dysk danych związanych z transakcją menedżer cache'u utrwala zmiany w systemie plików na dysku.
Przy pierwszym dostępie do systemu plików sprawdzane jest, czy w dzienniku nie ma transakcji, które nie zostały utrwalone na dysku.
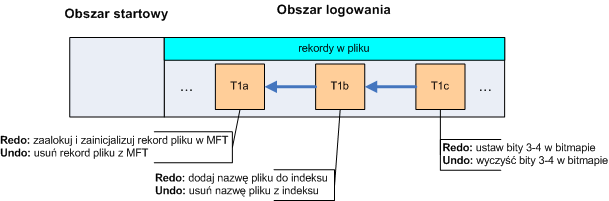
Menedżer kronikowania może zapisywać wszelkie typy rekordów w pliku. Jednak system plików NTFS stosuje dwa rodzaje rekordów:
rekordy uaktualnień - są najpopularniejszym typem rekordów zapisywanym w dzienniku. Każdy rekord składa się z dwóch rodzajów informacji:
dane ponawiania - informują jakie akcje muszą być podjęte, aby odtworzyć podoperację w pełni zapisanej w dzienniku transakcji (zatwierdzonej)
dane wycofywania - służą do wycofywania zmian wprowadzonych przez częściowo zapisaną transakcję (niezatwierdzoną)
Po zapisaniu tych rekordów do dziennika system plików przystępuje do utrwalania zmian w cache'u, a kiedy skończy modyfikować cache umieszcza w dzienniku kolejny rekord - zatwierdzając transakcję. Jeśli transakcja jest zatwierdzona, to NTFS gwarantuje, że operacja ta zostanie wykonana na systemie plików nawet jeśli nastąpi awaria.
Podczas odzyskiwania kroniki, system ponawia wszystkie zatwierdzone transakcje (chociaż zostały one zatwierdzone, nie wiadomo czy menedżer cache'u zdołał je odesłać na dysk - ma tu duże znaczenie, to co było wcześniej wspomniane, że informacje ponawiające powinny być tak zapisane, że ponowne wykonanie utrwalonej już operacji nie powinno niczego popsuć). Następnie system znajduje wszystkie niezatwierdzone transakcje i odwołuje zmiany podążając za wstecznymi wskaźnikami.
NTFS umieszcza w dzienniku informacje przy wykonywaniu następujących operacji: tworzeniu pliku, usuwaniu pliku, powiększaniu pliku, zmniejszaniu pliku, ustawianiu informacji o pliku, zmianie nazwy pliku, zmianie uprawnień pliku.
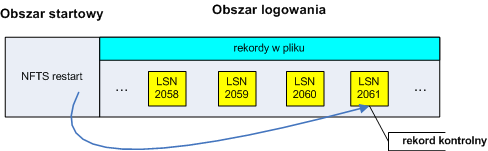
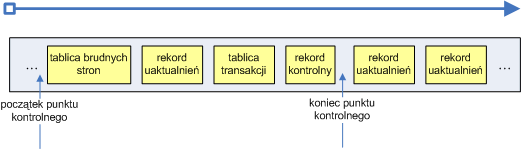
punkty kontrolne - jako dodatek do rekordów uaktualnień NFTS co jakiś czas zapisuje punkty kontrolne do pliku, jak ilustruje to poniższy rysunek:
Rekordy kontrolne pozwalają systemowi plików ustalić jakie akcje należy podjąć, aby przywrócić system do spójnego stanu. Dzięki nim wiadomo m. in. od których rekordów należy rozpocząć przetwarzanie. Po zapisie punktu kontrolnego system zapisuje w obszarze startowym jego numer sekwencyjny, tak aby mógł szybko ustalić najnowszy punkt kontrolny.
Pomimo, że dla systemu dziennik sprawia wrażenie nieskończonego, w rzeczywistości oczywiście taki nie jest. Dlatego menedżer cache'u przechowuje liczbę wolnego miejsca w logu, miejsce potrzebne do zapisania wszystkich nadchodzących rekordów i miejsce potrzebne do odwołania wszystkich aktywnych transakcji. Jeśli wolne miejsce nie jest w stanie pomieścić wszystkich zmian, to zwracany jest wyjątek przepełnienia dziennika. Wówczas blokowane są wszelkie operacje na transakcjach dopóki menedżer cache'u nie odeśle na dysk wszystkich niezapisanych danych, włącznie z danymi dotyczącymi dziennika. Po pozytywnym zakończeniu operacji dziennik jest resetowany i wszystko wraca do normy.
Jak to już zostało wcześniej wspomniane, system NFTS przystępuje do operacji odzyskiwania dziennika przy pierwszym dostępie do systemu plików. Proces ten zależy od dwóch tablic:
tablicy transakcji - przechowuje informacje o transakcjach, które zostały rozpoczęte, ale nie zostały zatwierdzone; wszystkie podoperacje tych aktywnych transakcji muszą zostać wycofane podczas przywracania spójności,
tablica brudnych stron - przechowuje informacje o tym, które strony w cache'u zawierają modyfikacje systemu plików, które nie zostały zapisane na dysk. Te dane muszą być utrwalone na dysku.
NTFS co 5 sekund zapisuje rekord z punktem kontrolnym do dziennika, tuż przed tym zachowywana w kronice jest także aktualna kopia wyżej wymienionych tablic, następnie w rekordzie kontrolnym zapisuje numery rekordów zawierających te tablice. Podczas procesu odzyskiwania danych odszukiwane są najświeższe kopie tych tablic i wczytywane są do pamięci.
Kronika zwykle zawiera jeszcze rekordy uaktualnień znajdujące się za ostatnim punktem kontrolnym. Reprezentują one zmiany, które zaszły później, więc system musi uwzględnić te zmiany w tablicach transakcji i brudnych stron. Po uaktualnieniu tablic zmiany są utrwalane na dysku twardym.
NTFS skanuje dziennik trzy razy, jednak przy pierwszym przebiegu zapisuje go sobie w pamięci, aby zminimalizować liczbę odczytów z dysku. Każdy z tych przebiegów ma określony cel:
faza analizy kroniki,
faza ponawiania operacji,
faza wycofywania operacji.
Analiza kroniki.
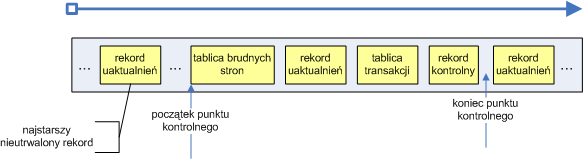
Podczas analizy kroniki jest ona przeglądana od początku ostatniego punktu kontrolnego, aby znaleźć rekordy uaktualnień i wykorzystać je do wprowadzenia zmian do tablicy transakcji i brudnych stron. Jak widać na obrazku punkt kontrolny tak naprawdę składa się z trzech rekordów, przez co rekordy uaktualnień mogą być z nimi przemieszane, dlatego system musi zacząć skanowanie od początku ostatniego punktu kontrolnego.
Większość rekordów uaktualnień zapisanych po punkcie kontrolnym reprezentuje modyfikacje albo tablicy transakcji albo tablicy brudnych stron. Jeśli rekord jest np. rekordem zatwierdzającym transakcję, wówczas odpowiedni rekord odpowiadający tej transakcji musi zostać usunięty z tablicy transakcji. Następnie system wyznacza numer najstarszej operacji, która nie została utrwalona na dysku. Tablica transakcji zawiera na koniec numery niezatwierdzonych operacji, natomiast tablica brudnych stron zawiera numery rekordów cache'u, które nie zostały utrwalone na dysku. Numer tej transakcji wyznacza moment, od którego rozpocznie się faza odtwarzania.
Ponawianie operacji.
Podczas fazy ponawiania dziennik jest również przeglądany do przodu rozpoczynając od numeru rekordu wyznaczonego w czasie analizy. System szuka rekordów z uaktualnieniami stron, które następnie są ponawiane.
Ja tylko system dojdzie do końca logu, w cache'u znajdują się uaktualnione informacje, które następnie menedżer cache'u leniwie zapisze na dysk.
Wycofywanie operacji.
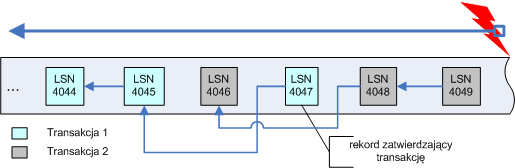
Po ukończeniu operacji ponawiania system przegląda dziennik od tyłu, wycofując wszelkie niezatwierdzone transakcje. Na rysunku widzimy dwie transakcje, z których pierwsza została zatwierdzona przed awarią systemu, natomiast druga nie. Zatem NTFS musi wycofać drugą transakcję.
Po ukończeniu fazy wycofywania operacji wolumin znajduje się w stanie spójnym. W tym miejscu następuje wymuszenie zapisu wszystkich danych na dysk i zapisywany jest pusty rekord w rekordzie startowym dziennika oznaczający, że system jest spójny. Na tym cały proces przywracania spójności się kończy.
| |  | |
| 12. Problemy związane z kroniką |  | 14. Inne sposoby na zabezpieczanie danych |