Subsections
4 Alternatywne architektury podsystemów komunikacji sieciowej
Celem tego rozdziału jest przekazanie najważniejszych informacji na temat
alternatywnych sposobów konstruowania podsystemów sieciowych.
Klasyczne podejście, którego przykładami są przedstawione implementacje
kodu sieciowego Linuksa i FreeBSD, często jest przyczyną niezadowalającej
wydajności kodu. Najbardziej znaną próbą poprawienia wydajności standardowego
kodu sieciowego jest implementacja Vana Jacobsona, zastępująca podsystem
sieciowy używany w systemie 4.3BSD. W niniejszym rozdziale zaprezentowano
wszystkie informacje na temat tej implementacji, jakie udało się znaleźć
w Internecie. Omówiono też pokrótce inne podejście, polegające na umieszczeniu
obok istniejącego podsystemu sieciowego dodatkowej szybkiej biblioteki komunikacyjnej,
nakładającej specjalne wymagania na aplikacje użytkowe.
Typowym sposobem implementacji oprogramowania sieciowego jest jego podział
na logicznie odrębne warstwy zgodnie z tym, co zostało opisane w rozdziale
2. W pracy [Jacobson 92b] można znaleźć
argumenty przeciwko takiej konstrukcji. Choć podział na warstwy stanowi
bardzo wygodną technikę projektowania protokołów, to
może mieć negatywny wpływ na wydajność napisanego zgodnie z tym
projektem oprogramowania.
Praktycznym potwierdzeniem tych spostrzeżeń jest implementacja stosu
protokołów TCP/IP, którą wykonał Van Jacobson ze współpracownikami dla
systemu 4.3BSD23 (zob. [Jacobson 92b],
[Jacobson 93a]).
Pomiary wykazały, że działa ona od jednego do dwóch rzędów wielkości szybciej,
niż stara implementacja24.
Przy tworzeniu nowej implementacji autorzy kierowali się następującymi
spostrzeżeniami.
- W kolejnych pakietach należących do jednego strumienia danych
nagłówki protokołów różnią się między sobą tylko w niewielkim stopniu.
- Przetwarzanie protokołów wymaga w typowym przypadku niewielu
instrukcji procesora.
- Jak wykazały pomiary, obsługa przerwań i kopiowanie danych z pamięci
do pamięci są zdecydowanie droższe czasowo od przetwarzania protokołów.
Implementacje o strukturze warstwowej zazwyczaj wykonują zbędne operacje
kopiowania i korzystają z nadmiarowych przerwań (sprzętowych lub
programowych).
- Dostęp do danej w pamięci trwa dłużej niż wykonanie na tej danej
operacji arytmetycznej.
- Osiągnięcie maksymalnej wydajności jest możliwe tylko przy
zrównolegleniu przetwarzania: w czasie, gdy pakiet
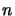 jest przesyłany
przez medium transmisyjne, odbiorca przetwarza otrzymany pakiet
jest przesyłany
przez medium transmisyjne, odbiorca przetwarza otrzymany pakiet 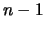 ,
natomiast nadawca przygotowuje do wysłania pakiet
,
natomiast nadawca przygotowuje do wysłania pakiet 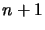 . Rezygnacja ze
struktury warstwowej skraca czas obsługi pakietu zarówno po stronie nadawczej,
jak i odbiorczej, ułatwiając tym samym osiągnięcie równoległości przetwarzania.
Brak równoległości jest najważniejszą przyczyną niezadowalającej
prędkości przesyłania danych w szybkich sieciach.
. Rezygnacja ze
struktury warstwowej skraca czas obsługi pakietu zarówno po stronie nadawczej,
jak i odbiorczej, ułatwiając tym samym osiągnięcie równoległości przetwarzania.
Brak równoległości jest najważniejszą przyczyną niezadowalającej
prędkości przesyłania danych w szybkich sieciach.
Implementacja zrealizowana na bazie tych spostrzeżeń odznacza się następującymi
cechami.
- Struktury danych oraz schematy przetwarzania zostały zaprojektowane
od podstaw. Nowy kod ma niewiele wspólnego z oryginalnym kodem Net/2.
- Przy nadejściu pakietu generowane jest co najwyżej jedno przerwanie.
Wysyłanie pakietów odbywa się bez użycia przerwań, jeśli pozwala na to karta
sieciowa.
- Każda porcja danych jest kopiowana tylko jeden raz na każdej z końcówek
komunikacyjnych.
- Żądania odczytu i zapisu generowane przez aplikacje są kierowane do
procedur specyficznych dla danego typu gniazda. Procedury te wykorzystują
wiedzę o postaci pakietów oraz o zasadach kontroli przepływu i niezawodności
przesyłania, stosowanych przez dany protokół lub zestaw protokołów
(np. TCP/IP).
- Bufory pakietów (typu struct pbuf) należą do urządzeń
sieciowych. To sterownik urządzenia jest odpowiedzialny za alokację bufora.
Sterownik gwarantuje, że bufor znajdzie się w ciągłym obszarze pamięci
najbardziej odpowiedniej dla danego urządzenia, wyrównanym do pożądanej
granicy, a na początku bufora pozostanie miejsce na nagłówki warstwy łącza
danych. Te same warunki nakłada się na przychodzące pakiety. Dzięki udziałowi
sterownika w procesie alokacji buforów pozbyto się dużej ilości kodu z
procedur wyjściowych sterowników. Struktura pbuf składa się z
następujących pól:
- p_data -- wskaźnik do początku bufora danych,
- p_len -- długość bufora danych,
- p_next -- wskaźnik do następnego bufora w kolejce,
- p_free -- wskaźnik do funkcji zwalniającej pamięć bufora,
- p_ifp -- wskaźnik do struktury urządzenia,
- p_packet -- wskaźnik do początku treści pakietu w buforze,
- p_pktlen -- długość pakietu,
- p_flags -- znaczniki określające rodzaj pakietu.
- Za każdym razem jest tworzony i wysyłany tylko jeden pakiet. Pomaga to
zwiększyć równoległość przetwarzania.
- Struktury danych, które mogą być przydatne później (w szczególności
nagłówki protokołów), są przechowywane w pamięci podręcznej. Dzięki temu
tworzenie nagłówka pakietu jest w większości wykonywane poprzez skopiowanie
zapamiętanych danych. Również nagłówki warstwy łącza danych są zapamiętywane
w pamięci podręcznej, która zastępuje tablicę trasowania (np. tablicę ARP).
- Po nadejściu pakietu, w procedurze obsługi przerwania wykonywane są
wszystkie procedury wejściowe, które składają się na koncepcyjny stos
protokołów. Jeśli pakiet jest przeznaczony dla lokalnej maszyny, to jest on
wstawiany do kolejki związanej z gniazdem docelowym25. W klasycznych
implementacjach niższe warstwy przekazują pakiety warstwom wyższym, wstawiając
je do kolejek ogólnosystemowych i wywołując przerwania programowe lub podobny
mechanizm, aby zaznaczyć konieczność dalszego przetwarzania pakietów w
późniejszym czasie. Dzięki uproszczeniu przetwarzania pakietu można
sprawdzać w procedurze obsługi przerwania, czy urządzenie odebrało już
kolejny pakiet. W efekcie wiele pakietów może zostać odebranych przy użyciu
tylko jednego przerwania.
- Nowe oprogramowanie korzysta z techniki tzw. szybkich ścieżek,
która polega na tym, że prosty przypadek szczególny, który pojawia się bardzo
często, jest oprogramowany niezależnie od skomplikowanego przypadku ogólnego.
Przykład szybkiej ścieżki dla protokołu TCP można znaleźć w liście
[Jacobson 93b].
- Zastosowano również technikę przewidywania nagłówka (ang. header prediction), która pozwala szybko stwierdzić, czy użycie szybkiej
ścieżki jest możliwe (tj. czy mamy do czynienia z pożądanym przypadkiem
szczególnym).
- Sumy kontrolne są weryfikowane podczas kopiowania danych do przestrzeni
użytkownika.
Pomiary, wykonane z użyciem zewnętrznego analizatora logicznego na
maszynie typu Sparcstation-2 z procesorem typu RISC,
wykazały, co następuje.
- Całkowity koszt przekazania pakietu IP do innej maszyny (ang. forward) wynosi 37 instrukcji i 7 odwołań do pamięci.
- Całkowity koszt przetwarzania protokołu TCP dla jednego pakietu
wynosi mniej niż 60 instrukcji i 22 odwołania do pamięci. W liście
[Jacobson 93b] można znaleźć przykład szybkiej ścieżki odbiorczej TCP,
wykonywanej przez 30 instrukcji procesora RISC.
- Jeśli urządzenia sieciowe są właściwie zaprojektowane, a medium
transmisyjne pozwala przesyłać pakiety o rozmiarze co najmniej 1KB, połączenia
TCP/IP przesyłają dane od aplikacji do aplikacji z prędkością pamięci głównej
użytej w komunikujących się komputerach.
- W tablicy 4.1 pokazano (za [Jacobson 92b])
na co zużywany jest czas podczas
przetwarzania odebranego pakietu. Pomiary wykonano na maszynie Sparcstation-2
40MHz dla pakietów FDDI o
rozmiarze 4KB każdy, wysyłanych co 330
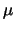 s, przy czasie wykonywania
pojedynczej instrukcji wynoszącym 25ns. Praca [Jacobson 92b]
nie zawiera wyników pomiarów wykonanych z oryginalną implementacją, ale
wyniki umieszczone w tablicy 4.1 pozwalają ocenić nową implementację
jako wydajną: przetwarzanie protokołów trwa ponad 100 razy krócej
niż czynności administracyjne (kopiowanie danych, obsługa przerwań).
s, przy czasie wykonywania
pojedynczej instrukcji wynoszącym 25ns. Praca [Jacobson 92b]
nie zawiera wyników pomiarów wykonanych z oryginalną implementacją, ale
wyniki umieszczone w tablicy 4.1 pozwalają ocenić nową implementację
jako wydajną: przetwarzanie protokołów trwa ponad 100 razy krócej
niż czynności administracyjne (kopiowanie danych, obsługa przerwań).
- W tablicy 4.2 umieszczono (za [Jacobson 92b])
informacje na temat czasu zwykłego kopiowania danych oraz tej samej operacji
połączonej z liczeniem sumy kontrolnej danych.
Wartości w nawiasach odnoszą się do przypadku, gdy kopiowane dane znajdują się
w pamięci podręcznej procesora,
a więc dostęp do nich jest szybszy niż do danych w pamięci głównej. Wszystkie
czasy podano w ns/bajt. Pomiary wykonano dla różnych maszyn.
Warto zwrócić uwagę, że na niektórych komputerach
liczenie sumy kontrolnej podczas kopiowania danych nie wydłuża czasu
kopiowania, co stanowi argument za wykonywaniem obu tych operacji równocześnie.
Niestety praca [Jacobson 92b] nie podaje informacji na temat czasu
liczenia sumy kontrolnej nie połączonego z kopiowaniem danych.
Tabela 4.2:
Koszt liczenia sumy kontrolnej -- czasy podano w ns/bajt ([Jacobson 92b])
|
|
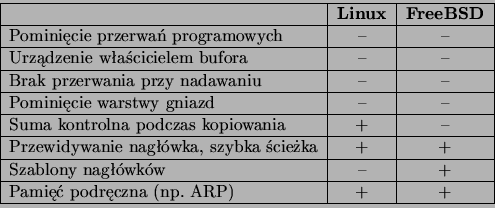
Na podstawie analizy dokonanej w rozdziale 3 ustalono,
które z wymienionych powyżej optymalizacji weszły w skład kodu sieciowego
Linuksa i FreeBSD. W tabeli 4.3 zestawiono te obserwacje.
Jak widać w obu implementacjach nie stosuje się optymalizacji, które wymagałyby
zmian w architekturze podsystemu sieciowego. Architektura FreeBSD stwarza
nieco większe problemy niż architektura Linuksa, gdyż nie da się weryfikować
sum kontrolnych TCP podczas kopiowania danych do przestrzeni użytkownika
w funkcji ogólnego przeznaczenia soreceive(). Z drugiej strony
w implementacji Linuksa nie używa się szablonów nagłówków, choć nie ma
ku temu znaczących przeszkód wynikłych z podziału na warstwy. Jedynym
odstępstwem od struktury warstwowej byłoby w tym przypadku umieszczenie
danych protokołu transportowego (szablon nagłówka TCP) i sieciowego (szablon
nagłówka IP) we wspólnej strukturze danych. Takie odstępstwo nie stanowiłoby
jednak wyłomu w dotychczasowych praktykach tworzenia kodu sieciowego Linuksa.
Tabela 4.3:
Optymalizacje w systemach Linux i FreeBSD
|
|
Podejmowane współcześnie próby przyspieszenia komunikacji sieciowej
nierzadko polegają na tworzeniu specjalnych bibliotek komunikacyjnych
projektowanych tak, aby zapewnić maksymalnie wydajne działanie.
Wygoda korzystania z takich bibliotek zazwyczaj schodzi na drugi plan.
Takie podejście jest szczególnie często stosowane przy budowie systemów
klastrowych.
W pracy [Lichota 02] wymieniono trzy najważniejsze czynniki sprzyjające
wysokiej wydajności komunikacji:
- określenie takiej semantyki biblioteki, która będzie ukierunkowana
na maksymalizację wydajności. To aplikacje powinny zostać przystosowane
do wymagań biblioteki (np. przez zastąpienie synchronicznego modelu komunikacji
z biblioteką modelem asynchronicznym), a nie na odwrót,
- uniknięcie pośredniego kopiowania danych. Kopiowanie powinno być
przeprowadzane tylko z buforów aplikacji do karty sieciowej i w odwrotnym
kierunku,
- umieszczenie aplikacji jak najbliżej sprzętu.
Drugi z tych postulatów może wymagać przystosowania kart sieciowych tak,
aby były one w stanie operować na adresach z wirtualnej przestrzeni
adresowej aplikacji użytkownika. Takie założenie przyjęto w specyfikacji
VIA (ang. Virtual Interface Architecture -- Architektura Wirtualnego
Interfejsu), opracowanej w 1997 roku przez firmy Compaq, Intel i Microsoft.
VIA jest obecnie najszerzej stosowanym standardem szybkiej komunikacji
w systemach klastrowych. Specyfikacja określa sposoby komunikacji aplikacji
użytkownika z kartą sieciową, które nie wymagają przechodzenia w tryb
jądra podczas wysyłania i odbierania danych.
Dodatkowo ustalono, w jaki interfejs
powinna być wyposażona typowa implementacja VIA, dostarczająca bibliotekę
komunikacyjną. Interfejs taki musi być zgodny ze standardem VIPL
(ang. Virtual Interface Provider Library, Biblioteka Dostarczająca
Wirtualny Interfejs). Przykładem implementacji VIA o otwartych źródłach
zgodnej ze specyfikacją VIPL jest M-VIA
(http://www.nersc.gov/research/FTG/via). Jest to rozwiązanie przeznaczone
dla systemu Linux z jądrem z serii 2.2 lub 2.4. Niskopoziomowy kod M-VIA
działa na poziomie jądra niezależnie od standardowego podsystemu sieciowego.
Aplikacje korzystające z dostarczonej biblioteki VIPL przechodzą w tryb jądra
tylko w celu wykonania operacji administracyjnych. Podczas przesyłania danych
biblioteka VIPL komunikuje się bezpośrednio z kartą sieciową.
Ponieważ korzystanie z biblioteki VIPL bywa niewygodne, stworzono wiele
bibliotek komunikacyjnych wyższego poziomu. Przykładem może być
przedstawiona w pracy [Lichota 02] biblioteka ZCCL (ang. Zero-Copy
Communication Library, Biblioteka Komunikacyjna Bez Kopiowania).
Jest to asynchroniczna biblioteka komunikacyjna bez pośredniego kopiowania,
przeznaczona do współpracy z biblioteką niższego poziomu, np. VIPL.
Jej zastosowaniem są systemy zdalnego dostępu do danych, w których
komunikacja jest oparta na modelu żądanie-odpowiedź, np. zdalne
systemy plików. Pozwala przedstawić działanie aplikacji jako automatu
skończonego o jasno określonych przejściach między stanami. Aplikacje
korzystające z tej biblioteki mogą działać zarówno na poziomie użytkownika,
jak i na poziomie jądra, używając w obu przypadkach tego samego interfejsu.
Więcej informacji na temat wydajnych bibliotek komunikacyjnych można
znaleźć w pracach [Lichota 02], [] i [Kilian 00].
Footnotes
- ... 4.3BSD23
- Z przyczyn prawnych nie weszła ona w skład
dystrybucji 4.4BSD ani żadnej innej.
- ... implementacja24
- Wielkość osiągniętego przyspieszenia zależy
przede wszystkim od stosunku mocy przetwarzania komputera do przepustowości
medium transmisyjnego.
- ... docelowym25
- W niektórych
przypadkach, np. pakietów z żądaniami NFS, można od razu wysłać odpowiedź
i zwolnić odebrany pakiet.