Next: 6 Podsumowanie Up: Mechanizmy komunikacji sieciowej w Previous: 4 Alternatywne architektury podsystemów Spis treści
Niniejszy rozdział stanowi próbę odpowiedzi na pytanie, w jaki sposób różnice w implementacji kodu protokołów sieciowych odbijają się na efektywności kodu. Przeprowadzono szereg badań przepustowości połączenia TCP przy użyciu różnych narzędzi pomiarowych i różnej wielkości transmitowanych bloków danych. Systemy operacyjne, których kod sieciowy opisano w rozdziale 3, przedstawiono na tle trzech innych podobnych systemów. Podjęto próbę analizy, w jakim stopniu kod sieciowy badanych systemów jest przygotowany do działania z mediami transmisyjnymi o wysokiej przepustowości.
Badania przeprowadzono z użyciem dwóch identycznych komputerów klasy Pentium taktowanych zegarem 120MHz i wyposażonych w 32MB pamięci RAM każdy. Komputery zostały połączone prywatnym pełnodupleksowym łączem typu Ethernet o przepustowości 100Mb/s26. Maksymalna jednostka przesyłu (MTU) dla sieci Ethernet wynosi 1500 bajtów, co oznacza, że pojedynczy segment TCP może nieść maksymalnie 1460 bajtów danych (zob. [Stevens 95]). Jako interfejsy sieciowe wykorzystano karty SMC 83C694CLJ na układach typu Digital 21140-AB, należących od rodziny układów Tulip. Podczas pomiarów w komputerach nie były aktywne żadne inne interfejsy sieciowe, z wyjątkiem pseudointerfejsu pętli zwrotnej (ang. loopback).
W tym punkcie wyszczególniono systemy operacyjne, które zostały objęte pomiarami.
Podczas wykonywania pomiarów w każdym z systemów działał tylko proces pomiarowy i procesy jądra. Zrezygnowano z używania pamięci wymiany (ang. swap) za wyjątkiem systemu OpenBSD, który nie zezwalał na taki tryb pracy28.
W eksperymentach mierzono szybkość przesyłania danych między dwoma procesami działającymi na dwóch różnych komputerach. Jako protokół sieciowy wybrano TCP/IP w wersji 4. Ograniczono się do transmisji jednokierunkowej, gdyż zdecydowana większość aplikacji korzystających z TCP/IP przesyła dane w wybranym momencie czasu tylko w jednym kierunku. Proces wysyłający dane wywoływał pewną liczbę razy funkcję write(), a proces odbierający -- funkcję read(). Domyślnym sposobem działania badanych implementacji TCP/IP jest sklejanie małych bloków danych dostarczanych przez kolejne wywołania funkcji write(). Można to zmienić, ustawiając flagę gniazda TCP_NODELAY (zob. [Stevens 95]). Dwa spośród czterech użytych programów pomiarowych pozwalały na ustawianie tej flagi i wykonanie pomiarów także dla przypadku, gdy bloki danych o rozmiarach nie przekraczających MTU wysyła się w osobnych pakietach IP.
Pomiary wykonano dla następujących rozmiarów pojedynczego bloku danych i liczby przesyłanych bloków:
Specjalny pomiar dla medium transmisyjnego o przepustowości 10Mb/s wykonano przy dziesięciokrotnie mniejszej liczbie przesłań bloków danych niż podano wcześniej.
Rezultatem pomiarów jest szybkość transmisji mierzona w MB/s. Każdy pomiar dla określonych warunków został wykonany pięciokrotnie. Jedno z czterech użytych narzędzi pomiarowych podaje tylko średnią arytmetyczną zmierzonych wartości, dlatego w dalszej analizie porównawczej zostaną uwzględnione tylko wartości średnie. Odchylenie standardowe zmierzonych wartości będzie poddane dyskusji w punkcie 5.6.1. Pełen zestaw uzyskanych rezultatów jest dostępny na płycie CD dołączonej do niniejszej pracy.
Zestaw programów lmbench jest najbardziej znanym pakietem służącym do pomiaru wydajności systemów operacyjnych w różnych aspektach ich działania. Kod źródłowy programów jest dostępny pod adresem http://ftp.bitmover.com/lmbench/. Wersja 2alpha13, oznaczana tutaj kryptonimem lmbench2, jest uznawana za standard przemysłowy i nie jest już rozwijana. Program bw_tcp2 mierzy przepustowość łącza TCP, przesyłając zadaną liczbę bajtów danych w porcjach po 64KB. Początek porcji danych u nadawcy i odbiorcy jest wyrównywany do granicy strony. Przed dokonaniem pomiaru przez pewien czas (co najmniej 5 sekund) przesyła się dane osobnym połączeniem TCP, aby ustabilizować niektóre parametry sterujące działaniem kodu sieciowego, takie jak zapamiętane rozmiary okien TCP. Nadawcą danych jest strona przyjmująca połączenie (serwer), a odbiorcą -- strona nawiązująca połączenie (klient). Odbiorca nie potwierdza w żaden sposób faktu otrzymania danych. Pomiar prowadzi się po stronie odbiorcy. Program nie pozwala ustawić flagi TCP_NODELAY.
Wersja 3 pakietu lmbench stanowi rozszerzenie wersji 2 i podlega ciągłemu rozwojowi. Podczas pisania niniejszej pracy dostępna była wersja o numerze 3alpha1. Program bw_tcp3 w porównaniu ze swoim poprzednikiem został wzbogacony m. in. o możliwość wyboru wielkości pojedynczego bloku danych. Przed dokonaniem pomiaru połączenie TCP jest rozgrzewane, tzn. przez pewien czas (co najmniej 5 sekund) przesyła się dane przez to połączenie. Pomiar powtarza się zadaną liczbę razy (tutaj: 5) z użyciem jednego połączenia, a wynikiem jest średnia arytmetyczna zmierzonych wartości. Nadawcą danych jest serwer, a odbiorcą klient. Odbiorca nie potwierdza faktu otrzymania danych. Pomiar prowadzi się po stronie odbiorcy. Program nie pozwala ustawić flagi TCP_NODELAY.
Program ttcp jest standardowym narzędziem do pomiaru szybkości połączenia TCP, opracowanym dla systemów BSD (działa także w Linuksie). Źródła programu są dostępne w wielu miejscach w Internecie, gdyż stanowi on własność publiczną (ang. public domain). W pracy użyto wersji 1.12; można ją znaleźć na dołączonej płycie CD. Program pozwala ustalić rozmiar pojedynczego bloku danych, liczbę przesyłanych bloków, stan flagi TCP_NODELAY. Nie ma możliwości rozgrzania połączenia. Nadawcą danych jest klient, a odbiorcą serwer. Odbiorca nie potwierdza faktu otrzymania danych. Każda ze stron komunikacji dokonuje pomiaru szybkości. Do analizy użyto wyników pomiarów dokonanych po stronie nadawcy. Wyniki te były najczęściej identyczne z wynikami uzyskanymi po stronie odbiorcy, choć w niektórych przypadkach przepustowość zmierzona po stronie nadawcy była o kilka procent większa. Wszystkie wyniki są dostępne na płycie CD dołączonej do pracy. Dodatkowo program ttcp podaje oszacowanie czasu spędzonego przez procesor w trybie jądra podczas transmisji danych.
Na potrzeby pracy napisano program składający się z 2 części: client i server. Nadawcą danych jest klient, a odbiorcą serwer. Pomiar obejmuje nie tylko czas wysyłania danych przez nadawcę, ale też czas odesłania jednobajtowego potwierdzenia przez odbiorcę. Obliczona w ten sposób przepustowość połączenia jest nieco zaniżona, ale uzyskuje się pewność, że dane rzeczywiście zostały przesłane od jednego procesu do drugiego. Program pozwala regulować wielkość bloku danych i liczbę przesłań oraz ustawiać flagę TCP_NODELAY. Początek bloku danych jest wyrównywany do granicy strony.
Na potrzeby pracy wykonano następujące pomiary:
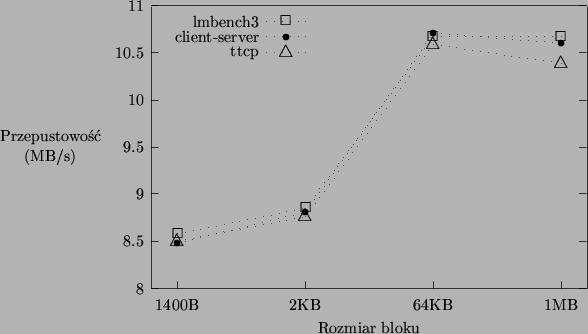
Na rysunku 5.1 pokazano różnice w wynikach pomiarów uzyskiwanych przy użyciu różnych narzędzi pomiarowych na przykładzie wyników uzyskanych dla systemu Linux 2.2.16 przy wyzerowanej fladze TCP_NODELAY. Dla większej czytelności wykresu usunięto wyniki uzyskane przy wielkości bloku 1 bajt (wahają się w granicach 0.09-0.12MB/s). Wartość zmierzona przez program lmbench2 wyniosła 10.63MB/s. Uzyskane wyniki są zbliżone, a największą wartość podaje zazwyczaj program lmbench3. Co ciekawe, najwyższą średnią przepustowość spośród wszystkich przeprowadzonych testów (10.83MB/s) uzyskano podczas pomiaru w Linuksie 2.2.16 dla bloku danych 64KB przy ustawionej fladze TCP_NODELAY za pomocą własnego programu pomiarowego, a więc narzędzia, które wprowadza dodatkowy narzut czasowy w postaci potwierdzenia zwrotnego.
Dla wszystkich programów pomiarowych z wyjątkiem lmbench3 obliczono odchylenia standardowe zmierzonych wartości. Poczyniono następujące obserwacje.
Jeśli nie zostanie powiedziane inaczej, w dalszych rozważaniach będą brane pod uwagę tylko wartości zmierzone przez program lmbench3 przy wyzerowanej fladze TCP_NODELAY.
 |
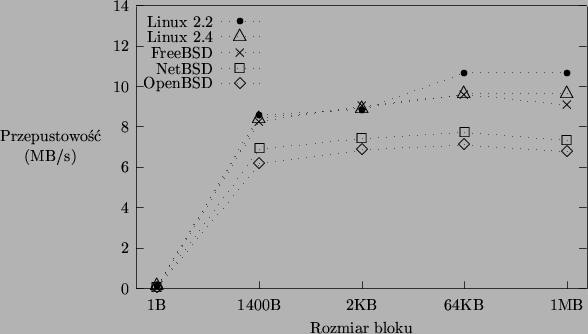
Na rysunku 5.2 ukazano różnice w zmierzonej przepustowości połączenia TCP dla wszystkich badanych systemów operacyjnych. Obie wersje Linuksa oraz FreeBSD prezentują zbliżoną wydajność, choć przy dużych rozmiarach bloków Linux 2.2 uzyskuje widoczną przewagę. Systemy NetBSD i OpenBSD są wyraźnie wolniejsze od pozostałych. We wszystkich systemach maksymalną przepustowość uzyskuje się przy bloku o rozmiarze 64KB. Niewielki spadek wydajności przy większych blokach danych jest przypuszczalnie spowodowany tym, że współczesne procesory, wyposażone w pamięć podręczną, najszybciej operują na niezbyt dużych zestawach danych. Szesnastokrotne skopiowanie do przestrzeni jądra bloku 64KB może trwać krócej niż jednokrotne skopiowanie bloku 1MB.
Warto zauważyć, że FreeBSD oraz obie wersje Linuksa były w stanie nasycić łącze komunikacyjne w ponad 80 procentach (dla łącza Ethernet 100Mb/s pełne nasycenie uzyskuje się przy przepustowości ok. 11.5MB/s).
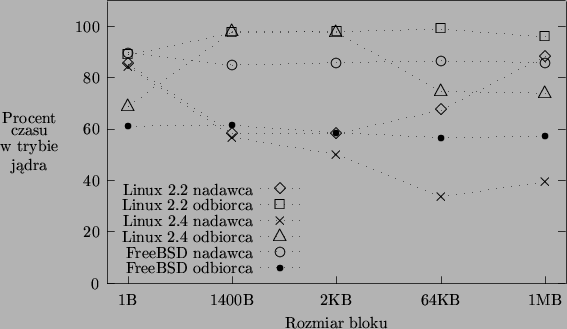
Na rysunku 5.3 pokazano, jaki procent czasu zużytego na
przesyłanie danych spędził procesor w trybie jądra, dla systemów Linux 2.2,
Linux 2.4
i FreeBSD. Wartości uśrednione z pięciu pomiarów wyliczono na podstawie
wyników przekazanych przez program ttcp przy użyciu podanego wzoru.
Parametry ![]() i
i ![]() oznaczają czas procesora spędzony odpowiednio
w trybie jądra i użytkownika,
oznaczają czas procesora spędzony odpowiednio
w trybie jądra i użytkownika, ![]() to stosunek czasu niejałowej pracy
procesora do czasu całkowitego. Należy zachować pewną rezerwę względem
przedstawionych danych, gdyż wartości
to stosunek czasu niejałowej pracy
procesora do czasu całkowitego. Należy zachować pewną rezerwę względem
przedstawionych danych, gdyż wartości ![]() ,
, ![]() i
i ![]() mogły
zostać zaledwie oszacowane przez jądro, a nie zmierzone. Warto
zwrócić uwagę, że wartości oszacowane dla FreeBSD tylko w niewielkim
stopniu zależą od rozmiaru bloku. Kod sieciowy Linuksa zachowuje się
dużo mniej przewidywalnie. Warto również zauważyć, że w kodzie Linuksa
ścieżka odbiorcza jest bardziej czasochłonna od nadawczej, podczas gdy
w kodzie FreeBSD jest na odwrót.
mogły
zostać zaledwie oszacowane przez jądro, a nie zmierzone. Warto
zwrócić uwagę, że wartości oszacowane dla FreeBSD tylko w niewielkim
stopniu zależą od rozmiaru bloku. Kod sieciowy Linuksa zachowuje się
dużo mniej przewidywalnie. Warto również zauważyć, że w kodzie Linuksa
ścieżka odbiorcza jest bardziej czasochłonna od nadawczej, podczas gdy
w kodzie FreeBSD jest na odwrót.
Zmierzenie przepustowości przy bloku danych o rozmiarze 1 bajta pozwala ocenić wydajność kodu przetwarzania protokołów łącznie z kodem interfejsu wywołań systemowych. Czas kopiowania danych jest zaniedbywalny. Wartości zmierzone przy użyciu programów client i server przy wyzerowanej fladze TCP_NODELAY przedstawiają się następująco:
Jak widać, w większości przypadków systemy Linux wykazały się w tym teście lepszą wydajnością niż systemy BSD.
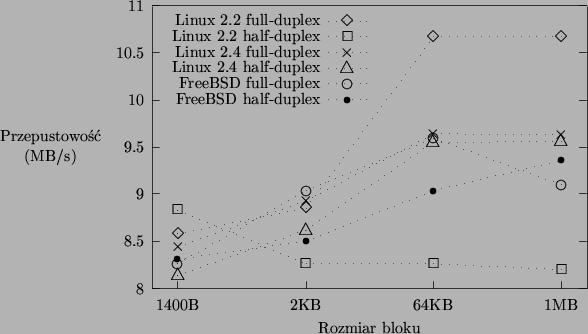
W trybie półdupleksowym (ang. half-duplex) karta sieciowa nie potrafi równocześnie wysyłać jednego pakietu i odbierać drugiego. W rezultacie zmniejsza się stopień zrównoleglenia operacji potrzebnych do przesłania danych. Wysoki stopień zrównoleglenia jest jednym z warunków osiągnięcia dużej efektywności transmisji sieciowej (zob. rozdział 4). Na rysunku 5.4 zilustrowano wpływ ustawienia trybu półdupleksowego na osiąganą przepustowość. Pominięto wyniki uzyskane dla bloku jednobajtowego. Przepustowość w systemie Linux 2.4 spadła zgodnie z przewidywaniami. Zaskoczeniem jest znaczny spadek przepustowości w Linuksie 2.2 i nieoczekiwany jej wzrost we FreeBSD przy bloku 1MB. Można wnioskować, że rozmaite zależności czasowe między zdarzeniami synchronicznymi i asynchronicznymi (np. moment wygenerowania przerwania przez kartę sieciową) mają istotny wpływ na wydajność kodu sieciowego.
Po przestawieniu kart sieciowych w tryb 10Mb/s można sprawdzić, czy we wcześniejszych testach osiągnięto stan pełnego nasycenia sieci pakietami. Jeśli tak było, to przepustowość zmierzona w teście 10Mb/s powinna być dziesięciokrotnie niższa niż poprzednio. Jeśli nie, przepustowość zmniejszy się, ale mniej niż dziesięciokrotnie. Niestety, wyniki uzyskiwane dla systemu FreeBSD w tym trybie nie były stabilne, a połączenie zrywało się. Mimo to wartość zmierzoną dla bloku 64KB można uznać za wiarygodną, gdyż narzędzia lmbench2 i lmbench3 dały powtarzalne wyniki. Przepustowość spadła z 9.59MB/s do 1.18MB/s, a więc mniej niż dziesięciokrotnie. Biorąc pod uwagę długość maksymalnej ramki Ethernetu (1518 bajtów) i liczbę bajtów zarezerwowanych w ramce na nagłówki warstwy łącza danych oraz protokołów IP i TCP (min. 58 bajtów) można uznać, że w tym teście osiągnięto pełne nasycenie sieci. Zaskakująco zachowała się implementacja Linuksa 2.2: przepustowość dla bloku 64KB spadła z 10.67MB/s do 0.87MB/s, czyli więcej niż dziesięciokrotnie. Prawdopodobnie częściowo odpowiadają za to złożone zależności czasowe, o których wspomniano wcześniej. Być może wadliwie działają w tym przypadku procedury sterowania przepływem protokołu TCP. Innym możliwym wytłumaczeniem jest zwiększenie kosztu obsługi kolejek nadawczych i odbiorczych, które ulegają wydłużeniu. Można przypuszczać, że w tym teście uwidoczniła się przewaga rozwiązania stosowanego w kodzie FreeBSD, polegającego na obsłudze kolejek nadawczych bez generowania przerwania programowego. Nadal jednak poziom nasycenia łącza komunikacyjnego przez implementację Linuksa przekraczał 75%.
Ostatni z pomiarów przeprowadzono na zmodyfikowanym jądrze Linuksa 2.2.16. Modyfikacja miała na celu skrócenie czasu, jaki upływa między wywołaniem systemowym read() lub write() a przekazaniem sterowania do kodu protokołu TCP. W tym celu zdefiniowano dodatkową stałą ustawianą w polu f_mode tych struktur file, które są związane z gniazdami TCP/IPv4. Dodatkowo zdefiniowano funkcje fast_tcp_read() i fast_tcp_write(), stworzone na bazie tcp_do_sendmsg() i tcp_recvmsg(). W funkcjach tych usunięto fragmenty kodu, które nie miały zastosowania przy przesyłaniu danych za pomocą read() i write(). Pełna treść łaty fastcall zawierającej modyfikacje jest dostępna na płycie CD dołączonej do pracy.
Narzut czasowy w funkcjach read() i write(), będący efektem sprawdzania dodatkowych warunków, zmierzono przy użyciu programów bw_pipe z pakietu lmbench3 oraz własnych narzędzi ipxserver i ipxclient, których kod można znaleźć na płycie CD dołączonej do pracy. Na płycie zamieszczono też pełne wyniki tych pomiarów. Czas przesyłania danych przez łącze nienazwane nie uległ znaczącym zmianom nawet dla bloku jednobajtowego. Przepustowość protokołu IPX dla bloku 512B spadła o ok. 1.4%, ale przyczyna spadku jest niejasna, jeśli wziąć pod uwagę wynik uzyskany dla łącza.
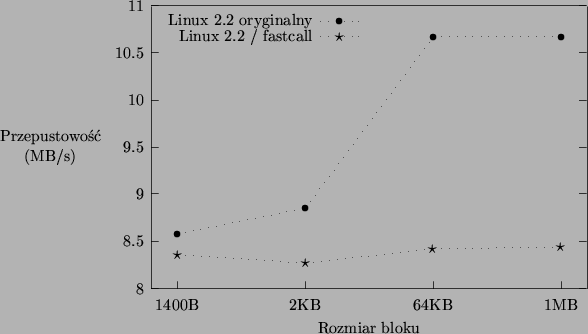
Wpływ modyfikacji na wydajność implementacji TCP/IP przedstawiono na rysunku 5.5. Pominięto wyniki uzyskane dla bloku jednobajtowego. Znowu można zaobserwować zaskakujący spadek przepustowości, jakim cechowała się implementacja Linuksa 2.2 już w kilku poprzednich testach. Natomiast zgodnie z oczekiwaniami przepustowość przy bloku jednobajtowym wzrosła. Pomiar wykonany programami client i server wykazał wzrost z 0.091MB/s do 0.141MB/s. Liczby te uzasadniają stwierdzenie, że wykonywanie kodu sieciowego z warstw administracyjnych zabiera zauważalną ilość czasu. Na podstawie wyników wykonanych eksperymentów trudno jednoznacznie wyjaśnić, dlaczego skrócenie tego czasu powoduje spadek przepustowości oraz zauważalne zmniejszenie odchyleń standardowych mierzonych wartości.
Przeprowadzone testy wykazały, że implementacje zarówno Linuksa, jak i FreeBSD cechują się dobrą wydajnością. Poziom nasycenia kanału transmisyjnego przy rozsądnej wielkości bloków danych zazwyczaj nie spada poniżej 75%. Do testów użyto dość wolnych komputerów, natomiast karty sieciowe odpowiadają współczesnym standardom. W praktycznych zastosowaniach wymagających dużej wydajności stosunek mocy obliczeniowej komputerów do przepustowości medium transmisyjnego powinien być co najmniej taki, jak w testach. Można domniemywać, że obie implementacje wykazałyby dobrą wydajność podczas testów na komputerach klasy Pentium 4 połączonych siecią typu Gigabit Ethernet.
Kod FreeBSD wykazuje się szczególnie dobrą wydajnością na tle implementacji z pokrewnych systemów NetBSD i OpenBSD. Historyczna nieefektywność kodu BSD, spowodowana złą architekturą buforów sieciowych mbuf, została w kodzie FreeBSD usunięta przede wszystkim dzięki umiejętnemu stosowaniu techniki klastrów, pozwalającej unikać zbędnego kopiowania danych. Należy podkreślić dużą stabilność i przewidywalność wyników pomiarów zarówno przepustowości, jak i obciążenia procesora. Odchylenia standardowe zmierzonych wartości były zazwyczaj niewielkie, a zmiana warunków pomiarów dawała najczęściej oczekiwane zmiany mierzonych wielkości.
Zachowanie implementacji Linuksa 2.2.16 było dużo mniej przewidywalne. Szczególnie zaskakuje fakt zmniejszenia przepustowości w wyniku przyspieszenia działania ścieżek nadawczej i odbiorczej, dziwią też efekty zwiększenia stosunku mocy obliczeniowej komputera do przepustowości medium transmisyjnego. Zwracają uwagę dość duże odchylenia standardowe niektórych zmierzonych wartości i nierówne krzywe zużycia czasu procesora. Jednak to właśnie w testach tej implementacji udało się osiągnąć największą przepustowość, sięgającą 95% maksymalnej przepustowości łącza 100Mb/s. Implementacja Linuksa 2.4.19 wykazała się mniejszą maksymalną przepustowością, ale dużo większą tolerancją na zmianę warunków pomiarowych.
Nie potwierdziła się teza o słabej wydajności kodu Linuksa. Ewentualnych dalszych usprawnień można by upatrywać w zastosowaniu szablonów nagłówków przy konstrukcji wysyłanych pakietów. Biorąc jednak pod uwagę, że ścieżka nadawcza kodu Linuksa jest mniej czasochłonna od ścieżki odbiorczej oraz że przedstawiona modyfikacja fastcall dała efekty odwrotne od oczekiwanych, trudno powiedzieć, czy użycie szablonów nagłówków miałoby pozytywny wpływ na wydajność. Innym możliwym kierunkiem zmian jest przeprojektowanie procedur obsługi przerwania sprzętowego na wzór rozwiązań stosowanych w systemie FreeBSD: opróżnianie kolejek nadawczych nie wymagałoby generowania przerwania programowego, a łączny czas obsługi przerwań sprzętowego i programowego przy odbiorze pakietu uległby skróceniu. Takie modyfikacje pociągnęłyby jednak za sobą konieczność przeprojektowania architektury podsystemu sieciowego. Jeszcze większych zmian architekturalnych wymagałoby zaimplementowanie propozycji Vana Jacobsona (zob. rozdział 4), polegających na rezygnacji z przerwań programowych, rezygnacji z przerwań przy transmisji pakietów, przypisaniu buforów do urządzeń i całkowitym usunięciu warstwy gniazd.
Mimo że wydajność obecnych implementacji może być niekiedy nie do końca zadowalająca, to istnieją w zasadzie tylko dwa istotne przypadki, gdy może zajść potrzeba stosowania specjalnych bibliotek komunikacyjnych. Pierwszy przypadek to klastrowe obliczenia równoległe, gdzie liczy się zarówno duża szybkość transmisji, jak i małe wymagania procedur komunikacyjnych na moc obliczeniową procesora. Drugi przypadek to zastosowanie komputera wyposażonego w kilka bardzo szybkich interfejsów sieciowych do budowy np. systemu rozproszonej pamięci masowej.