Subsections
Działanie serwisu z punktu widzenia użytkownika zostało już
wstępnie opisane w punkcie 2.2. W tym rozdziale chcę
dokonać pełnej analizy tworzonego przeze mnie systemu: zdefiniować
wymagania funkcjonalne oraz niefunkcjonalne. Te pierwsze zawarte
są w punkcie 3.1, drugie w punkcie
3.3. W punkcie 3.2
uzasadniam potrzebę rozproszenia aplikacji sprawdzającej strony
WWW, natomiast punkt 3.4 zawiera wymagania
stawiane bibliotece do rozdzielania zadań pomiędzy węzły sieci,
którą chcę zaimplementować w ramach realizacji całego systemu.
1 Wymagania funkcjonalne
Interfejsem użytkownika do systemu są dynamiczne strony WWW oraz
poczta elektroniczna. Funkcjonalność serwisu z punktu widzenia
użytkownika jest bardzo prosta -- serwis ma go informować o
zmianach wskazanych stron. Jednak, aby to było możliwe, niezbędne
są mechanizmy do personalizowania stron (autentykacja) oraz
zarządzania listą śledzonych stron i własnym kontem. Użytkownik,
korzystając ze stron WWW serwisu, powinien zatem móc:
- zarejestrować się w systemie; stworzyć nowe konto podając swój identyfikator, hasło oraz adres poczty elektronicznej,
- zalogować się, aby mieć dostęp do spersonalizowanych stron WWW, oraz wylogować się po zakończeniu pracy z serwisem,
- poprosić o ponowne przesłanie hasła listem elektronicznym na adres odpowiadający podanemu identyfikatorowi,
- dopisać stronę, która go interesuje (którą chce śledzić), podając jej adres URL,
- przeglądać listę śledzonych przez siebie stron wraz z informacją, kiedy dana strona została ostatnio zmodyfikowana,
- usunąć stronę z listy śledzonych stron,
- zmienić swoje hasło iłub adres poczty elektronicznej,
- usunąć swoje konto z serwisu.
System powinien cyklicznie (np. raz na dobę) odwiedzać wszystkie
śledzone strony, sprawdzając, czy ich zawartość się zmieniła.
Następnie system ma wysyłać list z powiadomieniem do tych
użytkowników, których śledzone strony uległy zmianie. Takie
powiadomienie powinno zawierać adresy wszystkich zmienionych stron
-- oczywiście spośród tych, które śledzi dany użytkownik.
2 Program sprawdzający strony -- dlaczego rozpraszać?
Zadanie sprawdzania śledzonych stron może być czasochłonne; czas
sprawdzenia zależy głównie, choć nie tylko, od liczby sprawdzanych
stron. Oczywiście elementem najbardziej czasochłonnym w procesie
sprawdzania danej strony jest połączenie się z odpowiednim
serwerem WWW, wysłanie zapytania i odebranie odpowiedzi HTTP z
nagłówkiem i ew. treścią strony. Samo sprawdzenie, czy strona się
zmieniła (niezależnie od sposobu![[*]](footnote.png) )
zajmuje nieznaczną ilość czasu w porównaniu ze ściąganiem
informacji o stronie lub jej zawartości. Biorąc pod uwagę, że
sprawdzanie danej strony WWW oznacza konieczność połączenia się z
jej serwerem WWW i pobrania z niego pewnej ilości informacji
(nawet niekoniecznie całej treści strony), można przyjąć, że
ściągnięcie jednej strony zajmuje średnio czas rzędu 1 sekundy.
Należy zaznaczyć, że jest to tylko oszacowanie, gdyż czas ten może
być bardzo różny, zależnie od fizycznej odległości między
komputerem a serwerem WWW, szybkości tego serwera, obciążenia
sieci itp.
)
zajmuje nieznaczną ilość czasu w porównaniu ze ściąganiem
informacji o stronie lub jej zawartości. Biorąc pod uwagę, że
sprawdzanie danej strony WWW oznacza konieczność połączenia się z
jej serwerem WWW i pobrania z niego pewnej ilości informacji
(nawet niekoniecznie całej treści strony), można przyjąć, że
ściągnięcie jednej strony zajmuje średnio czas rzędu 1 sekundy.
Należy zaznaczyć, że jest to tylko oszacowanie, gdyż czas ten może
być bardzo różny, zależnie od fizycznej odległości między
komputerem a serwerem WWW, szybkości tego serwera, obciążenia
sieci itp.
Podczas analizy takiego systemu należy odpowiedzieć sobie na
pytanie o przewidywane obciążenia. W przypadku serwisu
sprawdzającego strony pytanie to brzmi: jaka będzie liczba
śledzonych stron? Bardzo poważnym błędem byłoby niedoszacowanie
tej liczby. Nie ma nic gorszego niż system, który przestaje
sprawnie (lub w ogóle) działać, gdy liczba jego użytkowników
rośnie. Aby oszacować górną granicę liczby stron sprawdzanych
przez serwis, należy przyjąć jakieś założenia na liczbę
użytkowników oraz średnią liczbę śledzonych przez nich stron.
Biorąc pod uwagę fakt, że serwis -- raz uruchomiony -- będzie
dostępny dla wszystkich internautów i że może się on okazać bardzo
popularny, można założyć, że właściwym górnym oszacowaniem wydaje
się rząd 100 tysięcy użytkowników po kilku latach działania.
Oczywiście oznaczałoby to sukces serwisu, lecz aby być na niego
przygotowanym, serwis musi być w stanie obsłużyć związane z nim
obciążenie. Oszacowanie średniej liczby stron śledzonych przez
jednego użytkownika jest prostsze, a wynik obarczony mniejszym
błędem, gdyż serwis może w prosty sposób limitować tę liczbę. Na
potrzeby niniejszych wyliczeń przyjmuję, że jeden użytkownik
będzie średnio śledził 10 stron. Z szacunków tych wynika, że
serwis musi być przygotowany na śledzenie do 1 miliona stron.
Ponieważ większość czasu sprawdzania strony przypada na
komunikację sieciową (łączenie się z odpowiednim serwerem WWW i
pobieranie danych), zajmujący się tym program powinien być
wielowątkowy. Dzięki temu czekanie na odpowiedź z jednego serwera
nie będzie opóźniać komunikacji z innym. Jednak liczba wątków nie
może być zbyt duża z kilku powodów. Czas trwania całej operacji
jest i tak ograniczony szybkością połączenia danego komputera z
Internetem. Bardzo duża liczba wątków jest też nie zawsze możliwa
technicznie. System operacyjny może limitować liczbę portów
jednocześnie otwartych przez jeden program. Wreszcie program
mający zbyt dużo wątków może się okazać mało efektywny -- sporą
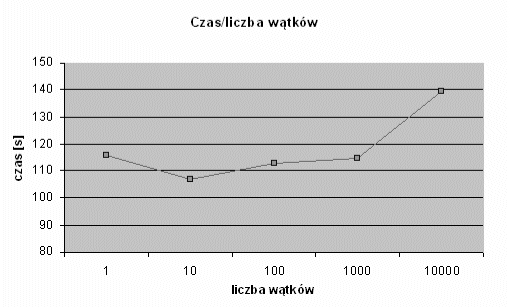
część czasu procesora będzie zajmować ich obsługa. Wykres na rys.
3.1 pokazuje zależność czasu wykonania programu od liczby
wątków. Program testowy, napisany w języku Java, wykonywał te same
obliczenia (podnoszenie trzystucyfrowej liczby do trzynastej
potęgi) w kolejno 1, 10, 100, 1000 i 10,000 wątków. Dla każdej
sprawdzanej liczby wątków program był uruchamiany 10 razy, a na
wykresie umieszczono średni czas działania. Widać wyraźnie, że dla
pewnej liczby powyżej 1000 wątków dodawanie nowych spowalnia
działanie całego programu, a optymalna liczba wątków leży gdzieś
pomiędzy 1 a 100.
Rysunek 3.1:
Czas działania programu w zależności od liczby wątków
 |
Jeśli w programie działa 20 wątków niezależnie sprawdzających
kolejne strony, a sprawdzenie jednej strony trwa średnio jedną
sekundę, to przejrzenie jednego miliona stron zajmie około 14
godzin (1 s * 1,000,000 / 20). Oczywiście taki czas działania
programu jest niedopuszczalny, z co najmniej trzech powodów:
- przy codziennym sprawdzaniu 14 godzin oznacza, że w pesymistycznym przypadku użytkownik dowiaduje się o zmianie strony po 24+14 = 38 godzinach, czyli nie po obiecanej dobie, lecz po prawie dwóch;
- wyliczona średnia wartość 14 godzin jest zbyt bliska długości całego cyklu (24h) -- jeśli wcześniej wypisane założenia są błędne i np. średni czas ściągania jednej strony wyniesie 2 sekundy, to czas sprawdzania wszystkich stron urośnie do 28 godzin, czyli będzie dłuższy niż cały cykl;
- zmiana w przyszłości długości cyklu na krótszy (np. przestawienie systemu na sprawdzanie co pół doby) nie będzie możliwa.
Biorąc pod uwagę wymienione argumenty, dobrze byłoby
ograniczyć czas sprawdzania śledzonych stron do najwyżej kilku
godzin.
Drugim problemem podczas ściągania śledzonych stron WWW może się
okazać słaba dostępność poszczególnych stron, zmieniająca się w
czasie i w zależności od połączenia między programem sprawdzającym
a serwerem WWW. Wynika to z charakterystyki Internetu, którą łatwo
zaobserwować korzystając z WWW. Dany serwer WWW może być czasem
słabo dostępny z komputera podłączonego do Internetu np. w
Szwajcarii, a w tym samym momencie mieć szybkie połączenie z
komputerem w Polsce czy w Kanadzie. Sprawdzanie
wszystkich śledzonych stron z jednego komputera jest więc
nieefektywne. Dużo lepiej byłoby sprawdzać daną stronę z komputera
znajdującego się możliwie jak najbliżej odpowiedniego serwera WWW.
Rozwiązaniem obu problemów -- czasu sprawdzania i ograniczonej
dostępności niektórych stron z konkretnych maszyn -- jest
wykorzystanie więcej niż jednego komputera i uruchomienie programu
sprawdzającego na każdym z nich. Programy działające na
poszczególnych komputerach muszą się ze sobą komunikować, żeby nie
sprawdzać tych samych stron i aby po zakończeniu sprawdzania móc
połączyć wyniki. Oznacza to konieczność stworzenia rozproszonego
systemu, działającego na wielu komputerach na raz, rozdzielającego
strony do sprawdzenia pomiędzy programy sprawdzające i
synchronizującego ich pracę. Wykorzystanie wielu komputerów
rozwiązuje problem czasu działania programu. W dobrze
zaprojektowanym systemie, gdy rośnie liczba śledzonych stron i
czas ich sprawdzania wydłuża się niebezpiecznie, wystarczy
podłączyć kolejny komputer. Komputery będące częścią systemu można
podłączyć w różnych miejscach Internetu. Przy odpowiednim
zaprojektowaniu algorytmu rozdzielającego strony pomiędzy węzły
sieci umożliwi to efektywne sprawdzanie. Strona znajdująca się na
serwerze WWW będzie ściągana przez program działający na tym
komputerze, który ma najszybsze połączenie z danym serwerem.
Dokładne wymagania, jakie musi spełnić system, aby w pełni
wykorzystać możliwości związane z jego rozproszeniem, opisane są w
punkcie 3.3.
Aby móc lepiej i precyzyjniej określić wymagania, wstępnie
zakładam, że system będzie miał architekturę scentralizowaną.
Oznacza to, że system będzie tworzyć jeden serwer główny i wiele
połączonych z nim węzłów. Szczegółowe uzasadnienie takiego wyboru
przedstawiam w rozdziale 4, zawierającym opis projektu
systemu.
3 Wymagania niefunkcjonalne w kontekście rozpraszania
Problem wydajności programu sprawdzającego śledzone strony WWW
został już poruszony w punkcie 3.2. Aby
system mógł sprawnie uporać się przewidywanym obciążeniem, podział
stron do sprawdzania pomiędzy programy działające na różnych
komputerach w systemie musi być efektywny. Dana strona powinna być
sprawdzana z tego węzła systemu (komputera), który ma najszybsze
połączenie z jej serwerem WWW. Nie jest to proste do zrealizowania
z dwóch powodów. Po pierwsze nie ma jednoznacznego, pewnego
sposobu na wybranie optymalnego węzła dla danej strony WWW poza
sprawdzeniem średniego czasu połączenia od każdego z węzłów.
Drugim powodem jest zmieniająca się nieustannie przepustowość
sieci oraz dostępność poszczególnych serwerów wynikająca ze
zmiennego obciążenia, awarii oraz powstawania nowych łączy, zmian
w sposobie podłączenia węzłów oraz serwerów do Internetu itp.
Wynika z tego, że przypisanie zadania sprawdzania danej strony do
konkretnego węzła nie może być ostateczne. Cały system musi być
dynamiczny -- zadanie sprawdzania konkretnej strony powinno być
przenoszone z węzła do węzła w miarę potrzeby tak, aby jego
wykonanie trwało jak najkrócej.
Oczywiście każda strona WWW (konkretnie: dany adres URL) powinna
być sprawdzana raz, niezależnie od tego ilu użytkowników ją
śledzi. System powinien tak sterować rozdziałem i przenoszeniem
zadań pomiędzy węzłami, aby nie dopuścić do sytuacji przypadkowego
sprawdzania tej samej strony wielokrotnie. Może natomiast celowo
przekazać zadanie sprawdzenia tej samej strony dwóm różnym węzłom
w systemie, aby porównać czas wykonania i w kolejnym cyklu zlecać
to zadanie szybszemu węzłowi.
Kolejnym rozwiązaniem, mogącym pozytywnie wpłynąć na wydajność
systemu, choć niezależnym od faktu jego rozproszenia, jest
uwzględnienie własności protokołu HTTP. Program sprawdzający
strony powinien wykorzystywać możliwości, jakie stwarza HTTP:
odczytywać informacje o wielkości pliku i dacie ostatniej
modyfikacji z nagłówka odpowiedzi, a następnie odpowiednio je
interpretować. W efekcie strona, dla której od czasu poprzedniego
sprawdzania nie zmieniła się ani wielkość, ani data ostatniej
modyfikacji, nie powinna być ponownie ściągana w całości w celu
porównywania zawartości.
2 Skalowalność
Skalowalność systemu to zdolność do obsłużenia wzrastającego
obciążenia poprzez dołączanie kolejnych zasobów (komputerów,
procesorów, pamięci). System skalowalny można rozszerzać bez
potrzeby modyfikacji oprogramowania. W przypadku systemu
rozproszonego dodawanym zasobem są zwykle kolejne węzły
(komputery). Wydajność dobrze skalowalnego systemu rozproszonego
rośnie (co najmniej) liniowo wraz z liczbą dołączanych węzłów.
Serwis rejestrujący zmiany WWW powinien być dobrze skalowalny w
rozumieniu podanej definicji. Algorytm równoważący obciążenie musi
zauważać pojawienie się w systemie nowego węzła i wykorzystywać
jego istnienie przekazując mu strony do sprawdzania. System
powinien być zaprojektowany tak, aby efektywnie wykorzystywać
nawet kilkadziesiąt węzłów. Efektywne wykorzystanie oznacza
osiąganie wydajności możliwie zbliżone do liniowej w zależności od
liczby węzłów. Ten warunek musi być spełniony niezależnie od
wybranej ostatecznie topologii systemu. Jeśli będzie to system o
scentralizowanej architekturze, to serwer główny nie może stanowić
wąskiego gardła przy założonej wcześniej liczbie węzłów.
Zagadnienie otwartości systemu wiąże się bezpośrednio z jego
skalowalnością. W systemie otwartym operacja podłączenia nowego
komputera do systemu powinna wymagać minimalnych zmian w
konfiguracji systemu. Może to oznaczać np. dodanie adresu
komputera do listy komputerów w systemie. System otwarty ma ściśle
zdefiniowany interfejs, przez jaki węzły komunikują się ze sobą
lub z węzłem głównym systemu (w przypadku systemu
scentralizowanego). Każdy węzeł implementujący wymagany interfejs,
niezależnie od wewnętrznej implementacji, może zostać podłączony
do systemu (pod warunkiem, że spełnia też istniejące wymogi
bezpieczeństwa). Projektowany przeze mnie system powinien być
systemem otwartym, z dobrze zdefiniowanymi protokołami komunikacji
między węzłami.
Można wyobrazić sobie sytuację, w której nowo podłączany węzeł sam
się rejestruje w systemie, nie oczekując żadnej akcji ze strony
administratora systemu. Taka otwartość kłóci się jednak z
niektórymi wymaganiami dotyczącymi bezpieczeństwa (punkt
3.3.5), nie umieszczam jej więc na liście wymagań.
4 Odporność na awarie
Odporność na błędy i awarie jest jednym z trudniejszych, ale i
ciekawszych aspektów analizy i projektowania systemów
rozproszonych. Z jednej strony wiele komputerów i działających na
nich programów oznacza więcej możliwości zaistnienia sytuacji
awaryjnej. Z drugiej strony dobrze zaprojektowany system
rozproszony jest w stanie sprawnie się z takimi sytuacjami uporać
-- sprawniej niż pojedynczy program wykonywany na jednym
komputerze. W przypadku takiego programu poważna awaria (np.
zawieszenie się programu lub awaria komputera, na którym program
jest uruchomiony) powoduje zwykle całkowite przerwanie działania
oraz utratę wszystkich wyników. W systemie rozproszonym awaria
częściowa (dotycząca fragmentu systemu) może zostać obsłużona.
System składający się z wielu komputerów i programów
współpracujących ze sobą w przypadku awarii jednego z nich
powinien automatycznie taką awarię zauważać i sterować pracą
reszty węzłów tak, aby fakt zaistnienia awarii pozostał
niezauważony na zewnątrz systemu.
W trakcie sprawdzania stron WWW w systemie może pojawić się szereg sytuacji awaryjnych, które można podzielić na związane z:
- działaniem serwera WWW,
- działaniem węzła systemu,
- działaniem serwera głównego.
Termin awaria jest bardzo szeroki -- Flaviu Cristian [Cri91]
proponuje następujący podział ze względu na typ błędów
pojawiających się w systemach rozproszonych:
- błąd pominięcia (ang. omission failure) -- program nie odpowiada na zapytania (nie odbiera zapytań bądź nie wysyła odpowiedzi),
- błąd opóźnienia (ang. timing failure) -- czas odpowiedzi programu przekracza założone (dopuszczalne) ramy,
- błąd przerwania działania (ang. crash failure) -- program przestaje działać, lecz przedtem działał poprawnie,
- błąd odpowiedzi (ang. response failure) -- odpowiedź programu jest nieprawidłowa.
Autorzy [Tan02] przytaczają jeszcze jeden typ błędu:
- błąd przypadkowości (ang. arbitrary failure) -- program generuje dowolne odpowiedzi w przypadkowych momentach.
System śledzenia stron WWW powinien być odporny na przewidywalne
typy sytuacji awaryjnych. Stosunkowo najprostsze będzie obsłużenie
błędnego działania jednego z serwerów WWW, na których znajdują się
śledzone strony. Zakładam, że każda odpowiedź wygenerowana przez
serwer WWW (tzn. przesyłana z serwera strona WWW) jest poprawna --
bez tego założenia WWW nie miałoby racji bytu! W absolutnej
większości wypadków nie istnieje bowiem sposób sprawdzenia, czy
strona otrzymana w wyniku zapytania jest tą, która powinna była
zostać przesłana w odpowiedzi. Ponieważ protokół HTTP działa na
zasadzie zapytanie-odpowiedź, więc błąd przypadkowości nie zagraża
systemowi (przypadkowo wygenerowana odpowiedź nie zostanie
odebrana przez system, gdyż nie poprzedziło jej zapytanie do
serwera WWW). Zatem system sprawdzania stron musi być przygotowany
na błędy pominięcia, opóźnienia oraz przerwania pracy serwera
WWW. Jednym słowem musi sobie poradzić w sytuacji, gdy serwer nie
odpowiada na zapytanie o śledzoną stronę. W jednym cyklu
sprawdzania system powinien pytać o nieosiągalną stronę więcej niż
raz, ewentualnie zmieniając węzeł, z którego wysyłane jest
zapytanie. Dzięki temu brak możliwości nawiązania połączenia
internetowego między jednym węzłem a danym serwerem WWW nie
przeszkodzi ściągnięciu stron z tego serwera przez inny węzeł.
Błędy związanie z działaniem węzła systemu są poważniejsze i będą
wymagały odpowiedniego obsłużenia. Ogólnie rzecz biorąc, w
przypadku, gdy jeden z węzłów przestanie przyjmować żądania lub
wysyłać do serwera wyniki zgodnie z protokołem komunikacji, serwer
główny powinien odłączyć błędnie działający węzeł i przydzielić
jego zadania innym węzłom. Tak stanie się też w przypadku braku
możliwości nawiązania połączenia z węzłem -- nawet gdy on sam
działa dobrze. Wyniki przesyłane przez węzły podłączone do systemu
(po spełnieniu pewnych warunków bezpieczeństwa opisanych w
następnym punkcie) są traktowane jako poprawne i nie będą
sprawdzane przez inne węzły. Taka redundancja nie byłaby możliwa w
systemie z powodów wydajnościowych. Tak określone wymagania czynią
co prawda system nieodpornym na błąd odpowiedzi ze strony węzła.
Zasadność powyższego założenia o zaufaniu w stosunku do węzłów
można jednak poprzeć argumentem, iż w każdym funkcjonującym
systemie musi istnieć pewien stopień zaufania między jego
elementami. Natomiast na pozostałe typy sytuacji błędnych
pojawiających się w węzłach system musi być odporny.
Naturalną konsekwencją scentralizowanej architektury systemu jest
jego wrażliwość na awarie serwera głównego. Wybór takiej
architektury wynika jednak ze wzięcia pod uwagę wszystkich
stawianych wymagań oraz pewnego kompromisu między nimi.
Uzasadnienie tego wyboru przedstawiam w punkcie
4.2. Węzeł główny systemu nie jest serwerem w
rozumieniu komputera lub oprogramowania odpowiadającego na
zapytania klientów. To raczej on sam jest klientem pozostałych węzłów
systemu. W związku z tym nie da się przeprowadzić analizy jego
odporności na awarie stosując podany wcześniej podział na typy
błędów. System powinien jednak spełniać następujące wymagania:
- W przypadku przerwania pracy i powtórnego uruchomienia, program działający na serwerze głównym powinien, na podstawie zawartości bazy danych oraz komunikatów otrzymywanych od węzłów, rozpocząć pracę w przerwanym momencie;
- Błędy czasu wykonania (ang. runtime errors) powinny być przejmowane i obsługiwane przez program na najniższym możliwym poziomie, w miarę możliwości nie zakłócając i nie przerywając pracy całego programu (dotyczy to także programów działających na węzłach systemu);
- System powinien umożliwiać prostą podmianę komputera, na którym działa program serwera głównego iłub komputera zawierającego bazę danych (nie musi to być ten sam komputer).
5 Bezpieczeństwo
System rozproszony -- znacznie bardziej niż pojedynczy program czy
komputer -- jest wystawiony na różnego rodzaju niebezpieczeństwa,
właśnie z racji swego rozproszenia. Dlatego też kwestie
bezpieczeństwa są tak istotne podczas analizy i projektowania tego
rodzaju systemów. Bezpieczny system musi być odporny nie tylko na
mogące powstać (niejako samoistnie) sytuacje awaryjne (punkt
3.3.4), ale także na celowe działania ludzi lub innych
programów mające na celu zakłócenie jego pracy. W przypadku analizy
bezpieczeństwa systemu śledzenia stron WWW należy wziąć pod uwagę
następujące trzy problemy, omówione dalej w tym punkcie:
- bezpieczeństwo fizyczne programów oraz danych przechowywanych i uruchamianych na komputerach,
- zapewnienie integralności systemu i bezpieczeństwo kanałów komunikacji,
- odporność całego systemu na zewnętrzne zagrożenia, np. zorganizowane ataki typu Denial of Service (DOS).
Pierwsze z wymienionych wymagań oznacza konieczność zapewnienia
bezpieczeństwa fizycznego programów (plików) oraz danych przez nie
wykorzystywanych. Programy wchodzące w skład systemu powinny być
też uruchamiane w wyznaczonych momentach (np. o danej godzinie)
lub uruchamiane ponownie w przypadku błędnego zakończenia pracy
(np. zawieszenia się programu lub zresetowania komputera). Opisane
wcześniej kwestie bezpieczeństwa są realizowane na poziomie praw
dostępu do plików, kont użytkowników, konfiguracji bazy danych,
ustawień mechanizmów automatycznego uruchamiania programów (np.
cron) itp. Wymaganie to stawia zadania bardziej przed
administratorem gotowego już systemu niż jego projektantem,
dlatego ich realizacja nie będzie dalej omawiana w tej pracy.
Tworząc taki system należy jednak mieć na względzie powyższe
wymaganie -- umożliwi to później administratorowi efektywną pracę.
Następna z wymienionych kwestii to integralność systemu. Można
sobie wyobrazić między innymi następujące zagrożenia tej
integralności:
- podłączenie do systemu nieautoryzowanego węzła,
- podszycie się pod istniejący węzeł,
- przejęcie kanału komunikacji pomiędzy węzłem a serwerem i przesyłanie dodatkowych, fałszywych zapytań i odpowiedzi oraz usuwanie lub modyfikowanie poprawnych zapytań i odpowiedzi generowanych przez system,
- podszycie się pod serwer główny i wykorzystanie węzła lub węzłów,
- podmiana zadania wykonywanego przez węzły i wykorzystanie w ten sposób mocy i rozproszenia systemu.
System musi być odporny na te i podobne ataki. Aby osiągnąć taką
odporność, komunikacja pomiędzy węzłami a serwerem musi być
szyfrowana, a programy na obu końcach kanału komunikacji powinny
potwierdzać swoją tożsamość przy użyciu certyfikatów
elektronicznych.
Ataki, jakich system może oczekiwać i na jakie musi być
przygotowany, to nie tylko opisane wcześniej próby nielegalnego
wtargnięcia do wnętrza systemu. Istnieje całe spektrum zagrożeń,
które można ogólnie zakwalifikować jako ataki odwołujące się do
publicznie dostępnego interfejsu systemu, ale w sposób
niepożądany. Zaliczają się do nich między innymi ataki poprzez
przepełnienie buforu, podanie danych w nieprawidłowym formacie, aż
do przeciążenia systemu gigantyczną liczbą poprawnych zapytań
(Denial of Service). W przypadku systemu sprawdzania stron WWW
jedynymi danymi wejściowymi jest lista śledzonych stron, co czyni
ochronę przed wspomnianymi atakami prostszą. Program powinien
sprawdzać poprawność podawanych adresów stron WWW oraz
uniemożliwiać wprowadzenie więcej niż pewnej dozwolonej liczby
adresów z jednego źródła (np. od jednego użytkownika systemu).
Wymienione w tym punkcie zagrożenia bezpieczeństwa systemu to
zaledwie czubek góry lodowej. Między producentami oprogramowania a
różnego rodzaju włamywaczami komputerowymi trwa nieprzerwana
rywalizacja, owocująca pojawianiem się nowych rodzajów ataków oraz
kolejnych sposobów bronienia się przed nimi. Projektując i
implementując taki system należy na bieżąco śledzić prasę oraz
serwisy internetowe poświęcone kwestiom bezpieczeństwa. Podczas
tworzenia systemu nie można ograniczać się do ochrony przed
istniejącymi już niebezpieczeństwami (a tym bardziej tylko przed
wymienionymi w wymaganiach!). Bardziej odpowiednim podejściem jest
raczej zaprojektowanie systemu tak, aby miał prostą i czytelną
strukturę, dobrze zdefiniowane zależności i obowiązki
poszczególnych jego elementów oraz jasno określony model
bezpieczeństwa na wielu poziomach.
4 Biblioteka do rozdzielania zadań pomiędzy węzły sieci
Jednym z etapów tworzenia systemu sprawdzania stron WWW będzie
zaprojektowanie i zaimplementowanie algorytmu rozdzielania zadań
pomiędzy węzły sieci oraz protokołów komunikacji pomiędzy węzłami
a serwerem. Zadaniem w tym systemie będzie oczywiście sprawdzenie,
czy wskazana strona WWW uległa zmianie od poprzedniego
sprawdzania. Moim celem będzie wyodrębnienie tej części
funkcjonalności serwisu i stworzenie tym samym ogólnej biblioteki
służącej do rozdzielania i rozproszonego przetwarzania zadań. Aby
umożliwić wykorzystanie tej biblioteki w przyszłości w innym celu
niż sprawdzanie stron, musi ona spełniać następujące warunki:
- niezależność od typu zadania -- biblioteka powinna umożliwiać przetwarzanie dowolnego zadania, spełniającego jedynie pewne ogólne założenia,
- prostota użycia -- najprostszy system korzystający z tej biblioteki powinien mieścić się w kilku prostych klasach implementujących dobrze zdefiniowane i czytelne interfejsy,
- możliwość podmiany klasy realizującej zadania w węzłach -- klasa ta będzie przesyłana z serwera do każdego z węzłów,
- łatwość administracji: definiowania listy węzłów w systemie, wyznaczania rozpoznawanych przez system certyfikatów itp.
Algorytm rozdziału zadań oraz protokoły komunikacji
zaimplementowane w bibliotece muszą oczywiście spełniać wymagania
opisane w punkcie 3.3 -- lub raczej
umożliwić spełnienie tych wymagań. Przykładowo w punkcie
opisującym kwestie dotyczące bezpieczeństwa systemu zawarte jest
wymaganie mówiące o konieczności szyfrowania połączeń między
elementami systemu. Biblioteka powinna umożliwiać (ale nie
wymuszać) wykorzystywanie szyfrowanych kanałów komunikacji.
Programista korzystający z biblioteki będzie mógł zaznaczyć w
odpowiednim pliku konfiguracyjnym, czy chce szyfrować połączenia,
czy nie.
Sebastian Łopieński