Subsections
4 Projekt systemu
1 Technologie
W tym podrozdziale znajduje się opis technologii i produktów
użytych przy realizacji systemu, wraz z uzasadnieniem dokonanego
wyboru. W większości wypadków prezentowałem też konkurencyjne
technologie i dokonywałem krótkiego porównania między dostępnymi
możliwościami. Głównymi kryteriami przy wyborze technologii były:
- dostępne możliwości -- na ile dana technologia (produkt) spełnia lub umożliwia spełnienie wymagań systemu,
- łatwość wykorzystania -- na ile łatwo będzie zaimplementować system przy pomocy danej technologii,
- powszechność -- wybranie produktu lub technologii, które może zostać wykorzystany tylko na jednej platformie, ogranicza w przyszłości możliwości wdrażania gotowego systemu,
- koszt -- w dobie powszechniej obecności bardzo dobrych darmowych produktów wybranie produktu komercyjnego musiałoby być uzasadnione poważnymi korzyściami w innych punktach.
Choć decyzje dotyczące technologii można podjąć dopiero na etapie
implementacji, to wcześniejsze wybranie używanych języków
programowania, platformy systemowej itp. pozwala na
precyzyjniejsze zaprojektowanie systemu. Przed rozpoczęciem etapu
projektowania chciałem więc wybrać: technologie do obsługi
dynamicznych stron WWW (serwer WWW, język generowania stron);
system bazy danych; język programowania, w którym zostanie
zaimplementowany system sprawdzania stron oraz mechanizm
komunikacji między elementami systemu. W kolejnych podpunktach
omawiam poszczególne technologie i produkty.
Dynamiczne strony WWW są głównym (poza pocztą elektroniczną)
interfejsem całego serwisu, jego sposobem komunikacji z
użytkownikami. Będą one działały na serwerze HTTP Apache. Serwer
ten jest aktualnie jednym z najbardziej rozpowszechnionych
serwerów WWW, używanym w szeregu zastosowań, bezpiecznym,
stabilnym i wydajnym. Dodatkową jego zaletą jest to, iż Apache
jest produktem darmowym.
Apache działa świetnie w połączeniu z także bezpłatnym systemem
operacyjnym Linux. Zamierzam wykorzystać dystrybucję Linuxa RedHat
7.2. Wybór dystrybucji nie jest istotny, gdyż wszystkie one są ze
sobą zgodne (przynajmniej na tyle, aby zmiana dystrybucji w
przyszłości nie pociągała za sobą konieczności modyfikacji kodu
źródłowego serwisu czy konfiguracji serwera WWW).
Strony WWW zostaną zaimplementowane w języku skryptowym PHP (w
wersji 4). Wybór języka do generowania dynamicznych stron nie jest
tak prosty jak wybór serwera, gdyż kontrkandydaci (Perl, servlety
Java, JSP, XSP, Python i inni) także spełniają wszystkie (lub
prawie wszystkie) wymienione warunki. Należy jednak pamiętać, że
serwis internetowy jest tylko drobną częścią całego systemu i
będzie się składał z najwyżej kilkunastu stron. Tak nieduży serwis
można łatwo i szybko zaimplementować właśnie w PHP, najbardziej
nadającym się do takich zastosowań.
Baza danych będzie w systemie elementem łączącym serwis
internetowy (dynamicznie generowane strony WWW będące interfejsem
użytkownika) oraz oprogramowanie do sprawdzania śledzonych stron.
W bazie danych trzymane będą informacje o użytkownikach, stronach,
wynikach sprawdzania itp. W projektowanym przeze mnie systemie
skorzystam z bazy danych Postgres. Produkt ten jest darmowy,
szeroko rozpowszechniony i często wykorzystywany na platformie
Linux w połączeniu z językiem PHP.
Główny rywal bazy danych Postgres to MySQL, również spełniająca
podane wymogi. MySQL jest uważany za nieco bardziej wydajny od
bazy Postgres. Postgres oferuje jednak więcej dodatkowych
własności, takich jak obsługa transakcji czy wewnętrzny język do
tworzenia procedur składowanych (ang. stored procedures --
procedur i funkcji działających wewnątrz bazy danych). Obie te
cechy mogą się jednak bardzo przydać przy tworzeniu systemu
rozproszonego. Wykorzystanie transakcji umożliwi zapewnienie
spójności bazy danych. Natomiast podprogramy zapisane i działające
w bazie pozwolą między innymi uniknąć dublowania kodu na poziomie
programów (np. ten sam kod w oprogramowaniu serwera głównego oraz
węzła) oraz poprawią wydajność działania bazy danych.
Cały system powinien być tak zaprojektowany i zaimplementowany,
aby w razie potrzeby umożliwić zmianę serwera bazodanowego.
Dlatego też wyboru bazy Postgres nie traktuję jako ostatecznego.
Oprogramowanie do sprawdzania śledzonych stron zostanie napisane w
języku Java w wersji J2EE 1.4. Wybór ten jest podyktowany
szeregiem istotnych powodów:
- Java jest dojrzałym, szeroko używanym, obiektowym językiem programowania,
- środowisko do kompilowania i uruchamiania programów w języku Java
![[*]](footnote.png) (tzn. JVM -- Java Virtual Machine oraz JRE -- Java Runtime Enviroment) jest darmowe,
(tzn. JVM -- Java Virtual Machine oraz JRE -- Java Runtime Enviroment) jest darmowe,
- programy w języku Java można uruchamiać na dowolnym komputerze (lub ogólniej: urządzeniu) wyposażonym w maszynę wirtualną Javy (ang. JVM),
- w ramach standardowej dystrybucji Javy dostępne jest wiele użytecznych bibliotek (między innymi do obsługi baz danych, połączeń sieciowych, formatu XML oraz protokołu SSH),
- architektura programów Java, podział na klasy i pakiety, możliwość implementowania interfejsów oraz ładowania potrzebnych klas (także z sieci) w trakcie działania programu to cechy bardzo pomocne przy implementacji biblioteki do równoważenia obciążenia i rozproszonego przetwarzania zadań,
- Java jest językiem programowania bardzo przyjaznym dla programistów, między innymi dzięki wbudowanej obsłudze wątków oraz wyjątków.
Pomimo tego, że istnieje bardzo wiele aktualnie używanych języków
programowania, wybór języka Java był dla mnie w praktyce
oczywisty. Jedynym poważnym konkurentem dla środowiska Java jest
stworzona i promowana przez firmę Microsoft platforma .NET.
Oferuje ona wiele zaawansowanych bibliotek, możliwość używania
różnych języków programowania (między innymi podobnego do Java
języka C#) oraz łatwą integrację z innymi produktami Microsoft
(systemem operacyjnym, bazą danych, serwerem wymiany informacji
itp.). Jednak wybór .NET ma dwie podstawowe wady. Po pierwsze
platforma ta jest produktem komercyjnym. Drugim minusem jest to,
iż działa ona jedynie w połączeniu z systemem operacyjnym firmy
Microsoft.
4 Komunikacja pomiędzy elementami systemu
Serwer główny będzie komunikował się z węzłami poprzez sieć
Internet. Wybór metody komunikacji nie jest oczywisty z powodu
dużej liczby możliwości:
- komunikaty tekstowe przesyłane zgodnie z protokołem TCP/IP,
- komunikaty w formacie XML przesyłane zgodnie z protokołem TCP/IP,
- zdalne wywołania metod przy użyciu protokołu SOAP,
- zdalne wywołania metod przy użyciu technologii CORBA,
- zdalne wywołania metod przy użyciu mechanizmu RMI,
- komunikacja poprzez bazę danych.
Jak zwykle w takich sytuacjach, każda z opcji ma swoje plusy i
minusy. Należy więc wybrać tę, która najlepiej spełnia wymagania
i nakłada najmniej ograniczeń. Przesyłanie tekstowych komunikatów
poprzez zwykłe połączenie TCP/IP jest najprostszym rozwiązaniem,
które jednak oznacza dla programisty konieczność ciągłego
utrzymania połączenia (jeśli połączenie TCP/IP zostanie przerwane,
trzeba je na nowo nawiązać). Inne problemy, które mogą się pojawić
przy implementowaniu tego rozwiązania, to konieczność sprawdzenia,
czy odebrany komunikat jest spójny oraz czy jest zakodowany w
spodziewanym formacie. Druga z wymienionych wad nie występuje, gdy
komunikaty będą przesyłane w formacie XML. W takim przypadku do
sprawdzenia poprawności formatu danej wiadomości można skorzystać
z istniejących parserów XML. Wykorzystanie formatu XML pozwoliłoby
na szczegółowe zdefiniowanie i na przykład opublikowanie struktury
każdej wiadomości. Dzięki tak sformalizowanemu protokołowi
komunikacji możliwe byłoby w przyszłości stworzenie dodatkowego
oprogramowania węzłów. Jednak stwarzanie takiej możliwości nie ma
większego sensu, gdyż oprogramowanie węzłów musi być
zaimplementowane w języku Java, tak aby kod klasy realizującej
dany typ zadania mógł być ściągany z serwera i uruchamiany na
węzłach.
Ponieważ oprogramowanie serwera głównego i węzłów będzie napisane
w obiektowym języku, zamiast niskopoziomowej komunikacji po TCP/IP
można wykorzystać jeden z mechanizmów zdalnego wywołania metod w
obiektach istniejących na innym serwerze. Dostępne mechanizmy,
które rozpatrywałem, to SOAP (ang. Simple Object Access
Protocol), CORBA (ang. Common Object Request Broker
Architecture) oraz RMI (ang. Remote Method Invocation).
Przy standardowym użyciu wszystkie te technologie oferują
komunikację w jedną stronę: metody dostępnej zdalnie klasy są
wołane przez obiekty działające na innych komputerach. Aby obie
strony mogły inicjować komunikację, należałoby na obu
współpracujących komputerach uruchomić serwer zdalnych obiektów.
Aby nie komplikować niepotrzebnie komunikacji między elementami
systemu, można tak zaprojektować protokół komunikacji między nimi,
aby wystarczyło zdalne wołanie metod w obiektach tylko jednego z
porozumiewających się programów.
Użycie protokołu SOAP jest kuszące, gdyż wykorzystuje on znane i
powszechnie stosowane technologie: HTTP oraz XML. Serwer SOAP
można uruchomić jako tzw. plug-in w serwerze HTTP Apache
-- nie trzeba więc otwierać żadnego nowego portu poza portem 80
(HTTP). Niemniej jednak jedna z głównych zalety protokołu SOAP
-- możliwość zaimplementowania klienta i serwera w różnych językach
oprogramowania i na różnych platformach systemowych -- traci
znaczenie przy wyborze języka Java do implementacji całego
oprogramowania. Ponadto przy zdalnym wywołaniu metody, gdy
wewnętrznie wbudowany mechanizm sam zapewnia sprawdzanie spójności
wywołania, możliwość korzystania z formatu XML staje się raczej
koniecznością, dodatkowym obciążeniem. Parametry przekazywane przy
wołaniu metod są ograniczone do prostych typów, co uniemożliwia
przekazywanie obiektów.
Podobnie rzecz ma się z technologią CORBA, będącą w powszechnym
użyciu w dużych systemach rozproszonych. Leżąca u podstaw
protokołu CORBA architektura pozwala na zdalne udostępnianie
obiektów oraz wołanie ich metod przy użyciu identyfikatora obiektu
bez wskazywania, na której maszynie obiekt się znajduje.
Funkcjonalność ta jest nieprzydatna z punktu widzenia tworzonej
przeze mnie biblioteki, ponieważ algorytm do równoważenia
obciążenia powinien ściśle kontrolować przydział zadań do węzłów.
Wymienionych wcześniej wad technologii SOAP i CORBA nie ma
protokół RMI ([Gro01]). Jest to protokół zdalnego wołania
metod dla klas w języku Java. Dzięki temu umożliwia on
wykorzystanie możliwości tego języka takich jak automatyczne
ładowanie klas poprzez protokół HTTP, przekazywanie obiektów w
parametrach wywołania metod czy definiowanie interfejsów zdalnych
obiektów w standardowym formacie Java (a nie np. IDL wbudowanym w
technologię CORBA). Używanie protokołu RMI nie nastręcza
programiście większych trudności. Korzystanie z niego wydaje się
być relatywnie prostsze niż z technologii CORBA (ze względu na
skomplikowaną architekturę) czy SOAP (konieczność używania formatu
XML). Fakt, że RMI zostało zaprojektowane właśnie dla języka Java
sprawia, iż jest to najlepszy -- spośród mechanizmów zdalnego
wołania metod -- wybór dla rozproszonych aplikacji implementowanych
w tym języku.
Zupełnie innym od rozważanych wcześniej sposobów komunikacji w
systemie jest komunikowanie się poprzez zawartość wspólnej bazy
danych. W uproszczeniu taka komunikacja w systemie sprawdzania
stron WWW działałaby następująco: serwer główny zostawia w bazie
danych informacje, które strony mają być sprawdzone i przez które
węzły (np. w postaci zaznaczonych flag na odpowiednich rekordach).
Następnie oprogramowanie węzła łączy się z bazą danych i pobiera
informacje o przydzielonych sobie stronach. Po ich sprawdzeniu
umieszcza wyniki w odpowiedniej tabeli, z której pobiera je serwer
główny. Problemem jest jednak zsynchronizowanie działań serwera
głównego i węzłów -- w jaki sposób węzeł ma wiedzieć, że nowo
przydzielone zadania czekają na niego w bazie danych?
Rozwiązaniem, z oczywistych powodów nienajlepszym, byłoby
cykliczne sprawdzanie zawartości bazy danych. Plusem takiej metody
komunikacji jest natomiast jej trwałość i odporność na błędy.
Komunikat w bazie danych nie musi być natychmiast odebrany przez
adresata, może czekać na moment, w którym program odbierający
zostanie uruchomiony i połączy się z bazą danych. Taka
funkcjonalność znacznie ułatwiłaby zapewnienie odporności systemu
na błędy (np. czasowe wyłączenia węzłów lub przerwanie
komunikacji). Informacje przekazywane przez bazę danych mają
własności asynchronicznych wiadomości. W praktyce taką metodę
komunikacji można by zakwalifikować jako komunikację opartą na
wiadomościach (ang. message-oriented communication).
Z powodu wymienionych wad baza danych nie może być jedynym
sposobem komunikowania się elementów systemu. Niezbędne, a
przynajmniej bardzo pomocne, wydaje się użycie synchronicznego
sposobu komunikacji. W implementowaniu biblioteki do równoważenia
obciążenia użyję protokołu RMI jako najwygodniejszej z omówionych
możliwości. Natomiast wszelkie istotne dla działania systemu
informacje będą także zapisywane na bieżąco w bazie danych, co
umożliwi proste odtworzenie stanu pracy w przypadku awaryjnego
przerwania działania i ponownego uruchomienia jednego z programów.
Baza danych będzie zawierać tzw. dane rekonstrukcji (por.
[Cou98]). Oznacza to, że system będzie wykorzystywał bazę
danych jako awaryjny środek komunikacji. Przykładowo, serwer
będzie zapisywał w bazie danych informacje o aktualnym cyklu,
postępach w realizacji zadań, przypisaniach poszczególnych zadań
do węzłów itp. Te informacje będą bezcenne w przypadku awarii
serwera -- po ponownym uruchomieniu nie będzie on żądał od węzłów
powtórnego wykonania zrealizowanych wcześniej zadań.
2 Budowa systemu
System sprawdzania stron WWW będzie systemem rozproszonym -- będzie
się składał z programów współpracujących ze sobą, działających na
połączonych siecią komputerach. System będzie przejrzysty (ang.
transparent), co oznacza, że fakt jego rozproszenia nie będzie z
zewnątrz widoczny. Patrząc z boku, system będzie się zachowywał
jak pojedynczy program.
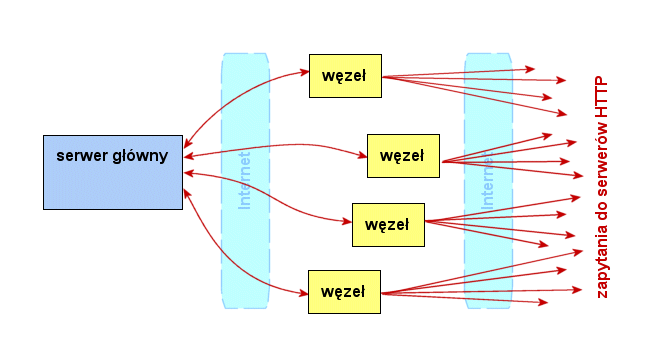
Programy sprawdzające strony WWW będą tworzyć scentralizowaną
sieć. Schemat połączeń w systemie pokazano na rys.
4.1. Punktem centralnym, sterującym działaniem całego
systemu, jest serwer główny. Zajmuje się on koordynowaniem pracy
węzłów: rozdziela pomiędzy nie strony do sprawdzania i odbiera
wyniki tego sprawdzania. Każdy z węzłów odbiera od serwera
głównego listę stron, łączy się z odpowiednimi serwerami WWW,
sprawdza, czy śledzone strony się zmieniły, po czym odsyła wyniki
do serwera głównego.
Rysunek 4.1:
Topologia systemu
 |
Scentralizowana struktura połączeń nie jest oczywiście jedyną,
która mogłaby być zastosowana przy budowie takiego systemu.
Spośród innych często wykorzystywanych topologii można by wymienić
pierścień z żetonem (ang. token-ring -- szereg równoważnych
komputerów połączonych w koło), sieć hierarchiczną (drzewo sieci
scentralizowanych -- węzeł może być jednocześnie ojcem podsieci)
czy sieć równoważną (ang. peer-to-peer -- komputery
połączone ze sobą bez wyraźnej struktury, komunikujące się
bezpośrednio). Istnieje także wiele kombinacji podstawowych
topologii. Mój wybór jest jednak uzasadniony tym, że
scentralizowana sieć ma następujące zalety:
- łatwość zaimplementowania -- czytelna topologia z jasno zdefiniowanymi rolami, dzięki temu algorytm równoważenia obciążenia będzie stosunkowo prosty,
- łatwość zarządzania -- serwer główny stanowi pojedynczy punkt administracji całym systemem,
- brak problemu spójności danych -- dane trzymane są w jednym miejscu,
- bezpieczeństwo -- scentralizowanie konfiguracji oraz danych ułatwia zapewnienie systemowi bezpieczeństwa.
Inne z wymienionych architektur nie mają przynajmniej części tych
plusów. Żadna z nich nie jest tak prosta do zaimplementowania oraz
administracji. Należy przy tym pamiętać, że łatwość
zaimplementowania danego rozwiązania nie jest jedynie kwestią
wygody programisty. Ma ona bezpośredni wpływ na możliwość
zastosowania i używania skutecznej strategii bezpieczeństwa, na
łatwość wprowadzania w przyszłości zmian w systemie itp.
Z wyborem architektury scentralizowanej wiążą się też pewne
minusy, o których należy pamiętać i tak zaprojektować oraz
zaimplementować system, aby ich efekty były minimalne. Jedną z wad
tej topologii jest ograniczona skalowalność. Do scentralizowanego
systemu nie można przyłączać bardzo dużej liczby węzłów, gdyż jego
wydajność zacznie być ograniczana przez przepustowość serwera
głównego. Jednak biorąc pod uwagę, że liczba węzłów nie przekroczy
kilkudziesięciu (por. punkt 3.3.2), można założyć, iż w
zupełności wystarczy jeden serwer główny.
Innym minusem scentralizowanej topologii jest mała odporność na
błędy. Wystarczy wyłączyć serwer główny, aby cały system przestał
działać. Problem ten jest w literaturze (np. [Tan02])
nazywany pojedynczym punktem błędu (ang. single point of
failure). Tej wady nie da się całkowicie ominąć, lecz należy
zminimalizować jej skutki, realizując wymagania omówione w punkcie
3.3.4. W szczególności oprogramowanie serwera głównego
będzie w stanie, po ponownym uruchomieniu, podjąć pracę w
przerwanym momencie. Projekt budowy programu głównego zamieszczono
w punkcie 4.5.
Wśród pożądanych cech systemów rozproszonych często wymienia się
także niemożność prostego wyłączenia systemu np. w efekcie
nacisków politycznych lub wyroków sądowych. Taką odporność
wykazują sieci równoważne, w których węzły komunikują się ze sobą
nawzajem bez pomocy żadnego wyróżnionego serwera. Przykładem tak
zbudowanych systemów jest Freenet oraz Gnutella. W przypadku
systemu sprawdzania stron WWW taka własność nie ma większego
znaczenia (trudno wyobrazić sobie przyczynę, dla którego serwis
musiałby zostać zamknięty z powodów prawnych). Przy innych
zastosowaniach biblioteki do rozdzielania zadań ta cecha mogłaby
się okazać pożądana. Niestety, w przypadku architektury
scentralizowanej zapewnienie takiej własności jest praktycznie
niemożliwe -- aby unieruchomić cały system, wystarczy wyłączyć
serwer główny.
3 Baza danych
Baza danych zawierać będzie informacje wykorzystywane zarówno
przez bibliotekę do przetwarzania rozproszonego, jak i kod
zajmujący się sprawdzaniem stron WWW. Informacje te będą ze sobą
powiązane relacjami. Cześć tabel, przechowująca ogólne informacje
o systemie, węzłach i zadaniach, będzie dostępna dla całego
systemu. Natomiast tabele z danymi specyficznymi dla wykonywanego
typu zadania wykorzystywane będą jedynie przez kod zajmujący się
realizacją tego zadania. Biblioteka do równoważenia obciążenia
oczywiście nie może się odwoływać do tabel opisujących konkretne
zadania, gdyż nie posiada na ich temat żadnych informacji. Tabele
te tworzy dopiero programista korzystający z gotowej, istniejącej
biblioteki.
Podstawowe tabele znajdujące się w bazie danych oraz relacje
między nimi przedstawiono w postaci diagramu DRD (ang.
Data Relationship Diagram) na rys. 4.2. Diagram ten
jest podzielony na dwie części: powyżej przerywanej linii znajdują
się tabele z ogólnymi informacjami o zadaniach, węzłach itp.
Struktura tej części bazy danych jest niezależna od typu
wykonywanego przez system zadania. W ich przypadku stosowałem
nazewnictwo angielskie. Natomiast poniżej niebieskiej linii widać
tabele związane konkretnie ze śledzeniem i sprawdzaniem stron WWW
- tabele te mają nazwy w języku polskim.
Rysunek 4.2:
Podstawowy schemat bazy danych
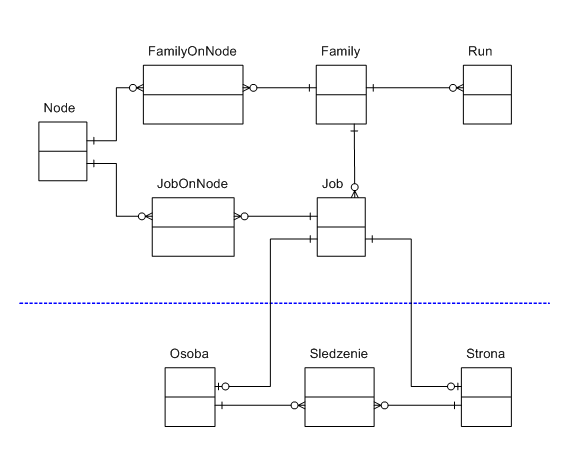 |
Tabele przedstawione na rys. 4.2 zawierają następujące dane:
- tabela Node - węzły podłączone do systemu,
- tabela Job - zadania (do rozdzielenia przez serwer główny i wykonania przed węzły),
- tabela JobOnNode - informacje o realizacjach danego zadania na danym węźle,
- tabela Family - grupy zadań,
- tabela FamilyOnNode - informacje, czy i pod jakimi warunkami dany węzeł nadaje się do realizacji danej grupy zadań,
- tabela Run - informacje o kolejnych cyklach realizacji zadań,
- tabela Osoba - użytkownicy serwisu,
- tabela Strona - strony śledzone przez użytkowników serwisu,
- tabela Sledzenie - informacja o tym, że dany użytkownik śledzi daną stronę.
Relacje pomiędzy tabelami to zwykle relacje typu "jeden do
zero-lub-wiele". Tabele FamilyOnNode, JobOnNode
oraz Sledzenie umożliwiają zaimplementowanie w bazie
danych połączeń typu "wiele do wielu" -- odpowiednio między
tabelami Family i Node, Job i
Node oraz Strona i Osoba. Tabele te
oprócz indeksów rekordów w tabelach nadrzędnych przechowują także
dodatkowe informacje. Przykładowo w tabeli Sledzenie
znajduje się pole od_kiedy, mówiące kiedy dany
użytkownik rozpoczął śledzenie danej strony.
Relacje typu "jeden do jednego" lub "jeden do zero-lub-jeden"
łączą tabelę Job z tabelami opisującymi szczegółowo dane
zadanie. W przypadku systemu sprawdzania stron są to tabele
Strona oraz Osoba. Tabela Strona
zawiera informacje niezbędne do sprawdzania strony WWW. Natomiast
tabela Osoba będzie przydatna do wysyłania powiadomień
(wysyłanie listów elektronicznych z informacją o zmianie stron
będzie drugim obok sprawdzania stron typem zadania wykonywanym
przez bibliotekę -- patrz punkt 5.3). Relacje
łączące te tabele są typu "jeden do zero-lub-jeden". W przypadku
relacji łączącej Job i Strona każdy rekord
w tabeli Strona ma odpowiednik w tabeli Job,
choć rekord w tabeli Job może nie być związany z żadnym
rekordem w tabeli Strona.
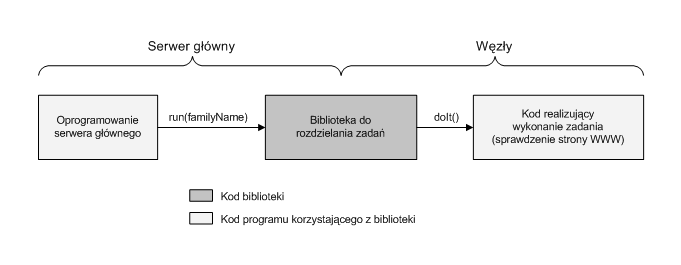
4 Biblioteka do rozproszonego przetwarzania zadań
Częściowo wyodrębnionym fragmentem systemu będzie biblioteka do
rozdzielania i rozproszonego przetwarzania zadań. Bibliotekę tę
nazwałem JODL od skrótu angielskiej nazwy Job
Dispatching Library. Biblioteka JODL nie jest programem
samym w sobie, oferuje ona jedynie pewną funkcjonalność. Programy
korzystające z biblioteki wywołują jej metody oraz podsuwają
bibliotece własne klasy z kodem realizującym zadania (i inne,
opisane w punkcie 4.4.2). Uproszczony
diagram interakcji pokazujący wykorzystanie biblioteki znajduje
się na rysunku 4.3.
Rysunek 4.3:
Diagram interakcji
 |
Biblioteka będzie działać w cyklach. Cykle mają kolejne numery,
zapisywane w tabeli Run. Pojedyncze uruchomienie metody
realizującej zadania z danej grupy (ang. family) to jeden
cykl, czyli jednorazowe wykonanie wszystkich zadań z tej grupy.
1 Zadania realizowane przez bibliotekę
Informacje o zadaniach będą trzymane w bazie danych (patrz punkt
4.3). W każdym cyklu biblioteka będzie pobierać z
bazy danych wszystkie zadania z danej grupy. Następnie każde z
zadań będzie wykonywane na odpowiednim węźle (sposób przydziału
zadań do węzłów jest opisany w punkcie
4.4.2). Wykonanie zadania z punktu
widzenia biblioteki polega na wywołaniu odpowiedniej metody.
2 Algorytm rozdzielania zadań
Główną częścią biblioteki do rozdzielania zadań stanowi algorytm
decydujący o przydziale poszczególnych zadań do węzłów systemu.
Przydział ten będzie dynamiczny z oczywistych, opisanych wcześniej
przyczyn. Algorytm musi wybrać węzeł dla zadania w dwóch
sytuacjach: gdy zadanie jest nowe, właśnie pojawiło się w
systemie, lub gdy istniejące już zadanie zmienia (z różnych
powodów) węzeł, na którym jest wykonane. Wraz z biblioteką
dostępna jest klasa implementująca prosty algorytm przydziału
zadań do węzłów. Wybiera ona węzeł, któremu najprawdopodobniej
najkrócej zajmie wykonanie danego zadania. Czasu tego nie da się
dokładnie wyliczyć ani nawet łatwo oszacować. Średni czas
realizacji z ostatnich cykli nie wystarcza, gdyż część zadań może
nie być wykonywana w każdym cyklu. Opieranie wyboru na liczbie już
przypisanych zadań do danego węzła jest niepewne z dwóch powodów:
wspomnianego wcześniej oraz różnych czasów wykonania
poszczególnych zadań. Ostatecznie, aby dokonać jak najlepszego
przydziału, algorytm przydziału ocenia każdy węzeł korzystając
równocześnie z wszystkich dostępnych informacji:
- liczby zadań przypisanych do danego węzła,
- częstotliwości realizacji każdego z zadań,
- średniego czasu wykonania zadań.
Oczywiście klasa z implementacją podstawowego algorytmu
przydzielania zadań do węzłów przy wyborze węzła nie może się
kierować żadną szczegółową wiedzą o danym zadaniu. Klasa ta takiej
wiedzy po prostu nie posiada, gdyż jest częścią ogólnej
biblioteki. Aby uzależnić przydział od konkretnego typu zadania,
programista może stworzyć klasę implementującą własny algorytm i
podstawić ją bibliotece zamiast klasy domyślnej. Przykładowo,
jeśli z jakiegoś powodu strony w domenie .org powinny być
sprawdzane zawsze przez arbitralnie wyznaczony węzeł, wystarczy
odpowiednio zaimplementować metodę przydziału zadań do węzłów,
uwzględniającą ten warunek. Własną klasę z implementacją tej
metody można podstawić tak, aby była wykorzystywana przy
rozdzielaniu wszystkich zadań lub np. zadań tylko z wybranej
grupy.
W określonych przypadkach istniejące zadanie, przypisane już do
jakiegoś węzła, może zostać na nowo przypisane do innego węzła.
Możliwe przyczyny takiej zmiany są następujące:
- węzeł, do którego zadanie było przypisane, przestał być dostępny,
- czas wykonania zadania w zależności od jego wielkości jest wyraźnie dłuższy niż średnia z wszystkich zadań,
- węzeł nie mógł zrealizować zadania,
- czas wykonania zadania pogorszył się w porównaniu z poprzednimi wykonaniami,
- w systemie pojawił się nowy węzeł, do którego trzeba przypisać część z istniejących zadań,
- biblioteka próbuje losowo zmienić przypisanie zadania w nadziei, że przyspieszy to jego wykonanie,
- w danym cyklu węzeł, do którego przypisane jest zadanie, wciąż realizuje swoje zadania, a inny węzeł wykonał już swoją pracę i jest wolny.
Zmiana przypisania zadania może być próbna lub stała. Zmiana
próbna to taka, która jest dokonywana tymczasowo, prawdopodobnie
jednorazowo. Przykładowo, gdy węzeł nie jest dostępny w danym
cyklu wykonywania zadań, jego zadania są przenoszone na inne
węzły. Ponieważ zmiana przypisań jest próbna, w momencie, gdy
węzeł ten zacznie działać ponownie, wrócą do niego zadania
wcześniej na nim wykonywane. Potraktowanie węzła, który zaczął
ponownie działać, jak nowego węzła świeżo podłączonego do systemu
byłoby błędne, gdyż wiązałoby się z utratą przypisań wypracowanych
przez przenoszenie zadań podczas poprzednich cykli. Natomiast do
nowego węzła zadania są przypisywane (najczęściej) losowo.
Zmiana próbna może zostać wycofana lub utrwalona (przejść na
zmianę stałą). Zmiana jest wycofywana, gdy węzeł poprzednio
wykonujący dane zadanie staje się ponownie dostępny i gdy okazuje
się, że nowy węzeł mniej efektywnie wykonuje to zadanie. Natomiast
zadanie zmienia węzeł na stałe, gdy poprzedni węzeł przestaje być
definitywnie dostępny lub gdy przeniesienie zadania okazuje się
być efektywne (tzn. zadanie jest wykonywane wyraźnie szybciej lub
skuteczniej na nowym węźle niż na starym).
Działanie algorytmu można modyfikować przez odpowiednią
zmianę jego ustawień i parametrów. Najważniejsze z nich to:
- jakie opóźnienie w wykonaniu zadania (w stosunku do średniego czasu wykonania) upoważnia do próby zmiany węzła,
- czy i jak często mają być dokonywane próby losowej zmiany przydziału,
- ile kolejnych prób należy przeprowadzić przed przeniesieniem zadania, gdy jego wykonanie się nie powiodło.
3 Protokół komunikacji wewnątrz systemu
Komunikacja w systemie będzie się odbywała pomiędzy serwerem
głównym a każdym z węzłów. Na tą komunikację składają się
następujące wiadomości:
- a.
- serwer inicjuje agenta (tzn. wysyła informacje o bazie danych, numerze cyklu, klasie realizującej zadanie itp.),
- b.
- serwer wysyła agentowi zadania, które mają być przez niego zrealizowane,
- c.
- agent odsyła serwerowi informacje o zadaniach, które wykonał,
- d.
- agent odsyła serwerowi informacje o zadaniach, których nie mógł zrealizować,
- e.
- serwer pyta agenta, ile zostało mu jeszcze zadań do wykonania,
- f.
- serwer prosi agenta o odesłanie części z zadań, które jeszcze nie zostały wykonane (aby móc je przekazać innemu agentowi).
Jak zostało już powiedziane w punkcie
4.1.4, podstawowym mechanizmem
komunikacji w systemie będą zdalne wywołania metod poprzez RMI.
Mechanizm ten w podstawowym użyciu zapewnia komunikację w jedną
stronę. Z powyższej listy typów przesyłanych wiadomości wynika, że
większość z nich jest inicjowana przez serwer. Jedynie informacje
o wynikach realizowania zadań są wysyłane z inicjatywy agenta
(punkty c. i d.). Czy potrzebna jest więc komunikacja w dwie
strony? Wydaje się, że nie ma takiej konieczności. Łatwiej z
punktu widzenia serwera będzie okresowo pytać każdego agenta o
wyniki, zamiast oczekiwać, że agent sam je odeśle w nieokreślonym
momencie. Punkty c. i d. można więc zmienić na następujące:
- c.
- serwer pyta agenta o wykonane już przez niego zadania,
- d.
- serwer pyta agenta o zadania, których agent nie mógł zrealizować.
Dzięki temu wszystkie typy komunikatów są inicjowane przez serwer.
Serwer, wywołując metody obiektów działających na węzłach, ma
kontrolę nad wymianą informacji w systemie.
4 Klasa serwera głównego
Główną klasą biblioteki jest klasa serwera, odpowiedzialna za
rozdzielanie zadań, wysyłanie ich do węzłów oraz odbieranie
wyników. Wykorzystanie biblioteki wiąże się z wołaniem metod tej
właśnie klasy. Prosty przykład wykorzystania jej możliwości
znajduje się w dodatku A, dlatego nie ma sensu go
powielać. Natomiast w tym punkcie chcę opisać wewnętrzny mechanizm
jej działania.
Klasa serwera głównego działa w jednym wątku. Udostępnia ona metodę, która zajmuje się:
- nawiązaniem połączenia z węzłami i zainicjowanie działających na nich agentów,
- wczytaniem z bazy danych zadań, które mają być zrealizowane.
Następnie w pętli są wykonywane następujące czynności:
- przypisanie agentów do zadań, które tego wymagają (np. są przypisane do nieistniejących węzłów),
- wysłanie do agentów nowo przypisanych im zadań,
- odebranie od agentów wykonanych przez nich zadań i usunięcie ich z lokalnej listy zadań do zrealizowania,
- odebranie od agentów zadań, które nie mogły zostać zrealizowane, i zakwalifikowanie ich do ponownego przypisania lub usunięcie ich z lokalnej listy zadań do zrealizowania,
- znalezienie agentów, którzy mają największa i najmniejszą liczbę zadań do wykonania i ewentualne przesunięcie części zadań do mniej zajętego agenta,
- sprawdzenie, czy któryś z agentów nie przekroczył określonego ograniczenia czasowego (ang. timeout) na wykonanie zadań i ewentualne odebranie mu części zadań i przekazanie ich innemu węzłowi,
- wykonanie próbnych zmian przypisania poszczególnych zadań w celu sprawdzenia czasu wykonania na innym węźle,
- przejrzenie czasów wykonania zrealizowanych właśnie zadań, sprawdzenie, czy któryś z czasów nie pogorszył się w porównaniu z poprzednimi wykonaniami i ewentualne przesunięcie zadania do wykonania w przyszłości na innym węźle.
Pętla ta działa do momentu, w którym lista zadań do zrealizowania
w tym cyklu będzie pusta. W ten sposób po zakończeniu działania
pętli wszystkie zadania są zrealizowane (bądź zostały podjęte
próby ich zrealizowania na więcej niż jednym węźle) oraz dokonano
zmiany przypisań zadań do węzłów tak, jak to opisano w punkcie
4.4.2.
Stan realizacji zadań jest na bieżąco zapisywany w bazie danych,
co pozwala w prosty sposób odtworzyć działanie klasy serwera głównego po jej
awaryjnym przerwaniu. Służy do tego będzie oddzielna metoda.
5 Aplikacja sprawdzająca strony WWW
Aplikacja sprawdzająca strony WWW i wysyłająca powiadomienia do
użytkowników jest głównym programem systemu CoNowego.pl,
działającym na serwerze głównym. Jest ona uruchamiana cyklicznie
(aktualnie raz na dobę). Podczas każdego uruchomienia aplikacja
sprawdza wszystkie śledzone przez użytkowników strony, a następnie
wysyła listy z powiadomieniami o zmianach zawartości stron. Kolejne
czynności wykonywane przez program to:
- inicjowanie programu, przygotowanie zadań sprawdzania stron,
- sprawdzanie śledzonych stron WWW przy użyciu biblioteki JODL,
- analiza wyników sprawdzania, przygotowanie zadań wysyłania powiadomień,
- wysyłanie powiadomień przy użyciu biblioteki JODL,
- zakończenie cyklu, wpisanie wyników do bazy danych, dealokacja zasobów.
Program serwer musi umieć sobie radzić z sytuacjami, gdy jego
działanie zostało przerwane w błędny sposób. W trakcie działania
po ukończeniu kolejnych czynności zapisuje on w bazie danych
odpowiednie informacje. W przypadku awaryjnego przerwania
działania i ponownego uruchomienia, program korzystając z
zapisanych informacji będzie w stanie kontynuować pracę w
przerwanym momencie. Dzięki analogicznej funkcjonalności w
bibliotece JODL, zaimplementowanej w metodzie
rerun(), w przypadku gdy działanie programu zostanie
przerwane w trakcie sprawdzania stron, przy ponownym uruchomieniu
sprawdzone zostaną tylko strony niesprawdzone wcześniej.
Sebastian Łopieński