Subsections
1 Dane testowe
Do przeprowadzenia testów potrzebowałem zbiór adresów istniejących
stron WWW. Strony te powinny przypominać swoją różnorodnością
strony odwiedzane (a więc i śledzone) przez użytkowników WWW --
oczywiście z punktu widzenia komputera, a nie zawartości w
rozumieniu ludzkim. Zależało mi więc na wykorzystaniu:
- różnych serwerów WWW (skrypt PHP przekazujący dokument HTML z tekstem podanym w parametrze, choć umożliwia wywołanie go na nieskończenie wiele sposobów i każdy przekazuje inny wynik, nie mógł spełnić tego warunku),
- różnych formatów dokumentów spotykanych w Internecie: HTML, XML, PDF, DOC, XLS itp. (w rzeczywistych proporcjach),
- plików o różnych wielkościach.
Uznałem, że najlepiej podane warunki będzie spełniać wynik
działania którejś z wyszukiwarek internetowych. Wybrałem serwis
Google (http://www.google.com), w którym szukałem stron
zawierających słowo ala. Google znalazł około 2 310 000
stron w Internecie zawierających tę frazę![[*]](footnote.png) . Stworzyłem dwa skrypty w języku
interpretatora poleceń bash. Pierwszy z nich, o nazwie
prepare_links, kolejno:
. Stworzyłem dwa skrypty w języku
interpretatora poleceń bash. Pierwszy z nich, o nazwie
prepare_links, kolejno:
- przy pomocy polecenia wget ściąga kolejne strony z wynikami wyszukiwania w serwisie Google (strona z wynikami zawiera maksymalnie 100 rezultatów),
- wyodrębnia z uprzednio ściągniętych stron same adresy URL przy pomocy polecenia sed oraz odpowiednich wyrażeń regularnych.
Natomiast drugi skrypt, nazwany links2db, tworzy
polecenia w języku SQL ("insert into ...") wstawiające
adresy do tabeli Strona. Oba skrypty są przedstawione w
dodatku B. W ten sposób stworzyłem bazę adresów
stron zawierającą 10 tys. pozycji. Z bazy tej korzystałem przy
wykonywaniu testów wydajnościowych systemu.
Celem pierwszego z wykonanych przeze mnie testów było zmierzenie
czasów sprawdzania stron WWW. Interesował mnie rozkład tych czasów
oraz czas minimalny, średni i maksymalny. Wiedza ta jest przydatna
między innymi przy szacowaniu obciążenia systemu oraz wyznaczaniu
dopuszczalnego czasu sprawdzania (ang. timeout). Aby
pomiar jak najbardziej odpowiadał rzeczywistości, strony powinny
być sprawdzane po kolei, w jednym wątku. Aby móc zaobserwować
faktyczny maksymalny czas sprawdzania stron, należało ustawić
długi dopuszczalny czas sprawdzania. W tym teście wynosił on 5
minut. Jeżeli w ciągu tego czasu nie udało się ściągnąć całej
strony (lub pierwszych 100 kilobajtów, jeśli jej rozmiar jest
większy), system uznawał, że strona jest niedostępna.
Test polegał na sprawdzeniu 10 tys. stron WWW. Ich adresy zostały
wygenerowane przy pomocy skryptów opisanych w punkcie
6.1. Było to pierwsze sprawdzanie tych stron, w bazie
danych nie było informacji o ich dacie ostatniej modyfikacji,
wielkości czy wyniku funkcji MD5. Oznacza to, że podczas
sprawdzania ściągane były całe strony, a nie tylko nagłówki
odpowiedzi HTTP.
W trakcie przeprowadzania testu udało się ściągnąć 9581 stron. W
przypadku pozostałych 419 stron system nie mógł nawiązać
połączenia z serwerem lub sprawdzany adres URL był błędny. Czas
sprawdzania był mierzony z dokładnością do 1/1000 sekundy.
Minimalny, średni i maksymalny czas ściągania i sprawdzania strony
wyniosły odpowiednio 1.007, 3.365 i 71.942 sekundy. Ściągnięcie
89% stron zajęło mniej niż 5 sekund. Rozkład liczby tych stron,
sprawdzonych w kolejnych dziesiątych sekundy, pokazany jest na
rys. 6.1.
Rysunek 6.1:
Czasy sprawdzania stron
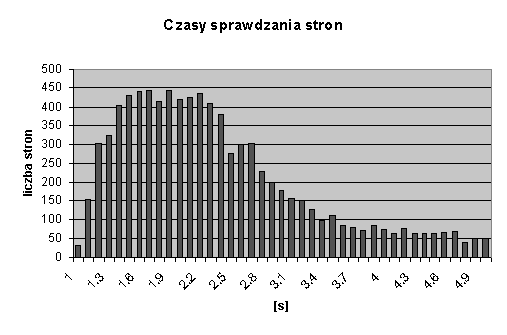 |
Ponieważ 30 sekund wystarczyło na ściągnięcie 99% stron, a
maksymalny czas sprawdzania wyniósł 72 sekundy, można przyjąć, iż
odpowiednią wartością dopuszczalnego czasu sprawdzania jest 60
sekund. Należy pamiętać, że podczas testu tylko jeden wątek
sprawdzał strony. W przypadku większej ich liczby należy
odpowiednio wydłużyć dopuszczalny czas sprawdzania.
Kolejnym pytaniem, na które należy znaleźć odpowiedź, jest pytanie
o liczbę wątków sprawdzających śledzone strony. Jaka liczba będzie
najbardziej odpowiednia, jaka zapewni największą wydajność.
Postanowiłem zmierzyć czas pracy systemu, w którym działa
kolejno 1, 2, 3, 5, 10, 15, 20, 25, 30, 40, 50, 70, 100, 150 i 200
wątków. Mierzyłem czas sprawdzania tysiąca identycznych adresów
URL. Dzięki temu, że w praktyce system sprawdzał na okrągło tę
samą stronę, znajdującą się na serwerze WWW podłączonym bardzo
szybkim łączem z programem sprawdzającym, na wyniki testu nie
wpłynęły czynniki zewnętrzne (różnice w czasie ściągania różnych
stron itp.). Dla danej liczby wątków pomiar powtarzałem 5 razy,
aby do analizy wziąć wartość uśrednioną.
Rysunek 6.2:
Czas sprawdzania stron w zależności od liczby wątków
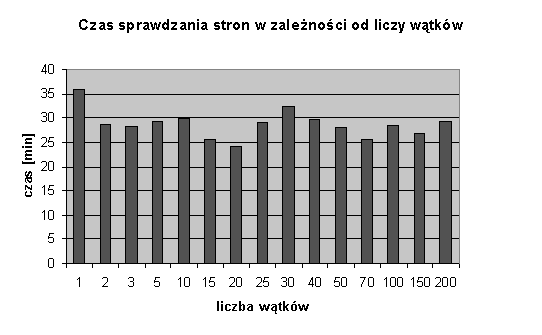 |
Po przeprowadzeniu testu okazało się, że liczba wątków nie ma
dużego wpływu na czas działania programu. Rysunek 6.2
przedstawia średnie czasy sprawdzania stron w zależności od liczby
wątków. Jedyną wyraźną różnicę w czasie widać dla programu
jednowątkowego -- działał on ok. 1/4 dłużej niż wynosiła
średnia dla programów z większą liczbą wątków. Przy okazji jednak
dało się zaobserwować niedoskonałości implementacyjne maszyny
wirtualnej Java. Przy dużej liczbie wątków (powyżej 50) program
sprawdzający strony od czasu do czasu przerywał swoje działanie.
Po zbadaniu przyczyn okazało się, że jest to problem
wykorzystywanej przeze mnie implementacji maszyny wirtualnej Java
na platformie Linux. W szczególności przerywanie działania
programu nie było spowodowane wyciekami pamięci czy błędnym
korzystaniem z mechanizmu wątków.
Biorąc pod uwagę wyniki testu, jak również zauważone błędy
implementacji maszyny wirtualnej Java, rozsądną liczbą wątków
wydaje się być wartość pomiędzy 5 a 25. Ostatecznie w uruchomionym
systemie śledzone strony są sprawdzane przez 20 wątków.
Trzeci z przeprowadzonych testów polegał na uruchomieniu systemu
na dwóch węzłach: jednym w Polsce oraz jednym w Szwajcarii. Węzły
te sprawdzały 1000 różnych stron WWW (sposób zdobycia ich adresów
opisano w punkcie 6.1), z których połowa znajdowała
się w domenie .pl. Początkowo sprawdzane strony WWW były
losowo rozdzielone pomiędzy oba węzły. Celem testu było
przekonanie się, czy i w jakim tempie zadania sprawdzenia stron w
domenie .pl będą przenoszone na węzeł umieszczony w
Polsce. Ciekawe też było, czy taki podział osiągnie stabilność.
Aby umożliwić migrację zadań pomiędzy węzłami, serwer główny był
uruchamiany 200 razy (a więc system pracował 200 pełnych cykli).
Natomiast współczynnik "przenosin" (czyli liczba zadań, które w
jednym cyklu system próbował przenieść na inny węzeł w stosunku do
liczby wszystkich zadań) wynosił 10%. Oznacza to, że w każdym
cyklu system przenosił 100 losowo wybranych stron na inny węzeł, a
następnie porównywał czasy sprawdzania na starym i nowym węźle i
utrwalał zmianę, jeśli była ona korzystna. Zmiana była uznawana
przez system jako korzystna, gdy zysk czasowy wynosił co najmniej
15%. Prawdopodobieństwo, że jakaś strona nie zostanie próbnie
przeniesiona na inny węzeł, jest praktycznie równe zeru (90%200 < 10-9). Aby zmniejszyć liczbę czynników
wpływających na wyniki eksperymentu, zostały zablokowane inne
powody przenoszenia zadań między węzłami (np. przenoszenie, gdy
jeden z węzłów skończy już realizowanie swoich zadań, a drugi
jeszcze pracuje).
Rysunek 6.3:
Zmiany węzłów
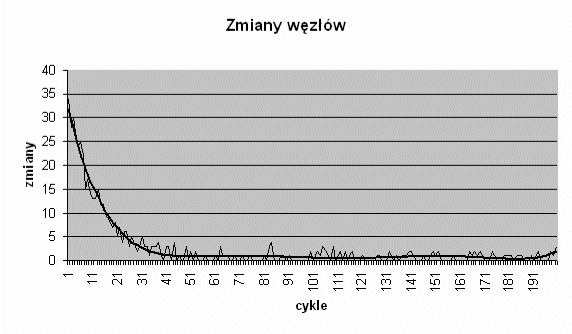 |
Cienka linia na rysunku 6.3 łączy punkty przedstawiające
liczbę korzystnych zmian przypisań zadań do węzłów w kolejnych
cyklach. Gruba linia na wykresie to linia trendu. W pierwszym
cyklu system dokonał 34 efektywne zmiany (na 100 zmian próbnych).
Jak można było przypuszczać, liczba korzystnych zmian dokonywanych
w następnych cyklach wyraźnie maleje. Od około 40. cyklu liczba
zmian w każdym kolejnym cyklu nie przekracza 4. Średnia liczba
zmian dla cykli od 31. do 40. wynosi 2.33, od 41. do 50. cyklu --
1.4, od 51. do 60. -- 0.55, a dla cykli od 51. do 200. średnia
ta osiąga wartość 0.67. Można więc przyjąć, że podział zadań w
przeprowadzonym teście osiągnął stabilność po około 40-50 cyklach.
Podczas testu system dokonał w sumie 528 zmian przypisań zadań do
węzłów. Niektóre zadania były przepisywane z jednego węzła na
drugi więcej niż raz. W efekcie po 200 cyklach 346 zadań zostało
przeniesionych na inny węzeł, a reszta pozostała na swych
początkowych węzłach.
Po przeprowadzeniu testu zainteresowało mnie również, o ile
szybciej zadania są wykonywane na efektywniejszych węzłach.
Przypomnijmy, że zmiana była utrwalana, jeśli zysk w czasie
realizacji zadania na nowym węźle w porównaniu do poprzedniego
wynosił co najmniej 15%. W ostatnim cyklu czas sprawdzania
wszystkich stron był równy 87% czasu sprawdzania w pierwszego
cyklu -- oznacza to zysk rzędu 13%. Biorąc pod uwagę jedynie
zadania, które zostały choć raz przeniesione na inny węzeł, zysk
ten wyniósł 23%. Wynika z tego, iż przenoszenie pomiędzy węzłami
zadań sprawdzania śledzonych stron ma wyraźny (choć nie kluczowy)
wpływ na wydajność całego systemu. Przenoszenie zadań pomiędzy
węzłami jest realizowane przez serwer główny, więc nie ma
większego wpływu na czas pracy węzłów.
Sebastian Łopieński