7.1 Wprowadzenie
7.2 Organizacja prosta (wolumeny sekwencyjne)
7.3 Wolumeny pasemkowane
7.4 Uwagi na temat innych rodzajów wolumenów
7.5 Wydajność różnego rodzaju wolumenów
7.6 Podsumowanie
Ten rozdział jest poświęcony różnym sposobom realizacji podstawowych funkcji warstwy operacyjnej systemu, związanych z odczytem i zapisem wirtualnych wolumenów.
W pierwszej części rozdziału rozważamy różne sposoby realizacji dwóch podstawowych organizacji wykorzystanych w systemie autora: organizacji prostej, czyli tzw. wolumenów sekwencyjnych (7.2) oraz RAID0, czyli tzw. wolumenów pasemkowanych (7.3), po czym dokonujemy bardzo pobieżnego przeglądu wybranych zagadnień związanych z pozostałymi rodzajami wolumenów (7.4). Powodem, dla którego spośród możliwych organizacji RAID główną uwagę poświęcamy wolumenom RAID0 jest to, iż z punktu widzenia potrzeb klienta systemu właśnie organizacja RAID0 ma największe znaczenie, o czym najlepiej świadczy fakt, iż ten właśnie rodzaj wolumenów został uznany przez zespół projektowy (w ramach którego autor planował implementacje) za najbardziej priorytetowy113.
W ostatniej części rozdziału przedstawiamy testy wydajności wolumenów. Skupiamy się przy tym głównie na wolumenach pasemkowanych, ewentualnie dodając tu i ówdzie, dla porównania, wyniki testów wydajności wolumenów sekwencyjnych lub fizycznych nośników (dysków) wykorzystanych w testach. Nie analizujemy pozostałych rodzajów wolumenów, gdyż nie zostały one przez autora zaimplementowane114. Testy wolumenów pasemkowanych dotyczą głównie wydajności operacji odczytu. Autor, z powodu ograniczonej ilości czasu i środków, nie mógł przeprowadzić analizy obu rodzajów operacji. Ponieważ w praktycznych zastosowaniach, m. in. w bazach danych, właśnie wydajność odczytu jest głównym czynnikiem decydującym o sprawności systemu115, autor skupił się właśnie na tej operacji. Operacje zapisu wolumenów (Serwer-RAID0, Klient-RAID0 i sekwencyjnych, patrz 7.3.2) autor wprawdzie zaimplementował, lecz nie zostały one dokładnie przetestowane pod kątem wydajności, dlatego dalej znajdziemy jedynie opis realizacji.
Operacje odczytu i zapisu dla wolumenów o nietrywialnych organizacjach bazują na operacjach dla wolumenów o organizacji prostej. Schemat realizacji tych ostatnich, poza drobnymi szczegółami, nie różni się od schematu przedstawionego w punkcie 4.4.4. Różnica polega na wprowadzeniu wsparcia dla wielu węzłów. Dodatkowo pojawia się koncepcja żądań zdalnych, tzn. wykonywanych przez inny węzeł niż ten, który odebrał żądanie klienta i odsyła klientowi wyniki. Dzięki wprowadzeniu żądań zdalnych (nazwiemy je tak dla odróżnienia od zwykłych żądań, które z kolei nazwiemy żądaniami lokalnymi) będziemy mogli konstruować bardziej skomplikowane organizacje wolumenów bazując na tych podstawowych typach żądań.
Należy tutaj wyjaśnić jedną kwestię. Otóż słowo żądanie pojawia się w tekście w dwóch znaczeniach. Raz mówimy o żądaniu jako o komunikacie wysłanym przez klienta (dla ustalenia nazwijmy je dalej wirtualnym żądaniem albo żądaniem klienta), innym razem mówimy o żądaniu jako obiekcie z punktu widzenia serwera, podlegającym przetwarzaniu i krążącym w strukturach serwera. Gdy wirtualne żądanie wysłane przez klienta zostanie odebrane przez wątek odbierający serwera, wówczas serwer tworzy obiekt (reprezentujący to żądanie na serwerze), który będzie podlegał przetwarzaniu. Obiekt ten reprezentuje sesję wykonania żądania (patrz 5.3.1). Obiekt ten ma kilka wersji: żądanie lokalne, żądanie zdalne, żądanie Serwer-RAID0. Każda wersja obiektu oznacza nieco inne przetwarzanie i drobne różnice w protokole klienta z serwerem. Wersja obiektu żądanie jest ustalana na podstawie rodzaju wolumenu (sekwencyjny, RAID0, zaś w obrębie RAID0 również w zależności od rodzaju algorytmu: Serwer-RAID0, Klient-RAID0 itd.), rozmiaru żądania (dla wirtualnych żądań do wolumenów RAID0, które dotyczą danych znajdujących się na jednym dysku, mogą być tworzone obiekty typu żądanie lokalne lub żądanie zdalne), lokalizacji danych względem odbiorcy żądania (lokalne lub zdalne).
Dalej w tekście będziemy również mówić żądanie lokalne o żądaniach do wolumenów sekwencyjnych, których dane znajdują się na węźle odbierającym żądanie (czyli które serwer odwzorowuje wewnętrznie, w celu obsługi, na obiekty typu żądanie lokalne), żądanie zdalne o żądaniach klientów do wolumenów sekwencyjnych wysłanych do niewłaściwego węzła i realizowanych w ten sposób, że węzeł obierający żądanie pośredniczy w transmisji danych, a żądanie RAID0 o żądaniach skierowanych do wolumenów typu RAID0.
Żądaniem lokalnym nazwiemy żądanie do wolumenu sekwencyjnego, które jest obsługiwane przez ten sam i wyłącznie przez ten jeden węzeł, który odebrał żądanie od klienta (patrz 7.2).
W związku z podanym wcześniej założeniem o nierozróżnialności węzłów serwera, klient może wysłać żądanie otwarcia wolumenu do dowolnego z węzłów serwera. Poza tym, z uwagi na możliwość dezaktualizacji wskazówek (patrz kolejny rozdział), również inne rodzaje operacji (odczyt, zapis itp.) mogą trafić do innego węzła niż ten, który zawiera fizyczne dane116.
W przypadku żądań zapisu i odczytu danych, problem dotyczy tak naprawdę rekonfiguracji i jest rozważany w kolejnym rozdziale. W naszym systemie przyjmujemy (opisaną w punkcie 8.2.3.1) metodę bezpośrednią, w której węzeł serwera, otrzymawszy żądanie do wolumenu znajdującego się na innym węźle, odsyła kod błędu zły węzeł wraz z załączoną nazwą poprawnego węzła. Klient, odebrawszy taki komunikat, uaktualnia swoje wskazówki i ponawia żądanie, cyklicznie, albo w nieskończoność, albo pewną ustaloną maksymalną liczbę razy.
W przypadku żądania otwarcia zwykłego wolumenu (o organizacji prostej) mamy zasadniczo dwie możliwości:
Autor zastosował to drugie rozwiązanie. Jest ono prostsze i szybsze, ponadto umożliwia uniknięcie wplatania semantyki transakcyjnej i koordynacji między węzłami do warstwy operacyjnej (w implementacji autora jedynie warstwa administracyjna wykorzystuje transakcje i zawiera mechanizmy koordynacji międzywęzłowej), co znacznie upraszcza tę warstwę.
Żądaniem zdalnym nazwiemy takie żądanie, które jest fizycznie realizowane117 na innym węźle niż ten, który odebrał żądanie od klienta (i, w związku z tym, odsyła mu także wyniki).
Żądania zdalne zostały wprowadzone na potrzeby realizacji organizacji Serwer-RAID0 (omówionej w punkcie 7.3.2). Żądania zdalne nie są nigdy generowane przez klienta, lecz wewnętrznie przez węzły serwera. Węzeł serwera, po odebraniu od klienta żądania odczytu, które dotyczy danych znajdujących się na innym węźle, może wewnętrznie podmienić je na żądanie zdalne i dalej je realizować jako takie. Z punktu widzenia klienta żądania zdalne nie różnią się od normalnych, więc klient realizuje wówczas żądania zdalne tak, jakby realizował oryginalne żądanie (to, które wysłał).
Żądania zdalne, oprócz sytuacji, w której klient wysyła żądanie dotyczące wolumenu sekwencyjnego pod niewłaściwy adres (wtedy węzeł może pośredniczyć w realizacji), pojawiają się także np. w implementacji Serwer-RAID0. Tam dane klienta mogą znajdować się częściowo na lokalnej maszynie, częściowo na innej, jednej lub kilku. Szczegóły realizacji takich żądań są omówione w punkcie 7.3.4.1, natomiast tutaj wspomnimy tylko, że w takiej sytuacji węzeł wewnętrznie tworzy sobie zbiór pod-żądań, zarówno lokalnych, jak i zdalnych, dotyczących fragmentów odczytywanego lub zapisywanego obszaru, i realizuje je jednocześnie. Również w tym przypadku klient rozmawia cały czas z tym samym węzłem i nie zdaje sobie sprawy z istnienia pod-żądań.
Realizacja zdalnego żądania odczytu
Zauważmy, że ponieważ węzeł zdalny nie odróżnia żądania klienta od żądania innego węzła, to w przypadku, gdy danych tam nie będzie (np. w wyniku rekonfiguracji, która mogła przenieść je gdzie indziej), on również może być pośrednikiem i pobrać dane z innego węzła. Łańcuch węzłów pośredniczących może być dowolnie długi.
Realizacja zdalnego żądania zapisu
Oba algorytmy dotyczą tylko najprostszego przypadku, gdy żądanie zdalne zostało wygenerowane na podstawie źle zaadresowanego (tzn. wysłanego do niewłaściwego węzła) żądania dotyczącego wolumenu sekwencyjnego. Realizacja żądań zdalnych generowanych w implementacji Serwer-RAID0 jest bardzo podobna. Szczegóły przedstawiono w punkcie 7.3.4.1.
W organizacji RAID0 wirtualna przestrzeń adresowa wolumenu jest odwzorowana na kilka fizycznych dysków w ten sposób, że pierwsze N wirtualnych bloków jest odwzorowane na pierwsze N bloków pierwszego dysku, kolejne N wirtualnych bloków na pierwsze N bloków drugiego dysku itd., po czym, po N pierwszych blokach ostatniego dysku w wirtualnej przestrzeni adresowej następuje drugie N bloków pierwszego dysku, dalej drugie N bloków drugiego dysku itd. Parametr N, tzw. rozmiar pasemka (ang. striping unit), jest dobierany w zależności od zastosowań. Na każdym z fizycznych dysków zbiór bloków, na który odwzorowane są jakieś bloki wirtualne, nazywamy kolumną RAID0.
Organizacja RAID0 jako jedyna spośród organizacji RAID nie zwiększa odporności na awarie. Przeciwnie, prawdopodobieństwo awarii zbioru dysków jako całości rośnie wykładniczo z liczbą użytych dysków.
Powodem stosowania tej organizacji jest wzrost wydajności, osiągnięty dzięki następującym cechom:
Jak już wspomniano, cięcie dużych żądań na mniejsze, wykonywane równolegle, nie musi być jednak korzystne w każdej sytuacji.
Powodem tego są dwa fakty:
Załóżmy teraz, że mamy dwa identyczne dyski (lub więcej) i żądanie o ustalonej wielkości, które dzielimy na jednakowe fragmenty, skierowane do każdego z tych dysków (po jednym do każdego), tak, aby fragmenty te były wykonywane równolegle. W tym przypadku konsekwencje dwóch wyżej wymienionych faktów będą m. in. następujące:
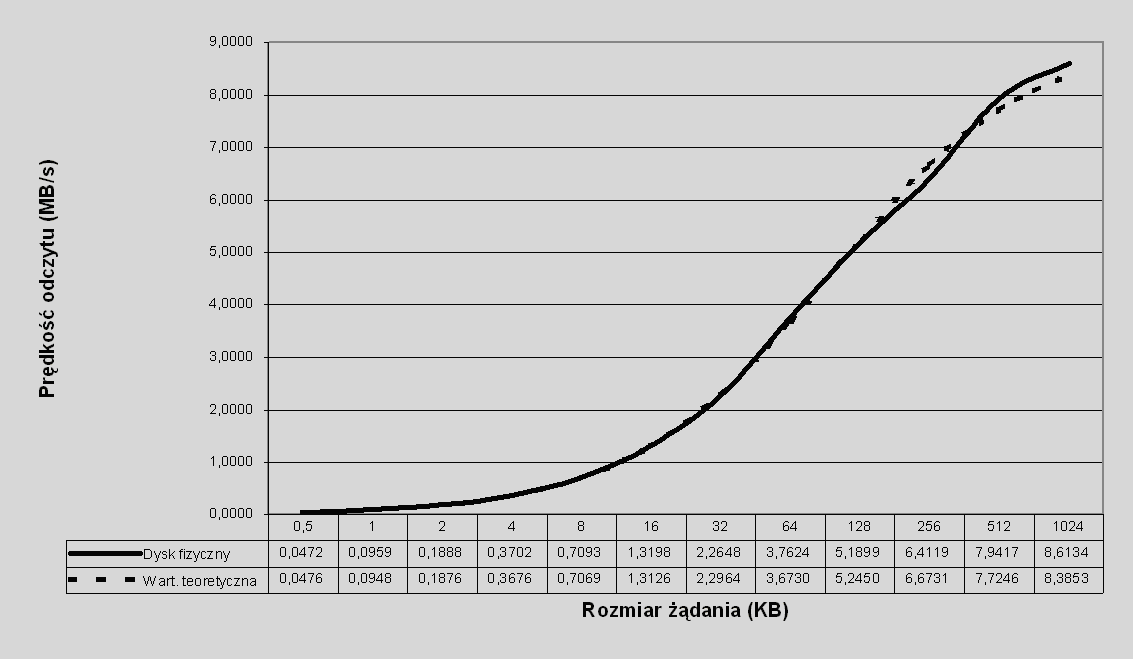
Zobrazujmy wymienione wyżej fakty. Przykładowa funkcja czasu wczytywania danych z dysku, dla dysków zastosowanych w testach omawianych w tej pracy, przedstawiona jest na rys. 7.1. Test przeprowadzono na identycznej konfiguracji sprzętowej jak opisana w punkcie 7.5.1.2.
Rys. 7.1 Przepustowość przy odczycie z dysku fizycznego w zależności od rozmiaru żądania: wartość rzeczywista i wartość przewidywana przez prosty model.
Wartości teoretyczne reprezentowane przez linię przerywaną są (średniokwadratowym) przybliżeniem opartym na modelu120, zgodnie z którym czas odczytu z dysku jest funkcją liniową, w której czynnik stały reprezentuje czas pozycjonowania głowicy (niezależny od rozmiaru żądania), zaś czynnik zmienny – przepustowość przy odczycie danych. Jak widać, model ten dobrze pasuje do faktycznych danych.
Wymienione wyżej dwa aspekty (zrównoleglenie wykonania a korzyści skali), obok kwestii obciążenia klienta systemu, będą głównym punktem zaczepienia w dyskusji na temat wydajności w punkcie 7.5.
W tradycyjnych systemach znane są dwa sposoby realizacji organizacji RAID0, sprzętowy i programowy. W obu przypadkach mechanizm jest taki sam: wirtualne żądanie rozbijane jest (zgodnie z definicją odwzorowania RAID0 i rozmiarem pasemka) na kilka żądań skierowanych do konkretnych fizycznych urządzeń. Podobnie odpowiedzi są zbierane i konsolidowane w jedną odpowiedź na wirtualne żądanie. Różnica wynika jedynie z tego, że w jednym przypadku zajmuje się tym sprzętowy kontroler (tzw. hardware-RAID), a w drugim przypadku system (tzw. software-RAID). W przypadku naszego systemu klastrowego oczywiście również można wykorzystać sprzętową macierz RAID lub programowe RAID oparte na dyskach jednego z węzłów systemu i realizowane przez lokalny system operacyjny, ale z punktu widzenia naszych rozważań nie są to przypadki interesujące.
W odróżnieniu od systemów tradycyjnych, system klastrowy umożliwia (programową) realizację RAID0 rozpiętego na wielu węzłach, tzn. stworzenie wirtualnego wolumenu opartego na dyskach fizycznych należących do różnych węzłów serwera. Istnieje co najmniej kilka sposobów implementacji, różniących się sposobem współpracy klienta z serwerem i węzłów w obrębie serwera:
Pomijamy tutaj wszelkie rozwiązania, które naruszają (wspomniane wcześniej) podstawowe postulaty konstrukcji serwera, w szczególności postulat, aby fizyczne zasoby serwera były ukryte przed klientem oraz aby wszystkie węzły były z punktu widzenia klienta jednakowe.
Opisane w p. 7.3.2 sposoby implementacji RAID0 będą się oczywiście różnić pod względem szybkości działania (opisane to zostanie w punkcie 7.5) i właśnie ten parametr jest podstawowym (choć, oczywiście, nie jedynym121) kryterium decydującym o praktycznej przydatności danego algorytmu, natomiast teraz wyliczymy niektóre inne różnice i związane z nimi zagadnienia.
Obciążenie klienta systemu jest, oprócz szybkości działania, najważniejszym spośród kryteriów decydujących o przydatności danego algorytmu. Jeżeli wziąć pod uwagę wydajność całego systemu, obejmującego nie tylko serwer, ale także klientów, którzy najczęściej także są serwerami (aplikacji, bazy danych itp.), to można uznać obciążenie klienta za kolejny, obok szybkości działania, parametr określający wydajność wolumenu122.
O obciążeniu klienta decydują następujące czynniki:
Właśnie powyższe czynniki leżą u podstaw koncepcji algorytmu Klient/R-RAID0. Algorytm ten, w porównaniu ze zwykłym Klient-RAID0, ma następujące cechy:
Wadą tego algorytmu jest to, że niezależnie od tego, czy jest to konieczne, czy nie, komunikat z żądaniem wysyłany jest do wszystkich węzłów. Problem ten rozwiązuje Klient/U-RAID0. Jeszcze dalej idzie rozwiązanie Klient/C-RAID0, eliminując niepotrzebne przerwania na kliencie. To ostatnie rozwiązanie jest najlepszym wariantem Klient-RAID0, jaki można uzyskać pod względem odciążenia maszyny klienta: klient wykonuje szczątkowe obliczenia, wysyła jeden komunikat (choć jest to wysyłanie grupowe), odbiera jedno przerwanie. Wadą tego rozwiązania (w stosunku do zwykłego Klient-RAID0) jest jego złożoność, co wpływa na sposób obsługi błędów i rekonfigurację (patrz p. 7.3.3.2).
Pozostałe rozwiązania (Serwer-RAID0 i Klient/Serwer-RAID0), pod względem obciążenia maszyny klienta, są praktycznie równoważne rozwiązaniuKlient/C-RAID0.
Wolumeny typu Klient/R-RAID0 wydają się gorszym rozwiązaniem od zwykłych wolumenów typu Klient-RAID0, gdyż wprowadzają dodatkowy narzut w operacji odczytu: albo więcej przerwań na maszynie klienta, albo synchronizację między węzłami serwera. Z drugiej strony, operacja zapisu jest bardziej efektywna. Dosyć rozsądną opcją wydaje się połączenie tych rozwiązań i wykonywanie operacji odczytu zgodnie ze scenariuszem Klient-RAID0, a zapisu zgodnie ze scenariuszem Klient/R-RAID0.
Duża złożoność operacji w przypadku wymienionych algorytmów będzie konsekwencją np. następujących własności, z których każda jest źródłem utrudnień z punktu widzenia obsługi sytuacji awaryjnych (oczywiście przykłady można mnożyć, tutaj wymieniamy tylko trzy, zdaniem autora, najistotniejsze):
Oprócz tego za element komplikujący uznamy obecność wskazówek, gdyż stanowi to dodatkowe utrudnienie z punktu widzenia rekonfiguracji systemu (patrz rozdział 8).
Wykorzystanie wskazówek pozwala na uniknięcie niepotrzebnego pośredniczenia jednych węzłów w dostępie do innych i związanego z tym narzutu.
Autor zbadał ten narzut doświadczalnie, porównując czas realizacji żądań odczytu skierowanych do wolumenów o organizacji sekwencyjnej w dwóch eksperymentach: w pierwszym eksperymencie żądania wysyłane były do węzła zawierającego dane, natomiast w drugim żądania wysyłane były do innego węzła, wymuszając pośrednictwo tego węzła w dostępie do danych. Eksperymenty prowadzone były w taki sposób, aby odczytywane dane znajdowały się już w schowku, tzn. zapewniona była 100% skuteczność schowka (patrz 7.5.1.3 oraz 7.5.1.5), ponieważ autor spodziewał się narzutu o rzędy wielkości mniejszego niż czas odczytu danych z dysku.
We wszystkich przypadkach (dla wszystkich rozmiarów żądań) narzut związany z pośredniczeniem był bardzo bliski 50%. Pozwala to oszacować, że np. w przypadku wolumenu typu Serwer-RAID0 zdefiniowanego na N węzłach i odczytu bloków ze schowka, gdyby wysyłać wszystkie żądania do ustalonego węzła, narzut byłby w przybliżeniu równy 50*(1 – 1/N) %, czyli, dla większej liczby węzłów, znów około 50%. Oczywiście w przypadku odczytu z dysku narzut ten będzie miał małe znaczenie.
Dodatkowym aspektem jest to, że fakt pośredniczenia niektórych węzłów w realizacji żądań dodatkowo je obciąża, opóźniając realizację innych żądań (zajmując procesor, wymuszając dodatkowe przełączenia kontekstu), więc można się spodziewać, że przy dużych obciążeniach spadek wydajności będzie jeszcze większy niż wynikałoby to z załączonych wyżej prostych wyliczeń.
Wczesne odsyłanie danych w Serwer-RAID0 w założeniu ma pozwolić na skrócenie średniego czasu wykonania żądania. W czasie gdy dane z niektórych węzłów jeszcze napływają, część danych może już zostać odesłana do klienta. Dodatkową zaletą jest to, iż wcześniej zwalnia się pamięć i struktury danych na danym węźle serwera, co pozytywnie wpływa na wydajność tego węzła (zobaczymy to w p. 7.5 przy okazji omawiania przepustowości – zbyt duża liczba żądań w strukturach serwera obniża wydajność).
Dodatkowym aspektem tego zagadnienia jest to, iż w sieci Giganet (a przynajmniej w oprogramowaniu komunikacyjnym użytym w tym projekcie), z uwagi na pewne ograniczenia sprzętowe i programowe, nie jest możliwe przesyłanie danych większych niż 32KB i każda większa porcja danych jest wewnętrznie rozbijana (przez warstwę komunikacyjną) na mniejsze fragmenty (por. 4.8). Zarazem rozmiar pasemka prawie zawsze przyjmuje wartości większe niż 32KB (przynajmniej w systemach tradycyjnych, typowa wielkość to 64KB; uzasadnienie tego w naszym systemie klastrowym znajduje się w p. 7.5), a zatem wykonując wczesne odsyłanie danych, nie tracimy korzyści skali (por. 7.3.1). Usprawnienie to ma zatem same zalety.
Jak już wcześniej wspomniano (p. 7.2.2), realizując żądania do wolumenów tego typu wykorzystuje się tzw. żądania zdalne. Realizacja tych żądań, podobnie jak żądań lokalnych, różni się minimalnie od przedstawionej wcześniej.
Żądania do wolumenów typu Serwer-RAID0, z punktu widzenia klienta systemu, nie różnią się specjalnie od innych rodzajów żądań. Protokół klient-serwer jest ustalony, operacje odczytu i zapisu mają przebieg opisany w punkcie 4.4.4.2. Jedyną różnicą w przypadku wolumenów typu Serwer-RAID0 jest to, że w drugiej fazie dwufazowej operacji zapisu klient, zamiast wysyłać całe dane w jednej paczce, wysyła wiele paczek danych, zawierających fragmenty pocięte według rozmiaru pasemka. Wszystkie pozostałe elementy protokołu odczytu i zapisu są identyczne jak w najprostszym przypadku (dla wolumenów o organizacji prostej).
Węzeł serwera odbiera więc żądanie do wolumenu Serwer-RAID0 tak, jak każde inne żądanie, po czym przechodzi do tworzenia obiektu, który będzie reprezentował to żądanie w strukturach procesu schowka. Obiekt ten niekoniecznie będzie jednak reprezentował żądanie Serwer-RAID0 (którego realizacja opisana jest niżej), podobnie jak żądanie do zwykłego sekwencyjnego wolumenu niekoniecznie musiało być żądaniem lokalnym. Utworzenie obiektu reprezentującego żądanie poprzedza bowiem sprawdzenie, czy obszar, którego ono dotyczy, znajduje się w całości na jednym z węzłów. Jeżeli tak jest, to tworzy się wewnętrznie albo żądanie lokalne (z odpowiednio przeliczonymi adresami) do odpowiedniego urządzenia (spośród tworzących wolumen RAID0) zawierającego dane do odczytania, albo żądanie zdalne. W przypadku żądania lokalnego, jest ono już żądaniem do fizycznego urządzenia, nie do wirtualnego wolumenu, natomiast w przypadku żądania zdalnego, jest ono nadal żądaniem do tego samego wirtualnego wolumenu, tyle, że skierowanym do zawężonego obszaru i wysłanym do innego węzła. Węzeł, który je otrzyma, stwierdzi, że odnosi się ono do jego lokalnych zasobów i z kolei odwzoruje je sobie wewnętrznie na swoje własne żądanie lokalne (z odpowiednio przeliczonymi adresami) do lokalnego urządzenia. Ostatecznie więc żądanie odebrane od klienta zostanie ostatecznie, czy to na węźle, który je odebrał, czy na zdalnym węźle, do którego zostało skierowane, odwzorowane na żądanie do jakiegoś lokalnego dysku, z adresami przeliczonymi tak, aby wskazywały właściwy obszar na tym urządzeniu. Realizacja żądania przebiega w tej sytuacji tak samo, jak opisaliśmy to wcześniej (p. 7.2.1 oraz 7.2.2) dla żądań lokalnych i zdalnych. Zauważmy, że we wcześniej opisanych algorytmach odczytu i zapisu dla żądań zdalnych nie musielibyśmy zakładać, że żądanie wysyłane przez węzeł pośredniczący do innego węzła jest żądaniem do zwykłego wolumenu.
Nieco bardziej złożone jest przetwarzanie w przypadku, gdy żądania klienta nie da się odwzorować na pojedyncze żądanie lokalne lub zdalne i przetwarzać tak, jak opisano wcześniej. Wówczas węzeł, który odebrał żądanie klienta tworzy wewnętrznie obiekt typu żądanie Serwer-RAID0, a następnie, dla kolejnych fragmentów odczytywanego lub zapisywanego obszaru, tworzy obiekty typu żądanie lokalne lub żądanie zdalne, zupełnie tak samo, jak opisaliśmy w poprzedzającym akapicie, żądania lokalne do odpowiednich fragmentów odnoszą się do lokalnych urządzeń i mają adresy już przeliczone na obszary tych urządzeń, zaś żądania zdalne są nadal żądaniami do tego samego wirtualnego wolumenu, z adresami odnoszącymi się do zawężonego obszaru w tym wolumenie. Obiekty żądań lokalnych i zdalnych, po stworzeniu, zostają zebrane w listę i powiązane z obiektem typu żądanie Serwer-RAID0. Następnie rozpoczyna się realizacja wszystkich pod-żądań (żądań z listy).
Przebiega ona tak, jak opisano wcześniej, ale z małymi wyjątkami:
A oto szczegóły realizacji dla operacji odczytu i zapisu.
Realizacja żądania odczytu w wersji Serwer-RAID0
Dla wszystkich pod-żądań równocześnie realizujemy wszystkie kroki algorytmu odczytu opisanego w punktach 4.4.4, 4.4.5 (żądania lokalne) i 7.2.2 (żądania zdalne). Dla żądań zdalnych rezerwujemy w pamięci bufory na dane, które zostaną odczytane z innych węzłów, generujemy żądania odczytu RDMA do innych węzłów, czekamy na odbiór danych, przesyłamy dane do klienta i ostatecznie zwalniamy przydzielony bufor. Dla żądań lokalnych postępujemy tak, jak opisano w 4.4.5.
Jedyna różnica polega na tym, że wszystkie pod-żądania oprócz ostatniego (tego, dla którego jako ostatniego będziemy wysyłać dane, co niekoniecznie musi mieć jakikolwiek związek ze względnym uporządkowaniem obszarów, których te żądania dotyczą) realizowane są jako tzw. depozyt, tzn. dane wysyłane są operacją RDMA do odpowiedniej części bufora klienta, ale klient nie otrzymuje przerwania. Dopiero przy ostatnim żądaniu wykonywana jest normalna operacja wyślij i klient dowiaduje się o odebraniu danych.
Zauważmy, że w tym algorytmie dane z części odczytywanego obszaru odbierane od kolejnych węzłów przesyłane są do klienta od razu, w kolejności, w jakiej nadchodzą. Przypomnijmy, że własność tę omówiliśmy już wcześniej (7.3.2) i nazwaliśmy wczesnym odsyłaniem.
Alternatywą byłoby:
Jak już wspomnieliśmy wcześniej, takie rozwiązanie miałoby gorszą wydajność.
Realizacja żądania zapisu w wersji Serwer-RAID0
Żądanie zapisu Serwer-RAID0 może być realizowane tylko w wersji przygotuj-odbierz, nie można wykorzystać mechanizmu RDMA.
Realizacja przebiega według następującego scenariusza:
Zauważmy, że w tym przypadku, inaczej niż w operacji odczytu, wysyłamy dane w jednym kawałku, podczas gdy przy odczycie stosowaliśmy wczesne odsyłanie. Zastosowanie podobnej metody tutaj wymagałoby, niestety, bardzo znacznej modyfikacji protokołu klient-serwer, co nie było intencją autora.
Poniżej przedstawiamy szczegóły realizacji żądań odczytu i zapisu w wersji Klient/R-RAID0.
Operacja odczytu w wersji Klient/R-RAID0
Scenariusz wykonania:
W wersji Klient/U-RAID0 klient nigdy nie będzie wysyłał żądania do węzłów, które nie zawierają żadnego fragmentu wolumenu, więc nie będzie potrzebne wysyłanie komunikatów przez serwery, a klient zlicza tylko odbierane dane – dokładnie wie, ile porcji danych powinien odebrać.
Również tutaj jednak uderza fakt, że klient jest zmuszony odebrać wiele przerwań w ramach realizacji jednego tylko żądania. Alternatywą dla takiego rozwiązania mogłoby być np. wprowadzenie synchronizacji między węzłami serwera (czyli metoda Klient/C-RAID0), np. w następujący sposób:
Scenariusz ten możliwy byłby jednak tylko wtedy, gdyby funkcja depozyt umożliwiała wysyłającemu węzłowi potwierdzenie w jakikolwiek sposób, że dane zostały dostarczone. Mechanizmy komunikacji wykorzystywane przez autora w chwili pisania tej pracy nie dawały takiej możliwości124.
Operacja zapisu w wersji Klient/R-RAID0
Scenariusz wykonania:
Zauważmy, że ten scenariusz jest bardzo podobny do scenariusza Klient-RAID0. Nie wprowadzamy tu żadnego dodatkowego przetwarzania ani narzutu, natomiast oszczędzamy: na obliczaniu fragmentów bufora do wysłania do kolejnych węzłów serwera, oraz o ile wykorzystany mechanizm komunikacji umożliwia rozsyłanie, również na pierwszym komunikacie w dwufazowym protokole zapisu.
Semantyka operacji dyskowych rzadko bywa precyzyjnie definiowana, w standardach trudno doszukać się jednoznacznych specyfikacji. Naturalnym wymaganiem, gwarantującym pewien determinizm, jest, aby żądania były niepodzielne, tzn. aby w sytuacji, gdy wiele żądań zostało wygenerowanych jednocześnie, system realizował je jedno po drugim (aczkolwiek niekoniecznie w kolejności, w jakiej je otrzymał), w taki sposób, aby:
A zatem część zmian wykonana jest w całości, a inne wcale. Można powiedzieć, że, w pewnym sensie, oznacza to realizację zmian w zerowym czasie. Chodzi więc o to, aby nigdy nie nastąpiła sytuacja, w której w pewnym momencie system jest w takim stanie, jakby zrealizował jakieś żądanie częściowo125.
Wymaganie niepodzielności jest dosyć silne. Można je osłabić, jeśli wziąć pod uwagę jedynie kwestię integralności danych. Z punktu widzenia integralności danych nie jest istotne, czy w danym momencie wolumen jest w stanie częściowej realizacji jakiegoś żądania, ale to, czy system w takiej sytuacji nie zacznie przeplatać realizacji żądań.
Problem ten najlepiej ilustruje następujący przykład. Załóżmy, że dwa procesy zapisują ten sam obszar na wirtualnym dysku, obszar składający się z dwóch fizycznych bloków na dwóch różnych fizycznych dyskach. Każdy z procesów wysyła w tym celu żądania zapisu do obu węzłów klastra. Jeżeli zdarzy się tak, że spośród żądań zapisu wysłanych do pierwszego węzła klastra pierwsze dojdzie i zacznie być realizowane żądanie od pierwszego procesu, natomiast spośród żądań do drugiego węzła klastra pierwsze dojdzie i zacznie być realizowane żądanie od drugiego procesu, wówczas w efekcie, po zakończeniu realizacji obu żądań, obszar na wirtualnym dysku będzie zapisany częściowo danymi procesu pierwszego, a częściowo danymi procesu drugiego, ponieważ każdy z tych procesów nadpisze dane drugiego procesu.
Własność nie przeplatania się żądań nazwiemy rozłącznością żądań. Jak nietrudno zauważyć, własność niepodzielności implikuje rozłączność, ale nie odwrotnie. Niepodzielność jest więc warunkiem silniejszym.
Problem ten dotyczy nie tylko implementacji klastrowej, ale w przypadku klastra jest szczególnie istotny, ponieważ duża liczba czynników zewnętrznych, z obciążeniem sieci na czele, może spowodować opóźnienia w dostarczaniu komunikatów i zmianę kolejności realizacji żądań, a jednocześnie koordynacja, trywialna przy implementacji lokalnie lub sprzętowo, jest kosztowna.
Rozwiązanie opisanego problemu wymaga, aby na czas zapisu danych cały zapisywany obszar był zablokowany do wyłącznego użytku procesu zapisującego. Aby uniknąć blokady, poszczególne bloki powinny być blokowane przez klienta sekwencyjnie, zgodnie z kolejnością wirtualnych adresów.
Poniższa procedura opisuje sposób blokowania dla dwufazowego protokołu zapisu:
Procedura ta wprowadza, niestety, dodatkowe opóźnienie. Dla wolumenu RAID0 skonstruowanego na N węzłach opóźnienie przekracza N-1 czasów przesłania krótkiego komunikatu (przekracza dlatego, że wchodzą tutaj w grę dodatkowe przełączenia kontekstu między wątkami poszczególnych węzłów oraz czas niezbędny na zablokowanie bloku w schowku w każdym z węzłów), co istotnie wpływa na opóźnienie. Jeżeli rozmiar pasemka nie jest dostatecznie duży (na tyle, aby czas poszczególnych operacji zapisu na dyskach był o rzędy wielkości większy niż czas przesłania komunikatu), to istotnie obniża to wydajność.
W niektórych przypadkach jednak zapewnienie powyższej własności może być trywialne, na przykład w implementacji Klient/R-RAID0 unikającej wielokrotnego generowania przerwań na kliencie (7.3.4.2).
Organizacja RAID1 (ang. również mirroring), zakłada istnienie dwóch nośników, na których istnieją identyczne kopie danych. Organizacja ta jest wykorzystywana ze względu na bezpieczeństwo i efektywność. Wszelkie żądania zapisu powodują uaktualnienie obu kopii. Odczyt może odbywać się tylko z jednej, ustalonej kopii (jest to wówczas RAID1 z tzw. kopią główną i rezerwową), tak jest zwykle w zastosowaniach zorientowanych na bezpieczeństwo. Alternatywnie, odczyt może odbywać się z obydwu kopii (wtedy mówimy o RAID1 z równoważeniem obciążenia126, ang. load-balancing), tak jest w zastosowaniach zorientowanych na wydajność.
Najważniejsze powody wykorzystywania tej organizacji to:
Wadą tej organizacji jest większe opóźnienie przy zapisie danych (trzeba zapisać obie kopie: po pierwsze nie dzieje się to idealnie równolegle, a po drugie nawet, gdyby działo się to idealnie równolegle, to musielibyśmy czekać na zakończenie obydwu zapisów128).
Najprostszą oraz najczęściej (w wielu sprzętowych i większości dotychczasowych programowych implementacji) stosowaną metodą równoważenia obciążenia pomiędzy serwerami zawierającymi kopie wolumenu RAID1 (ang. mirrors) jest wysyłanie żądań przez każdego z klientów naprzemiennie (ang. round-robin) do obydwu serwerów, niezależnie od tego, jakich bloków to żądanie dotyczy.
Rozwiązanie to zapewnia wprawdzie, że obydwa serwery będą otrzymywały średnio tę samą liczbę żądań, ale w rozwiązaniach programowych, gdzie schowki związane są z poszczególnymi dyskami129 raczej niż z wolumenami (co nie jest oczywiście możliwe, jako że dyski wchodzące w skład wolumenu są na różnych serwerach), ma zasadniczą wadę: przy tej metodzie zawartość schowków na obydwu serwerach po pewnym czasie będzie coraz mniej się różnić. Wynika to z faktu, że klient, wysyłając żądania naprzemiennie do obu węzłów, będzie zmuszał schowki znajdujące się na obu węzłach do przechowywania bloków obu fizycznych dysków. Kopia z dysku fizycznego na pierwszym węźle trafi, w wyniku realizacji żądania, do schowka na pierwszym węźle, natomiast kopia z dysku fizycznego na drugim węźle trafi do schowka na drugim węźle. Ale skoro kopie na obu węzłach muszą być w każdym momencie identyczne130, to znaczy, że w obu schowkach znalazł się taki sam blok danych. Jeżeli klienci będą wysyłać do obu schowków naprzemienie te same żądania z niewielkiego obszaru, to sytuacja taka (pojawienie się w obu schowkach tego samego bloku) będzie częsta. Gdyby obszar, z którego klienci czytają dane, był mniejszy niż wielkość schowka na każdym z węzłów, i żądania klientów byłyby czysto losowo kierowane do obu węzłów, to łatwo udowodnić, że w skończonym czasie na obu węzłach schowki zawierałyby identyczny komplet bloków.
W systemie klastrowym, gdzie duży i dobrze zarządzany schowek jest jednym z głównych czynników decydujących o przewadze tych systemów nad tradycyjnymi, jest to niedopuszczalne. Warto zauważyć, że problem ten nie występuje w implementacjach sprzętowych, gdzie schowek znajduje się na kontrolerze, czyli jest wspólny dla obydwu dysków. Tam fizycznie nie ma możliwości powstania dwóch kopii tego samego wirtualnego bloku.
Naturalnym rozwiązaniem jest więc podzielenie całego obszaru wolumenu na dwie części i przypisanie ich poszczególnym serwerom. Aby zapewnić równomierny rozkład obciążenia, można wykorzystać pomysł leżący u podstaw organizacji RAID0, definiując rozmiar pasemka i przydzielając kolejne kawałki dysku obu węzłom naprzemiennie. Podobnie, jak było w przypadku RAID0, rozmiar pasemka nie powinien być zbyt mały, aby średniej wielkości żądania, zamiast być rozbijane na dwa żądania do odpowiednich serwerów, mogły być wykonane sekwencyjnie131. Nie powinien być on również zbyt duży, aby obciążenie rozkładało się w miarę równomiernie i aby dostatecznie duże żądania mogły być jednak zrównoleglane. Łatwo zauważyć, że w tym rozwiązaniu zawartości obydwu schowków będą rozłączne.
Metoda ta ma jednak poważne wady. Najpoważniejszą z nich jest to, że oba dyski muszą obsługiwać cały obszar swoich danych, tzn. narzut związany z pozycjonowaniem głowicy w obu dyskach jest taki sam, jak w pojedynczym dysku. Tymczasem podstawową zaletą dobrych rozwiązań sprzętowych jest równoważenie obciążenia w taki sposób, aby zminimalizować pozycjonowanie głowicy (jest to zarazem trudne w rozwiązaniach programowych, ponieważ sterownik urządzenia nie ma bezpośredniej kontroli i informacji o dysku, niezbędnej do realizacji tej metody, konieczne byłoby zatem odgadywanie położenia głowicy).
Narzucającym się rozwiązaniem byłoby podzielenie całego obszaru wolumenu dokładnie w połowie na dwie części w ten sposób, że niższe adresy przypisane byłyby jednemu dyskowi, natomiast wyższe drugiemu. Zmniejszyłoby to narzut związany z pozycjonowaniem głowicy na każdym z dysków dwukrotnie132, lecz nie gwarantowałoby równomiernego rozłożenia obciążenia, jeśli żądania nie rozkładałyby się równomiernie w wirtualnej przestrzeni adresowej (a na ogół tak nie jest). Można jednak w prosty sposób poradzić sobie z tym problemem, przesuwając dynamicznie granicę pomiędzy blokami odwzorowanymi na pierwszy z dysków a blokami odwzorowanymi na drugi, tak, aby wyrównać obciążenie.
W badaniach wydajności urządzeń dyskowych tradycyjnie pojawiają się dwie wielkości: opóźnienie oraz przepustowość (ang. throughput)133.
Opóźnienie to czas, jaki upływa między rozpoczęciem wysyłania żądania przez klienta (tzn. momentem, w którym klient rozpoczyna proces wysyłania, jeszcze zanim wyśle jakiekolwiek dane, zleci operację DMA lub RDMA itd.) a zakończeniem realizacji tego żądania (otrzymaniem danych przy odczycie lub otrzymaniem potwierdzenia pomyślnego zapisu). Pojęcie to reprezentuje więc opóźnienie, z jakim spotka się klient systemu, gdy wygeneruje pojedyncze żądanie. Oczywiście opóźnienie jest większe dla żądań o większym rozmiarze.
Przepustowość to ilość danych przesłanych w jednostce czasu, czyli prędkość, z jaką dane są odczytywane lub zapisywane. W przypadku przepustowości nie można mówić o prostej zależności od rozmiaru żądania. Jeżeli generowane żądania mają ustalony rozmiar, to przepustowość jest iloczynem tego rozmiaru oraz średniej liczby obsłużonych żądań w jednostce czasu. Żądania o większym rozmiarze system realizuje wolniej, absorbują one średnio więcej czasu, więc w jednostce czasu można wykonać ich mniej. O tym, który czynnik przeważa w takim scenariuszu, i czy w związku z tym przepustowość rośnie czy maleje ze wzrostem rozmiaru żądania, decyduje wiele innych aspektów, związanych z konkretną realizacją, takich jak np. korzyści skali (rosnąca z rozmiarem żądania prędkość przesyłu danych), liczba jednocześnie pracujących klientów (gwałtownie rosnące opóźnienia przy maksymalnym obciążeniu systemu) 134.
Okazuje się, że w praktycznych zastosowaniach nie mniej ważny jest trzeci czynnik: obciążenie klienta.
Czynnik ten bywa definiowany w rozmaity sposób, np. jako:
Okazuje się, że w serwerach baz danych obciążenie procesora klienta (tzn. klienta systemu V3, który jest zarazem serwerem bazy danych) bardzo istotnie wpływa na wydajność systemu bazodanowego (bo serwer bazy danych poświęca pewną ilość czasu na obsługę żądań – wysyłanie, przerwania – zamiast na wykonywanie kodu związanego bezpośrednio z obsługą bazy danych – np. wykonywania zapytań, przeszukiwania itp.), w związku z czym trzy wyżej wymienione statystyki bezpośrednio przekładają się na wyniki testów wydajnościowych137.
W zastosowaniach multimedialnych spotykamy się jeszcze z tzw. roztrzęsieniem138 (ang. jitter), wariancją czasu realizacji żądania w strumieniu żądań. Parametr ten związany jest z płynnością strumienia danych multimedialnych. Oprócz wariancji można również badać w ogólności sam rozkład czasów realizacji żądań. W niniejszej pracy, ze względu na jej i tak dużą obszerność, nie będziemy się tym zajmować, ale warto pamiętać o wariancji badając wydajność systemu przeznaczonego np. na serwer strumienia danych wideo.
Niestety, spośród wymienionych wyżej ważniejszych statystyk związanych z wydajnością (opóźnienie, przepustowość oraz obciążenie klienta), autorowi pracy udało się zbadać jedynie opóźnienie i przepustowość. Badanie obciążenia nie powiodło się z powodów technicznych. Metoda zastosowana początkowo przez autora zawiodła z powodu niewłaściwego działania wykorzystanych bibliotek systemowych139, a metoda zastępcza140 dawała wyniki tak niestabilne, że w praktyce bezużyteczne. W dalszej części rozdziału opisano obie metody użyte przez autora, ale nie przedstawiono żadnych wyników testów.
Do testów wydajności implementacji RAID wykorzystano trzy jednakowo skonfigurowane stacje robocze połączone siecią Giganet, z których jedna pełniła funkcję klienta systemu, a dwie pozostałe funkcje węzłów serwera. Obie stacje serwerowe wyposażono w indentyczne dyski, na których w tych samych miejscach znajdują się jednakowej wielkości partycje.
Wszystkie trzy maszyny użyte w testach (tzn. klient i węzły serwera) są dwuprocesorowymi maszynami z procesorami Pentium II 400MHz, z 512MB pamięci SDRAM, 13GB dyskami ATA i kartami Giganet. Na węzłach serwera zainstalowano system operacyjny Windows 2000 Professional, natomiast maszyna kliencka używa Windows NT 4.0 Workstation (z uwagi na brak wsparcia dla Windows 2000 w części klienckiej systemu w wersji, na bazie której wykonano opisywane eksperymenty).
Węzły serwera są symetryczne, tzn. oferują tę samą wydajność. Aby jednak dodatkowo uniezależnić się od ewentualnych minimalnych różnic, wszystkie testy przeprowadzano symetrycznie, tzn. testy obejmujące jeden węzeł (np. test odczytu z lokalnego dysku lub odczytu z wolumenu znajdującego się na jednym węźle serwera) przeprowadzano na każdym z węzłów, uśredniając wyniki, natomiast testy obejmujące wiele węzłów141 (dwa) przeprowadzano na wszystkich (dwóch) kombinacjach (tak, aby każdy z węzłów w jednym z testów pełnił określoną rolę), również uśredniając wyniki.
Dyski węzłów serwera pełnią jednocześnie rolę urządzeń zewnętrznych zawierających dane (wolumenów), jak i dysków systemowych. W rzeczywistości system i jego pliki robocze (jak np. plik wymiany, ang. swap file) powinny być oddzielone od danych, a nawet umieszczone na oddzielnym kontrolerze, co pozwala uniknąć interakcji między normalną pracą systemu operacyjnego (tzn. zapisywaniem i odczytywaniem danych z dysku systemowego) a wykonywaniem żądań przez system V3 (odczytywaniem i zapisywaniem danych wirtualnych wolumenów). Niestety, w momencie wykonywania testów nie była dostępna bogatsza konfiguracja sprzętowa. Z tego samego powodu (braku odpowiedniego specjalistycznego sprzętu w czasie, gdy wykonywano testy wydajnościowe) niniejsze opracowanie nie zawiera testów porównawczych dla różnej liczby kolumn RAID0, wszystkie testy wykonano na serwerze składającym się jedynie z dwóch węzłów.
Ze względu na oszczędność miejsca, na wykresach wykorzystano skrótowe oznaczenia w stosunku do testowanych algorytmów (typy wolumenów), metod testowania itp. Znaczenie tych skrótów określone jest następująco:
Jak już wspominaliśmy wcześniej (7.5.1.1), obciążenie klienta bywa definiowane na różne sposoby, między innymi jako procent wykorzystanego czasu procesora klienta, średni narzut na pojedyncze żądanie lub spadek wydajności systemu.
Zarazem można sobie wyobrazić dwa sposoby pomiaru wspomnianych wielkości:
W tym drugim przypadku zakładamy, że aplikacja testowa jest dobrym przybliżeniem prawdziwej aplikacji, ma podobne właściwości i podobnie zachowuje się w różnych sytuacjach. Badając wpływ działania części klienckiej na szybkość działania aplikacji testowej otrzymujemy pewne przybliżenie wpływu, jaki część kliencka systemu V3 ma na rzeczywistą aplikację.
W pierwszym przypadku można posłużyć się np. tzw. systemowymi miernikami wydajności systemu Windows, zwanymi też licznikami wydajnościowymi (ang. performance counters). System udostępnia mnóstwo różnych statystyk związanych z działaniem procesów (i nie tylko), w szczególności np. średni procent czasu spędzonego przez procesor (w określonym przedziale czasu) na wykonywaniu kodu określonego procesu. Statystyki te opierają się na okresowym zwiększaniu różnego rodzaju liczników, stąd nazwa.
Obciążenie klienta można zmierzyć z wykorzystaniem liczników wydajności w następujący sposób:
Powodem, dla którego nie mierzymy czasu wykorzystanego przez naszą aplikację testową, a przez process jałowy, jest fakt, iż znaczną część czasu procesor spędza w jądrze oraz w innych procesach, które działają na rzecz naszej aplikacji generującej żądania. Pomiar czasu wykorzystanego przez aplikację nie odzwierciedlałby więc poprawnie wpływu żądań na system. Co więcej, zupełnie nie uchwyciłby aspektu przełączeń kontekstu i ich wpływu na obciążenie procesora, jeszcze bardziej fałszując wynik. Procent czasu spędzonego przez proces jałowy można interpretować jako procent czasu, który system spędzałby w dowolnych innych procesach, gdyby takie działały w systemie. Oczywiście i tu tylko w przybliżeniu.
W opisanej wyżej metodzie liczników wydajnościowych obliczamy wymienione wcześniej statystyki w następujący sposób:
Statystykę spadek wydajności systemu utożsamiamy z obliczonym wcześniej procentem czasu procesora klienta wykorzystanym na żądania odczytu/zapisu.
Alternatywna metoda, jak już pisaliśmy, polega na stworzeniu aplikacji testowej, która będzie symulować rzeczywiste obciążenie (rzeczywistą aplikację) i będzie miała wbudowane statystyki pozwalające dokładnie zmierzyć szybkość jej działania. Metoda ta nie jest tak uniwersalna jak liczniki wydajności, ponieważ jej skuteczność i sensowność wyników bardzo istotnie zależą od przyjęcia właściwego modelu aplikacji, tzn. napisania takiej aplikacji testowej, która w miarę dokładnie oddaje specyfikę rzeczywistego systemu. Wyniki będą różne dla różnych rodzajów aplikacji testowych, ponieważ różne będą liczby różnych współpracujących procesów, wątków, współpraca z dyskiem, komunikacja itp., w związku z czym różne będą schematy przełączeń kontekstu w tej aplikacji itp. Jeżeli jednak znajdziemy dobry model, wyniki testu będą reprezentować dokładnie to, co chcemy zmierzyć, czyli wpływ mechanizmu realizacji żądań odczytu/zapisu na wydajność aplikacji, taki, który uwzględnia wszystkie czynniki. Niestety, i to ostatnie jednak jedynie przy założeniu, że test będzie trwał dostatecznie długo. W praktyce wpływ różnych dodatkowych czynników, w tym przede wszystkim algorytmu szeregowania procesów w systemie Windows, okazuje się olbrzymi.
Bardzo prosty, uniwersalny (a więc niedokładny) model, praktycznie zastosowany przez autora do badania obciążenia klienta wygląda następująco:
Należy dodać, że w obu eksperymentach (z licznikami wydajnościowymi i z aplikacją testową) żądania są jednakowej wielkości, natomiast generujemy je w taki sposób, aby w każdej chwili liczba żądań przetwarzanych na serwerze była równa ustalonej liczbie klientów. Wyliczone wyżej statystyki są u nas funkcjami dwóch parametrów: rozmiaru żądania oraz liczby klientów (reprezentującej liczbę równoległych wątków wykonujących operacje odczytu/zapisu).
Z uwagi na to, że prędkość działania dysku jest o rzędy wielkości mniejsza niż prędkość przesyłania danych po sieci Giganet, skuteczność schowka ma bardzo silny wpływ na wyniki testów. Aby uzyskane w testach dane miały jakąś wartość, konieczne jest kontrolowanie tego parametru. W opisanych niżej testach ustalono skuteczność schowka sztywno na 0% lub 100%.
Możliwe jest dzięki temu uchwycenie wybranych aspektów wydajności (poprzez zminimalizowanie wpływu pozostałych):
Zapewnienie 100% skuteczności schowka zrealizowane zostało przez ustalenie na każdym z węzłów dużego rozmiaru schowka (tutaj 64MB) oraz rozgrzewanie schowka przed każdym z testów. Rozgrzewanie schowka polega na odczytywaniu tych bloków, które następnie będą odczytywane w trakcie testu.
Procedura ta, aby była poprawna, wymaga jednak spełnienia kilku warunków:
Drugie wymaganie związane jest z algorytmem działania schowka. Algorytm zastosowany w opisywanym systemie jest istotnie różny od dotychczas stosowanych algorytmów, w większości opartych na LRU. Jedną z naczelnych zasad konstrukcji tego algorytmu było, aby bloki, które zostaną zapamiętane w schowku, pozostawały tam przez odpowiednio długi czas. Związane jest to z faktem, że schowek w tym systemie pełni rolę schowka drugiego poziomu, więc odwołania do tych samych bloków są rzadkie (gdyby były częste, trafiałyby w struktury schowka pierwszego poziomu i blok pozostawałby tam przez cały czas, natomiast odwołanie do schowka drugiego poziomu oznacza, że blok został w międzyczasie wyeliminowany ze schowka pierwszego poziomu jako rzadko używany). W związku z powyższym, zanim przystąpimy do rozgrzewania schowka, musimy zapewnić, że przebywające tam już przed rozgrzewaniem bloki nie będą przetrzymywane w schowku. Chcemy, aby nowo odczytywane bloki zajęły ich miejsce, lecz kłóci się to z zasadą działania algorytmu schowka. Dlatego rozgrzewanie schowka poprzedzone jest (napisaną przez autora) procedurą tzw. czyszczenia schowka, polegającą na usunięciu ze struktur schowka informacji o starych blokach.
Zapewnienie 0% skuteczności schowka mogłoby być zrealizowane przez odpowiednią modyfikację systemu, jednak autor zdecydował się na nieco bardziej uniwersalną metodą, nie wymagającą skomplikowanych (i tym samym podatnych na błędy) modyfikacji kodu:
Wspomniany algorytm przedstawia się następująco:
Wspomniany parametr N dobieramy w taki sposób, aby był możliwie duży (czyli zapewniał, że żądanie do żadnego bloku nie zostanie powtórnie wygenerowane przez dostatecznie długi czas), a zarazem aby umożliwiał wygenerowanie dostatecznej liczby żądań. W praktyce autor wybierał wartość kilkakrotnie większą niż liczba bloków schowka, co wystarczało dla zredukowania trafień w schowku do wartości bardzo bliskiej 0%.
W tym punkcie porównujemy średni czas odczytu (opóźnienie przy odczycie) bloków o różnym rozmiarze dla dwóch rodzajów implementacji wolumenu RAID0 oraz zwykłego wolumenu z czasem odczytu bloków z dysku lokalnego. W wykonanym teście żądania są generowane są jedno po drugim, ale w danej chwili wykonywane jest tylko jedno żądanie. Pozwala to uchwycić różnego rodzaju opóźnienia, niewidoczne w testach, w których wykonywanych jest wiele żądań jednocześnie.
Na rys. 7.2 porównano czas wykonania żądania odczytu dla wolumenów o organizacjach Serwer-RAID0 i Klient-RAID0 oraz dla zwykłego wolumenu (o organizacji prostej, tzw. sekwencyjnego), przy skuteczności schowka 100%.
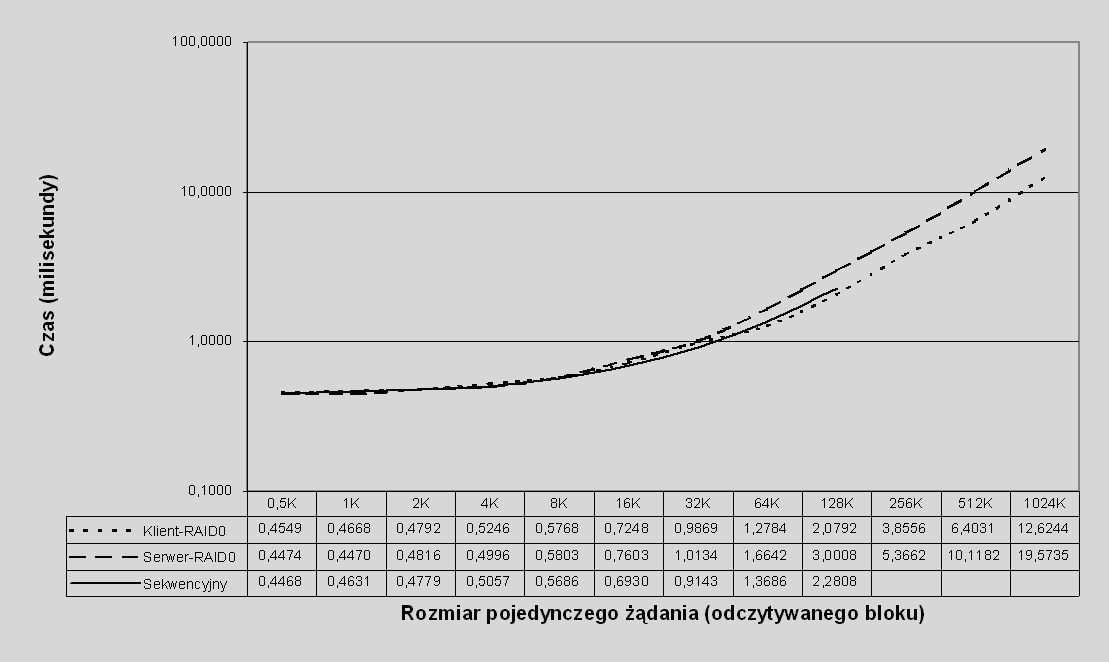
Rys. 7.2 Czas realizacji żądania odczytu dla różnych implementacji RAID0 oraz wolumenu sekwencyjnego w zależności od wielkości żądania: odczyt losowy ze 100% skutecznością schowka
Dla organizacji RAID przyjęto rozmiar pasemka równy 128KB, ponieważ ta wielkość daje najlepszą wydajność (co zostanie zweryfikowane w dalszej części tego rozdziału, patrz punkt 7.5.2.2 oraz 7.5.3.3). W przypadku zwykłego wolumenu pominięto wyniki dla rozmiarów żądań większych niż 128KB, ponieważ wersja systemu użyta do testów nie umożliwiała przesyłania bloków danych większych niż 128KB, w związku z czym przesyłane dane byłyby cięte na fragmenty o wielkości 128KB, powodując spadek wydajności, a wyniki takiego testu byłyby zafałszowane.
Na wykresie z rys. 7.2 widzimy, że dla małych żądań wszystkie trzy rodzaje wolumenów dają praktycznie identyczne rezultaty, tzn. różnice są w granicach błędu pomiarowego147. Dla dużych żądań Klient-RAID0 zaczyna bardzo wyraźnie przeważać nad Serwer-RAID0, przy rozmiarze żądania 1MB żądanie do wolumenu Klient-RAID0 obsługiwane jest o około 1/3 krócej niż żądanie do wolumenu Serwer-RAID0. Nie wiemy, jak zachowuje się dla żądań powyżej 128KB zwykły wolumen, jednak można się spodziewać, że czas obsługi żądania będzie rósł mniej więcej liniowo, podobnie jak dla pozostałych dwóch rodzajów wolumenów. Przyczyna leży w tym, że maksymalna wielkość pakietu danych przesyłanego po sieci Giganet w naszym systemie wynosi 32KB (w rzeczywistości maksymalny rozmiar, wynikający z ograniczeń sprzętowych, wynosi nieco mniej niż 64KB, ale dla potrzeb naszego systemu ta wielkość musi być potęgą 2), a więc każde żądanie przesyłu danych większe niż 32KB jest cięte na szereg żądań po 32KB, dlatego dla żądań powyżej 32KB czas rośnie mniej więcej liniowo (a drobna nieliniowość wynika stąd, że narzut naszego systemu dla dużych żądań nieco się amortyzuje).
Przewaga Klient-RAID0 nad Serwer-RAID0 w tym przypadku wynika stąd, że przy 100% skuteczności schowka o czasie wykonania żądania decyduje głównie czas komunikacji po sieci Giganet, i zależność ta jest najbardziej widoczna dla dużych żądań. Ponieważ Serwer-RAID0 wymaga dodatkowej komunikacji między serwerami, żądania do takiego wolumenu będą obsługiwane wolniej. Wprawdzie wczesne odsyłanie danych powoduje, że przesyłanie danych do klienta i przesyłanie danych między węzłami odbywają się w tym samym czasie, a przepustowość sieci Giganet jest wykorzystana w bardzo małym stopniu (co wyklucza wpływ tego parametru), jednak zachodzą następujące zjawiska:
W odniesieniu do ostatniego punktu można spekulować, że strumień fragmentów pochodzących z każdego węzła, a przesyłany do klienta powinien być około dwa razy rzadszy (tak byłoby np. w przypadku, gdyby fragmenty pochodzące od obu węzłów idealnie przeplatały się), ale oczywiście zachodzą tutaj również inne zjawiska, z ograniczoną zdolnością klienta do odbierania żądań na czele.
Wprawdzie wyniki dla 100% skuteczności schowka pozwalają nam lepiej uwypuklić różnice pomiędzy poszczególnymi implementacjami i rodzajami wolumenów wynikające z różnych modeli obiegu danych i komunikatów, ale do pełnego obrazu konieczne jest uwzględnienie różnic wynikających ze zrównoleglenia dostępu do dysku. Wyniki takiego eksperymentu pokazuje rys. 7.3. Przedstawiono na nim wyniki testu dla dwóch rodzajów wolumenów RAID0, w obu przypadkach przyjęto rozmiar pasemka równy 128KB.
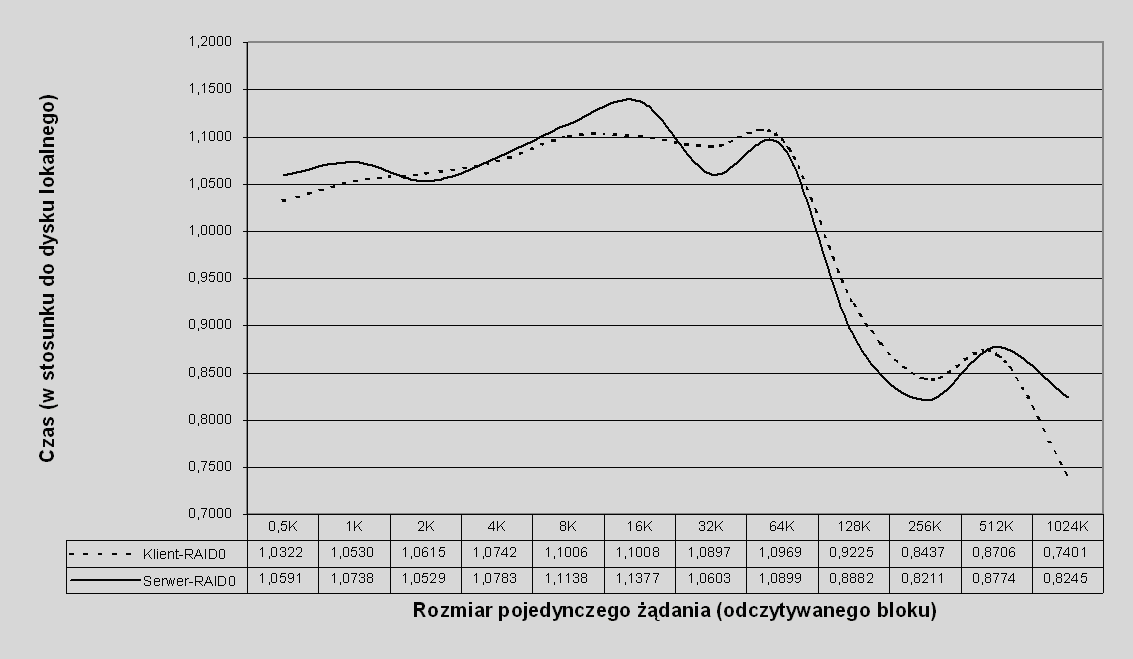
Rys. 7.3 Czas realizacji żądania odczytu w stosunku do dysku lokalnego w zależności od wielkości żądania: odczyt losowy z 0% skutecznością schowka dla różnych implementacji RAID0.
Widzimy, że w porównaniu z dyskiem lokalnym oba wolumeny RAID0 mają minimalnie gorszą wydajność dla małych żądań, wyraźnie gorszą dla średnich i wyraźnie lepszą dla dużych, przy czym ta ostatnia tendencja nasila się ze wzrostem rozmiaru żądania.
W tym przypadku zachodzą trzy podstawowe zjawiska, które mogą decydować o kształcie krzywych przedstawionych na wykresie:
Zjawiska te łącznie tłumaczą przebieg obserwowanych krzywych: nieco powyżej 1 dla małych żądań, z garbem dla średnich żądań i tendencją wyraźnie opadającą dla dużych żądań.
Nieco mniej oczywista, niestety, jest wzajemna relacja między wolumenami Serwer-RAID0 i Klient-RAID0. Jedyne, co możemy ustalić na podstawie wyników eksperymentów, to że relacja między wydajnością powyższych rozwiązań jest wysoce nieliniowa i zmienia się, na przemian na korzyść każdego z tych rozwiązań (co zresztą widać na powyższym wykresie, gdzie obie krzywe falują i raz po raz przecinają się). Nie można w związku z tym orzec, że jedno z tych rozwiązań jest, w jakimś zakresie typowych zastosowań, istotnie lepsze od drugiego. Różnice czasów (pomijając żądania 1MB, ale to może wynikać z błędu pomiaru) są na poziomie 3%.
Na rys. 7.4 porównano czas wykonania żądania odczytu dla wolumenu o organizacji Serwer-RAID0 dla różnych rozmiarów pasemka i dla 100% skuteczności schowka. Czasy odczytu dla różnych rozmiarów pasemka, od 8KB do 64KB, podzielono przez odpowiednie czasy dla rozmiaru pasemka 128KB. Oczekujemy, że duży rozmiar pasemka będzie dawał najlepsze rezultaty (a dane przedstawione na rys. 7.4 to potwierdzają), więc traktujemy ją jako przybliżenie przypadku granicznego, idealnego. W tym sensie wielkości prezentowane na wykresie odzwierciedlają w pewnym stopniu utratę wydajności w porównaniu z przypadkiem idealnym.
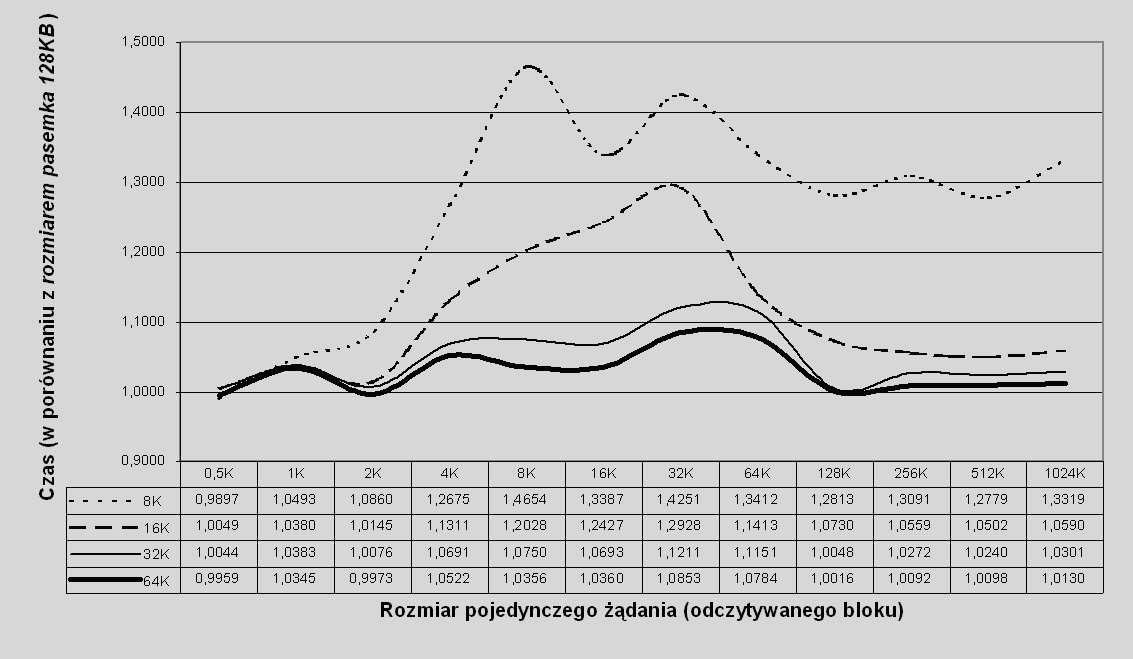
Rys. 7.4 Czas realizacji żądania odczytu dla różnych rozmiarów pasemka w porównaniu z rozmiarem pasemka 128KB w zależności od wielkości żądania: odczyt losowy ze 100% skutecznością schowka, wolumen typu Serwer-RAID0.
Natychmiast widać, że nie tylko rozmiar pasemka 128KB daje największą wydajność, ale w ogóle w całym zakresie rozmiarów pojedynczych żądań, im większy rozmiar pasemka, tym lepszy czas obsługi żądania. Wyniki te są zgodne z naszą intuicją: oczekiwalibyśmy, że w przypadku 100% skuteczności schowka nie ma znaczenia zrównoleglenie wykonania żądań, natomiast zmieniać się będzie (w zależności od rozmiaru pasemka) liczba kawałków, na które cięte będą żądania, a ponieważ transmisja danych po sieci Giganet (w tym przypadku główny czynnik decydujący o czasie wykonania żądania) charakteryzuje się wyraźnymi korzyściami skali (czas transmisji rośnie wyraźnie wolniej niż rozmiar transmitowanych danych), więc minimalizacja liczby fragmentów będzie premiowana. Ponieważ liczba fragmentów jest odwrotnie proporcjonalna do rozmiaru jednostki, według której są cięte (czyli rozmiaru pasemka), dlatego dla coraz większych rozmiarów pasemka odnosimy coraz mniejsze korzyści ze zwiększania tego parametru.
W przypadku Klient-RAID0 wyniki testów są nieco mniej oczywiste. W odróżnieniu od Serwer-RAID0, nie możemy tutaj mówić o prostej monotonicznej zależności czasu od rozmiaru pasemka dla każdego rozmiaru żądania, co widać na rys. 7.5.
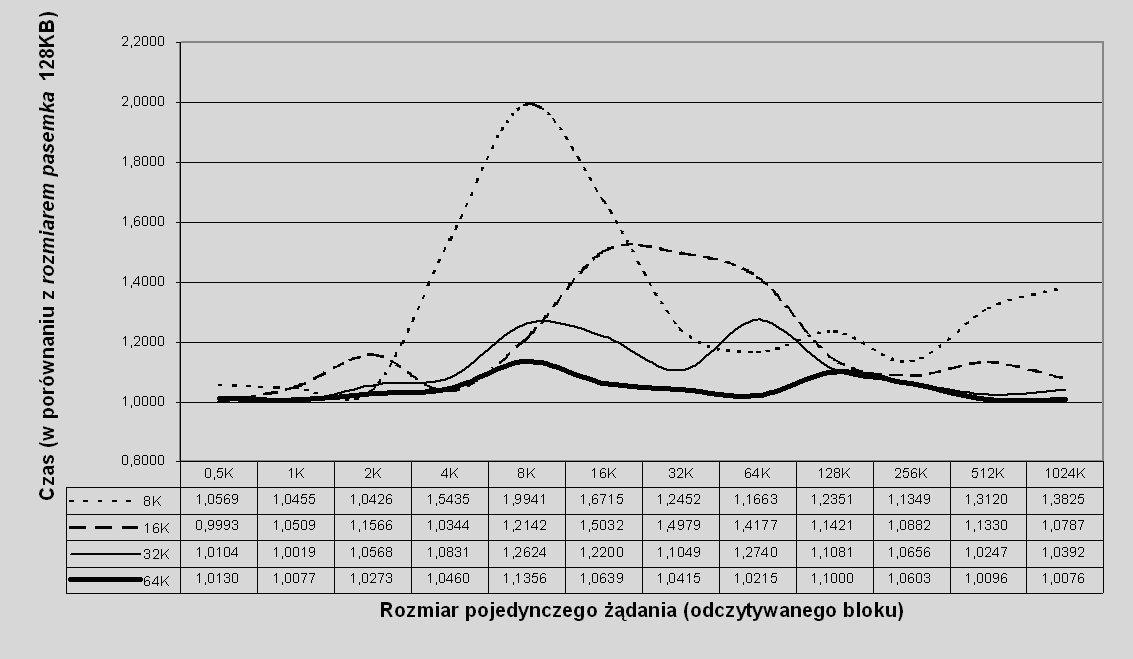
Rys. 7.5 Czas realizacji żądania odczytu dla różnych rozmiarów pasemka w porównaniu z rozmiarem pasemka 128KB w zależności od wielkości żądania: odczyt losowy ze 100% skutecznością schowka, wolumen typu Klient-RAID0.
Ogólna tendencja pozostaje prawdziwa dla większych rozmiarów pasemka oraz dla większych rozmiarów żądań, tzn. począwszy od rozmiaru pasemka równego 32KB, przechodząc do 64KB i 128KB uzyskujemy poprawę mniej więcej w całym zakresie, z wyjątkami w granicach błędu pomiarowego. Róznież tutaj więc możemy traktować przypadek rozmiaru pasemka 128 KB jako pewne przybliżenie przypadku idealnego. Również dla żądań powyżej 128KB wspomniana tendencja jest zachowana.
W tym przypadku widać jednak bardzo wyraźnie, że w Klient-RAID0 dla rozmiaru żądania równego lub nieco większego od rozmiaru pasemka wydajność przez chwilę wyraźnie się pogarsza (garby na wykresie). Zjawisko to jest na tyle wyraźne, że dla niektórych rozmiarów żądań Klient-RAID0 z mniejszym rozmiarem pasemka może być bardziej wydajne od Klient-RAID0 z większym rozmiarem pasemka, zupełnie wbrew temu, czego moglibyśmy oczekiwać. Błąd pomiarowy jest wykluczony, powyższe rezultaty powtarzają się w każdym teście. Autor nie potrafi wyjaśnić tego zjawiska.
Na wykresie 7.6 przedstawiono wyniki podobnego eksperymentu, dla wolumenu Serwer-RAID0, tym razem dla 0% skuteczności schowka.
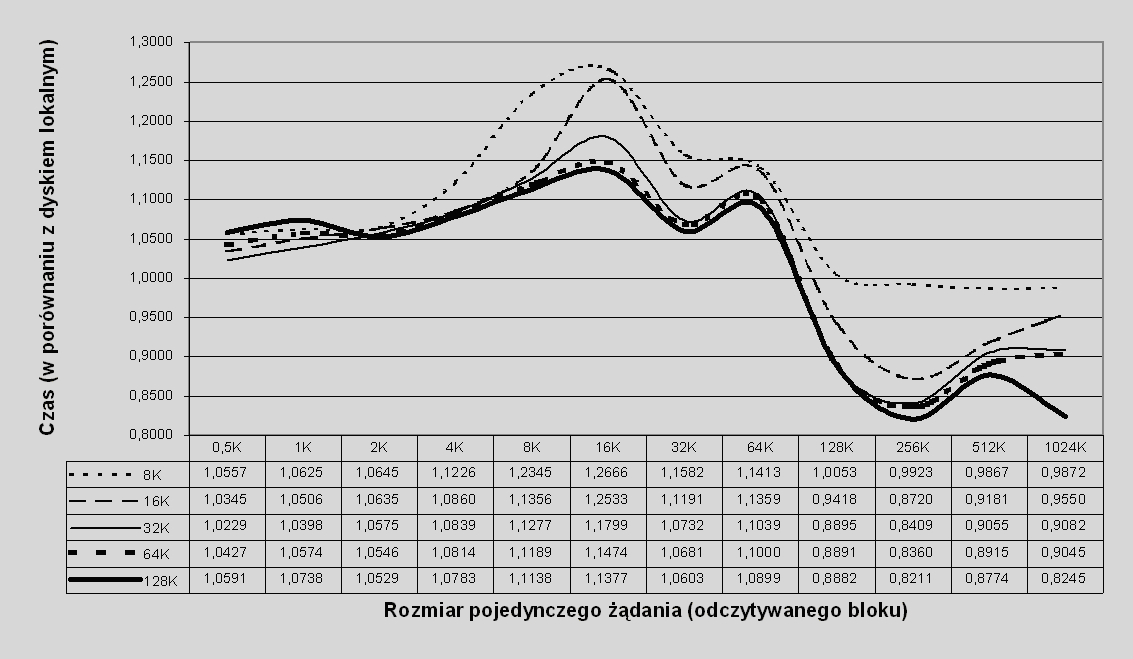
Rys. 7.6 Czas realizacji żądania odczytu w porównaniu z dyskiem lokalnym w zależności od wielkości żądania: odczyt losowy z 0% skutecznością schowka dla różnych rozmiarów pasemka, wolumen typu Serwer-RAID0
Podobnie jak dla 100% skuteczności schowka, zwiększanie rozmiaru pasemka zwiększa wydajność.
Również w przypadku Klient-RAID0 ta zasada jest spełniona, co widać na rys. 7.7.
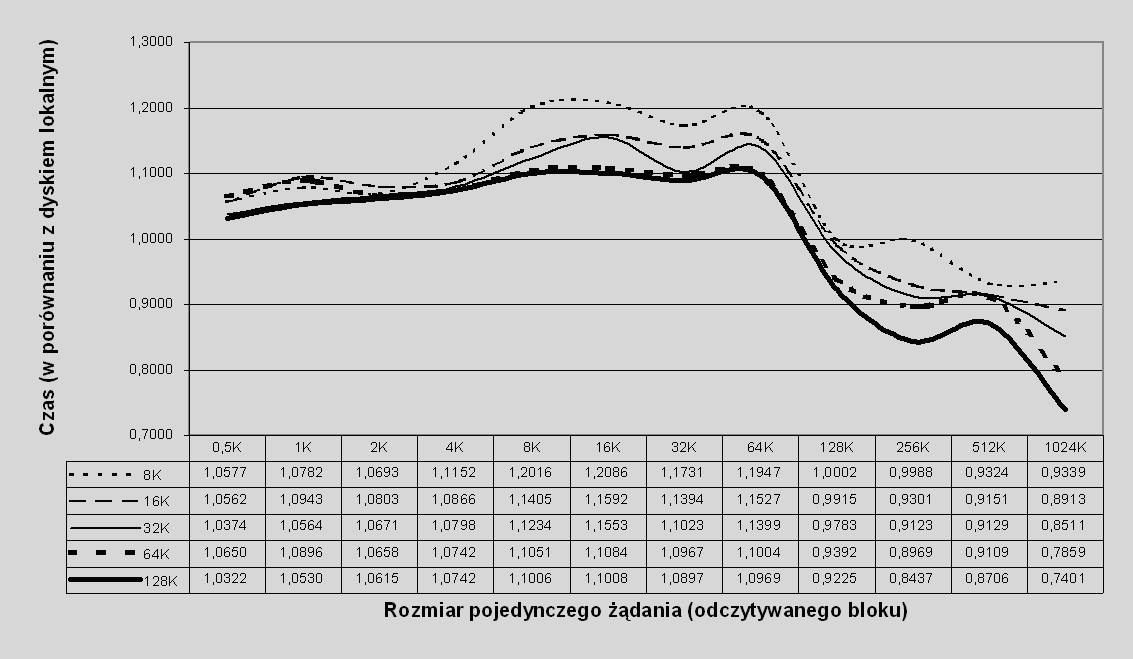
Rys. 7.7 Czas realizacji żądania odczytu w porównaniu z dyskiem lokalnym w zależności od wielkości żądania: odczyt losowy z 0% skutecznością schowka dla różnych rozmiarów pasemka, wolumen typu Klient-RAID0.
W obu przypadkach widać pewne zakłócenia przy bardzo małych żądaniach, ale można to przypisać błędom pomiaru.
W tym punkcie badamy najpierw wpływ obciążenia, tzn. liczby jednoczesnych żądań, na przepustowość, dla różnych rodzajów implementacji RAID0. Pozwala nam to wyznaczyć maksymalną przepustowość dla danego rodzaju żądania i danej implementacji RAID0. Następnie porównujemy maksymalną przepustowość dla różnych rodzajów implementacji. Ostatecznie krótko omawiamy wpływ rozmiaru pasemka na przepustowość.
Jak można się spodziewać, przepustowość przy odczycie danych w dużym stopniu zależy od tego, jak mocno obciążymy system. Wygenerowanie zbyt małej liczby żądań równocześnie nie obciąży serwera całkowicie, pozostawi wolne, niewykorzystane cykle procesora, okresy, w których dysk i możliwość komunikacji sieciowej są niewykorzystane, choć mogłyby być użyte do przesyłania dodatkowych żądań i transferu danych. Dlatego dla pewnego zakresu liczby jednoczesnych żądań, tj. od zera do pewnej wielkości granicznej, spodziewamy się wzrostu prędkości transferu danych. W pewnym momencie jednak liczba jednoczesnych żądań będzie na tyle duża, że generowanie dodatkowych żądań przestanie mieć sens, nie będzie powodować wzrostu wydajności. Może nawet spowodować niewielki spadek prędkości przesyłu danych z uwagi na to, że działanie serwera będą spowalniać przerwania generowane przez kolejno odbierane żądania oraz elementy zalegające w strukturach serwera powodujące rozrost struktur danych i związane z tym dłuższe czasy operacji na tych strukturach (czasy przeszukiwania tablic mieszających, list itp.).
Porównanie przepustowości przy odczycie dla wolumenu typu Serwer-RAID0 dla różnego obciążenia – różnej liczby jednoczesnych żądań – pokazano na wykresie na rys. 7.8.
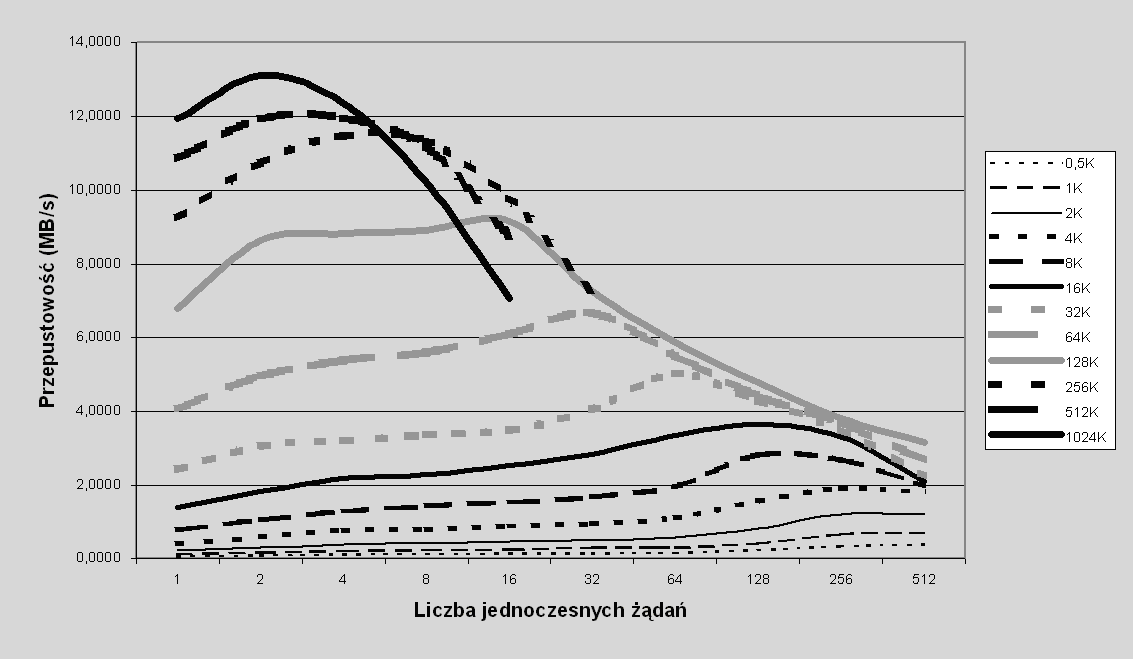
Rys. 7.8 Przepustowość przy odczycie w zależności od liczby jednoczesnych żądań: odczyt losowy dla różnych wielkości żądań, rozmiar pasemka 32KB, wolumen typu Serwer-RAID0
Eksperyment przeprowadzono w ten sposób, że jedna aplikacja testowa (jeden wątek) generowała jednoczesne żądania według następującego schematu (tutaj N jest ustaloną liczbą jednoczesnych żądań reprezentującą liczbę klientów, czyli obciążenie):
W teście tym żądania generowane są więc przez klienta w taki sposób, aby utrzymać stałą liczbę żądań realizowanych jednocześnie przez serwer. Metoda ta została zastosowana ze względu na to, iż zapewnia większą stabilność wyniku (zauważmy, że jeśli ustalona liczba klientów generuje żądania w sposób całkowicie losowy, to średnia liczba żądań realizowanych przez serwer, a więc i obciążenie serwera, będzie się zmieniać, wyniki odpowiedniego eksperymentu będą więc obciążone większym błędem).
Dla większych rozmiarów żądań krzywe się urywają, duża liczba jednoczesnych dużych żądań stanowiła zbyt duże obciążenie dla serwera.
Wyniki potwierdzają nasze oczekiwania. Wraz ze wzrostem liczby jednoczesnych żądań wydajność rośnie, jednak po przekroczeniu pewnej wartości zaczyna spadać. Wartość ta dla różnych rozmiarów żądań jest inna, choć rzuca się w oczy fakt, że maksymalne osiągi dla różnych rozmiarów żądań i róznej liczby jednoczesnych żądań tworzą w przybliżeniu coś na kształt opadającej krzywej, w której najbardziej zauważalny jest czynnik liniowy (krzywizna jest stosunkowo nieduża). Jeżeli założyć, że w kosztach związanych z generowaniem żądań najistotniejszy jest czynnik liniowy (a jest to dosyć rozsądne założenie, ponieważ liniowo z liczbą jednoczesnych żądań rośnie liczba komunikatów, elementów w strukturach serwera, przerwań itp.), to również tę zależność można wytłumaczyć: przepustowość maleje od pewnej hipotetycznej wartości maksymalnej prawie liniowo wraz z liczbą jednoczesnych żądań, a czynnik liniowy reprezentuje zagregowany koszt. Oczywiście w rzeczywistości wchodzi w grę mnóstwo innych czynników, dlatego nie można oczekiwać, że ta zależność będzie faktycznie liniowa.
Zauważmy również, że jeśli pominąć zakres parametrów, w którym serwer jest przeciążony (a dla mniejszych żądań nawet w tym zakresie), to zwiększenie rozmiaru żądania zwiększa prędkość transferu danych. Wynik ten jest dosyć oczywisty i w pewnym sensie weryfikuje poprawność naszego eksperymentu.
Bardzo podobnie wygląda ta sama zależność dla wolumenu Klient-RAID0 (wykres na rys. 7.9).
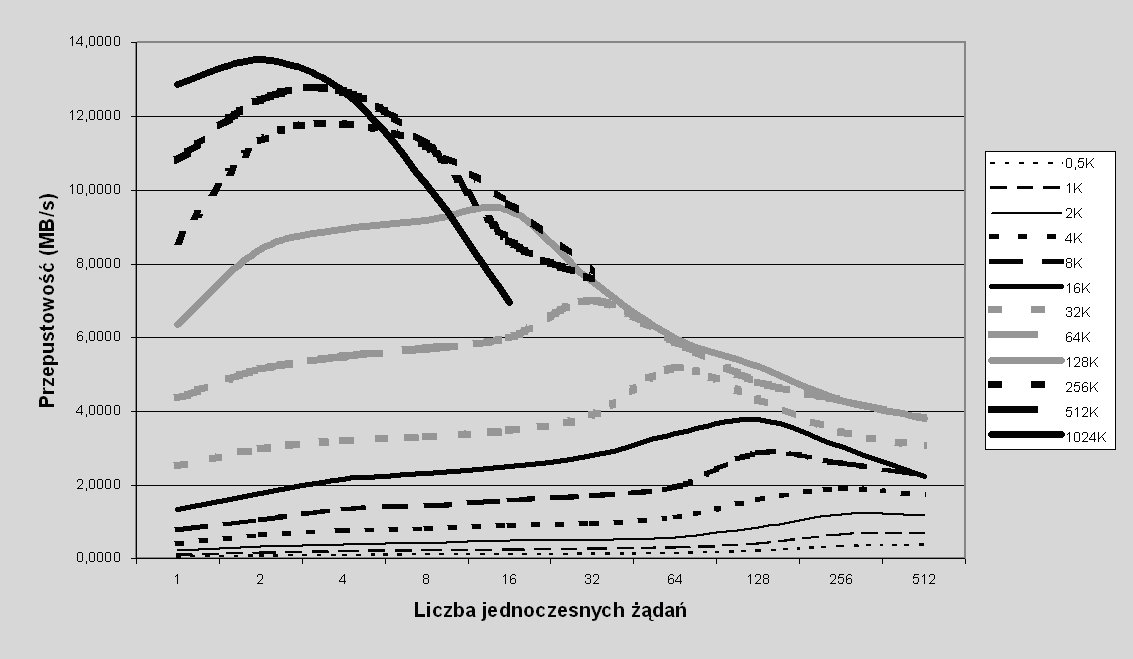
Rys. 7.9 Przepustowość przy odczycie w zależności od liczby jednoczesnych żądań: odczyt losowy dla różnych wielkości żądań, rozmiar pasemka 32KB, wolumen typu Klient-RAID0
Obserwujemy tutaj dokładnie te same zjawiska i tak samo również tłumaczymy zachowanie systemu.
Na wykresie na rys. 7.10 natomiast przedstawiamy dane dla wolumenu Serwer-RAID0 w nieco inny sposób, pokazując zależność przepustowości przy odczycie od rozmiaru żądania dla różnej liczby jednoczesnych żądań.
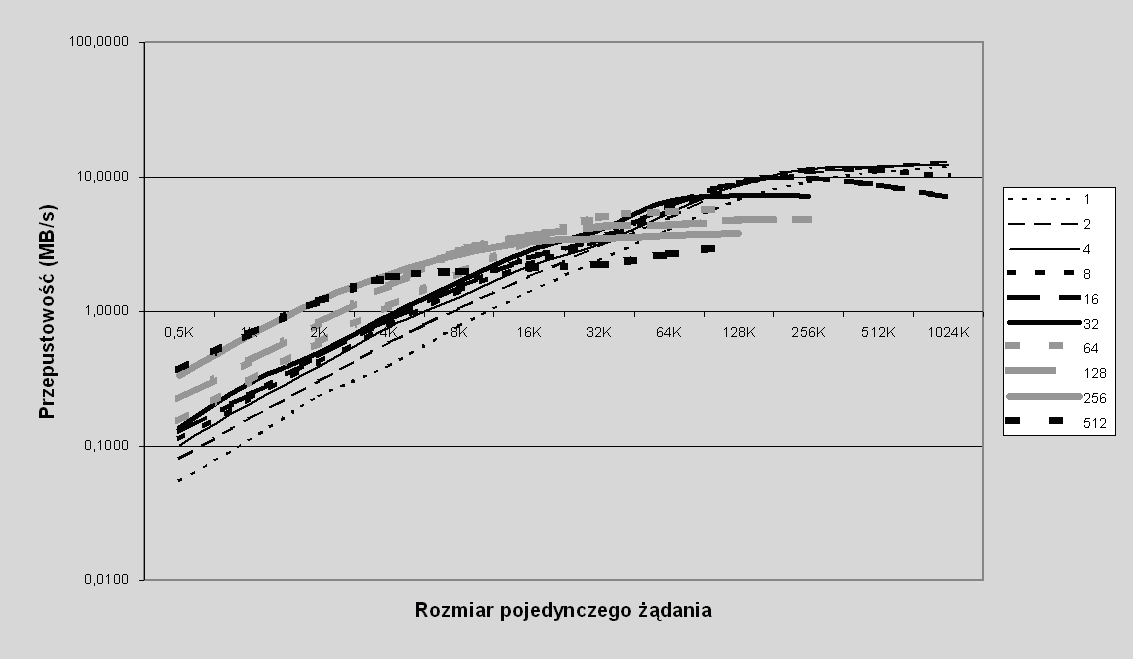
Rys. 7.10 Przepustowość przy odczycie w zależności od wielkości żądania: odczyt losowy dla różnej liczby jednoczesnych żądań, rozmiar pasemka 32KB, wolumen typu Serwer-RAID0
Co istotne na tym wykresie, każda z krzywych (prawie każda, tzn. wszystkie z wyjątkiem krzywej dla 16 żądań jednocześnie) w pewnym momencie zaczyna być płaska, a zatem dla (prawie) każdej liczby jednoczesnych żądań zwiększanie rozmiaru żądania w pewnym momencie przestaje mieć wpływ na przepustowość przy odczycie danych. A zatem zadana liczba jednoczesnych żądań pozwala (przez stosowanie dostatecznie dużych żądań) osiągnąć pewną maksymalną przepustowość przy odczycie, przy czym, jak już zauważyliśmy wcześniej, maleje ona wraz ze wzrostem liczby jednoczesnych żądań.
Również w przypadku wolumenu Klient-RAID0 obserwujemy tę samą zależność (wykres na rys. 7.11).
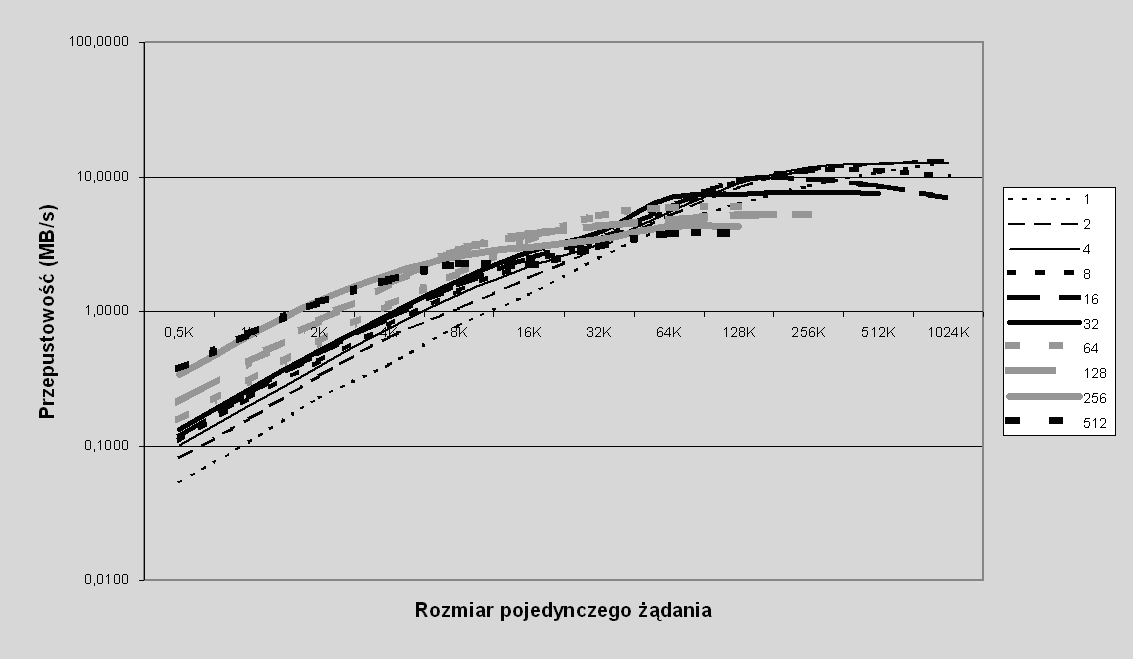
Rys. 7.11 Przepustowość przy odczycie w zależności od wielkości żądania: odczyt losowy dla różnej liczby jednoczesnych żądań, rozmiar pasemka 32KB, wolumen typu Klient-RAID0
Nie jest natomiast jasne, czy pojawiająca się gdzieniegdzie (np. szczególnie wyraźnie przy 16 jednoczesnych żądaniach w obu przypadkach) tendencja spadkowa dla rozmiarów żądań bliskich 1MB jest tylko błędem pomiarowym, czy rzeczywistym zjawiskiem. Autor napotykał pewne trudności z wykonywaniem bardzo długich symulacji dla dużych rozmiarów i większej liczby jednoczesnych żądań, ponieważ system pracował bardzo nierówno, a zarazem wykonywanie bardzo długich symulacji nie było możliwe z powodu pojawiających się w bardzo niedeterministyczny sposób błędów148.
Przepustowość przy odczycie, jak już zauważyliśmy wcześniej, zależy zarówno od rozmiaru żądania, jak i od liczby jednoczesnych żądań. Dla obu rodzajów wolumenów RAID0 ta zależność w prawie całym zakresie parametrów jest bardzo podobna, dlatego nie będziemy jej omawiać. Pewne różnice widać natomiast w maksymalnej przepustowości przy odczycie. Na wykresie 7.12 porównano maksymalną przepustowość przy odczycie (możliwą do osiągnięcia przy stosowaniu różnych rozmiarów żądań) w zależności od liczby jednoczesnych żądań, dla wolumenów o różnych organizacjach RAID0.
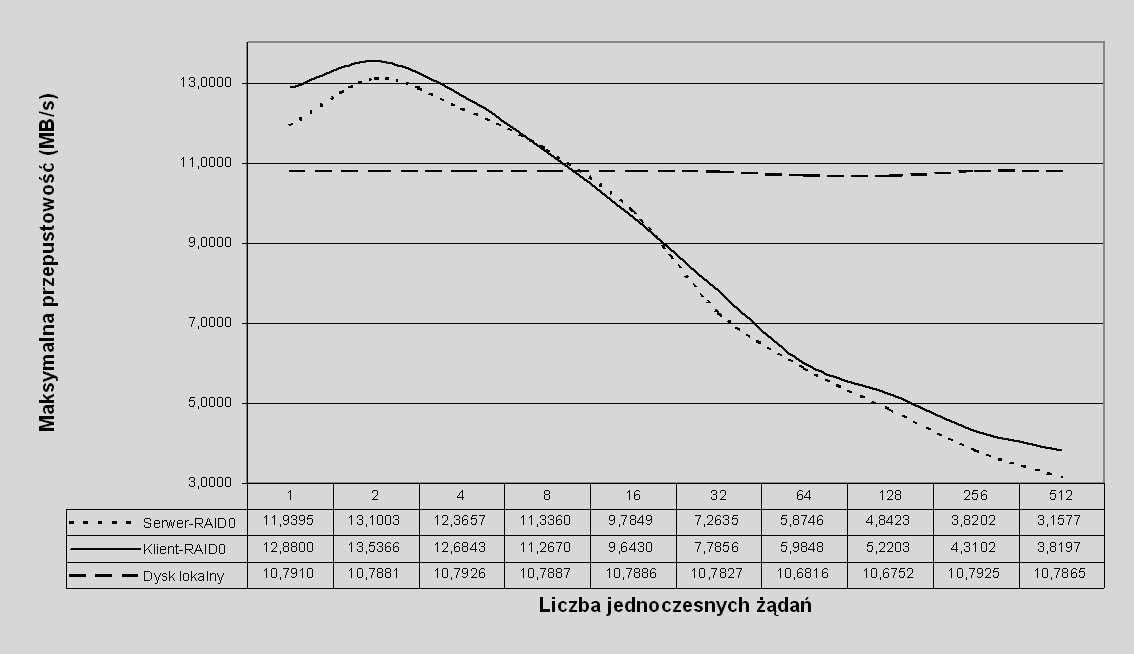
Rys. 7.12 Maksymalna przepustowość przy odczycie dla różnych rodzajów wolumenów RAID0 i dysku lokalnego: odczyt losowy, rozmiar pasemka 32KB
W prawie całym zakresie Klient-RAID0 daje nieco większą przepustowość. Jedynie dla średniej liczby (8 i 16) jednoczesnych żądań bardzo nieznacznie ustępuje Serwer-RAID0, jednakże różnica ta mieści się w granicach dokładności pomiaru. Możemy zatem stwierdzić, że przy dużych żądaniach (wcześniej przekonaliśmy się, że takie są konieczne, aby osiągnąć maksymalną przepustowość przy odczycie danych) Klient-RAID0 zapewnia nieco większą przepustowość. Obie organizacje RAID pozwalają osiągnąć większą (do 35%) przepustowość niż dysk lokalny dla niedużej liczby jednoczesnych żądań, maksimum występuje przy dwóch żądaniach – tylu, ile potrzeba, aby obciążyć oba węzły serwera. Wysyłanie dodatkowych żądań już tylko zakłóca pracę serwera. Można się spodziewać, że maksymalna przepustowość będzie większa dla większej liczby węzłów serwera i że maksimum będzie przypadało dla liczby żądań równej (lub być może nieco większej) liczbie węzłów. Niestety, ze względu na brak dostatecznej ilości sprzętu, ta hipoteza nie mogła być zweryfikowana w testach.
W przypadku testu przepustowości jest dosyć oczywiste, że rozmiar pasemka powinien przyjmować jak największe wartości, ponieważ aspekt zrównoleglania wykonania pojedynczych żądań (jedyna istotna korzyść wynikająca ze stosowania mniejszych rozmiarów pasemka) przestaje mieć sens – generowanie wielu żądań jednocześnie w zupełności wystarcza, aby jednocześnie obciążyć wszystkie węzły serwera i dodatkowe równoważenie obciążenia poprzez rozbijanie pojedynczych żądań nie ma sensu. Ważne jest natomiast, aby odczyt danych z dysku i transfer po sieci Giganet odbywał się szybko, a do tego (ze względu na korzyści skali) potrzeba, aby dane były czytane i przesyłane w dużych fragmentach. Wstępne obserwacje, dla wybranych parametrów, potwierdzają, iż rozmiar pasemka powinien być duży, dlatego nie będziemy tutaj prezentować wyników kompleksowych testów.
W rozdziale tym omówiliśmy zagadnienia związane z realizacją przez serwer żądań do wolumenów RAID0 i sekwencyjnych. Wspomnieliśmy pobieżnie o innych organizacjach (RAID1), jednak nie omawialiśmy szczegółów. Autor wspomniał jednakże o zagadnieniu równoważenia obciążenia w organizacji RAID1 jako przykładzie na to, że również tutaj systemy klastrowe mają swoje specyficzne problemy: w tym przypadku fakt, że obie kopie mają swoje oddzielne schowki i wynikający stąd problem dublowania się ich zawartości. W dalszej dyskusji skupiliśmy się na wolumenach RAID0, które zostały uznane za najbardziej potrzebne użytkownikom.
Przy realizacji organizacji RAID w systemie V3 napotkaliśmy na problemy nieco innej natury niż te, które pojawiają się w realizacjach sprzętowych149, trudności sprawia tu przede wszystkim kwestia rozproszenia150.
Wskazaliśmy kilka sposobów realizacji wolumenów RAID0: Serwer-RAID0, Klient-RAID0, Klient/R-RAID0, Klient/U-RAID0, Klient/C-RAID0 oraz Klient/Serwer-RAID0. Dokonaliśmy wstępnej analizy i porównania tych alternatywnych metod, wskazując na aspekty takie jak obciążenie klienta, złożoność, wykorzystanie wskazówek, wczesne odsyłanie danych. Każdy z wymienionych sposobów realizacji miał swoje wady i zalety. Algorytm Serwer-RAID0 zapewniał najlepszą izolację serwera (klient nie zna szczegółów organizacji, nie musi nawet korzystać ze wskazówek), najmniej obciąża klienta, posłużył nam także jako przykład wykorzystania możliwości komunikacji między węzłami serwera. Algorytm Klient-RAID0 jest z kolei przykładem algorytmu obciążającego klienta i nie wymagającego praktycznie żadnych dodatkowych zmian na serwerze, jest poza tym najprostszy w realizacji. Algorytmy Klient/R-RAID0 oraz Klient/U-RAID0 są przykładem całkowitego zrzucenia wszelkich obliczeń na serwer i możliwości wykorzystania operacji rozgłaszania, ale obciążąją klienta dodatkowymi przerwaniami. Modyfikacją powyższych dwóch, pozwalającą uniknąć zbędnych przerwań na kliencie jest algorytm Klient/C-RAID0. Realizacja tego algorytmu jest jednak możliwa tylko w takim systemie, w którym warstwa komunikacyjna umożliwia odebranie potwierdzenia dostarczenia danych wysłanych funkcją depozyt, co akurat w systemie V3 nie jest możliwe. Ostatni z przedstawionych algorytmów, czyli Klient/Serwer-RAID0, jest próbą połączenia zalet metod Serwer-RAID0 i Klient-RAID0. Ta metoda jest, niestety, najbardziej złożona, poza tym narusza niektóre założenia przyjęte wcześniej (węzeł odbierający żądanie to ten sam, który będzie na nie odpowiadał), przez co znacznie komplikuje obsługę awarii.
Wspomnieliśmy również o problemie spójności, który pojawia się w momencie rozproszenia wykonania żądań pomiędzy kilka węzłów. Autor nie znalazł nigdzie jasno określonego standardu określającego pożądaną semantykę. Wydaje się jednak, że zapewnienie spójności nie jest wymagane przez aplikacje151, dlatego w zaimplementowanych przez autora metodach nie znalazły się żadne dodatkowe mechanizmy synchronizujące zapis i odczyt pomiędzy węzłami serwera. Problem spójności posłużył nam dodatkowo jako przykład zalety, metody Klient/C-RAID0: ponieważ i tak węzły synchronizują między sobą wykonanie fragmentów żądania, więc spójność możemy dostać niejako za darmo.
Następnie dla dwóch wybranych metod implementacji RAID0 (Serwer-RAID0 oraz Klient/R-RAID0 i jego dwóch odmian) opisaliśmy w skrócie niektóre szczegóły implementacji, w przypadku Serwer-RAID0 opartej na koncepcji tzw. żądań zdalnych. Realizacja Serwer-RAID0 posłużyła nam jako przykład złożenia skomplikowanej implementacji z gotowych prostych elementów: żądań lokalnych i zdalnych. Dodatkową zaletą tej implementacji jest większa elastyczność: pod-żądania wysyłane do innych węzłów nie różnią się od żądań wysyłanych przez klientów, w szczególności np. węzeł, który odbierze takie pod-żądanie może nawet pośredniczyć w jego realizacji, jeśli to nie on przechowuje dane, których to pod-żądanie dotyczy. Realizacja Klient/R-RAID0 jest, jak już wcześniej wspomniano, przykładem wykorzystania rozgłaszania. Pominęliśmy tutaj natomiast opis realizacji metody Klient-RAID0, ponieważ jest ona dosyć oczywista, nie znajdujemy tam żadnych interesujących zagadnień.
Ostatnia część tego rozdziału została poświęcona testom wydajności niektórych implementacji RAID0. Do porównania wybraliśmy organizacje Klient-RAID0 oraz Serwer-RAID0, dwie bardzo odmienne metody reprezentujące przeciwstawne podejścia. Testowaliśmy opóźnienie oraz przepustowość przy odczycie w zależności od rozmiaru pasemka oraz (w przypadku przepustowości) liczby jednocześnie realizowanych żądań. Przeprowadzaliśmy testy ze 100% i z 0% skutecznością schowka – po to, aby odizolować i uwydatnić dwa aspekty: aspekt zrównoleglenia oraz różne modele komunikacji. W tym pierwszym przypadku musieliśmy wziąć pod uwagę czas odczytu z dysku, zapewniając 0% skuteczność schowka. W trym drugim musieliśmy, poprzez zapewnienie 100% skuteczności schowka, całkowicie wyeliminować odczyty z dysku, ponieważ stanowią czynnik dominujący i nie pozwoliłyby uchwycić różnic związanych z inną w obu przypadkach komunikacją.
W obu implementacjach przy obu testowanych wielkościach większe rozmiary pasemka dawały większą wydajność. Opłacało się również zwiększać liczbę jednoczesnych żądań, ale tylko do pewnego momentu, później zwiększanie równoległości wykonania odbijało się negatywnie na przepustowości. Następnie porównaliśmy obie implementacje RAID0 przy zastosowaniu optymalnych parametrów: dużego rozmiaru pasemka oraz optymalnej (zapewniającej maksymalną przepustowość) liczby jednoczesnych żądań. Okazało się, że obie metody są porównywalne. Wprawdzie Klient-RAID0 daje lepsze wartości mierników wydajności, ale nie są to różnice, które pozwoliłyby jednoznacznie uznać tę metodę za wydajniejszą.
Niestety, autor nie zdołał przetestować obciążenia procesora klienta. Badanie tego parametru wykazałoby przewagę Serwer-RAID0 nad Klient-RAID0. Istnienie przewagi jest bezdyskusyjne, ponieważ metoda Serwer-RAID0 generuje znacznie mniej przerwań na maszynie klienta, niejasna jest tylko wielkość tej różnicy. Zauważmy jednak, że różnica ta rośnie przy większych żądaniach (więcej przerwań na kliencie, cały czas tylko jedno na serwerze), podobnie, jak dopiero przy nieco większych żądaniach obserwowaliśmy drobną przewagę wydajności Klient-RAID0. Można więc zaryzykować stwierdzenie, że przy mniejszych żądaniach obie metody dają w zasadzie takie same rezultaty, natomiast przy większych żądaniach (rzędu 1MB) metoda Klient-RAID0 daje nieco mniejsze opóźnienie i większą przepustowość, podczas gdy Serwer-RAID0 nieco mniej obciąża klienta.