9 Obsługa błędów i sytuacji awaryjnych
9.1 Wprowadzenie
9.2 Najważniejsze definicje i postulaty projektowe
9.3 Zapewnianie odporności na awarie
9.4 Konsekwencje niektórych rodzajów awarii
9.5 Modele obsługi błędów
9.6 Podsumowanie
9.1 Wprowadzenie
Niniejszy rozdział
ma dosyć wyjątkowy charakter, ponieważ rozważania w nim zawarte są jakby
równoległe do wszystkich pozostałych. Rozdziały 2 – 8 napisano
przy założeniu, że kwestię awarii chwilowo
pomijamy, dla prostoty opisu i klarowności rozważań. Obecnie skupimy się
właśnie na awariach, odnosząc się w tym kontekście do wszystkich dotychczas
omawianych kwestii: warstw administracyjnej i operacyjnej, ich współdziałania,
architektury systemu oraz sposobu udostępniania zasobów klientom.
Na początku tego rozdziału wprowadzamy
kilka najważniejszych pojęć i formułujemy główne postulaty, którym
podporządkowana będzie dalsza analiza. W kolejnym punkcie (9.3)
wyliczamy niektóre sposoby zapewniania odporności na
awarie, ogólnie i w kontekście systemu V3. Niejako komplementarne do zawartych
w p. 9.3 są natomiast rozważania z
punktu 9.4, gdzie wymieniamy potencjalne konsekwencje, jakie
poszczególne rodzaje awarii mogą mieć dla opisywanego systemu. W obu tych
punktach nie znajdziemy pełnego wykazu środków zapobiegania awariom
zastosowanych w systemie V3. Część z nich została już omówiona w poprzednich rozdziałach, w innym kontekście.
Nie dokonujemy też przeglądu wszelkich
dostępnych metod, gdyż zagadnienie to jest zbyt obszerne, aby umieścić je w tej
pracy. W ostatnim punkcie (9.5) dokonujemy przeglądu metod obsługi błędów użytych w
systemie V3. Metody te łączą obsługę
błędów z raportowaniem i obsługą awarii155.
9.2 Najważniejsze definicje i postulaty projektowe
9.2.1 Najczęstsze przyczyny niedostępności systemów
Niedostępność
systemu (ang. outage lub downtime) może albo być wynikiem awarii,
albo być zaplanowana (konieczność wymiany, unowocześnienia lub rozbudowania
sprzętu, oprogramowania, archiwizacji danych itp.). Względna częstość różnych
przyczyn niedostępności zależy od typu systemu, różne źródła podają różne dane.
Na diagramie156
na rys. 9.1 przedstawione są ogólne statystyki przyczyn niedostępności
systemów.
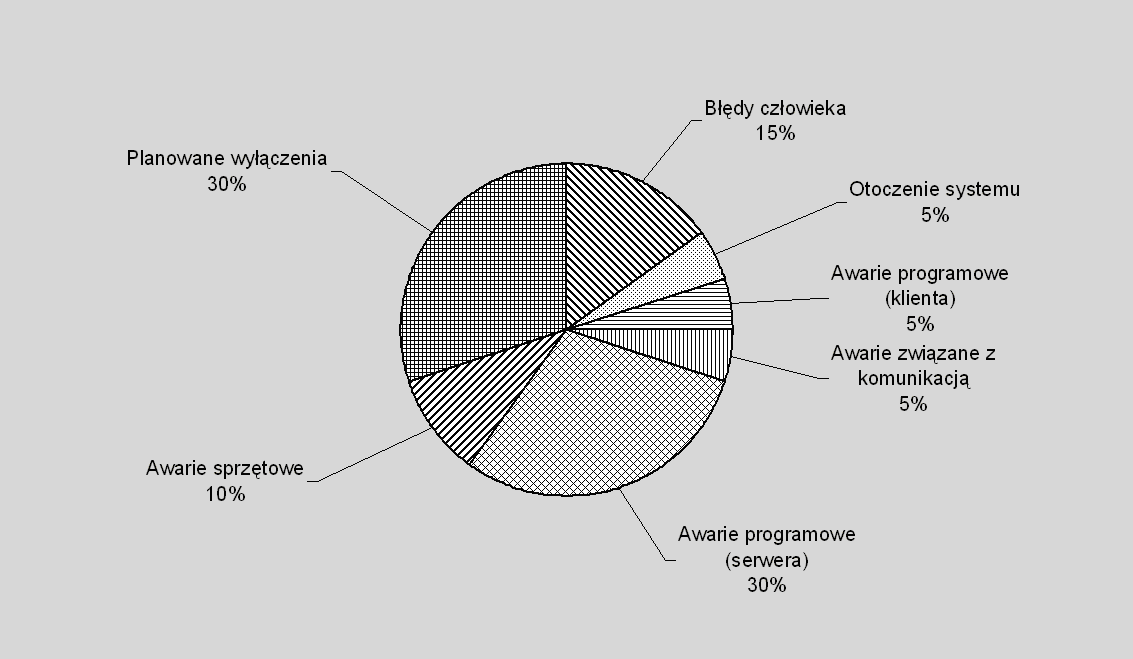
Rys. 9.1 Przyczyny niedostępności systemów.
Zauważmy, że awarie sprzętowe stanowią
jedynie około 10% przyczyn, podczas gdy najczęstszą przyczyną, odpowiedzialną
za aż 40% awarii są różnego rodzaju błędy programowe (łącznie awarie: serwera,
klienta i komunikacyjne157).
Nie wystarczy więc zastosowanie drogich komponentów sprzętowych i macierzy
RAID, sprawny system musi posiadać mechanizmy radzenia sobie z awariami
programowymi. Zazwyczaj, w różnego rodzaju analizach i przy projektowaniu
systemów odpornych na awarie, obserwuje się tendencję do koncentrowania się na
awariach dysków i połączeń w sieci – temu wszystkiemu służą organizacje RAID,
odtwarzanie połączeń, anulowanie i powtarzanie żądań itp. Tymczasem znacznie
istotniejsze z punktu widzenia odporności systemu są takie usprawnienia jak
izolacja błędów w poszczególnych modułach, zapisywanie stanów do dziennika i
możliwość restartu poszczególnych modułów.
Szacuje
się158,
że spośród wszystkich błędów sprzętowych około 90% stanowią błędy, które można naprawić (odtwarzając połączenia, ponawiając żądania itp.) w czasie
rzeczywistym w sposób przezroczysty dla systemu, tzw. błędy przejściowe (ang.
transient failures). W rzeczywistości zatem, jeśli zastosować odpowiednie algorytmy i
(programowe) metody radzenia sobie z takimi błędami, wówczas okazuje się, że
awarie sprzętowe wymagające poważniejszej ingerencji (wymiana podzespołów,
rozpoczęcie migracji danych na nowy nośnik itp.) stanowią zaledwie 1/100
przypadków.
Drugą pod względem
częstości przyczyną niedostępności systemów są planowane wyłączenia. Wiele
systemów nie umożliwia np. archiwizacji danych na bieżąco (ang. online
backup), w trakcie działania
systemu – np. w serwisach sieciowych lub systemach bankowych często można
spotkać się z informacją, że „trwa przeładowywanie danych”. Z podanej
statystyki jasno wynika, że dobrze zaprojektowany system powinien umożliwiać
wykonywanie wszelkich czynności administracyjnych w trakcie normalnego
działania, bez przerw w udostępnianiu usług.
9.2.2 Cechy systemów odpornych na awarie
Z punktu widzenia projektowania systemów pod
kątem odporności na awarie największe znaczenie mają następujące cechy:
- Wysoka
dostępność (ang. high availability, w skrócie HA),
oznaczająca zdolność systemu do dostarczania usług przez jak największy procent
czasu, czyli, innymi słowy, minimalizację łącznego czasu, w którym system jest
niesprawny. Pojęcie to jest dosyć ogólne i obejmuje różne rodzaje środków,
działań zmierzających do maksymalizacji dostępności systemu, aczkolwiek w
praktyce mianem wysoce dostępnych
określa się systemy mające specyficzną architekturę sprzętową i programową.
- Odporność
na awarie (ang. fault-tolerance,
w skrócie FT), pojęcie silnie związane z wysoką dostępnością, często
(aczkolwiek niepoprawnie159)
stosowane zamiennie. Odnosi się głównie do specjalizowanego sprzętu,
zaprojektowanego w taki sposób, aby całkowicie wyeliminować ryzyko awarii, np.
poprzez dublowanie podzespołów, podwójne wykonywanie obliczeń i porównywanie
rezultatów itp.
- Sprężystość (ang. resiliency), pojęcie
bardziej ogólne niż wysoka dostępność (odnosząca się przede wszystkim do
specyficznej architektury sprzętowo-programowej).
Sprężystość systemu
definiujemy160 jako:
- zapewnienie, że wszystkie rodzaje
potencjalnych awarii są zidentyfikowane, włączając w to wszelkie awarie
programowe, sprzętowe, problemy z komunikacją,
- zapewnienie, że dla każdej awarii
istnieje scenariusz radzenia sobie z nią, i dla każdego z takich scenariuszy,
jeśli zawiedzie, istnieje scenariusz awaryjny – nawet jeśli będzie to oznaczać
ingerencję człowieka, ręczne zmiany konfiguracji, odtwarzanie danych itp.,
- zapewnienie, że dla każdej awarii
maksymalny czas przywracania systemu do stanu sprzed awarii jest ograniczony,
dobrze określony i znany.
Podsumowując,
system sprężysty to taki, który może
przetrwać awarię krytycznego podzespołu i w którym usunięcie takiej awarii
odbędzie się w dobrze zdefiniowanym, ograniczonym i akceptowalnym czasie.
Oczywiście liczą
się również takie aspekty jak niezawodność (ang. reliability). Szczególnie z uwagi na to, że systemy omawiane w tej
pracy, realizując wiele funkcji programowo, są bardziej narażone na błędy
programisty. Aspekt niezawodności uwzględniamy tutaj wskazując na prostotę
niektórych rozwiązań (np. w rozdziale 8).
9.2.2.1 Sprzętowa odporność na awarie
Odporność na awarie
odnosi się przede wszystkim do sprzętu. Teoretycznie wykorzystanie sprzętu
odpornego na awarie powinno zapewnić stuprocentową dostępność systemu. W
praktyce okazuje się jednak, że najczęstsze są awarie programowe i nie da się
zapewnić wysokiej dostępności systemu jedynie poprzez zastosowanie sprzętu
odpornego na awarie. Z tego powodu, a także z uwagi na bardzo wysoki koszt tego
rodzaju sprzętu, znacznie częściej spotyka się rozwiązania programowe. Wykorzystywanie sprzętu odpornego na awarie w pewnym stopniu stoi w
sprzeczności z podstawową koncepcją tworzenia systemów klastrowych, zgodnie z
którą należy wykorzystywać tani, powszechnie dostępny sprzęt (ang. commodity
hardware), dzięki czemu za
porównywalną ceną można wykorzystać go więcej (więcej węzłów w systemie, więcej
dysków), a wydajność i odporność na awarie zapewnić za pomocą odpowiednich
środków programowych.
System V3 nie zawierał żadnych
komponentów sprzętowych odpornych na awarie, temat ten nie mieści się również w
problematyce niniejszej pracy, dlatego w dalszej jej części będziemy zajmować
się wyłącznie programowymi metodami zapewniania wysokiej dostępności.
9.2.2.2 Wysoka dostępność
Wysoka dostępność,
nazywana też czasem programową
odpornością na awarie (ang. software fault-tolerance), obejmuje cały szereg różnego rodzaju środków, w tym
między innymi następujące161:
- Stosowanie
dysków z podwójnymi interfejsami SCSI, podłączonymi do
dwóch kontrolerów znajdujących się na dwóch różnych węzłach. Na ogół jeden
węzeł aktywnie wykorzystuje swoje połączenie i korzysta z dysku, natomiast
drugi utrzymuje swoje połączenie na wypadek awarii, nie wykonując na dysku
żadnych operacji. W razie awarii tego pierwszego węzła (aktywnie korzystającego
z dysku), drugi węzeł może od razu przejąć współpracę z dyskiem. Jeżeli w
systemie znajdują się jakieś mechanizmy przekierowywania żądań, klient systemu
nie odczuje awarii, dane nadal będą na bieżąco dostępne. Środek ten jest
doskonałym zabezpieczeniem na wypadek awarii programowych, ale wiąże się z
dużymi kosztami. W systemie V3 nie uzwględniono dotychczas tej możliwości.
- Utrzymywanie
węzłów zapasowych, które mogą w razie awarii przejąć
zadania węzła głównego. Oba węzły na bieżąco kontrolują się, aby wykryć awarię. Węzeł główny przetwarza żądania klienta, natomiast w razie awarii węzeł główny
odcina się od sieci, aby nie przenosić skutków swojej awarii na inne węzły i klienta, a węzeł zapasowy przejmuje jego funkcje. Awaria może być albo
maskowana przed klientami (węzeł zapasowy dubluje wszelkie informacje z węzła głównego
i jest w stanie pełnej gotowości, zdolny do natychmiastowego podjęcia dalszego
przetwarzania), albo manifestowana (węzeł zapasowy jest bezczynny lub realizuje
własne zadania, a klienci w razie awarii muszą ponowić żądania, przekierowując
je pod nowy adres).
W kontekście klastrowych systemów składowania danych ta
możliwość dotyczy przede wszystkim wykorzystania organizacji RAID1 z kopiami na różnych węzłach. Jeden węzeł może pełnić rolę węzła głównego, natomiast drugi
rolę węzła zapasowego, utrzymującego na bieżąco aktualną kopię danych. Gdy nastąpi awaria, węzeł zapasowy jest w stanie natychmiast przejąć obciążenie,
aczkolwiek wymaga to od klientów ponowienia żądań. Autor wspomina o tym krótko
w p. 7.4.1.
- Stosowanie
programowych organizacji RAID, zarówno w obrębie
węzłów (wewnątrzwęzłowe RAID, ang. intra-node RAID), jak i pomiędzy węzłami
(międzywęzłowe RAID, ang. inter-node RAID albo across-node
RAID). Szczególnie
interesującym rozwiązaniem, planowanym także w systemie V3, jest, łącząca obydwa powyższe, organizacja wolumenu RAID5 skonstruowana z kilku kolumn RAID5
znajdujących się na różnych węzłach, gdzie każda pojedyncza kolumna jest zarazem samodzielnym wolumenem RAID5 zbudowanym na kilku lokalnych dyskach.
Rozwiązanie takie zapewnia bardzo wysoki poziom bezpieczeństwa i wysoką wydajność odczytu. Wprawdzie wydajność zapisu nie jest imponująca, ale
wydajność operacji zapisu w niektórych zastosowaniach, m. in. dla potrzeb
serwera bazy danych, w ogóle ma dużo mniejsze znaczenie niż wydajność operacji
odczytu i niezawodność.
- Dublowanie
fizycznych połączeń sieciowych, które pozwala na
natychmiastowe kontynuowanie transmisji np. w przypadku fizycznego uszkodzenia
nośnika. Podobną rolę pełni możliwość wykorzystania gorszych łączy, np. w
systemie V3 rozważano możliwość kontynuowania dostarczania usług za
pośrednictwem sieci Ethernet i protokołu TCP w razie awarii łączy Giganet.
Wprawdzie wydajność w takim przypadku spada dramatycznie, ale rozwiązanie takie
pozwala na utrzymanie ciągłości sesji. Obecnie w systemie V3 istnieje możliwość
stosowania podwójnych interfejsów sieciowych (Giganet) i awaryjnego
przenoszenia między nimi obciążenia, ale system nie w pełni tę możliwość
wykorzystuje m. in. z uwagi na niektóre założenia projektowe162.
- Mechanizm
tworzenia kopii zapasowych, koniecznie z możliwością
wykonywania ich w trakcie pracy, na bieżąco, bez przerw w dostarczaniu usług.
Autor zamierza wyposażyć system w tę możliwość za pomocą operacji kopia z punktu w czasie.
- Możliwość
funkcjonowania, gdy niekrytyczne komponenty zawiodą. W
systemie V3, dla przykładu, awaria warstwy administracyjnej nie powoduje
przerwy w dostarczaniu usług przez warstwę operacyjną. Warstwa administracyjna
nie jest elementem krytycznym systemu: jej chwilowa awaria nie niesie ze sobą
bardzo poważnych konsekwencji (jak byłoby np. w przypadku dłuższej awarii
warstwy operacyjnej i zatrzymania działania aplikacji korzystających z
wirtualnych wolumenów).
- Odizolowanie
punktów awarii. Awaria, nie izolowana, na ogół będzie
się rozprzestrzeniać. Węzeł, który niepoprawnie funkcjonuje może zakłócać pracę innych węzłów niepoprawnymi żądaniami. Proces, który niepoprawnie funkcjonuje
może błędnie zapisywać obszary na dysku, niszcząc dane wolumenów, a nawet niszcząc dysk systemowy. Wątek, który niepoprawnie funkcjonuje może mazać po
pamięci procesu, powodując niepoprawną pracę pozostałych wątków. System powinien, w miarę możliwości, unikać takich sytuacji, uniemożliwiając wadliwemu
elementowi zakłócanie pracy pozostałych elementów systemu. W systemie V3, dla
przykładu, wzajemnie odizolowane są warstwy administracyjna i operacyjna, każda
z nich może ulegać awarii bez możliwości zakłócenia pracy drugiej warstwy.
Również izolacja klienta od serwera za pomocą wirtualnego interfejsu ma podobny
efekt. W przeszłości operacje zapisu RDMA mogły sprawić, że awaria klienta i
wadliwa praca części klienckiej systemu spowoduje zniszczenie struktur w
pamięci serwera. Obecnie, dzięki zastosowaniu operacji zapisu w modelu przygotuj-odbierz163
i weryfikacji żądań klientów przez serwer, uniemożliwiono przenoszenie się awarii klienta na serwer.
- Automatyzacja
zarządzania systemem. Większość systemów projektuje
się obecnie w taki sposób, aby wyeliminować punkty krytyczne, tzn. uczynić system odpornym na wystąpienie pojedynczej awarii.
Awarie długotrwałe stwarzają ryzyko, że w międzyczasie pojawi się kolejna
awaria, czyniąc nieodwracalne szkody w systemie – na ogół systemy nie są
projektowane tak, aby zawsze radzić sobie z dwoma lub więcej awariami, jeśli pojawią
się jednocześnie164.
Automatyzacja czynności naprawczych pozwala uniknąć interwencji człowieka,
która z natury jest raczej czasochłonna i dokonuje się z dużym opóźnieniem. W
ten sposób, pośrednio, automatyzacja zarządzania systemem i procesami
awaryjnymi bardzo istotnie zwiększa ogólną dostępność systemu.
- Rozbudowane
mechanizmy monitorowania i wykrywania awarii.
Znaczenie takich mechanizmów jest tutaj identyczne jak znaczenie wymienionej
wyżej automatyzacji. Wczesne wykrycie awarii skraca czas między pojawieniem się
jej a usunięciem jej skutków, a więc zmniejsza prawdopodobieństwo pojawienia
się w tym samym czasie kolejnej awarii. W efekcie wzrasta dostępność systemu.
- Mechanizmy
zarządzania uprawnieniami i kontroli dostępu.
Czynnikiem wpływającym na awaryjność jest umyślna lub nieumyślna ingerencja użytkownika. W systemie V3 zastosowano autoryzację jakiejkolwiek komunikacji w
warstwie administracyjnej w celu częściowego wyeliminowania ryzyka. Komunikacja
w warstwie Giganet nie jest jednak w żaden sposób zabezpieczona. Jeżeli system
V3 byłby wykorzystany w architekturze z serwerami plików i aplikacji jako
bezpośrednimi klientami, udostępniającymi usługi właściwym (docelowym)
użytkownikom za pośrednictwem zwykłej sieci Ethernet, dodatkowe mechanizmy
kontroli dostępu nie są tutaj konieczne.
Oczywiście wyżej
wymienione środki nie wyczerpują całej gamy dostępnych rozwiązań. Autor
zaprezentował tutaj jedynie najważniejsze i najczęściej stosowane.
Warto tutaj nadmienić, że najlepsze
systemy stosują wiele z wymienionych rozwiązań jednocześnie i posiadają jakiś algorytm165
zarządzający wykorzystaniem dostępnych środków, np. stosowaniem redundantnych
organizacji danych (RAID1, RAID5), procesem replikacji danych itp.
9.3 Zapewnianie odporności na awarie
9.3.1 Sposoby zapewniania odporności na awarie
Zapewnianie odporności na awarie166
obejmuje zapobieganie awariom (minimalizacja
prawdopodobieństwa ich wystąpienia lub szkodliwości ich skutków), wykrywanie faktu wystąpienia awarii oraz
usuwanie skutków awarii.
Sposoby zapobiegania awariom i
minimalizacji ich skutków są oczywiście podzbiorem środków służących do
zapewniania wysokiej dostępności (patrz p. 9.2.2.2), więc nie będziemy ich tutaj powtórnie wymieniać.
Ograniczymy się tylko do omówienia izolacji
modułów zapobiegającej rozprzestrzenianiu się awarii. Pozostałe metody
spośród wcześniej wymienionych, zastosowane w systemie V3 zostały omówione w
innych rozdziałach.
Kwestii wykrywania awarii również nie
będziemy tu bardziej szczegółowo omawiać, ponieważ w obecnej wersji systemu V3
zastosowane środki są nader skąpe: autor ograniczył się do komunikatów typu
bicie serca wysyłanych między modułami w
warstwie administracyjnej oraz okresowej kontroli spójności konfiguracji.
W chwili obecnej w systemie V3 dostępne
jest bardzo wąskie spektrum środków służących do usuwania skutków awarii:
jedynie odtwarzanie połączeń w razie ich zerwania i możliwość restartu całych
modułów. Druga z tych metod posłużyła jako postulat projektowy (autor
projektował komponenty w taki sposób, aby możliwe było ich restartowanie w
dowolnym momencie) a zarazem domyślna polityka obsługi błędów (patrz 9.5) w niektórych przypadkach, natomiast tym pierwszym
autor niniejszej pracy nie zajmował się osobiście, dlatego nie będziemy tego
opisywać, tym bardziej, że w chwili obecnej nie jest to wyrafinowany mechanizm.
9.3.2 Odizolowanie od siebie modułów systemu
Odizolowanie od siebie modułów systemu
obejmuje następujące elementy:
- Bezpieczne interfejsy: ustalenie interfejsów między modułami w
taki sposób, aby zminimalizować ryzyko utraty spójności danych w prawidłowo funkcjonującym module w wyniku wadliwych akcji – żądań i wywołań funkcji –
podjętych przez inny, wadliwy moduł.
- Restartowalność
modułów: umożliwienie restartu poszczególnych modułów
bez rozbijania całego systemu, i w taki sposób, aby po krótkiej chwili potrzebnej na restart (kiedy system może nie być w pełni funkcjonalny)
zrestartowany moduł odtworzył połączenia z innymi modułami i ponownie podjął
pracę.
- Samodzielność
modułów: Zminimalizowanie zależności między modułami,
w taki sposób, aby w miarę możliwości poszczególne moduły systemu mogły funkcjonować w czasie, gdy inne moduły są niesprawne.
Autor zastosował
powyższe metody, aby wbudować izolację w system V3 za pomocą następujących
kroków:
- Zastąpienie fizycznych odwołań do
urządzeń dyskowych odwołaniami wirtualnymi nie tylko umożliwia implementację
organizacji RAID, ale również umożliwia węzłom serwera weryfikowanie żądań
klientów (postulat bezpiecznych
interfejsów). Ma to szczególne znaczenie przy rekonfiguracji systemu, gdy klient może generować żądania na podstawie nieaktualnych informacji (rozważania
na ten temat znajdują się w poprzednim rozdziale).
- Zastosowanie scenariusza bezpośredniego propagacji zmian (patrz poprzedni
rozdział) uniezależnia funkcjonowanie warstwy operacyjnej od warstwy administracyjnej
(samodzielność modułów).
- Elementy warstwy administracyjnej (zarządca węzła serwera i zarządca
klienta) mogą być restartowane
i odtwarzają połączenia między sobą oraz połączenia z zarządzanymi przez siebie
komponentami (proces schowka na węźle
serwera lub sterownik V3 na maszynie
klienta), zapisując stany tymczasowe w pamięci odpornej na awarie.
Oprócz tego w systemie zastosowano następujące
środki:
- Całkowicie wyeliminowano transfery RDMA
od klienta do serwera, aby uniknąć zamazania pamięci serwera przez wadliwie
działającego klienta. Zamiast tego, wprowadzono model przygotuj-odbierz167,
w którym klient wysyła dane wprost do buforów przygotowanych na tę okazję przez
serwer, nie specyfikując adresów, tak, że nie jest możliwe zapisanie pamięci
spoza specjalnie przeznaczonego na ten cel obszaru.
Kwestia izolacji
modułów miała także wpływ na architekturę systemu (rozdział 4) i decyzję o wyborze spośród dostępnych metod
realizacji niektórych zadań (patrz np. p. 8.2.2).
9.4 Konsekwencje niektórych rodzajów awarii
W tym punkcie opisujemy konsekwencje
wystąpienia niektórych rodzajów awarii, w tym również pośrednie konsekwencje
awarii wynikające z zastosowania niektórych środków naprawczych, do których
należą zerwanie połączenia i zrestartowanie węzła: dwie bardzo uniwersalne,
choć brutalne i nie w każdym przypadku skuteczne, metody radzenia sobie z poważniejszymi awariami (por. p. 9.3.2).
9.4.1 Zerwanie połączenia klient-serwer w warstwie operacyjnej
Zerwanie połączenia między klientem a
serwerem w warstwie operacyjnej ma m. in. następujące konsekwencje, wymagające
uwzględnienia w projekcie systemu:
- Odłączony klient na ogół zajmuje pewne
zasoby, np. otwarte wolumeny. Serwer nie może natychmiast po wystąpieniu awarii
odebrać klientowi tych zasobów, ponieważ istnieje szansa, że klient będzie w
stanie odtworzyć połączenie i kontynuować pracę w sposób przezroczysty dla
aplikacji. Zarazem serwer nie może blokować zasobów dla tego klienta w
nieskończoność (przykład: serwer nigdy nie pozwoli odłączyć wolumenu, ponieważ
nadal jest on otwarty). Dodatkowym aspektem jest to, że wielu klientów może nie
zamykać automatycznie wolumenów, kończąc sesję poprzez zerwanie połączenia.
Serwer musi być w stanie odróżniać
wszystkie te sytuacje lub w inny sposób zapewniać, że żaden z podstawowych
elementów funkcjonalności systemu (a takimi są m.in. dbanie o ciągłość sesji
klienta, jak również możliwość administrowania systemem, w tym odłączanie
wolumenów) nie zostanie zaniedbany.
- Realizacja żądań zostaje przerwana w
trakcie, a ponieważ każde żądanie stanowi samo w sobie mini-sesję (składa się z
kilku komunikatów, wymaga tworzenia po obu stronach dodatkowych struktur,
zajmowania zasobów), przerwanie żądania pozostawia w systemie bałagan. Jeżeli
nie uda się ponownie nawiązać komunikacji w krótkim czasie i kontynuować pracy,
konieczne jest usunięcie niepotrzebnych struktur i zwolnienie zasobów.
Problem
zerwanej sesji i blokowanych zasobów sygnalizowany był już w p. 5.3.1.2, zaś zagadnienia związane z utrzymaniem ciągłości
sesji omówione są w p. 5.3.2.2. Autor nie znalazł dotąd sensownego rozwiązania tego
problemu, które gwarantowałoby pełną automatyzację systemu.
Zamiast tego, jako
środek tymczasowy, autor przyjął w systemie V3 następującą zasadę:
- rozłączenie
klienta nie powoduje usunięcia informacji o odwołaniu klienta do wolumenu,
wolumen nadal pozostaje oznaczony jako używany przez tego klienta;
- rozłączenie jest
sygnalizowane administratorowi systemu;
- administrator
systemu ma do dyspozycji funkcję administracyjną usuń stare odwołania, która powoduje usunięcie odwołań rozłączonych
klientów do wskazanego wolumenu.
Rozwiązanie to
przenosi obowiązek podjęcia decyzji o usunięciu referencji do wolumenu (tj.
skojarzenia klienta z wolumenem będącego rezultatem otwarcia wolumenu przez klienta,
patrz punkt 8.2.2.2) na administratora, który może sprawdzić stan
połączeń, stan systemu klienta, rozstrzygnąć, czy rozłączenia są wynikiem
chwilowej awarii czy stanem permanentnym i, w tym drugim przypadku, zatwierdzić
je, likwidując informacje o takich rozłączeniach i umożliwiając odłączenie
wolumenu w celu wykonania czynności administracyjnych. Oczywiście można sobie
wyobrazić bardziej złożone funkcje, umożliwiające zarządzanie pojedynczymi
połączeniami klientów, precyzowanie minimalnego czasu, który musi trwać
rozłączenie, aby można było usunąć odwołanie do wolumenu itd., jak również
dodatkowe automatyczne reguły takie jak np. automatyczne usuwanie odwołań przy
rozłączeniach, które trwają kilka godzin.
Odnośnie
drugiej z powyższych konsekwencji, w systemie V3 mamy kilka następujących
podstawowych typów obiektów, które wymagają uporządkowania:
- Ciasteczka (ang. cookies), czyli drobne struktury pozwalające identyfikować trwające
sesje, tworzone dla wykonania kilkufazowych operacji – np. dla dwufazowego
zapisu,
- Struktury związane z wymienionymi
sesjami, czyli np. dane o parametrach i stanie wykonania wielofazowej
operacji, wykorzystywane przez
nadchodzące w ramach tej operacji kolejne komunikaty,
- Muteksy, sekcje krytyczne i inne
struktury synchronizacji zajęte na czas wykonywania czynności i nie zwolnione.
Przykładem będzie mutex chroniący blok dyskowy, zajęty na czas wykonywania
operacji zapisu, a zwalniany tuż przed wysłaniem ostatniego komunikatu w
protokole dwufazowego zapisu. Awaria komunikacji spowoduje przerwanie protokołu
i pozostawienie bloku zajętego.
- Zajęta (zarejestrowana) pamięć, np.
przeznaczona pod dane do odbioru.
W niniejszej pracy
nie będziemy omawiać szczegółowo tego zagadnienia. Problem porządkowania zasobów
po awarii dotyczy nie tylko jednego, konkretnego typu awarii omawianego w tym
punkcie, ale zdecydowanej większości, wiąże się także z modelem obsługi
wyjątków zastosowanym w implementacji i metodą raportowania błędów168.
System V3 jest na tyle złożony, że zagadnieniu porządkowania zasobów można
byłoby poświęcić osobną pracę. Zagadnienie to jest zarazem bardzo silnie
związane ze szczegółami implementacji i wymagałoby bardzo precyzyjnego
omówienia szczegółów implementacji poszczególnych modułów, co nie jest celem
autora.
9.4.2 Zerwanie połączenia procesu schowka z zarządcą serwera
Awaria polegająca na samym tylko zerwaniu
połączenia między procesem schowka a zarządcą serwera jest mało prawdopodobna,
gdyż jest to połączenie lokalne (między procesami na tym samym węźle). Zerwanie
połączenia jest jednak jednym ze skutków innych, poważniejszych awarii, w
szczególności np. awarii procesu schowka albo zawieszenia się procesu i
niemożności reagowania na żądania zarządcy serwera lub odwrotnie, awarii
zarządcy serwera lub np. planowego restartu zarządcy w celu usunięcia
wewnętrznej awarii lub uaktualnienia wersji.
Nie będziemy koncentrować się na
omawianiu z osobna skutków wymienionych wyżej poszczególnych rodzajów awarii,
lecz wskażemy podstawowe konsekwencje utraty lokalnego połączenia między
warstwami:
- Warstwa operacyjna po awarii nie ma
możliwości informowania warstwy administracyjnej o awariach (np. o błędzie
operacji dyskowej oznaczającym uszkodzenie nośnika), w związku z czym:
- do czasu odtworzenia połączenia awarie nie
będą zgłaszane administratorowi systemu,
- nie mogą działać automatyczne scenariusze
naprawcze.
Opóźnienie momentu, w którym awaria zostanie zgłoszona administratorowi
lub zostanie uruchomiony scenariusz naprawczy zwiększa prawdopodobieństwo pojawienia się kolejnej awarii, co może doprowadzić np. do trwałej utraty
danych.
- Niektóre metody propagacji zmian nie będą
funkcjonować prawidłowo (patrz p. 8.2).
- Ograniczone są możliwości administracji,
np. nie można rozstrzygnąć, jakie zasoby są w danym momencie wykorzystywane.
System musi blokować wykonanie wszelkich operacji, których realizacja bazuje na
tym, że jakieś zasoby są w danej chwili dostępne. Przykładem takiej operacji
może być zmiana parametrów lub usunięcie wolumenu.
- Jeżeli przyczyną utraty połączenia nie
była awaria procesu schowka lecz np. restart zarządcy serwera (w celu
aktualizacji wersji lub wykonania innej planowanej czynności
administrtacyjnej), to mamy sytuację, w której proces schowka działa, ale
zarazem brak połączenia uniemożliwia ewentualny restart procesu schowka, więc
proces schowka, choć nadal funkcjonuje, jest o wiele bardziej narażony na
awarie. Jeśli wziąć pod uwagę fakt, że restart procesu jest głównym remedium na
wszelkiego rodzaju awarie, jest to sytuacja wysoce niekorzystna.
Gdy teraz
proces schowka ulegnie awarii, nie będzie już w stanie wystartować ponownie,
ponieważ do funkcjonowania niezbędne mu są informacje konfiguracyjne
otrzymywane z zarządcy serwera. Zarazem część kliencka systemu, próbuje odtworzyć
połączenia przez ograniczoną ilość czasu. Brak lokalnego połączenia pomiędzy
warstwami jest więc łącznikiem, który powoduje, że restart lub awaria zarządcy
serwera może spowodować zablokowanie działania procesu schowka (niemożność
restartu), klientów systemu (nieudane próby ponowienia żądania przez
dostatecznie długi okres czasu) i ostatecznie aplikacji (błąd wykonania
operacji).
Dzięki uniezależnieniu warstwy operacyjnej
od administracyjnej udało się uniknąć kilku innych niekorzystnych konsekwencji.
Doskonałym przykładem może być sposób obsługi błędów. W systemie V3 polityka
obsługi błędów, choć ustalana przez warstwą administracyjną, jest przekazywana
warstwie operacyjnej i uaktualniana w razie zmian. Warstwa operacyjna, znając
politykę obsługi błędów, jest w stanie, w razie zerwania połączenia, obsługiwać
błędy w zakresie umożliwiającym dalszą pracę. Autor początkowo rozważał
raportowanie błędów do warstwy administracyjnej i podejmowanie decyzji w tej
warstwie, jednak zrezygnował z tego rozwiązania ze względu na wyżej wymienione
niekorzystne konsekwencje.
Oprócz wyżej
wymienionych dosyć niekorzystną konsekwencją zerwania połączenia jest także to,
że po jego odtworzeniu obie warstwy muszą nawzajem poinformować się o zmianach.
Warstwa administracyjna przekazuje nową konfigurację, np. nowe wolumeny. Aby
móc to uczynić, musi albo śledzić zmiany od czasu zerwania połączenia, albo
poprosić proces schowka o podanie jego aktualnej konfiguracji, tak, aby można
było odnaleźć różnice i przesłać jedynie listę zmian do wykonania. Ale
informacja jest przekazywana również w drugą stronę, np. jeżeli warstwa
administracyjna rejestruje otwarte wolumeny, to musi odpytać proces schowka o
listę aktualnie otwartych wolumenów.
W systemie V3 autor również dokonuje
takich uaktualnień. Jeżeli w trakcie, gdy połączenie było zerwane,
administrator zdefiniuje nowe wolumeny, to po odtworzeniu połączenia informacje
o nich zostaną automatycznie przesłane do procesu schowka, dzięki czemu staną
się one dostępne dla klientów. Zarazem w trakcie, gdy nie ma połączenia,
zabronione jest np. usunięcie wolumenu.
9.5 Modele obsługi błędów
9.5.1 Obsługa błędów w procesie schowka
Obsługa błędów w procesie schowka jest
zrealizowana w szczególny sposób z kilku powodów:
- proces schowka jest zarządzany przez zarządcę
serwera, sam nie ma wbudowanych żadnych mechanizmów decyzyjnych i nie może
zarządzać obsługą błędów,
- proces schowka podlega silnym
ograniczeniom czasowym, wszelkie decyzje muszą być podejmowane szybko, w
większości przypadków nie jest możliwe żadnego rodzaju oczekiwanie,
- proces schowka jest zorganizowany potokowo169,
tzn. żądania w procesie według ustalonego schematu krążą między modułami
żądania (patrz punkt 4.4.5), w odróżnieniu od np. zarządcy serwera, w którym
przetwarzanie zorganizowane jest zdarzeniowo, tzn. zdarzenia (w tym m. in.
akcje użytkownika, awarie, zaprogramowane alarmy, żądania od innych elementów
warstwy administracyjnej) inicjują wykonanie pewnych czynności, a poszczególne
moduły wywołują nawzajem swoje funkcje w celu obsługi tych zdarzeń.
Spośród
powyższych powodów najistotniejszym problemem jest potokowa organizacja
procesu, która powoduje, że nie ma w procesie kilku ustalonych punktów, w których skupione jest sterowanie (tzn. z których inicjowane są wywołania
funkcji pozostałych modułów i gdzie zawsze system ostatecznie wraca po
wykonaniu wywołanych funkcji) i gdzie można byłoby w ostateczności umieścić
obsługę sytuacji awaryjnych. Fakt ten powoduje, że nie ma większego sensu
stosowanie wyjątków, podczas gdy obsługa błędów za pomocą bardzo licznie
zgłaszanych i wyłapywanych wyjątków jest podstawą obsługi błędów w zarządcy
serwera (p. 9.5.2).
Autor
przyjął następujący model:
- W momencie wystąpienia błędu wywoływana
jest specjalna funkcja raportuj,
która jako argument przyjmuje szczegółowe informacje na temat rodzaju błędu, jak również miejsca jego wystąpienia (funkcja, moduł), a jako wynik przekazuje
kod akcji do wykonania na miejscu. Kody
akcji do wykonania będą różne dla różnych modułów, funkcji, miejsc wystąpienia
błędu, te same kody mogą być interpretowane w różny sposób, ale w większości
przypadków jednymi z dopuszczalnych kodów akcji będą zignoruj błąd i
przerwij
wykonanie (danej funkcji, sygnalizując błąd). Akcję taką nazywamy dalej
akcją natychmiastową.
- W miejscu, w którym została wywołana
funkcja raportująca, zaraz za wywołaniem tej funkcji, musi się znaleźć kod
odpowiedzialny za wykonanie akcji wskazanej przez funkcję raportującą. Dla
każdego miejsca wystąpienia i rodzaju błędów możliwych jest tylko kilka
rodzajów akcji (prawie wszędzie możliwe będą wspomniane akcje typu zignoruj błąd i
przerwij wykonanie. W wielu przypadkach dopuszczalne mogą być
również inne, bardziej wyszukane akcje (ponów
próbę, zwiększ czas oczekiwania itp.),
zależne od kontekstu. Wszystkie dopuszczalne rodzaje akcji muszą być tutaj
interpretowane, a jeśli akcja otrzymana od funkcji raportującej nie będzie
jedną z przewidzianych w danym kontekście, dopuszczamy nawet awaryjne
zatrzymanie systemu (bo nie jest to błąd czasu wykonania, ale poważny błąd
programisty).
- Fukcja raportująca, odebrawszy informację
o błędzie, sprawdza swoje struktury w celu ustalenia, jak na ten błąd należy
zareagować. Struktury takie określają politykę
obsługi błędów (ang. error handling policy), ich zawartość jest modyfikowalna, powinna być dostarczana przez
zarządcą serwera, który może ją również modyfikować dynamicznie. Polityka
obsługi błędów powinna wyznaczyć, dla danego rodzaju błędu, jedną akcję natychmiastową oraz jedną lub więcej
działań asynchronicznych. Akcja
natychmiastowa definiuje, co należy uczynić w miejscu wystąpienia błędu, aby
można było dalej kontynuować pracę. System działa potokowo, więc nie jest
możliwe wstrzymanie wykonania, błąd musi zostać obsłużony natychmiast lub
zostać przejęty przez inne moduły, umożliwiając szybkie przywrócenie modułu, w
którym wystąpił, do normalnego funkcjonowania. Wspomniane wyżej przejmowanie
przez inne moduły umożliwiają tu właśnie działania
asynchroniczne.
- Wspomniane działania asynchroniczne to lista działań, które należy dołączyć do
wewnętrznej kolejki w systemie. Oprócz funkcji raportującej, model wymaga także
obecności specjalnego wątku i stowarzyszonej z nim kolejki (w procesie schowka
tę rolę pełni wątek konfiguracyjny),
w której funkcja raportująca będzie umieszczać działania asynchroniczne do wykonania. Wątek, z którym
stowarzyszona jest ta kolejka musi pobierać kolejno elementy z tej kolejki i wykonywać zdefiniowane tam działania. Nazwa
asynchroniczne
odnosi się właśnie do sposobu wykonania – w odroczonym terminie, bez
oczekiwania funkcji raportującej na rezultat.
Dla
każdego błędu w tym modelu mamy więc dostępne dwa rodzaje reakcji: reakcję
natychmiastową, która daje możliwość kontynuacji pracy systemu, i reakcję opóźnioną, realizowaną już przez inny moduł, gdzie powinna się znaleźć
kompleksowa obsługa błędu (o ile nie udało się zawrzeć jej w całości w reakcji natychmiastowej).
Przykładem działania tego modelu może
być błąd odczytu z dysku. Funkcja raportująca powinna zalecić jako akcję
natychmiastową zasygnalizowanie błędu realizacji żądania. Żądanie zostanie
przekazane dalej, np. bezpośrednio do wątku wysyłającego w celu odesłania
klientowi komunikatu z informacją o błędzie. Oprócz tego jednak zostanie
zaplanowane działanie asynchroniczne, polegające np. na przeniesieniu danych
wolumenu na inny dysk (jeśli jest jakiś dostępny w wolnej puli zasobów) i
zasygnalizowaniu administratorowi systemu konieczności wymiany uszkodzonego
podzespołu.
Dosyć istotnym elementem tego modelu
jest możliwość określania polityki
obsługi błędów. Użytkownik powinien mieć możliwość wyboru spośród dostępnych działań dla każdego rodzaju awarii, system również musi sam być w
stanie dokonywać niektórych wyborów. Przede wszystkim zaś polityką obsługi
błędów musi zarządzać proces schowka. W systemie V3 jednak w chwili obecnej
polityka obsługi błędów jest ustalona, bez możliwości administracji, ponieważ w
systemie nie istnieją bardziej złożone mechanizmy obsługi awarii, takie jak.
migracja danych, możliwość stosowania wolumenów typi RAID1 itp.
9.5.2 Obsługa błędów w zarządcy serwera
Zarządca serwera,
jak już wcześniej (p. 9.5.1) wspomniano, wykorzystuje wyjątki C++. Przetwarzanie
jest tu skupione w kilku punktach (moduł odbierający żądania klientów i kilka
modułów posiadających własne wątki i reagujących na zdarzenia), w systemie nie
ma obiegu żądań, lecz wzajemne wywołania funkcji przez moduły. W zastosowanym
tutaj modelu obsługi błędów są jednak pewne podobieństwa do modelu wbudowanego
w proces schowka.
Przyjęty tutaj
model opiera się na następujących zasadach:
- W miejscu wystąpienia błędu zgłaszany
jest wyjątek. Wyjątek musi zaiwerać precyzyjne informacje o typie błędu i
miejscu jego wystąpienia.
- Część wywołań funkcji znajduje się we
własnej, prywatnej sekcji try..catch. Wyjątki wyłapywane tutaj są
raportowane za pomocą specjalnej funkcji raportującej. Jednocześnie na ich
miejsce generowane są inne wyjątki, znacznie bardziej ogólne, zawierające
jedynie informacje odpowiadające poziomowi abstrakcji bieżącej funkcji, w
której właśnie następuje zasłonięcie
wyjątku170, z
ukryciem szczegółów funkcji, w której zostały pierwotnie zgłoszone.
- W miejscu zasłonięcia wyjątku wszystkie
szczegóły, które są pomijane (informacje, które zawierał wyjątek wyłapany, a
których nie zawrzemy już teraz w wyjątku zasłaniającym go), oprócz tego, że
mogą być wykorzystane przez funkcję raportującą, mogą być użyte na miejscu.
Można wyobrazić sobie tutaj model podobny do użytego w procesie schowka, gdzie funkcja
raportująca wskazuje akcję natychmiastową. Autor jednak zdecydował się w tym
miejscu na akcje natychmiastowe wbudowane w kod, z funkcją raportującą, która
przekazuje informacje tylko w jednym kierunku.
- Funkcja raportująca zapisuje każdy błąd
do dziennika. Oprócz tego może, opcjonalnie, sama zainicjować pewne
asynchroniczne procesy, generując zdarzenie.
- W systemie może istnieć wątek obsługi
zdarzeń i stowarzyszona z nim kolejka zdarzeń, do której funkcja raportująca
wkłada informacje o zdarzeniach, a z której wątek obsługi zdarzeń pobiera je i,
stosownie do rodzaju zdarzenia, albo sam podejmuje odpowiednie czynności
(wywołując funkcje innych modułów) albo przekazuje zdarzenie dalej.
W systemie V3 autor
zrezygnował z możliwości dynamicznego zarządzania działaniami natychmiastowymi
w zarządcy serwera, natychmiastowa obsługa jest ustalona, wbudowana
bezpośrednio w kod. Powodem tego jest fakt, iż w większości sytuacji nie ma
żadnej dowolności – czynność, którą należy wykonać, jest jednoznacznie określona.
9.6 Podsumowanie
W rozdziale tym
wprowadziliśmy podstawowe pojęcia związane z obsługą awarii, takie jak dostępność,
izolacja itp., dokonaliśmy krótkiego przeglądu metod zapewniania
wysokiej dostępności, podaliśmy garść odniesień do poprzednich rozdziałów
(gdzie zastosowania niektórych z tych metod zostały bardziej szczegółowo opisane), opisaliśmy nieco bardziej szczegółowo kwestię izolacji. Podaliśmy
ważniejsze konsekwencje zerwania połączeń między klientem i serwerem oraz
lokalnie między warstwami. Autor brał te konsekwencje pod uwagę podejmując
decyzje projektowe. Na końcu przedstawiono dwa modele obsługi błędów,
zastosowane w zarządcy serwera i w procesie schowka. Oba modele istotnie różnią
się od siebie, co wynika z odmiennej organizacji działania obu elementów
systemu: jeden z nich zorganizowany jest zdarzeniowo, a drugi potokowo. Oba
modele mają też jednak cechy wspólne.
System V3 w obecnej fazie rozwoju nie
może być uznany za odporny na awarie i wysokodostępny. Wiele z wysuwanych przez
autora w tej pracy postulatów nie zostało jeszcze zrealizowanych. Najbardziej
dokuczliwym wydaje się brak możliwości tworzenia wolumenów RAID1 i brak
możliwości archiwizacji danych. Właśnie te dwie funkcje autor uważa w obecnej
fazie rozwoju systemu za najbardziej priorytetowe.
155 Przy czym przez obsługę błędów
rozumiemy tu obsługę wyjątków w programie oraz działania podejmowane przez
program, gdy wywołania funkcji systemowych zakończą się niepowodzeniem; obsługa błędów oznacza więc przyjęty
model programistyczny (który może
polegać np. na przekazywaniu sterowania przez wyjątki, generowaniu zdarzeń i
przekazywaniu ich między modułami, natychmiastowej obsłudze błędów itd.). Obsługą awarii natomiast nazywamy tutaj
strategię bardziej wysokopoziomową: działania podejmowane wspólnie przez różne
moduły systemu w celu usunięcia awarii.
156 Źródło: IEEE Computer, kwiecień 1995, powyższy diagram znajduje się
również w [49].
157 W pracy źródłowej, z której pochodzą te dane,
awarie komunikacyjne zaliczono do awarii programowych. Chodzi tu
więc o awarie komunikacyjne polegające na przypadkowym zerwaniu połączenia,
zagubieniu pakietu itd., czyli awarie łatwo usuwalne
programowo (przez ponowienie żądania, odtworzenie połączenia itp.) – stąd przyjęta klasyfikacja i nazewnictwo. Awarie komunikacyjne polegające na
fizycznym uszkodzeniu połączenia lub
awarii sprzętu (kart sieciowych, kontrolerów przełączających) zaliczone zostały
do grupy awarii sprzętowych, a nie komunikacyjnych (mimo, iż dotyczą
sprzętu służącego do komunikacji).
158 Stwierdzenie takie znajduje się w [9], w rozdziale dotyczącym wysokiej dostępności.
159 Bardziej precyzyjna definicja obu pojęć i różnice między nimi bardzo
dobrze opisane są w [52].
160 Definicja została zaczerpnięta z [49], tam również znajduje się najpełniejszy opis tego
pojęcia.
161 Autor opiera się tutaj na własnych doświadczeniach, ale także na
informacjach zawartych w [49] i [33], gdzie znajduje się bardzo pełne i precyzyjne
omówienie problemu wysokiej dostępności.
162 Odpowiedź na żądanie musi nadejść po tym samym połączeniu, po którym
wysłano żądanie.
163 Zapis w modelu RDMA i wystaw-odbierz
został omówiony w punkcie 4.4.
164 W dyskusjach biznesowych unika się wchodzenia w szczegóły, rozważania
prawdopodobieństw, wzajemnych zależności między awariami, istnieje raczej tendencja
do wyrażania właściwości systemu w prostych, łatwych do zrozumienia przez laika
kategoriach, takich jak np. brak
pojedynczego punktu awarii. Konsekwencją tego jest, iż większość systemów
bywa obecnie projektowana pod kątem zapewnienia takich „klarownych” własności,
zaś mało „efektowne” usprawnienia bywają lekceważone. Opinia ta pochodzi od
współuczestników projektu V3.
165 W pracy [30] w dość formalny i teoretyczny sposób opisano algorytm
zarządzania procesem replikacji w dużych systemach składowania danych.
166 Różne zagadnienia związane z wysoką dostępnością, odtwarzaniem danych
i stabilnego stanu systemu po awarii w systemach rozproszonych, bazach danych
itp. znajduje się m. in. w pracach [43], [48], [4] i [10].
167 Opis wykorzystywanej w implementacji biblioteki komunikacyjnej ACL, jak
również informacje na temat standardu VIA, znaleźć można w [14].
168 Uwagi na temat modelu raportowania błędów w procesie schowka znajdują
się w p. 9.5.1.
169 Patrz także p. 4.4.3 oraz 4.4.5, gdzie zobaczymy budowę wewnętrzną procesu schowka i
ścieżkę, jaką przebywają prostsze żądania (tzn. te do lokalnie zdefiniowanych
wolumenów sekwencyjnych).
170 Przez zasłonięcie wyjątku
rozumiemy opisywany tu właśnie proces polegający na wyłapaniu wyjątku bardziej
szczegółowego i zastąpieniu go wyjątkiem bardziej ogólnym.