2 Główne definicje oraz założenia projektowe
2.1 Wprowadzenie
2.2 Cechy technologii klastrowej
2.3 Wirtualizacja zasobów systemu
2.4 Odciążenie klienta kosztem serwera
2.5 Podsumowanie
2.1 Wprowadzenie
Celem tego
rozdziału jest przedstawienie głównych założeń projektowych systemu V3 i kilku
najważniejszych definicji, niezbędnych w dalszej dyskusji.
W punkcie 2.2 omawiamy wykorzystanie technologii klastrowej,
począwszy od podania formalnej definicji systemu klastrowego, a skończywszy na
wymienieniu własności, jakie taki system powinien posiadać i kilku głównych
ograniczeń. Właśnie te bardzo ogólne własności i ograniczenia stanowią jakby
meta-założenia projektowe dla systemu V3. Nie wszędzie udało się zrealizować
wszystkie z nich, ale większość przynajmniej częściowo. W kolejnych rozdziałach
pracy, przy omawianiu kolejnych zagadnień, będziemy pisać bardziej szczegółowo
o konsekwencjach tych meta-założeń.
Dalej (punkt 2.3) piszemy o wirtualizacji zasobów jako sposobie na
zapewnienie podstawowych własności wymienionych w 2.2.1. Od ogólnej koncepcji wirtualizacji przechodzimy do
dyskusji wirtualnych wolumenów, które są sposobem jej realizacji. Oprócz
definicji i własności wirtualnych wolumenów omawiamy również koncepcję zarządcy wirtualnych wolumenów, czyli
pewnego modelu architektury systemu, który może być podstawą implementacji wirtualnych
wolumenów i który jest z powodzeniem stosowany w praktyce w wielu systemach
nieklastrowych.
Punkt 2.4 zawiera omówienie dodatkowego założenia, które
dodano w rezultacie eksperymentów z wykorzystaniem systemu w serwerach
bazodanowych. Okazuje się, że bardzo opłacalne jest odciążanie maszyny klienta
kosztem umieszczenia większej funkcjonalności i skupienia przetwarzania na
węzłach serwera. Idea ta stoi niejako w sprzeczności z dotychczasowym trendem w
projektowaniu systemów, jednak swoje uzasadnienie znajduje właśnie w cechach
technologii klastrowej.
2.2 Cechy technologii klastrowej
Wykorzystanie technologii klastrowej wiąże
się z pewnymi ograniczeniami, ale też z licznymi korzyściami. Chcąc właściwie
wykorzystać wszystkie zalety tej technologii w ramach narzucanych przez nią
ograniczeń musimy wyposażyć projektowany system w szereg własności, o których
będzie mowa w punkcie 2.2.3. Musimy także wziąć pod uwagę kilka ograniczeń, o
których piszemy w punkcie 2.2.2.2.
2.2.1 Definicja systemu klastrowego
2.2.1.1 System klastrowy jako system rozproszony
Ścisła definicja klastra (systemu klastrowego, ang. cluster
system) do dziś jest przedmiotem sporów między specjalistami w dziedzinie
systemów rozproszonych. Większość definicji ma jednak sporo punktów wspólnych.
Najczęściej klaster definiuje się jako system rozproszony posiadający dwie
cechy.
- System
składa się ze zbioru połączonych siecią kompletnych, samodzielnych komputerów. Węzły systemu stanowią zupełnie niezależne jednostki obliczeniowe, nie
dzielą żadnych komponentów sprzętowych19,
nie wykorzystują też raczej do komunikacji między sobą żadnych specjalnych
niestandardowych rozwiązań architekturalnych (dzielona pamięć itp.), komunikują
się za pośrednictwem zwykłej sieci lokalnej, która często zbudowana jest z
wykorzystaniem szybkich podzespołów, np. Giganet, Gigabit, Myrinet. Naturalną i oczywistą
konsekwencją tego faktu jest to, że węzły muszą ze sobą współpracować, czyli że
system jest wyposażony w jakiś mechanizm synchronizacji i koordynacji działań.
- System
stanowi (z punktu widzenia klientów systemu) jednolity zasób. Klaster, mimo, że złożony z wielu równorzędnych węzłów, musi
stanowić, z punktu widzenia użytkownika lub systemów zewnętrznych (klientów),
spójną całość, jednolity serwer. W związku z powyższym w szczególności klient
nie musi i nie powinien posiadać wiedzy na temat wewnętrznej architektury
systemu, a wszelkie informacje na temat konkretnych węzłów mogą mieć jedynie charakter
roboczy (tymczasowy).
Oprócz wymienionych
wyżej postulatów definiujących pojęcie klastra można wymienić także szereg
cech, które są bardzo pożądane w każdym systemie klastrowym, a zarazem trudne
do osiągnięcia w systemach nieklastrowych (patrz 2.2.3).
2.2.1.2 System klastrowy a wewnątrzklastrowa sieć
Określenie klaster bywa stosowane w dwóch różnych
kontekstach. Problem ze ścisłym ustaleniem terminologii wynika z faktu, że
technologia wykorzystana w komunikacji między węzłami systemu klastrowego
zazwyczaj jest droga i sieć łącząca węzły jest siecią wewnętrzną, tworem
analogicznym do sieci zasobów (SAN, patrz 1.1) łączącej dyski i serwery plików w tradycyjnych
systemach. Komputery połączone taką
siecią stanowią więc zazwyczaj jeden spójny system udostępniający usługi użytkownikom (stacjom roboczym) już za pośrednictwem zwykłej20
sieci Ethernet. Dosyć naturalna jest w
tej sytuacji tendencja, aby pojęcie całej sieci wykorzystanej w międzywęzłowej
komunikacji, ze wszystkimi podłączonymi do tejże sieci komputerami, utożsamiać
z klastrem jako jednym, spójnym
systemem.
Zarazem czasem bywa tak, że sieć
łącząca węzły serwera łączy jednocześnie serwer z klientami. Tak jest na
przykład w systemie V3, dedykowanym do udostępniania zasobów dyskowych klientom
podłączonym do tej samej sieci lokalnej Giganet. Serwery plików, baz danych i
serwery aplikacji podłączone do tej wspólnej sieci Giganet można tu traktować
po prostu jako klientów serwera wirtualnych urządzeń blokowych, a z logicznego
punktu widzenia fakt, że ta sama sieć fizycznych połączeń została wykorzystana
jako sieć wewnątrzserwerowa oraz jako medium łączące klientów z serwerem, nie
ma większego znaczenia.
W
dalszej części pracy będziemy używać terminu klaster zarówno w odniesieniu do systemu składowania danych jako
spójnej całości w obrębie większej sieci (obejmującej też np. bazę danych,
serwer aplikacji etc.), jak też w odniesieniu do całej tej sieci, łączącej
system składowania danych z klientami tego systemu (serwerami baz danych,
aplikacji etc.). W miarę
możliwości będziemy jednak unikać dwuznaczności i używać w pierwszym z
powyższych przypadków słowa serwer,
rezerwując termin klaster na
oznaczenie całej sieci.
2.2.2 Główne zalety, wady i ograniczenia technologii klastrowej
Poniżej wymieniamy niektóre z zalet, wad i
ograniczeń technologii klastrowej wybrane pod kątem istotności z punktu
widzenia budowy systemów składowania danych.
2.2.2.1 Główne zalety i korzyści
Oto główne zalety technologii klastrowej i
korzyści z jej stosowania dla systemów składowania danych.
- Doskonała
skalowalność. Systemy klastrowe są w naturalny sposób
skalowalne, dokładanie do systemu kolejnych węzłów zwiększa jego wydajność. Odpowiednio zaprojektowane oprogramowanie będzie się dostosowywać do rozmiarów
systemu i ilości dostępnych zasobów. Głównym (i praktycznie jedynym) czynnikiem
ograniczającym skalowalność jest przepustowość wewnątrzklastrowej sieci.
- Olbrzymie schowki. Pamięć operacyjna węzłów klastra może być
wykorzystana jako schowek (ang. cache)
dla operacji odczytu/zapisu danych. Pamięć operacyjna oraz moc obliczeniowa w
komputerach klasy PC jest o rzędy wielkości tańsza niż schowki zaimplementowane
sprzętowo w dyskach, dlatego węzły systemu mogą być wyposażone w gigabajty
pamięci dedykowane dla schowka, znacząco podnosząc wydajność. Co więcej,
stosowanie tzw. schowków kooperujących
(ang. cooperative caching) pozwala
(przynajmniej teoretycznie) uzyskać wzrost wydajności schowka wraz ze wzrostem
rozmiarów systemu.
- Możliwość
wyeliminowania punktu krytycznego. Olbrzymią wadą
tradycyjnych systemów jest to, że serwer udostępniający wirtualne zasoby (lub
kontroler macierzy RAID w rozwiązaniach sprzętowych) stanowi tzw. punkt krytyczny systemu (ang.
single point of failure), tzn. każda
awaria tego elementu blokuje dostęp do danych, nie ma możliwości przejęcia
obciążenia przez inny, zapasowy system. Nawet jeżeli stosuje się organizację
danych zapewniającą redundancję, zawsze punktem krytycznym będzie element
pośredniczący w dostępie do tych danych: kontroler lub serwer, do którego
podłączone są dyski. Systemy klastrowe tymczasem nie mają tego ograniczenia.
Zasoby mogą być zarządzane i udostępniane przez kilka lub nawet wszystkie węzły
w klastrze, zabezpieczając w ten sposób system przed awariami. Kopie danych
mogą być umieszczone na różnych węzłach systemu i wówczas, w razie awarii
jednego węzła, jego pracę może przejąć inny.
- Dowolne
organizacje wolumenów. Zasoby dyskowe udostępniane
przez klaster przechowujący dane są wirtualne, konstruowane w oparciu o
fizyczne zasoby w dowolnie złożony sposób. Umożliwia to między innymi łączenie
wielu dysków w duże, wirtualne urządzenia, stosowanie (zaimplementowanych
programowo) organizacji RAID, dużo bardziej skomplikowanych algorytmów
zarządzania wydajnością (np. równoważenia obciążenia, optymalizowania
rozmieszczenia danych itd.). Kontrolery sprzętowe, ze względu na koszt,
zapewniają zazwyczaj dosyć prostą funkcjonalność.
- Wysoki
współczynnik wydajności do ceny. Wynika to z rodzaju
stosowanych technologii: komputery klasy PC zamiast dedykowanych, specjalnie zaprojektowanych komponentów.
Niektóre z wyżej
wymienionych zalet, przede wszystkim wirtualizacja zasobów dyskowych,
programowo implementowane organizacje RAID czy też spójne zarządzanie zasobami,
możliwe są również w tradycyjnych systemach dzięki tzw. zarządcom wolumenów21
(oprogramowaniu zintegrowanemu z systemem operacyjnym, które, podobnie, jak w
systemach klastrowych, pośredniczy między aplikacją a fizycznymi urządzeniami).
Stworzone w ten sposób wirtualne zasoby są jednak dostępne jedynie lokalnie na
serwerze, na którym działa wspomniane oprogramowanie i mogą być konstruowane
jedynie w oparciu o urządzenia bezpośrednio (poprzez interfejs SCSI czy też
jako NAS) podłączone do danego serwera. Udostępnienie takich zasobów pozostałym
serwerom może opierać się na tradycyjnych rozwiązaniach, takich jak np.
dzielone dyski czy katalogi w systemie Windows NT. Wszystkie te rozwiązania
łączy jednak niska wydajność, w większości zastosowań nieakceptowalna.
2.2.2.2 Główne wady i ograniczenia
Oto niektóre wady i ograniczenia związane z
wykorzystaniem technologii klastrowej.
- Większa
podatność na awarie. Związane jest to z faktem, iż w
systemie klastrowym wiele funkcji, które tradycyjnie realizowane są sprzętowo
(np. organizacje RAID), realizowane jest programowo. W rozdziale 9 dowiemy się, że znakomita większość awarii, z którymi
borykają się administratorzy systemów, to awarie programowe. Jeśli wziąć pod
uwagę fakt, że systemy klastrowe wciąż nie są jeszcze tak powszechne, jak
systemy tradycyjne, czyli że statystyka ta dotyczy w dużej mierze systemów, w
których duża część funkcji realizowanych jest sprzętowo, to można się
spodziewać, że podobna statystyka wykonana wyłącznie dla systemów klastrowych
będzie jeszcze dobitniej wskazywała na oprogramowanie jako podstawowe źródło
wszelkich awarii.
Nie należy tu jednak mylić podatności na wystąpienie
awarii z odpornością na awarie w ogóle. Systemy klastrowe mają większe
możliwości radzenia sobie w sytuacjach awaryjnych, maskowania awarii przed
klientem, dzięki czemu prawdopodobieństwo wystąpienia awarii skutkującej utratą
danych czy zakłóceniem pracy klienta jest znacznie mniejsze. Zarazem jednak, z
uwagi na większą częstość awarii, rola scenariuszy awaryjnych i działań
zapobiegawczych jest większa.
- Większa
złożoność i pracochłonność projektu. Wiąże się to
częściowo z faktem, że system klastrowy, przez rozproszenie i zrównoleglenie,
musi borykać się z zagadnieniami takimi jak synchronizacja, koordynacja i
rozproszone transakcje, tradycyjnie uznawanymi za złożone i podatne na błędy w
trakcie implementacji. W systemie rozproszonym, środowisku wielowątkowym, w
dodatku silnie zorientowanym na wydajność znacznie trudniej znaleźć przyczynę błędów: błędy silnie zależą od szybkości systemu22,
przez co stają się praktycznie niederministyczne, pojawiają się dopiero po
wielu godzinach23, ponadto
brak dostatecznie wygodnych narzędzi do testowania systemu. Dodatkowym
utrudnieniem może być również konieczność testowania kodu działającego w jądrze
(część kliencka zarządcy wolumenów) lub śledzenia wykonania dużej, złożonej
aplikacji24.
2.2.3 Własności dobrze zaprojektowanego systemu klastrowego
W każdym dobrym
systemie klastrowym, wykorzystującym w pełni możliwości technologii klastrowej,
powinny być spełnione następujące postulaty:
- Równorzędność
i wymienność. System złożony jest z grup
równorzędnych, nie specjalizowanych25
do żadnych konkretnych zadań węzłów. System może wewnętrznie dzielić się na
podsystemy realizujące różne rodzaje zadań (grupa węzłów wykonująca obliczenia, grupa węzłów udostępniająca system plików), ale w obrębie każdej grupy
(podsystemu) węzły mogą wzajemnie zastępować się (np. w przypadku awarii, w odpowiedzi na zmiany obciążenia itp.), dzięki czemu system jest odporny na
awarie, elastyczny i rekonfigurowalny.
- Ciągłość
dostarczania usług. W przypadku awarii węzły mogą
przejmować nawzajem swoje zadania26, zaś awarię węzła można obsłużyć z zachowaniem ciągłości dostarczania usług.
Własność ta związana jest z równorzędnością i wymiennością węzłów27
(to pozwala na przejmowanie obciążenia uszkodzonego węzła) oraz z wymaganiem,
aby cały system stanowił dla klientów jednolity zasób (wówczas wszelkie żądania
klientów mogą być skierowane lub wewnętrznie przekierowane do dowolnego z węzłów).
- Skalowalna
pojemność i wydajność. System jest w naturalny sposób
skalowalny. Dołożenie kolejnych węzłów powiększa proporcjonalnie pulę dostępnych zasobów i (do pewnego stopnia, tzn. z poprawką na ograniczenie
przepustowości wewnątrzklastrowej sieci) zdolność do równoległego przetwarzania żądań. Co więcej, wydajność po awarii, w idealnym przypadku (w odpowiednio
zaprojektowanym systemie) spadnie jedynie proporcjonalnie do spadku liczby węzłów klastra. Własność ta również związana jest z dwoma postulatami
wymienionymi wyżej: możliwością przekierowywania żądań i obsługiwania ich na dowolnym z węzłów.
- Automatyczna
(dynamiczna) rekonfiguracja/optymalizacja. Wszelkie
zmiany warunków działania systemu, włączając w to wszelkiego rodzaju awarie, zmiany obciążenia systemu i zmiany konfiguracji sprzętowej lub programowej,
powinny skutkować automatyczną zmianą konfiguracji systemu w taki sposób, aby zapewnić optymalną wydajność i bezpieczeństwo.
Oto dwa przykłady takich automatycznych czynności:
- W systemie składowania danych po awarii
jednego z dysków trzymających kopie danych wolumenu RAID1 na innym dysku
powinna zostać utworzona dodatkowa kopia, tak, aby zapewnić pożądaną
redundancję danych.
- Przeniesienie fizycznego dysku między
węzłami klastra powinno być automatycznie wykryte przez system, powinny wówczas
zostać dokonane odpowiednie zmiany w konfiguracji, zaś żądania klientów powinny
zostać odpowiednio przekierowane (tak, aby przenieść całe dotychczasowe
obciążenie na nowy węzeł).
Własność
ta wiąże się dwoma wymienionymi wcześniej: ciągłością dostarczania usług i
skalowalnością. W sytuacji awaryjnej system powinien być w stanie np. sam
wybrać wolny nośnik z puli zasobów, które zastąpi uszkodzony fragment wolumenu.
Trudno sobie również wyobrazić, aby w bardzo dużym systemie człowiek za każdym
razem decydował np. o odwzorowaniu wolumenów na fizyczne nośniki. Systemy zdolne do samoczynnego zarządzania na bieżąco
swoją konfiguracją nazywamy systemami
samozarządzającymi (ang. self-management systems).
- Spójna,
globalna administracja. System realizujący wymienione
wcześniej postulaty cechuje wysoka złożoność, polegającą między innymi na
sporej liczbie czynności wykonywanych automatycznie. Działania poszczególnych
węzłów muszą być skoordynowane, a zmiany konfiguracji systemu odbywać się w sposób spójny, zsynchronizowany pomiędzy węzłami i w obrębie węzłów. Wszelkie
zmiany dokonywane przez administratora systemu (człowieka) również muszą być
zsynchronizowane z działaniami systemu i automatycznymi zmianami konfiguracji,
dlatego nie jest możliwe bezpośrednie zarządzanie lokalnymi węzłami, edycja
ustawień, konfiguracji itp. ręcznie, tak, jak dzieje się to przypadku
normalnego systemu operacyjnego. Abstrakcja udostępniona administratorowi
systemu musi opierać się na koncepcji spójnego serwera udostępniającego
globalnie logiczne zasoby (w przeciwieństwie do abstrakcji opartej na zbiorze
węzłów lub procesów, którymi można zarządzać niezależnie).
Mimo, że istnieje
wiele komercyjnych i niekomercyjnych produktów szczycących się „wsparciem dla
klastrów” lub wykorzystujących w jakiś sposób technologię klastrową, niewiele z
nich realizuje choć w części wszystkie z wymienionych postulatów. Najczęściej
realizowany jest, i to jedynie częściowo, postulat ostatni, tzn. globalnej,
spójnej administracji systemem.
Postulat
równorzędności i wymienności jest
dosyć ogólny. System V3 jest podsystemem w obrębie systemu klastrowego28
i nie widać istotnego powodu, dla którego węzły systemu V3 miałyby być
dedykowane do oddzielnych zadań, aby wyróżniać w systemie V3 jakieś podgrupy
funkcjonalne. Dlatego w projekcie systemu V3 przyjęto znacznie silniejsze
założenie: wszystkie węzły systemu V3
są całkowicie równorzędne i wymienne.
Mogą się różnić liczbą lokalnych dysków, ale wszystkie muszą być wyposażone w
to samo oprogramowanie, być
w stanie zastępować się wzajemnie,
zamiennie realizować przydzielone im funkcje.
2.3 Wirtualizacja zasobów systemu
Natychmiastową
konsekwencją wcześniej przyjętych założeń o równorzędności węzłów i spójności
systemu (punkt 2.2.1) jest wirtualizacja wszelkich udostępnianych zasobów,
tj. oddzielenie abstrakcji zasobów udostępnianej klientom od szczegółów budowy
systemu, wchodzących w jego skład fizycznych urządzeń, m.in. ich wydajności,
pojemności i umiejscowienia.
2.3.1 Ogólnie o wirtualizacji zasobów
Z punktu widzenia udostępniania zasobów
podstawowa idea wirtualizacji polega na ukryciu fizycznych zasobów serwera
przed klientem i przeniesieniu części logiki z klienta na serwer. Serwer
powinien porozumiewać się z klientem na poziomie logicznym, tzn. otrzymywać
żądania wyrażone w kategoriach logicznych (wirtualnych) zasobów, odwzorowując
je (często według złożonego schematu) na operacje na fizycznych nośnikach.
Dzięki temu będzie w stanie między innymi:
- weryfikować żądania klientów, włączając w
to zarówno kwestię zgodności z protokołem
klient-serwer29, jak i
praw dostępu, szyfrowania, autoryzacji itp.,
- samodzielnie decydować o skierowaniu
żądań klientów do odpowiednich dysków według dowolnych, nawet dynamicznie zmienianych
odwzorowań (logicznej abstrakcji zasobów na zasoby fizyczne),
- być widziany z zewnątrz jako spójny
system, w którym każdy z węzłów może być pośrednikiem lub bramką (ang. gateway), za pośrednictwem której uzyskuje się dostęp do zasobów.
Koncepcja
wirtualizacji opiera się na pojęciu wirtualnego
wolumenu, który reprezentuje logiczny, wirtualny zasób udostępniany przez
serwer.
2.3.2 Definicja wirtualnego wolumenu
Wirtualny wolumen
(ang. virtual volume) reprezentuje
pojedynczą wirtualną partycję, czyli urządzenie blokowe składające się z pewnej
liczby wirtualnych bloków. Wirtualne bloki odwzorowane są w pewien sposób na
całość fizycznych zasobów serwera w ten sposób, że operacja odczytu/zapisu dla
każdego takiego bloku jest w pewien ściśle określony sposób odwzorowana na
sekwencję operacji na fizycznych nośnikach. Odwzorowanie to zadane jest
wspólnie dla wszystkich bloków wolumenu i nazywamy je organizacją
wolumenu.
Najbardziej typowymi organizacjami wolumenów
będą:
- Wolumen sekwencyjny, czyli taki, który jest dokładnie odworowany na wybrane
urządzenie fizyczne, tzn. ciąg wszystkich bloków wirtualnego wolumenu jest odwzorowany na spójny, ciągły obszar na fizycznym nośniku i operacje adresowane
do poszczególnych wirtualnych bloków przekładają się na dokładnie takie same operacje wykonane na odpowiadających im blokach fizycznych.
- Wolumen skonkatenowany, czyli taki, który powstaje z konkatenacji kilku
wolumenów sekwencyjnych. W takim
wolumenie następujące po sobie spójne ciągi wirtualnych bloków odwzorowane są
dokładnie na fizyczne urządzenia, tak, jak w wolumenie sekwencyjnym.
- Wolumeny RAID0, RAID1, RAID5 itd. realizujące odwzorowania
identyczne, jak w macierzach RAID.
Zauważmy,
że w odwzorowaniach typu RAID, inaczej niż w dwóch wymienionych wcześniej,
operacja na pojedynczym bloku wirtualnym może być odwzorowana na kilka operacji
na różnych blokach fizycznych.
2.3.3 Własności wirtualnych wolumenów
Bazując na postulatach sformułowanych w
punkcie 2.2.1, w poprawnie zaprojektowanym systemie składowania
danych powinniśmy zapewnić następujące własności wolumenów:
- Globalna
widoczność. Wolumen widoczny jest na każdym z węzłów
serwera i każdy z węzłów serwera może (mniej lub bardziej wydajnie) prawidłowo odpowiadać na żądania kierowane do tego wolumenu.
- Złożone odwzorowania. Wolumen może być w złożony sposób
odwzorowany na dowolny podzbiór całości dostępnych zasobów serwera, w
szczególności np. może mieć organizację RAID, w której poszczególne fragmenty
(kolumny) znajdują się na różnych węzłach i dzięki temu zapewniać zwiększoną
wydajność i odporność na awarie.
- Rekonfigurowalność
na bieżąco. Wolumen może być rekonfigurowany, w miarę
możliwości w trakcie pracy systemu i bez przerw w przetwarzaniu żądań klientów,
w szczególności może być przenoszony z jednych nośników fizycznych na inne, jak
również rozszerzany o nową przestrzeń dyskową.
- Wysoka
dostępność wolumenów. Wolumen musi być wysoce dostępny30.
Wszystkie te własności zostały częściowo
zrealizowane w systemie V3 i są omawiane w kolejnych rozdziałach pracy. Kwestię
widoczności i udostępniania zasobów przedstawiamy w rozdziale 5, kwestia
odwzorowań wolumenów na fizyczne nośniki (w tym różne realizacje i ich
efektywność) jest omówiona w rozdziale 7, aspekt rekonfigurowalności w rozdziałach 6
(globalna administracja) i 8 (przejrzystość zmian z punktu widzenia klientów), zaś problem wysokodostępności
i odporności na awarie w rozdziale 9.
2.3.4 Zarządcy wirtualnych wolumenów
Mianem zarządcy
wolumenów (ang. volume manager)
określamy oprogramowanie, które dostarcza następującą funkcjonalność (lub
istotny jej podzbiór):
- utrzymywanie informacji o zasobach, zarówno
fizycznych (dyski, partycje), jak i logicznych (wirtualne wolumeny), ich
wzajemnym przyporządkowaniu, konfiguracji, prawach dostępu itp.,
- zarządzanie konfiguracją systemu,
możliwość zmian konfiguracji, zapewnianie spójności konfiguracji w całym
systemie (np. odpowiednie rozmieszczanie plików konfiguracyjnych,
synchronizowanie ustawień systemowych itp.),
- monitorowanie zasobów w celu zmierzenia
wydajności lub wykrycia potencjalnych awarii,
- udostępnianie zasobów użytkownikowi,
czyli:
- udostępnianie wirtualnych interfejsów
(wirtualnych wolumenów),
- wzbogacenie wirtualnych obiektów o
dodatkowe funkcje, takie jak wbudowany schowek, różnego rodzaju organizacje
danych zapewniające redundancję (dla zwiększenia odporności na awarie) i/lub
zwiększoną wydajność lub elastyczność,
- udostępnianie szeregu różnych funkcji
administracyjnych, takich jak migracje, kopie, zmiany organizacji, zwiększanie
pojemności wolumenów, w szczególności dokonywanych na bieżąco, tj. dostępnych w trakcie normalnego funkcjonowania
systemu (ang. online)31.
Zarządca wolumenów
zazwyczaj obejmuje sterownik (ang. driver)
wirtualnego urządzenia integrowany z systemem operacyjnym oraz dodatkowe
oprogramowanie do zarządzania zasobami, takie jak centralna konsola,
rozproszony system agentów wykonujących zmiany konfiguracji, zbierających
statystyki czy uruchamiających procesy. Typowa architektura (umiejscowienie w
systemie) przedstawiona jest na rys. 2.1.
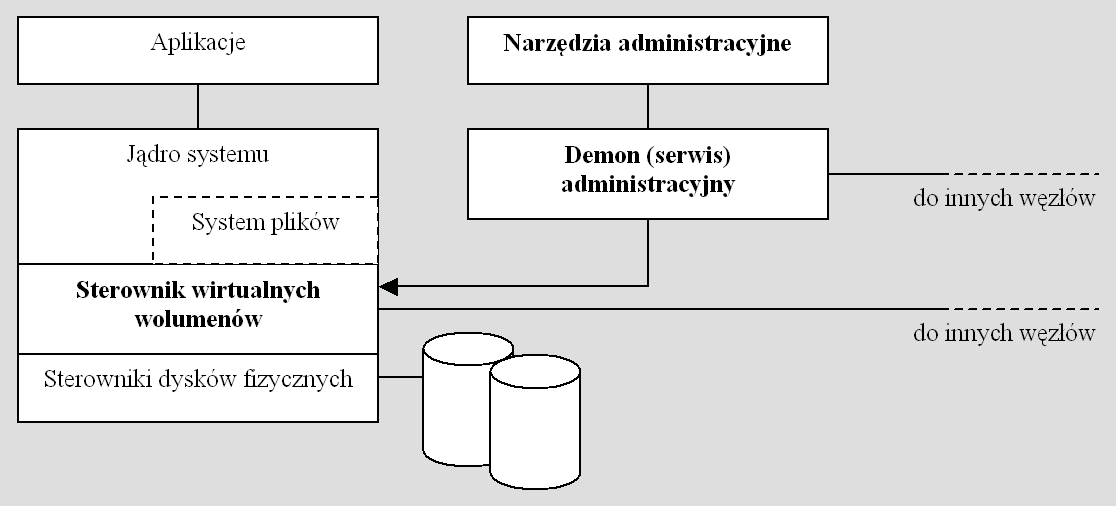
Rys. 2.1 Architektura systemu ze sterownikiem wirtualnych wolumenów.
Wytłuszczonym drukiem zaznaczono elementy,
których nie ma w normalnym systemie. Dwie linie przerywane prowadzące do innych
węzłów reprezentują połączenia w systemach wielowęzłowych. Połączenia te tworzą
jakby dwie warstwy: warstwę, w której komunikują się serwisy administracyjne
(nazwijmy ją, dla odniesienia, warstwą administracyjną) oraz warstwę, w której komunikują się sterowniki i
przesyłane są właściwe dane (nazwijmy ją warstwą
operacyjną). Oczywiście nie w każdym systemie wyposażonym w zarządcę
wolumenów architektura będzie identyczna: modułów może być więcej lub mniej,
mogą inaczej się z sobą komunikować (w szczególności żadna ze znanych autorowi
implementacji nie wspiera systemów wielowęzłowych, w związku z czym nie ma
połączeń, które na rysunku zaznaczono linią przerywaną).
Wszędzie natomiast występują trzy podstawowe
elementy:
- Sterownik
wirtualnych wolumenów. Zawsze jest umiejscowiony
między systemem plików a sterownikami urządzeń fizycznych. Jego zadaniem jest udostępnienie w systemie nowych, wirtualnych obiektów w taki sposób, aby mogły
być używane tak jak zwykłe urządzenia (tzn. tak, aby były nieodróżnialne od urządzeń fizycznych).
- Serwis
systemowy (demon).
Zazwyczaj jest to aplikacja działająca w trybie użytkownika. Realizuje ona
wszelkie czynności, których implementacja w sterowniku nie jest konieczna,
ponieważ:
- programowanie serwisu działającego w
trybie użytkownika jest znacznie prostsze i wygodniejsze niż programowanie
wewnątrz sterownika (czyli w jądrze),
- awarie serwisu nie są groźne (serwis
można ponownie wystartować, odtworzyć połączenia itd.), podczas gdy awaria
sterownika na ogół powoduje awarię całego systemu i utratę danych.
- Narzędzia administracyjne. Są to aplikacje, obecnie na ogół
graficzne, kontaktujące się z systemowym serwisem administracyjnym w celu
sprawdzenia konfiguracji, zmiany ustawień, zainicjowania jakichś czynności itp.
W systemie V3
również występują wymienione trzy elementy, przy czym sterownik wirtualnych
wolumenów powstał na bazie zmodyfikowanej przez autora (o elementy wirtualizacji) biblioteki systemowej odpowiedzialnej za przekazywanie żądań do
jądra32,
zaś serwis i narzędzia administracyjne są elementami (wielowęzłowej) warstwy
administracyjnej, omówionej szczegółowo w rozdziale 6.
2.4 Odciążenie klienta kosztem serwera
Koncepcja przenoszenia obciążenia z klienta
na serwer stoi w sprzeczności z obecną praktyką. Najpierw więc przedstawiamy
obecne tendencje, by później skupić się na proponowanym alternatywnym
rozwiązaniu i jego związkach z technologią klastrową.
2.4.1 Migracja obciążenia w stronę klienta w systemach nieklastrowych
2.4.1.1 Wydłużająca się ścieżka dostępu do informacji
W tradycyjnych
(tzn. nie-klastrowych) systemach opartych na modelu klient-serwer obserwujemy
od pewnego czasu tendencję do umiejscawiania coraz bardziej skomplikowanej
funkcjonalności związanej z dostępem do danych na kolejnych poziomach
(warstwach), za które odpowiadają osobne grupy serwerów, np. w tradycyjnej dużej konfiguracji w przedsiębiorstwie znajdziemy następujące trzy warstwy:
- Warstwę urządzeń blokowych: dyski, często
w architekturze SAN, podłączone albo bezpośrednio (wprost do światłowodu), albo
za pośrednictwem serwerów (interfejs SCSI), ostatnio udostępniające także
wybrane operacje wyższego rzędu (np. migrację danych, archiwizację), ale
realizowane w zasadzie wyłącznie w oparciu o mechanizmy sprzętowe.
- System plików, osadzony na jednym lub
(nieco rzadziej) na wielu serwerach, wykorzystujących interfejs urządzeń
blokowych udostępniany przez niższą warstwę.
- Serwery aplikacji, bazujące na
poprzedniej warstwie, np. udostępniające różnego rodzaju obiekty i złożone operacje
na danych.
Stosowanie takiego
podejścia jest na ogół konieczne ze względu na modularność, niepodobieństwem
jest łączyć różne poziomy abstrakcji (bloki dyskowe, pliki, obiekty
bazodanowe). Wiążą się z tym jednak pewne problemy:
- Ścieżka dostępu do informacji wydłuża
się: trzeba przesłać więcej komunikatów, odebrać więcej przerwań, jest więcej
przełączeń kontekstu, każda warstwa wprowadza dodatkowe obciążenie związane ze
zmianą poziomu abstrakcji. Rośnie więc czas dostępu do danych.
- Przetwarzanie (logika) jest dalej od
danych, większy czas dostępu ma bezpośrednie przełożenie na czas realizacji
wszelkich operacji na danych.
Sposobem
na poradzenie sobie z tym byłoby realizowanie przetwarzania tam, gdzie
przechowywane są dane. W tradycyjnych systemach problem ten rozwiązany jest na odwrót, oto przykłady.
- Maszyny klienckie wyposażane są w
schowki, których celem jest przybliżenie danych do klienta.
- Stosowane są techniki takie jak
indeksowanie plików itp.
W
obu przypadkach to klient musi implementować dodatkową funkcjonalność,
klientowi stawia się dodatkowe wymagania sprzętowe (np. pamięć na schowki),
klient realizuje dodatkowe przetwarzanie. Obciążenie (nie tylko obliczenia, ale
także złożoność i koszt) migruje więc w stronę klienta.
2.4.1.2 Brak dostatecznej skalowalności systemu
Kolejnym powodem
przenoszenia obciążenia na klienta jest problem ze skalowalnością: koszt
serwera rośnie szybciej niż liniowo z rozmiarem udostępnianej przestrzeni
dyskowej i zdolnością do przetwarzania żądań, czyli pojemnością. W związku z powyższym część logiki serwera bywa
włączana do części klienckiej systemu, klient wykonuje niektóre spośród
operacji logicznie przynależnych do serwera. Przykładem tego zjawiska może być
aplikacja korzystająca z sieciowego systemu plików i wykonująca na nich
operacje takie jak np. szyfrowania/deszyfrowanie, kompresja/dekompresja czy
wyszukiwanie w podkatalogach, wykorzystując do tego cykle lokalnego procesora.
Zasadniczym problemem tutaj jest nie
tylko gorsza wydajność tych operacji (ponieważ dokonują się na danych, które
nie są lokalne), lecz także obciążenie maszyny klienta, co w przypadku np.
serwerów aplikacji ma bezpośredni, wyraźny wpływ na wydajność.
2.4.2 Migracja obciążenia w stronę serwera w systemach klastrowych
Dzięki wyjątkowym
cechom systemów klastrowych możliwe jest proste rozwiązanie niektórych
problemów tradycyjnych systemów, w związku z czym koncepcja klastrowego systemu
składowania danych w niektórych punktach idzie w przeciwnym kierunku, tzn.
obliczenia i funkcjonalność migrują w stronę serwera.
2.4.2.1 Wykorzystanie mocy procesorów na węzłach serwera
System klastrowy
jest w naturalny sposób skalowalny, ma sporą pamięć operacyjną i moc
obliczeniową, w praktyce jest mocno niewykorzystany i ma mnóstwo wolnych cykli
procesora. Fakt powyższy jednoznacznie zweryfikowano w praktyce na przykładzie
systemu V3, gdzie procesor znakomitą większość czasu spędzał na aktywnym lub
pasywnym oczekiwaniu. Płynie stąd wniosek, iż można i należy jak najbardziej
odciążać klienta kosztem serwera33,
ponieważ z punktu widzenia systemu jako całości (serwerów zasobów dyskowych,
serwerów aplikacji) wydajność jest dzięki temu wyraźnie lepsza.
2.4.2.2 Wykorzystanie inteligencji węzłów serwera
Węzły serwera, w
odróżnieniu od dysków, kontrolerów dyskowych itp. mogą mieć wbudowaną
nietrywialną inteligencję, dzięki czemu można uniknąć niektórych warstw i
skrócić ścieżkę dostępu do informacji.
Dla przykładu:
- Można rozszerzyć protokół klient-serwer i wzbogacić go o autoryzację, szyfrowanie
itp. Obecnie żadne z urządzeń dyskowych nie posiada i zapewne długo jeszcze nie
będzie posiadać takiej funkcjonalności – udostępnianie danych w bezpieczny
sposób wymaga np. serwera pośredniczącego, do którego podłączone są dyski i
który udostępnia je poprzez własny system plików. W systemach klastrowych nie
jest to konieczne: węzły mogą posiadać mechanizmy bezpieczeństwa, a serwery
aplikacji są bezpośrednio podłączone do systemu.
- Warstwy znajdujące się nad warstwą blokową (nazwijmy tak umownie
warstwę udostępniającą interfejs urządzeń blokowych) można (dzięki inteligencji węzłów) do niej dolepiać, tzn. oprócz interfejsu urządzeń blokowych węzły mogą
również udostępniać interfejsy wyższych warstw, np. system plików. Daje to następujące korzyści:
- pewien procent odwołań będzie lokalny, a
w niektórych przypadkach węzeł obsługujący żądanie klienta będzie tym samym
węzłem, który zawiera odpowiednie bloki dyskowe – unikamy dzięki temu
niepotrzebnej komunikacji,
- możliwa jest lepsza integracja warstw,
np. system samozarządzający się, posiadający zdolność do sterowania równoważeniem
obciążenia i optymalizowania swojej konfiguracji, w tym lokalizacji danych,
może reorganizować warstwę blokową pod kątem potrzeb wyższych warstw.
Obie powyższe korzyści można oczywiście osiągnąć również w tradycyjnych
systemach, ale ponieważ nie da się oprogramować w taki sposób fizycznych dysków ani kontrolerów dyskowych, konieczne jest obciążenie serwerów, które z nich
korzystają (np. serwerów plików), a więc obciążenie wyższej warstwy,
przesunięcie obciążenia w stronę klienta, wbrew postulatowi sformułowanemu
wcześniej.
Natomiast obecność w systemie klastrowym
szybkiej międzywęzłowej sieci o dużej przepustowości i bardzo małym opóźnieniu
powoduje, że zlepianie warstw (umieszczanie dodatkowych warstw na tym samym
zbiorze węzłów) jest bardziej opłacalne niż w tradycyjnych systemach, w których
kolejne warstwy odwołują się do siebie na ogół za pośrednictwem sieci Ethernet
i protokołu opartego na TCP/IP.
2.5 Podsumowanie
W dalszej części pracy będziemy często
korzystać z wprowadzonych wyżej definicji systemu
klastrowego i wirtualnego wolumenu.
Będziemy brać pod uwagę nasze postulaty projektowe (wprowadzone w punktach 2.2.1, 2.2.3 i 2.3.3) oraz (sformułowane w punkcie 2.4) założenia odnośnie wirtualnych wolumenów.
Przypomnijmy je tutaj w skrócie.
Główne
założenia projektowe
- Wszystkie węzły w systemie są równorzędne
i wymienne.
- System stanowi (z punktu widzenia
klientów systemu) jednolity zasób.
- Zapewniamy ciągłość dostarczania usług
klientom (tzn. minimalizujemy prawdopodobieństwo wystąpienia przerwy w
udostępnianiu usług aplikacjom).
- Zapewniamy skalowalność pojemności i
wydajności.
- Wyposażamy system w zdolność do
automatycznej (dynamicznej) rekonfiguracji/optymalizacji.
- Administracja systemem jest globalna.
- Staramy się jak najbardziej odciążać
klienta kosztem serwera.
- Wolumeny są widoczne globalnie, w obrębie
całego serwera.
- Możliwe są złożone odwzorowania wolumenów
na fizyczne nośniki.
- Możliwa jest rekonfiguracja wolumenów na bieżąco.
- Zapewniamy wysokodostępność wolumenów (minimalizujemy łączny czas
wyłączeń systemu).
Wirtualizacja zasobów będzie zrealizowana w
oparciu o koncepcję zarządcy wolumenów
(opisaną w 2.3.4).
Należy zaznaczyć, że powyższe założenia nie
wyczerpują całej listy, są to tylko założenia pierwotne. Oprócz tego dalej
czynimy założenia dodatkowe, np. związane z upraszczaniem implementacji.
Przykładem mogą być założenia dotyczące sesji (patrz p. 5.3), dzięki którym prostsza jest obsługa błędów.
19 Może za wyjątkiem sytuacji, w której dyski z dwoma interfejsami SCSI
podłączone są do dwóch węzłów.
20 Komponenty sieciowe wykorzystywane w systemach klastrowych (np. karty
Giganet) są stosunkowo drogie, stanowią jeden z głównych składników kosztu
systemu.
21 Patrz punkt 2.3.4.
22 W praktyce często zdarzało się, że błędy pojawiające się w wersji
systemu przeznaczonej do dystrybucji (ang. release)
znikały, gdy autor stosował (odrobinę wolniejszą) wersję przeznaczoną do
testowania i wyłapywania błędów (ang. debug).
23 W trakcie pracy nad systemem wielokrotnie zdarzało się, że fatalny
błąd pojawiał się dopiero po kilkunastu godzinach intensywnych testów.
24 Pracując nad częścią kliencką systemu w wersji wykorzystującej
zmodyfikowaną bibliotekę systemową odpowiedzialną za przekazywanie żądań
aplikacji do jądra systemu (w systemie Windows NT/2000 jest to kernel32.dll) autor musiał np. śledzić
wykonanie głównego procesu serwera bazy danych ORACLE, w kontekście którego
wykonywał się kod tej biblioteki, co było dodatkowym utrudnieniem ze względu na
wzajemne zależności między wątkami procesu serwera ORACLE i wątkami testowanej
biblioteki systemowej.
25 Chodzi o specjalizację w sensie specjalnej architektury, wyposażenia w
specjalne podzespoły sprzętowe itp.
26 Oczywiście pod pewnymi warunkami, np. w przypadku systemu składowania
danych zapewnienie możliwości wzajemnego przejmowania obowiązków przez różne węzły może polegać na zastosowaniu organizacji RAID lub użyciu dysków o
podwójnych interfejsach SCSI.
27 Niekoniecznie wszystkich węzłów, ale przynajmniej w ramach jakichś grup,
tak, aby dla każdego węzła istniał co najmniej jeden inny, który może go
zastąpić.
28 Zgodnie z uwagą z punktu 2.2.1.2 możemy powiedzieć, że V3 jest
serwerem w obrębie klastra.
29 Chodzi o protokół, którego klienci używają w komunikacji z serwerem,
patrz p. 4.4.4.
30 Definicja tego pojęcia i odniesienia do literatury są podane dalej, w
punkcie 9.2.2.2.
31 W literaturze angielski termin „online”
często bywa tłumaczony na „tryb
bezpośredni”. Autor zdecydował się tu jednak na konsekwentne używanie
zwrotu „na bieżąco”, który dokładniej
oddaje sens terminu „online” w tym
konkretnym konteście.
32 Część kliencką systemu V3 zaimplementowano dotychczas jedynie w wersji
dla systemu Windows NT, tutaj wspomnianą biblioteką systemową jest kernel32.dll.
33 Będzie to jedno z naszych założeń projektowych.