|
W poprzednich rozdziałach naszkicowano cele systemu oraz przedstawiono istniejące środowiska o podobnych zastosowaniach. W oparciu o te dane można określić wymaganą funkcjonalność, potrzebną do zrealizowania celów. W kolejnych podrozdziałach zostanie przedstawiony projekt bardziej złożonych części systemu.
Techniczne, szczegółowe informacje na temat zastosowanych rozwiązań znajdują się w kolejnym rozdziale (rozdz. 4).
System oraz język LSP przede wszystkim musi realizować wszystkie założenia przedstawione we wstępie. Musi zatem zapewniać następującą funkcjonalność:
Główną część systemu stanowią mechanizmy odpowiedzialne za wczytywanie oraz interpretację programów zapisanych w języku LSP. Wszystkie instrukcje tego języka powinny być zapisywane jako węzły dokumentu XML, bądź wyrażenia XPath.
Język LSP ma służyć do przetwarzania danych i tworzenia dokumentów. Wszystkie operacje powinny być jak najprostsze. Celem jest bowiem dostarczenie języka, w którym można będzie zapisać logikę aplikacji wraz z generowaną treścią, bez konieczności wyrażania tej logiki za pomocą niskopoziomowych instrukcji, jak to ma miejsce w zwykłych językach programowania.
Parser, czyli środowisko wykonania, musi zapewniać dostęp do danych oraz niskopoziomową realizację wszystkich funkcji języka.
Język ma zapewniać proste operacje, dostępne w większości języków programowania, tj. obsługę zmiennych oraz funkcji na nich działających, jak również wyrażeń logicznych i konstrukcji, takich jak pętle oraz wykonywanie warunkowe. Nie powinien zawierać żadnych niskopoziomych operacji.
System powinien dostarczać możliwości bezpośredniego pobierania danych z bazy (za pośrednictwem zapytań SQL, nie będących częścią języka) oraz wywoływania procesora XSLT.
Jest to jedno z najbardziej skomplikowanych zagadnień etapu projektowego, ponieważ trudno jest stworzyć schemat autoryzacyjny nadający się do dowolnych zastosowań. Jednak w celu zapewnienia pełnej funkcjonalności LSP musi posiadać system autoryzacji na tyle dobry, aby można go było zastosować w większości prostych aplikacji.
Poza wszystkimi wymienionymi wymaganiami, również istotnymi przy tworzeniu aplikacji, system powinien dostarczać funkcje potrzebne przy tworzeniu serwisów internetowych, takie jak obsługa sesji, generowanie formularzy HTML na podstawie danych pobranych z bazy, weryfikacja wprowadzanych danych oraz automatyczna obsługa typowych formularzy (tj. takich, które wymagają jedynie wstawiania bądź uaktualniania danych w bazie).
W wielu sytuacjach stosowanie XSLT do generowania dokumentów wyjściowych jest niemożliwe bądź kosztowne. Dlatego też system powinien potrafić przekształcać dokumenty wyjściowe do najczęściej używanych formatów, takich jak PDF (poprzez TeX lub bezpośrednio) oraz pliki tekstowe. Formatem wejściowym dla tych konwersji powinien być podzbiór XHTML, dzięki temu można pisać aplikacje używając jedynie LSP oraz XHTML.
System musi umożliwiać dodawanie do języka nowych instrukcji, pobieranie danych z innych źródeł oraz wywoływanie funkcji zewnętrznych. Jest to konieczne w odniesieniu do programów, w których wymagane są operacje niemożliwe do zrealizowania w samym LSP, lecz nie są to operacje kluczowe dla programu.
W kolejnych rozdziałach szczegółowo przedstawiono projekt interpretera, założenia systemu autoryzacji oraz wymagania dotyczące rozszerzeń i funkcjonalności specyficznej dla aplikacji WWW.
W systemie LSP została zastosowana technologia TWIG (zob. p. 2.1.1), gdyż daje ona te same możliwości co DOM, a jednocześnie nie posiada jego wad oraz znacznie lepiej używa się jej w Perlu. Ze względu na brak możliwości wielokrotnego przetwarzania węzłów w istniejącej implementacji TWIG, w LSP zastosowano własną o podobnej zasadzie działania.
TWIG ma oczywiście ograniczenia wynikające z niemożliwości sięgnięcia do już przetworzonych węzłów, ale konstrukcja systemu LSP nie wymaga takich operacji, w związku z czym jest to najlepsze rozwiązanie dla tego zastosowania.
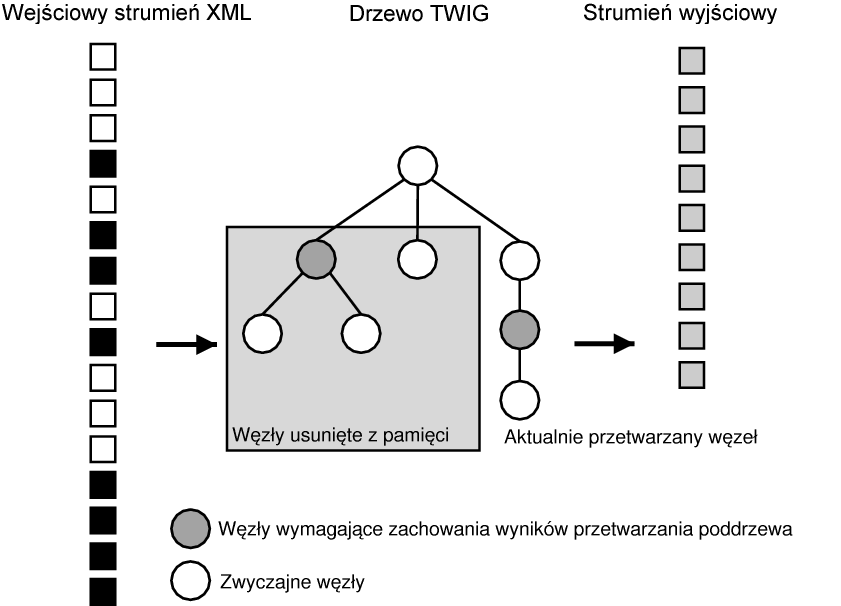
Rysunek 3.1 przedstawia zasadę działania modelu TWIG. Strumień wejściowy XML (składający się z odpowiadających sobie otwierających i zamykających znaczników, oznaczonych odpowiednio kolorami białym i czarnym) jest w miarę wczytywania przekształcany na drzewo struktury. W drzewie tym pewne węzły (oznaczone szarym kolorem) do przetworzenia wymagają wyników przetwarzania całego swojego poddrzewa. Pozostałe nie mają takich ograniczeń i ich poddrzewa można usunąć z pamięci (na diagramie niepotrzebne węzły są objęte szarym prostokątem).
W trakcie przetwarzania kod odpowiadający za obsługę poszczególnych węzłów generuje dokument wyjściowy, na diagramie przedstawiony jako ciąg szarych pudełek. Elementy wyjściowe tworzą kolejny strumień, który może być przesłany do procesora XSLT, przetworzony na inny format dokumentu wewnątrz LSP, bądź też po prostu przesyłany do użytkownika.
Dzięki takiej konstrukcji LSP może zarówno przetwarzać duże dane wejściowe, jak i generować bardzo duże dokumenty, nie zużywając ogromnych ilości pamięci.
Zgodnie z założeniami instrukcje języka powinny być zapisywane jako
węzły dokumentu XML.
LSP musi także zawierać operacje na zmiennych
(służących między innymi do przechowywania danych wejściowych) oraz
konstrukcje językowe reprezentujące same zmienne.
Ponieważ zapisywanie tych bardzo częstych operacji jako węzłów XML
byłoby niewygodne, postanowiłem do tego celu wykorzystać standard
XPath -- stanowiący również część XSLT i innych
języków operujących na XML, jak np. XQL![[*]](footnote.png) .
.
XPath wykorzystuje się w LSP do adresowania dokumentów XML wczytywanych z dysku i tworzonych na podstawie danych pobieranych z baz SQL, jak również do obsługi zmiennych. Dzięki wykorzystaniu istniejącego standardu, rozwiązuje się problem przetwarzania dokumentu w celu dokonania wartościowania zmiennych, gdyż można do tego celu wykorzystać gotowe biblioteki.
Działanie interpretera przy wykorzystaniu drzewa struktury sprowadza się do zdefiniowania procedur obsługi węzłów będących instrukcjami języka. Dzięki użyciu XML można wykorzystać istniejące metody dostępu do parametrów instrukcji (czyli atrybutów elementów drzewa).
Pozostała treść aplikacji, czyli węzły XML nie należące do LSP oraz tekst (czyli węzły tekstowe), jest wykorzystywana zgodnie z zasadą działania instrukcji LSP, do której przynależy. W najprostszym przypadku jest ona -- po zinterpretowaniu wszystkich wyrażeń XPath -- kopiowana do dokumentu wyjściowego.
Działanie każdej instrukcji języka LSP obejmuje więc następujące etapy:
W kilku przypadkach instrukcje LSP wymagają wykonania pewnych operacje przed przeczytaniem treści, na przykład wstawienia elementów do dokumentu wyjściowego.
Ten etap może być wykonywany wielokrotnie, zależnie od zasady działania odpowiedniej instrukcji języka. Przykładowo podczas pobierania danych z bazy, zawartość węzła zostanie przetworzona dla każdego rekordu wynikowego przekazanego przez zapytanie.
Po zakończeniu przetwarzania poddrzewa mogą być wykonywane operacje, które do działania potrzebują całości wygenerowanych danych, jak na przykład przetwarzanie XSLT.
Pozostaje sformułowanie podstawowej funkcjonalności języka, tj kluczowych instrukcji. Poniższa lista zawiera grupy funkcji, które musi realizować główna część LSP, w kolejnych podrozdziałach są również omówione specyficzne instrukcje wymagane do zrealizowania pozostałych funkcji systemu. Pełny opis języka znajduje się w dodatku A.
Aplikacja LSP musi zawierać główny węzeł (APPLICATION - A.4.1). Element ten nie ma żadnej funkcjonalności, jego interpretacja to po prostu wypisanie zawartości po przetworzeniu.
Ważna jest też instrukcja wykonywania innej aplikacji LSP (INCLUDE - A.4.10). Powoduje ona wstawienie do dokumentu wyjściowego wyniku działania tej aplikacji. Ta instrukcja języka jest przetwarzany inaczej niż zwykłe - jej zawartość służy do przekazania podprogramowi parametrów wykonanania.
Język LSP zawiera instrukcje przetwarzania warunkowego (IF - A.4.5, ELSE - A.4.6) oraz instrukcję wyboru (CHOOSE - A.4.7). Istnieje również jedna instrukcja pętli (WHILE - A.4.8). Działanie tych instrukcji jest dość oczywiste.
XPath służy jedynie do wartościowania zmiennych, więc operacje takie jak pobieranie parametrów z zewnątrz i przypisywanie ich do zmiennych (PARAM - A.4.3), czy też po prostu nadawanie wartości (SET - A.4.4) muszą być realizowane w LSP. Zawartość węzła w obu przypadkach nie jest kopiowana do dokumentu wynikowego, zamiast tego używana jest ona jako wartość przypisywana na zmienną.
Poza instrukcjami potrzebnymi do realizacji wymagań, wymienionymi w tym oraz w kolejnych podrozdziałach, język zawiera również kilka instrukcji dodanych w celu umożliwienia lepszego wykorzystania możliwości środowiska LSP. Są one opisane w rozdziale 4 (oraz w opisie języka, w dodatku A).
Środowisko LSP ma służyć do tworzenia aplikacji bazodanowych, więc kluczowym elementem jest pobieranie danych i ich przetwarzanie. Możliwe jest pobieranie danych z relacyjnych baz SQL oraz z statycznych plików XML. Dane mogą być przetwarzane za pomocą XSLT. Jeżeli te możliwości nie są wystarczające dla potrzeb aplikacji, to jest możliwe proste dodawanie nowych źródeł danych, jak również funkcji przetwarzających.
Pobieranie danych z baz SQL możliwe jest dzięki instrukcji QUERY (A.4.2). Programista musi jedynie wyspecyfikować bazę danych, z której chce pobierać dane, oraz wykonywać zapytania. Rekordy pobierane z bazy są automatycznie zamieniane na postać XML i przypisywane na określoną przez programistę zmienną.
Możliwe jest też pobieranie i przetwarzanie dokumentów XML przechowywanych w bazie SQL.
LSP potrafi pobierać dokumenty XML z dysku i przypisywać je do zmiennych (za pomocą instrukcji LOAD - A.4.9). Następnie można je wykorzystywać w aplikacji za pomocą wyrażeń XPath. LOAD może działać podobnie jak QUERY - możliwe jest podanie maski nazwy pliku. W takim przypadku zawartość węzła zostanie przetworzona wielokrotnie, dla każdego pasującego pliku.
Możliwe jest też zapisywanie zmiennych zawierających dokumenty XML na dysku za pomocą operacji STORE (A.4.12). Zasada działania tej instrukcji jest podobna do zasady działania operacji SET, jakkolwiek wartość nie jest przypisywana do zmiennej tylko do pliku.
Integracja LSP z XSLT umożliwia przetwarzanie wyników działania przy użyciu arkusza stylów. Służy do tego instrukcja TRANSFORM (A.4.14). Zawartość takiego węzła jest przetwarzana, a następnie wynik jest wykorzystywany jako wejście dla procesora XSLT.
LSP zapewnia kilka możliwości rozszerzenia, m.in prosty
mechanizm służący (przede wszystkim) do pobierania danych z
innych źródeł niż wymienione wcześniej.
Służy do tego instrukcja CALL (A.4.13).
Funkcja ta działa podobnie jak QUERY, tyle że zamiast wywoływać
zapytania SQL, wywołuje (stworzoną przez twórcę aplikacji) funkcję,
napisaną w Perlu i przekazującą wynik działania w postaci tablicy
haszującej.
Umożliwia to dodanie nowego źródła danych bez konieczności głębszego
poznawania działania LSP, a także proste dodawanie funkcji nie
będących źródłami danych, ale realizujących jakąś specyficzną funkcjonalność
potrzebną do działania aplikacji.
LSP dostarcza złożony system autoryzacji, który stanowi dobrą podstawę do zabezpieczenia aplikacji. System ten jest dość uniwersalny, choć mogą znaleźć się zastosowania wymagające bardziej złożonych mechanizmów.
System wspiera logowanie użytkowników poprzez przekazanie specjalnych parametrów określających nazwę użytkownika oraz hasło. W celu przekazania tych informacji można skorzystać ze specjalnie do tego celu stworzonych typów danych login i password instrukcji PARAM (A.4.3). System przechwyci takie parametry i spróbuje zalogować użytkownika do systemu. Jeżeli użytkownik jest nieokreślony, a w niektórych zastosowaniach użytkownik zawsze będzie nieokreślony, system autoryzacji zakłada, że nie ma on żadnych uprawnień.
Podstawowe pojęcia
Program wykorzystujący system autoryzacji do udostępniania swoich funkcji użytkownikom.
Zbiór mechanizmów umożliwiających w miarę ogólny sposób określania uprawnień użytkowników do pewnych funkcji aplikacji wyższego poziomu.
Przykładowo, rekord opisujący dane klienta jest obiektem -- rekordem typu dane klienta. Funkcja wykonująca pewne obliczenia dla użytkownika też jest obiektem, klasy np. funkcja matematyczna.
Obiektem z punktu widzenia systemu autoryzacji jest wszystko to do czego aplikacja może chcieć mieć dostęp. Klasy obiektów, obiekty same w sobie są definiowane przez aplikację, system autoryzacji dostarcza tylko ogólnych metod weryfikacji praw dostępu do funkcji i danych.
Ogólny schemat dostępu do obiektu
Niech użytkownik X dysponuje zestawem uprawnień Y (listy uprawnień są obsługiwane przez system autoryzacji, więc z punktu widzenia systemu użytkownik to tak naprawdę identyfikator listy uprawnień). Użytkownik ten chce wykonać pewną operację A na obiekcie O. Obiekt O jest klasy C. System ma dostarczyć mechanizm do weryfikacji, czy użytkownik określony przez identyfikator Y może wykonać operację A na obiekcie klasy C.
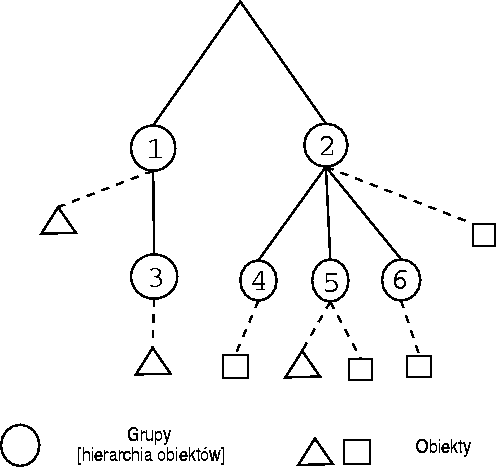
W skrócie można ten schemat opisać w następujący sposób: użytkownik może mieć dostęp do pewnych klas obiektów przynależących do określonych grup (oraz ich podgrup).
Diagram 3.2 przedstawia przykładowy model hierarchii obiektów w systemie LSP.
Uwagi
Zależności między grupami są częścią systemu autoryzacji (ale są konfigurowane przez aplikację), przynależności obiektów do grup są określane wyłącznie przez aplikację.
Rozszerzony schemat dostępu do obiektu
Użytkownik określany identyfikatorem Y chce wykonać akcję A na obiekcie klasy C, który znajduje się (lub np. jest tworzony) w grupie G. System sprawdza listy uprawnień, znajdując takie, które są przypisane do tego konkretnego użytkownika, określają prawa do wykonywania akcji A na obiektach klasy C lub zgodnych (można użyć '*' jako nazwy klasy lub akcji, oznacza to prawo do wszystkich klas lub akcji). Grupa określona w danym wpisie w bazie uprawnień musi być nadgrupą grupy G. Jeżeli grupa w tabeli nie jest określona, oznacza to grupę domyślną, czyli grupa G musi być podgrupą jednej z grup, do których należy użytkownik Y.
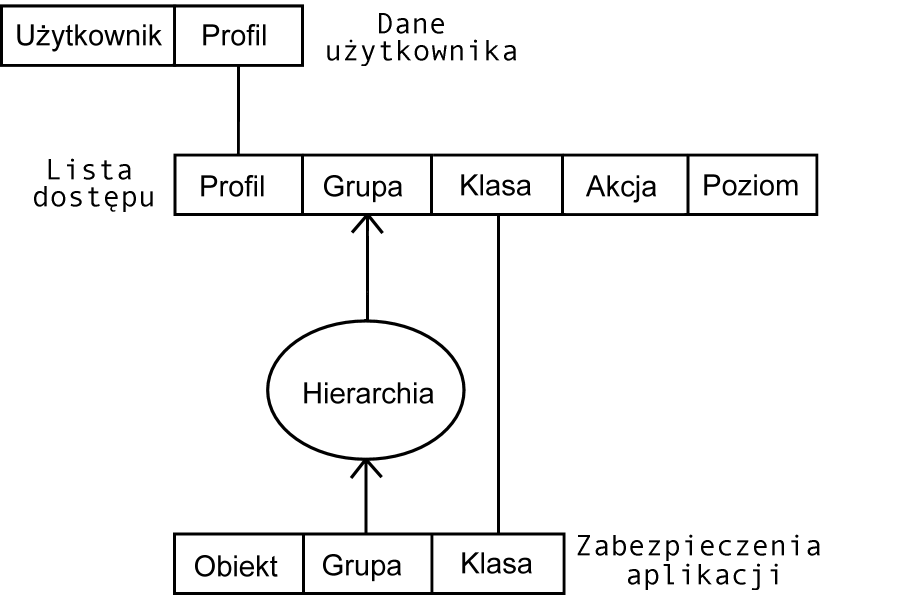
Diagram 3.3 ilustruje schemat działania mechanizmów autoryzacyjnych.
Aplikacja sprawdza czy pewien jej obiekt, który jest klasy Klasa i należy do grupy Grupa, może być udostępniony użytkownikowi Użytkownik o profilu dostępu Profil. Dodatkowym parametrem jest Akcja, którą użytkownik chce na tym obiekcie wykonać. System autoryzacji przechowuje listy dostępu określające wszystkie możliwe sytuacje, w których powinien zezwolić na dostęp, z dodatkowo określonym poziomem Poziom, który może być dowolnie wykorzystany przez aplikację.
Przykładowo użytkownik JanKowalski, który jest przypisany do profilu Klient chce zmodyfikować pewien dokument w systemie. Dokument ten należy do klasy Dokument. Uprawnienia określają, że może to zrobić dla np. grupy OponyWiosenneSA, czyli jego firmy. Dodatkowo, określają też że dla żądanej operacji (akcji) typu Modyfikacja ma zapewniony dostęp na poziomie 5. Aplikacja do modyfikacji dokumentu wymaga poziomu 3, więc uprawnienia zostają przyznane, jakkolwiek zostają zablokowane niektóre elementy dokumentu, wymagające poziomu 6.
Gdyby ten sam użytkownik usiłował wykonać identyczną operację na dokumencie należącym do innej firmy, dostęp zostałby zablokowany.
Klasa obiektu, operacja oraz poziomy uprawnień są określone w aplikacji. Grupa jest pobierana z bazy danych bądź z dokumentu, natomiast uprawnienia użytkownika z tabeli autoryzacyjnej w bazie systemu LSP. Sama aplikacja nie musi sprawdzać kim jest jej użytkownik, polityka bezpieczeństwa jest więc w przejrzysty sposób podzielona na definiowanie zabezpieczeń w aplikacji oraz przyznawanie uprawnień użytkownikom.
W celu wykorzystania mechanizmów autoryzacyjnych, spora część instrukcji języka LSP została rozszerzona o wspólny zestaw atrybutów autoryzacyjnych (A.3.1), umożliwiających zdefiniowanie do jakiej klasy obiektów wymagane są uprawnienia, aby można było wykonać daną funkcję, do jakiej grupy należy ten obiekt oraz jakiego poziomu operacja jest wymagana.
Najprostszym przykładem zastosowania jest instrukcja IF, umożliwiająca uzależnienie przetworzenia jej zawartości od spełnienia wymagań autoryzacyjnych.
Można prosto pokazać jak przydaje się rozróżnienie klasy obiektu, grupy oraz poziomu. Klasa obiektu jest na stale przypisana do fragmentu aplikacji o ograniczonym dostępie. Grupa może wynikać z przetwarzania danych pochodzących z bazy SQL i chęci pokazywania jedynie tych informacji, które użytkownik może zobaczyć. Poziom z kolei może powodować udostępnianie bardziej zaawansowanych funkcji lub bardziej szczegółowych danych.
Dla ułatwienia tworzenia i przetwarzania formularzy, LSP zawiera instrukcje umożliwiające tworzenie list wyboru i pól wprowadzania tekstu na podstawie informacji pobieranych z bazy danych. Formularze takie mogą być też automatycznie obsługiwane, w przypadku operacji wstawiania oraz aktualizowania danych działających tylko na jednej tabeli.
Formularz generowany przez LSP umożliwia reprezentację jednego rekordu z jednej tabeli z bazy SQL. Nie jest możliwe edytowanie w ten sposób plików XML; to niestety zbyt skomplikowane zagadnienie. Sam formularz jest obsługiwany za pomocą instrukcji FORM (A.4.17). Instrukcja ta wymaga podania nazwy tabeli, z której pobierane będą dane, nazwy klucza oraz identyfikatora rekordu do edycji. W bardziej skomplikowanych sytuacjach można też wykorzystać zapytanie SQL do wyboru rekordu. Jeśli podany zostanie klucz oraz pusty identyfikator, to zostanie stworzony formularz nowego rekordu (z pustymi bądź domyślnymi wartościami pól).
Formularze mogą zawierać trzy rodzaje komponentów odpowiadających danym z bazy: pola tekstowe (INPUT - A.4.18), pola wyboru (LINK - A.4.19) oraz pola logiczne (BOOLEAN - A.4.21). Pola wyboru umożliwiają powiązanie z co najwyżej jednym kluczem obcym. Wszystkie komponenty mogą mieć zdefiniowane wartości domyślne (w przypadku list wyboru określa się domyślną wartość klucza obcego). Pola tekstowe mogą być różnych typów, odpowiadających typom zmiennych obsługiwanych przez LSP.
Dodatkowo jest też obsługiwana instrukcja BUTTON (A.4.20), umożliwiający wstawianie do formularzy przycisków, których wybranie spowoduje przekazanie wartości z formularza do wybranego podprogramu LSP bądź wywołanie automatycznej obsługi formularzy.
Dzięki wbudowanym zaawansowanym mechanizmom obsługi sesji, wszystkie dane o formularzu, który został wygenerowany dla użytkownika, mogą zostać przechowane właśnie w sesji. System może stwierdzić na podstawie zachowanych danych do jakiej tabeli powinien wstawić dane przesyłane przez użytkownika oraz czy przesyłane dane są poprawne (tzn. czy użytkownik nie usiłuje przesłać danych niezgodnych z wygenerowanym formularzem, np. o nieodpowiednich typach, lub, w przypadku list wyboru, o wartości nie będącej prawidłowym kluczem obcym). Pełna specyfikacja formularza, zachowana w sesji, jest porównywana z przesłanymi danymi. Po wykorzystaniu, informacje o formularzu są usuwane, dzięki temu automatycznie uzyskuje się zabezpieczenie przed wielokrotnym przetworzeniem tego samego formularza.
Po weryfikacji przesłane dane są tłumaczone na odpowiednie instrukcje SQL i wykonywane. Mechanizm ten umożliwia jedynie operacje na pojedynczych tabelach i pojedynczych rekordach. Ponieważ jednak właśnie takie operacje stanowią olbrzymią większość wszystkich operacji na danych w typowych aplikacjach bazodanowych, więc możliwości te bardzo ułatwiają tworzenie takich programów. Bardziej zaawansowane operacje można zaimplementować zapisując je w LSP, bądź też jako rozszerzenia systemu -- w Perlu.
W przypadku bardzo prostych aplikacji, jak również na etapie tworzenia prototypów systemu, może nie być wymagane operowanie wyłącznie na dokumentach XML i przetwarzanie ich za pomocą XSLT. Niezależnie od tego przydatne jest tworzenie dokumentów w postaci PDF czy też tabeli w postaci arkuszy Excel. W celu umożliwienia wykorzystania takich funkcji w prostych aplikacjach, LSP zawiera moduł przekształcający minimalny podzbiór HTML na TeX (i pośrednio także PDF) oraz XLS.
Generowanie dokumentów jest uaktywniane na podstawie rozszerzenia pliku zażądanego przez użytkownika z przeglądarki WWW. Rozszerzenia xml, html, lsp powodują wygenerowanie dokumentu w formacie HTML. Na podstawie nazwy żądanego pliku, system określa aplikację LSP która powinna zostać uruchomiona w celu wygenerowania treści dokumentu (Aplikacje te na dysku posiadają rozszerzenie lsp).
Dla innych formatów można użyć rozszerzenia tex, pdf bądź xls. Tak więc aby z aplikacji wygenerować dokument PDF, należy po prostu skierować użytkownika do dokumentu o nazwie identycznej z aplikacją, która generuje treść tego dokumentu, ale o rozszerzeniu pdf zamiast lsp bądź xml.
LSP umożliwia przekształcanie wynikowego dokumentu z HTML na LaTeX oraz, wykorzystując program pdflatex, do postaci PDF. Obsługiwane znaczniki to bardzo skromny podzbiór możliwości formatujących HTML (elementy B, I, CODE, PRE, CENTER, BR, P, NBSP) oraz obsługa prostych (nie zagnieżdżonych) tabel (elementy TABLE, TH, TR, TD).
Przetwarzanie takie odbywa się po stworzeniu całego dokumentu HTML przez aplikację LSP. Znaczniki nie obsługiwane przez aplikację zostaną automatycznie usunięte. Aplikacja może też kontrolować, które części dokumentu mają być dostępne w różnych formatach, wykorzystując systemową zmienną format (zob. p. A.2).
Podczas generowania dokumentów w formacie XLS wykorzystywany jest również podzbiór HTML. W tym przypadku jednak obsługiwane są jedynie znaczniki służące do obsługi tabel (identyczne jak w przypadku TeX oraz PDF). Poszczególne tabele w dokumencie przekształcane są na odrębne arkusze. Wszelkie formatowanie jest ignorowane.
W p. 3.3.4 przedstawiono mechanizm rozszerzania LSP poprzez definiowanie nowych źródeł danych, umożliwiający również tworzenie ogólnych rozszerzeń. Poza tą możliwością istnieją jeszcze dwa mechanizmy.
Pisząc odpowiedni filtr można prosto dodać obsługę nowego formatu wyjściowego. Filtry są programami zupełnie niezależnymi od całego LSP, są wykonywane przez środowisko w przypadku zażądania odpowiedniego typu dokumentu. Filtr otrzymuje na standardowym wejściu wygenerowaną przez aplikację LSP treść dokumentu i powinien przekazać wynik, wypisując go na standardowe wyjście.
Dzięki tej bardzo prostej metodzie, można bardzo poszerzyć możliwości aplikacji nie wykorzystujących XSLT, a także zrealizować przekształcenia trudne bądź mało wydajne przy zastosowaniu XSLT (np. zamiana standardu kodowania dokumentu).
LSP umożliwia także tworzenie bibliotek znaczników, całkowicie zintegrowanych z systemem. Wymaga to dogłębnego zapoznania się z środowiskiem LSP, w szczególności, w przeciwieństwie do pozostałych technik rozszerzeń, konieczna jest dobra znajomość źródeł systemu. Jednak po zapoznaniu się ze sposobem realizacji istniejących instrukcji, pisanie kolejnych jest już łatwe.
Mechanizm działania wszystkich instrukcji jest przedstawiony w p. 3.2.3. Nie jest on skomplikowany, tak więc ich implementacja też nie może być bardzo skomplikowana. Najprostsza instrukcja -- kopiująca po prostu zawartość -- to jeden wiersz kodu. Trudniejsze jest tworzenie instrukcji korzystających ze zmiennych, systemów autoryzacji i uwierzytelniania, różnych źródeł danych.
Niestety nie ma tu miejsca na szczegółowe opisanie całego kodu systemu. Szczegółowe opisy znajdują się w komentarzach zawartych w tym kodzie i tam należy szukać pomocy przy pisaniu nowych modułów.
W tej części pracy przedstawiono jedynie wybrane, najbardziej złożone fragmenty systemu. Pominięto problemy związane z tworzeniem środowiska, ale nie dotyczące bezpośrednio wskazanych we wstępie celów systemu LSP. Niektóre z tych zagadnień, związane z implementacją, są przedstawione w kolejnym rozdziale.