|
W kolejnych podrozdziałach zarysowana jest architektura systemu, wykorzystane techniki programistyczne oraz najistotniejsze kwestie techniczne.
Całość kodu jest napisana w Perlu, z wykorzystaniem istniejących parserów XML, XSLT oraz kilku modułów pomocniczych. Umożliwia to instalację na prawie dowolnej platformie serwerowej, jak również wykorzystanie olbrzymiej biblioteki gotowych modułów do Perla w celu rozszerzenia systemu.
System może pracować jako aplikacja CGI, FastCGI oraz moduł serwera WWW Apache (również dostępnego na większości platform).
Funkcjonalność systemu jest rozbita na kilka niezależnych modułów. Celem tego rozdziału jest przedstawienie co każdy z nich realizuje oraz opisanie w skrócie sposobu ich wykonania. Nazwy modułów użyte w tym rozdziale odpowiadają nazwom modułów Perla, jak również nazwom plików zawierających ich implementację.
Moduł główny, o nazwie LSP, służy przede wszystkim jako część łącząca razem wszystkie pozostałe moduły. Z tego modułu korzysta interfejs CGI oraz FCGI (stanowiący niezależny program), natomiast interfejs Apache zaimplementowany jest bezpośrednio w tym module.
Core (czyli rdzeń) zawiera implementację parsera języka LSP oraz kod funkcji odpowiadających za obsługę podstawowych jego elementów. Moduł ten udostępnia też interfejs, pozwalający innym modułom na dodawanie własnych procedur obsługi elementów języka. Realizuje funkcjonalność zdefiniowaną w p. 3.2.
Autoryzacja jest jednym z podstawowych elementów systemu. Funkcjonalność tego modułu jest bardzo złożona, choć sama implementacja jest dość prosta. Dokładny opis autoryzacji znajduje się w sekcji 3.4, a opis wykorzystania możliwości w A.3.1 (Atrybuty autoryzacyjne).
Moduł składa się głównie z zapytań do tabel autoryzacyjnych (zob. p. 4.5.1), znajdujących się w systemowej bazie danych.
Moduł zapewnia obsługę sesji użytkownika. Do obsługi sesji wykorzystywane są jednorazowe identyfikatory, przekazywane użytkownikowi za pomocą ciasteczka HTTP i przesyłane do serwera przy każdym uruchomieniu aplikacji. W przypadku metod dostępu uniemożliwiających korzystanie z ciasteczek, system po zalogowaniu wysyła wraz z wynikami identyfikator sesji, a do użytkownika należy obowiązek przekazywania go do serwera. LSP dostarcza tylko interfejsów działającychprzez HTTP, więc do wykorzystania innych metod dostępu potrzebne jest stworzenie nowego, specjalnego interfejsu. Identyfikator sesji jest zmieniany po każdym kolejnym wywołaniu, celem uniemożliwienia podszycia się pod użytkownika.
Sesja służy do przechowywania w niej wartości które są potrzebne do wygenerowania kolejnych dokumentów. System LSP sam korzysta z sesji, między innymi do przechowywania informacji o użytkowniku oraz danych o wygenerowanych formularzach. Fizycznie, sesje są zapisywane w jednej tabeli w systemowej bazie danych. Tabela ta zawiera trzy pola -- identyfikator sesji, klucz oraz wartość. Moduł używa zastrzeżonych nazw kluczy (zaczynających się od znaku podkreślenia, "_") do przechowywania własnych informacji.
Ze względu na spore możliwości, jakie zapewnia ten moduł, postanowiłem rozszerzyć język LSP o możliwości przechowywania dowolnych zmiennych w sesji użytkownika. Służą do tego instrukcje KEEP (A.4.15) oraz FIND (A.4.16) służące, odpowiednio, do zachowywania wartości zmiennej w sesji oraz do ich pobierania.
System umożliwia automatyczną obsługę prostych formularzy generowanych za pomocą komponentów formularzy (opisanych w dodatku A.4). Tym właśnie zajmuje się moduł Edit, zawierający również funkcje pomocnicze wykorzystywane przez komponenty formularzy.
Aby uniknąć konieczności przetwarzania całego formularza po raz kolejny, podczas jego generowania wszystkie informacje niezbędne do weryfikacji przechowuje się w sesji (zob. p. 4.2.4). Po przetworzeniu dane te są usuwane. Jednocześnie dzięki temu niemożliwe jest przesłanie identycznego formularza dwa razy poprzez przejście wstecz i ponowne wysłanie z przeglądarki -- trzeba jeszcze przeładować formularz.
Działa tu mechanizm sprawdzania poprawności typów podobny do tego, który zastosowano do sprawdzania poprawności parametrów aplikacji (por. p. A.4.3). W szczególności, jeśli mechanizmy automatycznej obsługi nie wystarczają do zrealizowania celu, można zastąpić automatyczną obsługę oddzielną aplikacją, która wykona zadanie posługując się danymi wygenerowanymi z formularza oraz informacjami zapisanymi w sesji. Można też wykorzystać mechanizm automatycznej obsługi bez korzystania z komponentów formularzy, jednak wtedy trzeba samemu zajmować się sprawdzaniem poprawności.
Mechanizm sprawdzania poprawności zastosowany do weryfikacji formularzy ma dwa ważne rozszerzenia, nie wykorzystywane przy obsłudze parametrów aplikacji. Po pierwsze umożliwia przekazywanie wartości ukrytych -- nie są one przesyłane do użytkownika, tylko zapamiętywane w sesji i wykorzystywane przy automatycznej obsłudze formularza. Po drugie jest możliwe weryfikowanie, czy wybrana wartość klucza obcego jest jedną z wartości przekazanych użytkownikowi w liście wyboru w formularzu -- system przechowuje wszystkie możliwe wartości pola w tablicy sesji.
Moduł ten zawiera mechanizmy rozszerzania funkcjonalności systemu poprzez definiowanie filtrów (por. p. 3.7.1) oraz funkcji wywoływanych za pomocą mechanizmu CALL (por. p. 3.3.4). W tym module także zaimplementowano standardowe filtry konwertujące do formatów TeX, PDF oraz XLS.
Moduł Cache obejmuje wszelkie funkcje związane z buforowaniem. Jego możliwości są wykorzystywane przez najróżniejsze części systemu LSP. Moduł zapewnia obsługę kilku rodzajów buforów: globalnego, związanego z sesją i tymczasowego. Bufory tymczasowe niszczone są w całości po obsłużeniu każdego wywołania, globalne nie są nigdy usuwane, zaś bufory związane z sesją trwają tak długo, jak sesja.
Bufory mogą mieć ograniczony całkowity rozmiar w bajtach, liczbę elementów lub być nieograniczone. Moduł implementuje dwa algorytmy zwalniania miejsca -- kolejkę FIFO oraz LRU (ang. Least Recently Used, technika polegająca na usuwaniu najdawniej używanego elementu bufora).
Więcej informacji o wykorzystywaniu buforowania w LSP znajduje się w kolejnym rozdziale.
Ponieważ środowisko działa w trybie serwerowym, więc utrzymywanie gotowych połączeń do baz danych jest bardzo proste. Dzięki temu aplikacja łączy się z każdą bazą tylko raz, co znacznie skraca narzut związany z uruchamianiem.
Buforowanie połączeń (ang. connection pooling) jest szczególnie przydatne wtedy, gdy baza danych jest uruchomiona na innym komputerze niż serwer aplikacji. W takiej sytuacji narzuty na otwieranie połączeń są największe.
System sam potrafi zarządzać liczbą jednocześnie utrzymywanych połączeń, w razie potrzeby tworząc nowe.
Sterowniki baz danych umożliwiają przygotowanie zapytań przed ich wykonaniem, większość z nich umożliwia również przygotowywanie zapytań korzystających z wartości przekazywanych przez referencję (ang. bind values - wartości związane). Takie zapytanie może być potem wykonywane wielokrotnie z różnymi parametrami.
LSP umożliwia efektywne wykorzystanie tej techniki, buforując zapytania w obrębie pojedynczej odsłony, sesji, bądź globalnie (domyślnie używany jest bufor globalny, co jest najefektywniejsze).
Źródłowe pliki po wczytaniu i zredukowaniu do minimalnego potrzebnego drzewa (np. znaczniki nieobsługiwane przez system są zamieniane na tekst) są przechowywane w globalnym buforze, w postaci gotowej do uruchomienia.
Wszelkie stałe elementy oraz funkcje inicjujące związane z jedną aplikacją są uruchamiane tylko jeden raz.
Możliwe jest też buforowanie fragmentów wygenerowanego dokumentu (por. opisy elementów, p. A.4.11). Ten element języka został dodany do środowiska w celu umożliwienia wykorzystania tego bardzo przydatnego narzędzia w aplikacjach użytkownika.
Jest to użyteczne, jeśli pewien fragment dokumentu wyjściowego jest zależny od tylko kilku parametrów. Dzięki temu elementy te mogą być generowane tylko raz, co znacznie przyspiesza działanie w niektórych zastosowaniach.
Jeżeli zapytanie przekazuje niewiele wyników, to można zaoszczędzić na jego wykonywaniu, zapamiętując same wyniki. Taki bufor jest domyślnie ważny jedynie do końca jednego przetworzenia aplikacji, choć istnieją zastosowania, w których sensowne jest buforowanie wszystkich wyników (np. jeśli jakieś dane zmieniają się bardzo rzadko).
LSP może działać jako aplikacja CGI bądź FastCGI oraz jako moduł Apache (por. p. 4.1). W pierwszym i drugim przypadku aplikacja obsługiwana jest przez program lsp.cgi. W trzecim przypadku w konfiguracji serwera Apache należy dodać obsługę katalogu aplikacji przez moduł LSP.pm. Konfiguracja interfejsu jest omówiona w dodatku B.
Parametry wywołania pobierane są z argumentów CGI. Wyniki zwracane są poprzez protokół HTTP.
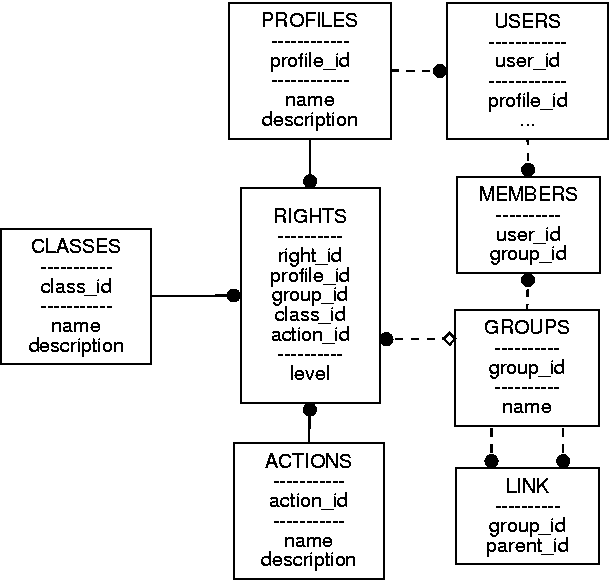
Informacje o użytkownikach przechowywane są w tabelach users, members, groups, link. Po zainstalowaniu podstawowego systemu, można dodać nowe pola do tych tabel, na potrzeby przechowywania własnych informacji (podstawowe dane w tabeli users zawierają identyfikator, nazwę użytkownika oraz hasło).
Diagram 4.1 ilustruje zależności między wszystkimi tabelami. W kolejnych punktach znajdują się bardziej szczegółowe opisy tabel.
Tabela użytkowników. Znajdują się tu wszyscy użytkownicy systemu. Poza polami służącymi do uwierzytelniania (przedstawionymi na diagramie) może zawierać np. dane osobowe i kontaktowe.
Każdy użytkownik (określany przez pole user_id) może być związany z wieloma grupami (pole group_id). Tabela members zawiera właśnie przyporządkowanie użytkowników do grup. Jest to podstawa do określania dostępu do danych w systemie.
Profile uprawnień. Każdy użytkownik ma przypisany jeden profil, z kolei profile są używane w tabeli Rights do wyznaczenia zbioru uprawnień, przysługujących danemu użytkownikowi.
Struktura (drzewo) grup użytkowników. Pole parent określa grupę nadrzędną, name to pole napisowe zawierające nazwę grupy.
Umożliwia tworzenie grafowej a nie drzewiastej struktury grup, Tabela ta reprezentuje wiązanie typu wiele do wielu pomiędzy grupami.
Centralna tabela systemu uprawnień, zawiera wiązanie profili z konrektnymi przywilejami (możliwościami wykonywania pewnych akcji na pewnych obiektach). Dzięki polu group_id można definiować uprawnienia do dowolnych grup, niezależne od przynalezności użytkownika. Gdy pole to jest równe NULL, to uprawnienie dotyczy wszystkich grup, do których należy dany użytkownik. Jeżeli jest ustawione, to dotyczy tylko wyspecyfikowanej grupy.
Proste tabele zawierające identyfikatory i opisy, odpowiednio, akcji oraz klas obiektów.
Tablica sesji (sessions) składa się z trzech pól:
Liczbowy identyfikator sesji;
klucz, czyli identyfikator, według którego przechowywane są wartości zmiennych w sesji, jest to nazwa takiej zmiennej;
wartość zmiennej; klucze i wartości są typu napisowego.
System LSP wykorzystuje tylko najbardziej podstawowe polecenia SQL do operowania na własnych tabelach, dzięki czemu jest zgodny z większością istniejących systemów bazodanowych. Wykorzystywany był głównie z bazami PostgreSQL oraz MySQL.
Do wykorzystania automatycznej obsługi formularzy, a dokładniej do automatycznego wstawiania danych do bazy, wymagane jest automatyczne przyznawanie kluczy głównych -- LSP nie jest w stanie zrobić tego w bezpieczny sposób. Poza tym wymaganiem, kwerendy generowane przez system automatycznej obsługi formularzy z powodzeniem działają na większości istniejących systemów bazodanowych obsługujących SQL.
Implementacja LSP rozszerza nieco możliwości systemu przewidziane w projekcie. Wprowadzone zmiany umożliwiają pisanie bardziej efektywnych aplikacji, dzięki umożliwieniu lepszej kontroli nad działaniem mechanizmów sesji oraz buforowania. Komentarze zamieszczone w kodzie zawierają bardziej szegółową jego dokumentację, przytaczanie jej tu w całości byłoby bezcelowe. Szczegółowy opis języka LSP, niezbędny do wykorzystywania LSP do tworzenia własnych aplikacji znajduje się zaś w dodatku A.