W tym rozdziale znajduje się opis budowy translatora języka TLCC. Opis ten odnosi się do poszczególnych części składowych mechanizmu translacji, począwszy od analizy kodu, a skończywszy na wygenerowaniu docelowej aplikacji. Program został napisany dla systemu operacyjnego Linux, przy wykorzystaniu biblioteki MICO CORBA [9]. Kod źródłowy programu znajduje się na załączonej dyskietce (por. dodatek C).
Specjalne konstrukcje dostępne w TLCC wymagają odpowiedniej analizy leksykalnej i składniowej kodu. Głównym problemem jest to, że działanie leksera nie może się ograniczać do prostego rozpoznawania poszczególnych elementów leksykalnych, lecz wymaga także interpretowania niektórych konstrukcji języka. Przyczyna tego jest taka, że pewne symbole, jak np. nawiasy kwadratowe, są innymi leksemami w bloku instrukcji (indeks w tablicy), a innymi w wizualizatorach (blok wizualizacji).
W analizatorze leksykalnym pamięta się, czy aktualnie czytany kod należy do wizualizatora. Przejście do tego trybu następuje w momencie napotkania słowa kluczowego visualizer, a wyjście z tego trybu - po wczytaniu końca definicji wizualizatora. Wewnątrz wizualizatora domyślnie wszystkie znaki '[' traktowane są jako rozpoczęcie bloku wizualizacji. Wyjątkami są jedynie identyfikatory oraz typy danych (po których znak '[' może wystąpić w sensie operatora tablicowego).
W momencie napotkania znaku kończącego blok, czyli ']', jako leksem przekazuje się właśnie utworzony napis (kod HTML). Zmienia się stan leksera i z powrotem na wejściu umieszczany jest znak ']'. Dopiero w tym nowym stanie może on zostać zinterpretowany jako koniec bloku i przekazany w postaci leksemu.
Dzięki użyciu pojedynczego, prostego symbolu dla bloków wizualizacji, wstawianie kodu HTML w programie jest bardzo proste i przejrzyste.
Jeśli chcemy wstawić zwykłą instrukcję w bloku wizualizacji, należy użyć symbolu '#'. Symbol ten oznacza zarówno początek, jak i koniec bloku instrukcji. Z punktu widzenia analizy leksykalnej, napotkanie tego znaku powoduje przejście leksera do stanu, w którym normalnie rozpoznaje wszystkie słowa kluczowe i symbole języka, z tym, że dopuszcza specjalne użycie nawiasów kwadratowych (jako bloków wizualizacji).
W blokach '#' możliwe jest również bezpośrednie wypisywanie wartości wyrażeń. Po napotkaniu znacznika końca takiego bloku jako leksem przekazywany jest średnik. Jeśli ostatnim elementem przed znakiem '#' było wyrażenie (bez średnika na końcu), to wraz z tym dodatkowym średnikiem stanie się ono instrukcją (zawierającą wyrażenie). Natomiast w przeciwnym razie ostatnim elementem bloku zostanie instrukcja pusta. Zatem podczas generowania kodu będzie można rozróżnić te dwie sytuacje.
Dzięki specjalnym znacznikom wstawianie wyrażeń z języka TLCC w kodzie HTML jest proste i nie wymaga stosowania dodatkowych funkcji wypisujących dane wyrażenie. Również łatwo stosuje się samo przejście do bloku instrukcji.
Kolejnym elementem, który wymaga specjalnej obsługi jest możliwość wielokrotnego zagnieżdżania bloków poszczególnych rodzajów. Implementacja tej cechy w analizatorze leksykalnym sprowadza się do utrzymywania licznika zagnieżdżonych bloków wizualizacji i zagnieżdżonych bloków instrukcji. Dzięki temu wiadomo, w jaki sposób interpretować poszczególne symbole. Przykładowo, po napotkaniu znaku ']' istotne jest czy był to ostatni (na najwyższym poziomie) blok wizualizacji i czy poziom zagnieżdżenia zwykłych bloków instrukcji jest równy 1 (ponieważ cały czas jesteśmy wewnątrz definicji klasy). W takim wypadku oznacza to, że właśnie zakończyła się definicja wizualizatora i lekser powinien przejść do innego trybu pracy (tzn. czytania definicji klasy).
Natomiast z punktu widzenia analizy składniowej wygodne jest potraktowanie każdego ciągu znaków, który został wprowadzony wewnątrz bloku wizualizacji (aż do znaku specjalnego, takiego jak ']' czy '#') jako pojedynczego leksemu. Dzięki temu składnia wizualizatorów (jeśli chodzi o ich gramatykę) nie różni się zbytnio od składni zwykłych funkcji. Otóż definicje wizualizatorów złożone są z ciągu elementów, którymi mogą być: instrukcje, bloki wizualizacji lub ciągi znaków wizualizacji (które są tymi specjalnymi leksemami). Taką samą budowę ma również każdy zagnieżdżony blok wizualizacji.
Po wykonaniu analizy leksykalnej i składniowej kodu, przeprowadzana jest analiza kontekstowa. Jej celem jest sprawdzenie zgodności typów danych, wywołań funkcji, poprawności użycia różnych identyfikatorów itp. Dzięki temu, że kod napisany w TLCC jest analizowany kontekstowo mamy pewność, że wynikowa aplikacja w C++ będzie poprawna i nie wystąpią błędy kompilacji w ostatniej fazie generowania programu.
Analizator kontekstowy dla translatora TLCC w większości zaimplementowany jest w sposób standardowy. Dla programu wejściowego pamięta się drzewo symboli (klas, funkcji, zmiennych itd.) i w przypadku napotkania pewnego identyfikatora ustalany jest jego typ, na podstawie informacji zawartych w tym drzewie. Jedyne niestandardowe konstrukcje, opisane w tej części, związane są z obsługą akcji i wizualizatorów.
W przypadku napotkania definicji akcji w wizualizatorze zadaniem analizatora kontekstowego jest zbudowanie listy wszystkich zmiennych, których wartości powinny być zachowane aż do wykonania tej akcji. Kod akcji może odwoływać się do zmiennych lokalnych zadeklarowanych w tym wizualizatorze, więc istnieje potrzeba przywrócenia ich wartości, gdy użytkownik zażąda wykonania danej akcji.
Analizator sprawdza wszystkie odwołania do zmiennych wewnątrz akcji, a następnie ustala czy była to zmienna lokalna, czy atrybut pewnego obiektu. W ten sposób budowana jest lista zmiennych lokalnych, których używa bieżąca akcja. Zmienne z tej listy będą zachowywane w odnośniku, który zostanie stworzony na podstawie definicji akcji.
Jednyną sytuacją w TLCC, gdzie jako parametr funkcji można podać nazwę innej funkcji, jest wbudowana konstrukcja set_visualizer(). Służy ona do zmiany wizualizatorów dla danego obiektu. Zadaniem analizatora kontekstowego w tym przypadku jest odszukanie właściwego elementu w tablicy symboli dla odpowiedniej klasy i sprawdzenie czy rzeczywiście podana funkcja jest wizualizatorem.
Podobna sytuacja zachodzi również w przypadku użycia wbudowanej funkcji set_root(), która zmienia korzeń wizualizacji dla bieżącej sesji. Jako parametr pobiera ona dowolny obiekt, przy czym konieczne jest sprawdzenie czy klasa tego obiektu posiada wizualizatory. Jedynie w takim przypadku obiekt ten może się stać nowym korzeniem wizualizacji.
Klasy, których definicje znajdują się w programie, nie muszą posiadać wizualizatorów. Jednak gdy już jakieś posiadają, to musi się wśród nich znajdować wizualizator domyślny, definiowany przy pomocy słów kluczowych default visualizer. Zatem kolejnym zadaniem analizatora kontekstowego jest niedopuszczenie do sytuacji, gdy wśród wizualizatorów klasy nie ma wizualizatora domyślnego.
W tym punkcie opisuję sposób tworzenia wynikowego kodu w C++, na podstawie kodu w TLCC. Każda specjalna konstrukcja tłumaczonego języka musi być zastąpiona odpowiednimi instrukcjami C++, które w wielu przypadkach wykorzystują bibliotekę CORBA (odwzorowanie standardu CORBA na C++ jest omówione w pozycji [7]). Program wygenerowany w ten sposób jest następnie kompilowany przy pomocy zwykłego kompilatora (gcc) i tworzony jest plik wykonywalny. Działanie wynikowego programu polega na udostępnieniu interfejsu, opartego na systemie CORBA, który pozwala obsługiwać żądania HTTP.
W zależności od miejsca wystąpienia w programie pewnego typu danych, tłumaczy się go na różne typy w C++. W niektórych miejscach kodu (np. w wywołaniach funkcji) trzeba użyć typów dostarczanych przez bibliotekę CORBA. Natomiast w innych sytuacjach wymagane jest użycie takiego typu, który będzie obsługiwać operacje dostępne w TLCC (np. dla zmiennej typu string trzeba użyć specjalnej klasy wspierającej operacje na łańcuchach). Tabela 4.1 przedstawia zestawienie typów języka TLCC z tymi, które są użyte w generowanym kodzie.
|
W przypadku typów złożonych, takich jak struktury, tablice czy napisy, wykorzystywane są specjalne klasy bądź struktury, które pozwalają wykonywać różne dodatkowe operacje. Natomiast typy dostarczane przez bibliotekę CORBA są używane jedynie do wymiany danych między obiektami, podczas wywołań funkcji. Przykładowo klasa String, która wewnętrznie obsługuje napisy, pozwala efektywnie dopisywać do nich tekst. W przypadku wbudowanych tablic klasa Array umożliwia wydajną zmianę ich rozmiaru (w szczególności dodanie nowego elementu). W kodzie źródłowym programu klasa Array zdefiniowana jest jako wzorzec, ponieważ zależy od rodzaju tablicy i musi pobierać zarówno typ wewnętrzny, jak i odpowiadający mu typ z biblioteki CORBA dla swoich elementów. Natomiast przy wywołaniach funkcji, które wymagają użycia tablic, wykorzystywane są sekwencje udostępniane przez system CORBA (np. StrSeq, którą należy zdefiniować w pliku IDL jako sekwencję napisów).
Wszystkie konwersje między typami wewnętrznymi, a typami z biblioteki CORBA wykonywane są za pomocą odpowiednich operatorów konwersji. Trzeba przy tym zwrócić uwagę na prawidłowe zwalnianie pamięci związanej z danymi, które zostały przekształcone i nie będą dłużej potrzebne (np. wynikami funkcji).
Operacje przypisania odnoszące się do takich typów danych jak tablice, struktury czy napisy są dosyć czasochłonne. Przyczyną tego jest konieczność kopiowania wszystkich buforów pomiędzy jedną zmienną, a drugą. Aby ograniczyć narzut z tym związany dobrze jest przeciążyć operator przypisania w C++.
Można zauważyć, że nie zawsze trzeba kopiować wszystkie dane, gdy występuje przypisanie. Można w nowym obiekcie, np. klasy String lub Array, ustawić wskaźnik na bufor obiektu, z którego nastąpiło przypisanie. Zatem obiekty te będą dzieliły wspólny bufor. Jednak w momencie, gdy zawartość jednego z nich będzie wymagała zmiany, kopiowanie i oddzielenie ich zawartości jest niezbędne. Opłaca się odkładanie tego kopiowania tak długo, jak to tylko możliwe.
Implementacja tego mechanizmu sprowadza się do utrzymywania listy obiektów, które dzielą ten sam bufor danych. W momencie przypisania jednego napisu na inny, kopiuje się jedynie wskaźnik do wspólnego bufora, a docelowy obiekt dołączany jest do odpowiedniej listy. Zmiana napisu, który korzysta z dzielonego bufora wymaga wcześniejszego usunięcia obiektu z listy i utworzenia jego własnej kopii bufora.
Ze względu na to, że w definicjach klas mogą się pojawić rodzaje atrybutów, które nie są obsługiwane przez C++ (np. shared), należy każdą klasę odpowiednio przetłumaczyć. Dla zwykłych atrybutów trzeba wygenerować funkcje, które będą umożliwiały zarówno pobieranie wartości zmiennej, jak i przypisanie na tą zmienną (są to przykładowo funkcje get_zmienna() i set_zmienna()). Oczywiście wszystkie typy danych, które pojawiają się przy tym procesie muszą być też poddane tłumaczeniu, zgodnie z poprzednim punktem. Translacja ta odnosi się również do poszczególnych funkcji składowych klasy.
Specjalnego potraktowania wymagają atrybuty statyczne, których widoczność ogranicza się do pojedynczej sesji. Oznacza to, że każda sesja musi mieć swoje własne kopie takich atrybutów. Aby to osiągnąć, trzeba wygenerować specjalną klasę, która zawiera wszystkie zdefiniowane zmienne statyczne w bieżącym pliku (w TLCC). Wyjątek stanowią stałe zdefiniowane jako static const. W tym przypadku nie ma potrzeby tworzenia kopii tych atrybutów. Wystarczy, aby były to stałe globalne w procesie serwera obiektów. Natomiast jeśli chodzi o funkcje statyczne, to są one tłumaczone na zwykłe funkcje statyczne w sensie C++, oczywiście z dokładnością do translacji typów.
Bardziej skomplikowane jest generowanie kodu dla atrybutów dzielonych. Ponieważ atrybuty te muszą być przechowywane na serwerze obiektów dzielonych, więc trzeba podzielić analizowaną klasę na dwie nowe:
Ponadto wynikowa klasa musi posiadać pewne dodatkowe pola i metody, związane z obsługą akcji, wizualizatorami itp. Dokładny opis tych specjalnych elementów klasy znajduje się w następnych punktach.
Podobnie jak definicje klas, tak i definicje wszystkich funkcji programu w TLCC muszą być odpowiednio przetworzone przez translator. Istnieje wiele różnych sytuacji, w których wejściowy kod musi zostać przekształcony. Już w momencie rozpoczęcia tłumaczenia treści funkcji należy wygenerować dodatkowe instrukcje, które przetłumaczą parametry funkcji w taki sposób, aby ich typ odpowiadał typom używanym lokalnie. Przykładowo, wskaźnik do łańcucha znaków trzeba przekształcić na obiekt klasy String. To samo dotyczy takich typów jak obiekty, struktury i tablice. Szczególną uwagę należy zwrócić na wskaźniki do obiektów, dla których trzeba zadeklarować zmienne typu Nazwa_var (gdzie Nazwa odpowiada nazwie klasy), aby zapewnić automatyczne zwalnianie referencji. Konieczne jest także zduplikowanie otrzymanego dowiązania do obiektu, gdyż może ono zostać przypisane na pewną zmienną klasową, a wszystkie parametry zdalnie wywołanej funkcji są automatycznie usuwane przez system CORBA po zakończeniu wywołania.
Poszczególne atrybuty mogą się znajdować wewnątrz specjalnych klas pomocniczych (atrybuty statyczne i dzielone), więc trzeba to uwzględnić przy odwołaniach do nich. Ponadto w przypadku wyrażeń zawierających operator dostępu do elementów klasy (kropka), konieczne jest wykorzystanie specjalnych funkcji służących do pobierania i ustawiania wartości atrybutu (gdyż może to być dostęp zdalny).
Ponadto istnieją też inne przypadki, gdy konieczna jest modyfikacja wejściowych instrukcji. Przykładowo, rzutowanie typu dla obiektów musi być wykonane przy pomocy funkcji udostępnianej przez bibliotekę CORBA - _narrow(), a nie przez operator C++. Również podczas tworzenia obiektu za pomocą operatora new z TLCC, należy najpierw utworzyć referencję do tego obiektu, a następnie rzutować ją na zdalny typ, gdyż prawdopodobnie nastąpi przypisanie referencji na jakąś zmienną. Przy pierwszym odwołaniu do nowo utworzonej referencji, obiekt typu Nazwa_impl zostanie zaalokowany i aktywowany w POA.
Innym przykładem jest porównywanie zmiennych typu obiektowego przy użyciu operatora '=='. Nie wystarczy tutaj zwykłe porównanie w sensie C++, ponieważ mogą to być różne obiekty, zawierające jednak referencję do tego samego obiektu zdalnego. W tym przypadku zatem wymagane jest sprawdzenie referencji, które są przechowywane w tych obiektach.
Klasa nadrzędna (definiowana przez translator) dla wszystkich klas programu napisanego w TLCC posiada atrybut, który zawiera wskaźnik na bieżący wizualizator dla konkretnego obiektu tej klasy. Jednak pojawia się tutaj pewien problem, polegający na tym, że zmienna ta nie może zawierać po prostu wskaźnika do metody tej klasy (w sensie C++). Przyczyna tego jest taka, że wskaźnik ten musi również przechowywać dowiązania do metod (którymi są wizualizatory) w podklasach tej klasy nadrzędnej (czyli wszystkich zdefiniowanych w języku TLCC). Aby było to możliwe, konieczne jest użycie zwykłego wskaźnika do funkcji, który jednak nie może przechowywać dowiązań do funkcji składowych. Zatem trzeba wygenerować pewne pomocnicze funkcje (najlepiej użyć tutaj funkcji inline dostępnych w C++), których jedynym zadaniem będzie wywołanie konkretnych wizualizatorów. Czyli dla każdego wizualizatora tworzona jest pomocnicza funkcja, która go wywołuje, a każdy obiekt przechowuje wskaźnik na bieżącą funkcję pośredniczącą (czyli w praktyce na wizualizator).
Oprócz tego każda klasa posiada atrybut, którym jest wskaźnik na domyślną funkcję pośredniczącą (czyli na domyślny wizualizator). Wartość tego atrybutu ustawiana jest statycznie, ponieważ podczas generowania kodu wiadomo, który wizualizator jest domyślny. W konstruktorze tej klasy ustawia się odpowiednio bieżący wizualizator i jest on równy wizualizatorowi domyślnemu.
Sam wizualizator tłumaczony jest na funkcję składową, która przekazuje napis. Tworzenie tego napisu sprowadza się do zadeklarowania zmiennej klasy String i dołączania do niej wartości kolejnych leksemów wizualizacji. Również użycie funkcji print() czy umieszczenie wyrażenia między znacznikami '#' powoduje dołączanie odpowiedniej wartości do tworzonego łańcucha. Także wywołania różnych funkcji specjalnych, takich jak action{} czy field(), powodują wygenerowanie pewnych napisów. Dokładny opis obsługi akcji i formularzy w wizualizatorach znajduje się w następnym punkcie.
Obsługa akcji i formularzy składa się z dwóch części. Najpierw w wizualizatorze trzeba zbudować odpowiednie łańcuchy znaków, zawierające informacje o akcji, którą należy wykonać. Trzeba również przekazać w tych łańcuchach wartości zmiennych lokalnych używanych przez akcję. Natomiast druga część polega na zbudowaniu w konkretnej klasie funkcji pomocniczych, które obsługują poszczególne akcje. Ponadto muszą być dodane specjalne konstrukcje, służące do wywoływania tych funkcji.
Pojawienie się definicji akcji w wizualizatorze powoduje wygenerowanie pewnego odnośnika do strony WWW. Utworzony w ten sposób URL odnosi się do głównej strony serwisu (cały czas tej samej) i posiada cały zestaw parametrów, które określają funkcję do wywołania i jej argumenty. Konkretna akcja identyfikowana jest przy pomocy numeru. Akcje numerowane są w kolejności ich pojawiania się w wizualizatorze. Oprócz tego przekazywany jest numer bieżącej sesji oraz identyfikator obiektu, z którego należy tą akcję wywołać. Potrzebny jest również parametr, który zawiera zakodowane wartości zmiennych lokalnych wizualizatora. Samo kodowanie tych wartości przypomina serializację obiektów, która jest szczegółowo opisana w p. 4.5.2.
W podobny sposób obsługiwane są również akcje związane z formularzami. Wewnątrz formularzy można dodatkowo wiązać zmienne z jego elementami. Działanie funkcji field() polega na wygenerowaniu nazwy, która następnie zostanie rozpoznana przez aplikację przy następnym żądaniu użytkownika. Wtedy nastąpi przypisanie wartości tego elementu na podaną zmienną.
Akcje wymagają pewnych specjalnych atrybutów w definicji klasy. Potrzebna jest tablica wskaźników do funkcji, które reprezentują poszczególne akcje. Wymagana jest również specjalna metoda, która wywołuje funkcje o określonym indeksie w tablicy, z podanymi parametrami. Jeśli chodzi o same definicje funkcji dla akcji, to najpierw funkcja taka musi odtworzyć zmienne lokalne, które były dostępne w wizualizatorze. Korzysta przy tym z łańcucha, w którym te wszystkie wartości są zakodowane. Oprócz zmiennych lokalnych dekodowane są także wartości elementów formularzy i przypisywane na odpowiednie zmienne. Przypisanie może dotyczyć zarówno zmiennych lokalnych (których deklaracje umieszczone są na początku funkcji obsługi), jak i atrybutów klas.
Po wykonaniu tych czynności można w funkcji umieścić oryginalną definicję akcji, zawartą w wizualizatorze. Oczywiście jej kod w TLCC musi podlegać tłumaczeniu, zgodnie ze wszystkimi regułami opisanymi w tym rozdziale.
Wynikowa aplikacja działa w środowisku rozproszonym, więc wymagane jest współdziałanie procesów wchodzących w jej skład. Procesami tymi są:
Przy starcie aplikacji na samym początku tworzone są serwery obiektów dzielonych. Nadrzędny serwer obiektów dzielonych (uruchamiany jako pierwszy proces) tworzy obiekty współdzielonych klas (klasy te zostały wygenerowane podczas translacji). Następnie uruchamiany jest serwer główny, który łączy się z nadrzędnym serwerem obiektów dzielonych i pobiera dowiązania do wszystkich wykorzystywanych obiektów. W kolejnym kroku uruchamiane są zwykłe serwery obiektów dla sesji. Przy starcie rejestrują się w głównym serwerze i otrzymują referencje do obiektów dzielonych, które są zapamiętane jako zmienne globalne w aplikacji.
Aby właściwie przeprowadzić inicjowanie aplikacji konieczny jest plik konfiguracyjny, który zawiera informacje o tym jakie serwery i na jakich maszynach należy uruchomić. W przypadku serwerów obiektów istotny jest numer przypisany do każdego z nich w tym pliku. Jest on wykorzystywany przy tworzeniu identyfikatorów sesji użytkowników. Dzięki niemu serwer główny może rozpoznać, do którego serwera obiektów należy przekierować nadchodzące żądania. Ponadto numer ten jest używany przy konstruowaniu identyfikatora głównego obiektu POA w programie. Dlatego nie może się on zmienić przy restarcie serwera, jeśli chcemy prawidłowo obsługiwać sesje, które zostały utworzone wcześniej.
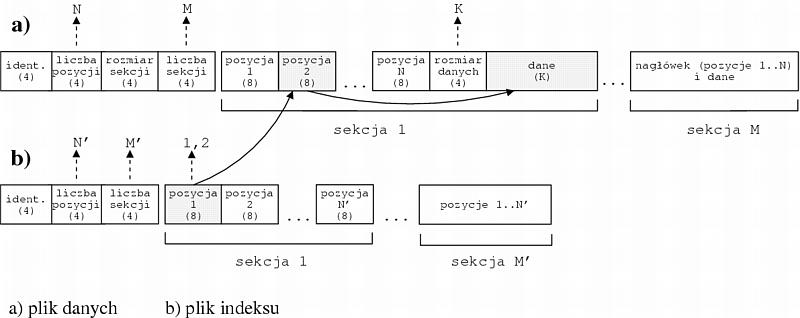
Ponieważ wszystkie obiekty tworzone przez aplikację są trwałe, więc bardzo istotne jest rozwiązanie problemu ich serializacji. W generowanej implementacji każda klasa ma metodę, która daje ciąg bajtów reprezentujący obiekt tej klasy oraz metodę, która na podstawie takiego ciągu bajtów inicjuje odpowiedni obiekt. Zatem ważną rzeczą jest, aby efektywnie zapamiętywać te ciągi bajtów na dysku. W tym celu wykorzystuje się dwa pliki: plik z danymi obiektów i plik z indeksem. Rysunek 4.1 przedstawia ich format. W nawiasie podano rozmiar każdego elementu pliku w bajtach.
Jeśli chodzi o ustalenie pozycji dla nowego obiektu, to najprościej dopisać go w ostatniej sekcji. Natomiast gdy nie ma już miejsca w ostatniej sekcji, to można utworzyć nową sekcję i tam umieścić obiekt. Jednak spowodowałoby to gwałtowny wzrost rozmiaru pliku danych, przy czym w większości byłby on niewykorzystany. Dlatego lepszą strategią jest odzyskiwanie wolnego miejsca w sekcjach, których stopień zapełnienia danymi spadł poniżej pewnego poziomu (granicznego zapełnienia sekcji przy powtórnym użyciu, równego np. 60%). W tym celu należy najpierw uporządkować sekwencje w sekcji, aby stanowiły spójny ciąg bajtów i wtedy można dopisywać kolejne obiekty do tego ciągu. Wielkość sekcji powinna być tak dobrana (można to zrobić w pliku konfiguracyjnym), aby częstość porządkowania była mała. Typowym rozmiarem sekcji jest np. 512 KB, co w przypadku gdy aplikacja używa stosunkowo małych obiektów (np. średnio 16 KB) daje dobry wynik.
Oprócz pliku z danymi potrzebny jest również specjalny indeks, czyli pozycje w pliku danych poszczególnych obiektów. Jest to związane z koniecznością modyfikacji położenia poszczególnych obiektów, na skutek zmiany ich wielkości. Ponieważ POA nie pozwala na modyfikację identyfikatora obiektu, więc identyfikator ten może określać jedynie pozycję obiektu w indeksie (która nie ulega ona zmianom). Natomiast sam indeks zawiera dla każdego obiektu zarówno numer sekcji, w której obiekt ten jest zapisany, jak i pozycję w tablicy nagłówkowej. Dzięki temu można uzyskać dostęp do danych poszukiwanego obiektu na podstawie jego identyfikatora POA.
Plik indeksu posiada strukturę zbliżoną do pliku danych z tym, że uaktualnianie wpisów o poszczególnych obiektach nie wymaga zmiany miejsca tego wpisu. Nie są również potrzebne nagłówki sekcji. W przypadku skasowania obiektu zwalniane jest również miejsce, które ten obiekt zajmował w indeksie. Analogicznie do pliku danych, gdy poziom wypełnienia sekcji wpisami jest niski, to jest ona powtórnie zapełniania przez nowe informacje. Nie jest przy tym potrzebne wcześniejsze porządkowanie tej sekcji.
Przedstawiony format plików przechowujących obiekty po serializacji ma następujące zalety:
Serializacja napisów wymaga jedynie przepisania wszystkich znaków do generowanego ciągu i dodania na końcu specjalnego znacznika końca łańcucha (o wartości 0). Kodowanie tablic jest również proste, gdyż na początku wystarczy podać długość tej tablicy, a później zserializować wszystkie jej elementy. Podobnie jeśli chodzi o zapisywanie struktur - wystarczy zrobić to dla wszystkich atrybutów tej struktury. Nieco większym problemem są natomiast referencje do obiektów. Ponieważ wszystkie obiekty są tworzone przy użyciu mechanizmów systemu CORBA, więc każda referencja zawiera dowiązanie do oryginalnego obiektu. Niestety referencje są dosyć długie (kilkaset bajtów), przy czym niewiele różnią się między sobą. Zatem łatwo można przeprowadzić ich kompresję przed serializacją i dekompresję przy deserializacji obiektu. Szczegółowy opis tej metody kompresji znajduje się w p. 4.5.4.
W obecnej implementacji dezaktywowane obiekty zawsze zapisuje się na dysku (nawet wtedy gdy nie podlegały modyfikacji). Ma to taką zaletę, że obiekty używane wspólnie (np. kolejne elementy listy) zostają zapisane blisko siebie. Dzięki temu powtórny odczyt całej grupy obiektów będzie szybki.
Sesje wymagają szczególnego podejścia, jeśli chodzi o serializację. Nie można odczytywać i zapisywać pojedynczych obiektów tak, jakby nie należały do większej grupy, ponieważ spowodowałoby to bardzo dużą fragmentację danych dla sesji o zmiennej wielkości (każdy obiekt mógłby zostać zapisany w innym miejscu pliku danych). Zatem takie grupy obiektów należy obsługiwać jako całość, tzn. jako pojedynczy obiekt sesji, nie ulegający fragmentacji.
Wykonanie operacji na jakimś obiekcie z sesji oznacza, że trzeba najpierw odczytać wszystkie obiekty z jego grupy. Natomiast zwolnienie pamięci dla obiektów z sesji oznacza, że cała grupa jest serializowana i usuwana z pamięci. Dzięki temu odczyt sesji jest bardzo szybki, ponieważ wszystkie obiekty zapisane są na dysku blisko siebie. W przypadku gdy chcemy wykonać operacje tylko na kilku obiektach, narzut związany z odczytem całej sesji nie jest duży, ponieważ przeczytanie spójnego bloku z dysku zajmuje znacznie mniej czasu niż odczyt kilku małych porcji danych, które jednak nie tworzą spójnego obszaru.
W języku TLCC istnieje możliwość wyłączenia określonych obiektów z sesji i traktowania ich podobnie jak obiektów dzielonych. Oznacza to, że obiekt taki nie będzie serializowany i deserializowany razem z całą grupą obiektów danego użytkownika. Nastąpi to tylko w przypadku wykonania na nim pewnej operacji. Jest to wygodne w przypadku, gdy chcemy dla każdej sesji trzymać np. duży zbiór obiektów i sporadycznie odwoływać się do jednego z nich. Aby zaznaczyć, że tworzony obiekt powinien być odseparowany od sesji, należy go utworzyć przy pomocy operatora new_separated.
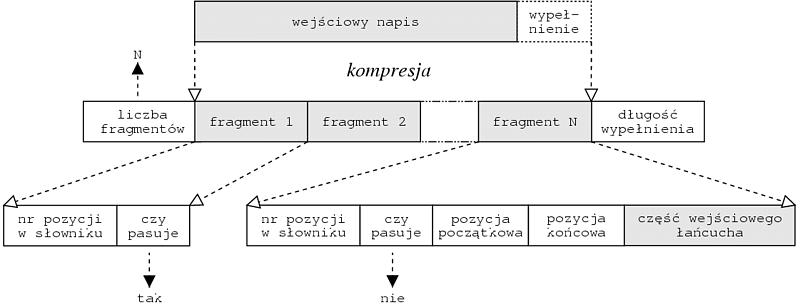
Ponieważ referencje do obiektów korzystających z systemu CORBA są długie, więc trzeba je kompresować przy serializacji obiektów. Można zauważyć, że łańcuchy znaków, które odpowiadają tym referencjom nie różnią się znacznie dla poszczególnych obiektów tworzonych przez ten sam serwer. Często bardzo długie fragmenty tych łańcuchów są w każdym przypadku identyczne.
Wystarczy dany łańcuch podzielić na N równych fragmentów (ich długość jest dobrana przy pomocy testów). Dla każdego fragmentu będziemy używali M bitów jako identyfikatora fragmentu. Zatem można zapamiętać w słowniku fragmentów dla każdej spośród N części łańcucha. Potrzebny jest jeszcze dodatkowy bit, który będzie informował czy użyty fragment całkowicie odpowiada temu, który jest zapamiętany w słowniku. Jeśli występują między nimi jakieś różnice, to do wynikowego łańcucha dołączana jest informacja, która pozwoli odtworzyć oryginalny fragment. Wystarczy zapisać najkrótszy spójny podłańcuch, którym napisy te się różnią (wraz z pozycją tego podłańcucha). Algorytm kompresji referencji ilustruje rysunek 4.2.
Przy kodowaniu danego fragmentu łańcucha wybierany jest taki element ze słownika fragmentów, aby po zakodowaniu napis był jak najkrótszy. Jeśli żaden z dostępnych fragmentów nie powoduje wystarczającego skrócenia tego napisu i jest jeszcze miejsce w słowniku, to do słownika dołączany jest aktualnie kodowany fragment.
Każdy serwer przechowuje swój własny słownik fragmentów, którego używa przy serializacji obiektów i przekazywaniu parametrów do akcji w jego obiektach. Słownik ten jest zapisywany do pliku przy zamykaniu serwera i odczytywany przy starcie.
Do usuwania obiektów, podobnie jak w C++, służy operator delete. Jednak operator ten nie działa na właściwych obiektach, które należy usunąć, lecz na obiektach będących referencjami systemu CORBA. Aby możliwe było zdalne usunięcie obiektu, potrzebna jest specjalna funkcja, która jest dziedziczona z klasy nadrzędnej dla wszystkich obiektów w TLCC. Funkcja ta powoduje zarejestrowanie obiektu jako przeznaczonego do usunięcia. W momencie gdy obiekt ten będzie musiał zostać usunięty z pamięci, nie będzie on zserializowany na dysk tak jak inne obiekty, lecz usunięty. Zostanie również zwolnione miejsce na dysku, które zajmował.
Pewnym problemem jest potrzeba niejawnego usuwania sesji. W przypadku gdy użytkownik porzuci swoją sesję (bo opuścił serwis) należy usunąć wszystkie obiekty z tej sesji po określonym (konfigurowalnym) czasie. W języku TLCC do zarządzania sesją można użyć wbudowanych funkcji transient_session() i persistent_session(), opisanych w p. 3.9.
Jeśli chodzi o samą implementację tego mechanizmu, to wystarczy pamiętać w serwerze obiektów sesje, które mają być w przyszłości usunięte, wraz z czasem ich przyszłego usunięcia. Każde odwołanie do takiej sesji powoduje odświeżenie czasu (przez dodanie do bieżącej wartości ustalonej stałej). Jedynymi problemami przy takim rozwiązaniu są restart serwera oraz potencjalnie duża liczba sesji, których dane należy zapamiętać. Dlatego wymagane jest użycie specjalnego pliku, w którym te informacje są składowane.
Każde żądanie, które przychodzi od użytkownika trafia najpierw do serwera głównego. Jeśli w żądaniu tym nie ma numeru sesji użytkownika, to należy utworzyć nową sesję. Wtedy serwer główny wybiera jeden (kolejny) serwer obiektów i wysyła do niego żądanie, które nadeszło. W przypadku gdy użytkownik posiada już sesję, główny serwer może na podstawie jej numeru określić, jaki serwer obiektów powinien to żądanie obsłużyć.
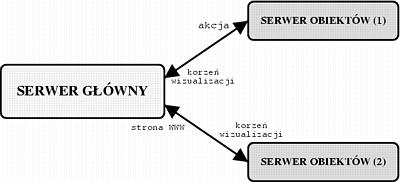
Serwer obiektów po otrzymaniu żądania tworzy nową sesję dla danego użytkownika, bądź lokalizuje sesję, której numer znajduje się w żądaniu. Lokalizacja może oznaczać odczytanie jej z dysku. W przypadku gdy w otrzymanym pakiecie znajduje się zakodowana akcja do wykonania, zostaje znaleziony odpowiedni obiekt, którego ta akcja dotyczy i wykonana właściwa funkcja z tego obiektu. Następnie do głównego serwera obiektów, jako wynik wywołania zdalnej funkcji, przesyłany jest bieżący korzeń wizualizacji. Jest to potrzebne, ponieważ podczas obsługi akcji korzeń ten można zmieniać przy pomocy wbudowanej funkcji set_root(), a nowy korzeń może się znajdować na innym serwerze obiektów. Zatem bardziej wydajne jest bezpośrednie wysyłanie żądań do tego nowego serwera, który zawiera sesję, do której użytkownik się podłączył. Proces taki zachodzi np. przy logowaniu się użytkownika do serwisu.
W kolejnym kroku serwer główny wysyła polecenie wizualizacji do bieżącej sesji danego użytkownika, podając przy tym aktualny korzeń wizualizacji. Otrzymana strona WWW jest następnie odsyłany przez serwer główny jako odpowiedź na żądanie HTTP. Sytuację, gdy w wyniku obsługi akcji zmienia się korzeń wizualizacji, ilustruje rysunek 4.3.
W implementacji zdalnego wywołania funkcji z obiektów wykorzystywany jest mechanizm POA, udostępniany przez bibliotekę CORBA. Wykorzystanie POA pozwala osiągnąć następujące cele:
Jednak POA narzuca pewne dodatkowe wymagania, jeśli chodzi o generowany kod. Trzeba zainicjować nową instancję POA oraz napisać dodatkową klasę, która będzie zarządcą serwantów (czyli obiektów do których można odwoływać się zdalnie). W kodzie generowanym przez translator serwanty używają tego samego zarządcy, gdyż wszystkie obiekty obsługiwane są według identycznego algorytmu. Polega on na aktywacji obiektu, który został użyty, a nie jest obecny w systemie i dodatkowo usunięcie (co pewien czas) obiektów, które były najmniej wykorzystywane. Oprócz tego konieczne jest generowanie i właściwa obsługa złożonych identyfikatorów obiektów oraz wykonywanie ich serializacji i deserializacji.
Pojedynczy obiekt w systemie opartym na technologii CORBA może obsługiwać żądania pochodzące z innych procesów. Może się zdarzyć, że podczas obsługi jednego wywołania funkcji nadejdzie już następne żądanie do tego samego obiektu. W takim wypadku o działaniu aplikacji decydują cechy implementacji standardu CORBA, z której korzysta program. Wiele zależy także od parametrów, z jakimi inicjowany jest obiekt POA w aplikacji.
W pracy korzystałem z systemu MICO CORBA w wersji 2.3.1, która posiada wsparcie jedynie dla jednowątkowego przetwarzania żądań w serwerze obiektów. Z punktu widzenia założeń tej pracy nie jest to wadą, gdyż istnieje możliwość uruchamiania wielu serwerów obiektów (zarówno sesji, jak i dzielonych). Wiele procesów serwerów działających na tej samej maszynie może niezależnie obsługiwać żądania pochodzące od różnych użytkowników.
Jednak w pewnych sytuacjach implementacja MICO zachowuje się podobnie do systemów wielowątkowych. W sytuacji opisanej na początku tego punktu, gdy do pojedynczego obiektu nadejdzie jednocześnie więcej niż jedno żądanie, wykonywanie kodu funkcji wcześniej wywołanej może zostać zawieszone. Dzieje się tak w przypadku, gdy funkcja ta wywoła metodę ze zdalnego obiektu, który znajduje się na innej maszynie. Wtedy biblioteka MICO CORBA nie zawiesza wykonywania aplikacji do czasu otrzymania wyniku, lecz obsługuje inne oczekujące żądania.
Zatem pisząc kod w języku TLCC trzeba zwrócić uwagę na sytuację, gdy wykonywane jest wywołanie funkcji z obiektu, który może się znajdować w innym procesie. Jeśli istnieje prawdopodobieństwo, że jakiś inny proces wywoła w tym czasie funkcję z obiektu implementowanej klasy, to należy zapewnić bezpieczeństwo takiego wywołania. Wystarczające jest spełnienie dwóch warunków:
Następny przykład ilustruje sposób korzystania z tych funkcji:
if (obj.lock())
{
// wywołanie różnych funkcji z obiektu 'obj'
obj.unlock();
}
else
// obsłużenie braku dostępu do obiektu
Przedstawiony kod jest tylko jednym z wielu możliwych rozwiązań. Bazuje
on na tym, że przed dostępem do chronionego obiektu wykonywane jest
sprawdzenie, czy z tego obiektu można skorzystać.
Aby aplikacja wygenerowana przez translator mogła obsługiwać żądania HTTP, potrzebny jest serwer WWW. W obecnej wersji wykorzystywany jest pomocniczy program-dyspozytor (o nazwie dispatcher), którego zadaniem jest przyjmowanie połączeń HTTP i przesyłanie otrzymanych żądań do serwera głównego. Obsługa użytkowników wykonywana jest asynchronicznie, tzn. podczas oczekiwania na odpowiedź od serwera głównego, dyspozytor jest gotowy do obsługiwania kolejnych połączeń.
Istnieje również możliwość napisania specjalnego modułu do popularnego serwera Apache [1], który analogicznie do programu dispatcher przesyłałby żądania serwerowi głównemu aplikacji. Innym rozwiązaniem jest skorzystanie z mechanizmu CGI (ang. Common Gateway Interface) [6] do komunikacji między serwerem WWW a wynikową aplikacją.