W tym rozdziale chciałbym przedstawić przykładową aplikację działającą za pośrednictwem protokołu HTTP oraz porównać program napisany w języku TLCC z analogicznymi programami zbudowanymi przy pomocy innych systemów. Istnieje wiele różnych narzędzi umożliwiających tworzenie serwisów WWW. Do najpopularniejszych należą języki skryptowe, takie jak PHP [12] czy ASP [2], a także pakiet J2EE [8] oparty na języku Java. W tym rozdziale zestawię fragmenty kodu w TLCC z odpowiadającymi im fragmentami programów w PHP i Javie.
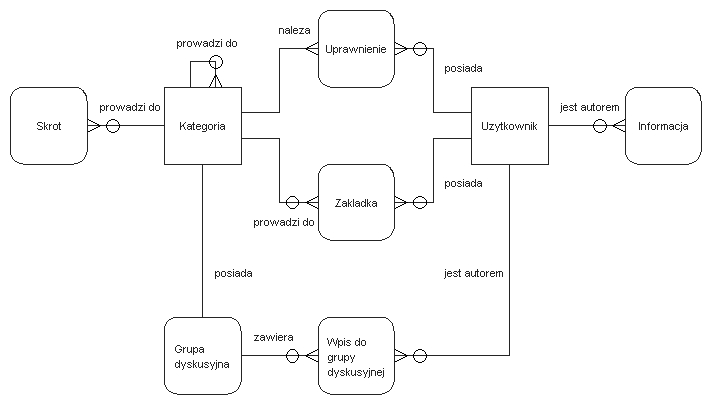
Przykładowy serwis, którego dotyczą te porównania, to katalog stron WWW, pogrupowanych ze względu na kategorie. Poszczególne kategorie tworzą drzewiastą strukturę, której liśćmi są odnośniki do konkretnych stron. Użytkownicy posiadający odpowiednie uprawnienia mogą modyfikować poszczególne węzły struktury. Ponadto w przykładowym serwisie dostępne są też inne funkcje, takie jak: dodawanie zakładek do stron przez użytkowników czy grupy dyskusyjne, związane z poszczególnymi kategoriami. Rysunek 5.1 przedstawia diagram związków encji dla tej aplikacji.
W dalszej części rozdziału dokładnie opisuję reprezentację drzewa kategorii i implementację funkcji, które są z nią związane. Pełny kod źródłowy przykładu znajduje się na załączonej dyskietce.
Podwęzły związane z daną kategorią mogą być odnośnikami do konkretnych stron WWW (umieszczanych w tym katalogu) lub podkategoriami (które zawężają temat kategorii nadrzędnej). W danej grupie znajdują się tylko elementy tego samego typu (np. tylko podkategorie). Każdy węzeł posiada następujące atrybuty:
Najwygodniej jest reprezentować poszczególne kategorie
jako obiekty. Podobnie jak w systemie plików można przyjąć, że dowolny
węzeł zawiera wszystkie informacje o jego węzłach potomnych (czyli
tytuł, opis itp.). Zatem definicje odpowiednich struktur i klas, skrócone
do samych atrybutów, będą wyglądały następująco:
// TLCC
struct NodeData
{
string title;
string description;
string href;
TopicNode topicNode;
}
class TopicNode
{
NodeData[] pathData;
NodeData[] childrenData;
}
Struktura NodeData zawiera dane pojedynczego węzła w drzewie. Natomiast klasa TopicNode reprezentuje grupę tematyczną. Grupa ta może zawierać zarówno podgrupy, jak i odnośniki do konkretnych stron.
Oprócz tego w klasie TopicNode należy zdefiniować różne metody pozwalające wykonywać operacje na węzłach, czyli dodawanie i usuwanie węzłów potomnych, pobieranie tytułu, opisu itp. Ponieważ każda grupa zawiera dane kategorii na ścieżce prowadzącej od korzenia do bieżącego węzła (wystarczy pamiętać tytuł i referencję do obiektu), więc nie ma potrzeby pobierania tych informacji ze wszystkich obiektów na tej ścieżce. Aby zapewnić, że tytuły kategorii nadrzędnych są aktualne, wystarczy co pewien czas sprawdzać, czy zgadzają się z danymi węzła, który jest ojcem (wszystkie zmiany będą przenoszone wraz z poruszaniem się w głąb drzewa).
W przypadku gdy grup tematycznych jest bardzo dużo trzeba się liczyć z tym, że każdorazowe odwołanie do pewnej grupy jest związane z odczytaniem obiektu z dysku. Lecz w opisywanym modelu przy wyświetlaniu danej grupy będziemy mieli jedynie odwołania do dwóch obiektów (bieżącej kategorii oraz jej ojca), więc obsługa żądań od użytkowników będzie szybka. Oczywiście za samo składowanie i aktywowanie obiektów odpowiada kod generowany automatycznie przez translator.
Jeśli chcielibyśmy napisać naszą aplikację w PHP lub w Javie i nie napracować się nad przechowywaniem informacji o kategoriach, to najlepiej jest skorzystać z bazy danych (zasady projektowania baz danych opisane są w pozycji [3]). Potrzebujemy tabeli, w której będą składowane informacje o węzłach w drzewie grup. Jej strukturę zilustrowano w tabeli 5.1.
|
Jednak w tym przypadku pojawia się pewien problem. Aby pobrać tytuły kategorii na ścieżce od danego węzła do korzenia, trzeba dla każdego węzła na tej ścieżce wykonać osobne zapytanie. Jeśli korzystamy z bazy danych Oracle, to rozwiązaniem jest konstrukcja CONNECT BY PRIOR, ale w przypadku darmowych baz danych (np. MySQL czy PostgreSQL) trzeba wprowadzić dodatkową tabelę grupującą węzły nadrzędne dla poszczególnych kategorii. Jej strukturę ilustruje tabela 5.2.
|
Widoczna jest także jeszcze jedna różnica między podejściem bazodanowym i obiektowym. W obiektach TLCC atrybuty wszystkich węzłów podrzędnych są zebrane w jednej tablicy, dzięki czemu mamy pewność, że ich odczyt z dysku będzie szybki. Natomiast w przypadku bazy danych informacje o każdej kategorii podrzędnej znajdują się w osobnym wierszu, a poszczególne wiersze wcale nie muszą być zapisane blisko siebie, więc czas ich odczytu będzie dłuższy. Innym rozwiązaniem może być umieszczenie w tabeli opisującej węzeł wszystkich informacji o potomkach (tak jak w obiektach). Dane te mogą być zapisane jako serializowane obiekty (Javy lub PHP) lub złożone typy danych, udostępniane przez PostgreSQL. Jednak w przypadku zmian wielkości tych danych (zakładamy, że do kategorii mogą być często dodawane nowe elementy) dostęp do nich będzie coraz wolniejszy, ze względu na fragmentację poszczególnych wierszy tabeli w bazie danych. Jeszcze inne podejście mogłoby polegać na stworzeniu specjalnego pliku do zapisu tych informacji. Lecz implementacja operacji na takim pliku byłaby znacznie bardziej czasochłonna niż stworzenie tabel lub definicji odpowiednich klas w TLCC.
Oprócz skryptów tworzących bazę danych lub kodu zarządzającego odpowiednim plikiem musimy jeszcze dodać do naszej aplikacji odpowiednie klasy (Javy lub PHP), które będą wykonywały zapytania i udostępniały informacje o poszczególnych kategoriach. Ponadto muszą istnieć funkcje, które w przypadku modyfikacji tych danych zmienią również zawartość bazy. Widać zatem, że musimy stworzyć kod, który zarządza nie tylko danymi lokalnymi aplikacji, ale również informacjami zgromadzonymi w bazie. W przypadku aplikacji napisanej w TLCC możemy się ograniczyć tylko do operacji na danych lokalnych, które są automatycznie zapamiętywane w sposób trwały.
Zatem w kolejnych przykładach zakładam, że w kodzie programów korzystających z bazy danych znajduje się klasa NodeData, która reprezentuje informacje o grupach i odnośnikach w naszej aplikacji. Jej definicja odpowiada definicji struktury NodeData, z p. 5.2.1. Wystarczy ją tylko przepisać na PHP lub Javę (referencji do węzła odpowiada jego identyfikator o nazwie nodeId).
Gdybyśmy chcieli zbudować w Javie aplikację o zbliżonej architekturze do programów generowanych przez translator TLCC, to wiązałoby się to z dodatkowym nakładem pracy. Trzeba by napisać takie programy jak: serwer główny, serwer obiektów (sesji) i serwer obiektów dzielonych. Natomiast w serwerze obiektów należałoby zaimplementować takie mechanizmy jak rejestracja obiektów, zapamiętywanie danych związanych z sesjami, rozpoznawanie wywołanych akcji, wizualizacje itp.
Ponadto potrzebna jest specjalna biblioteka, która korzystając z architektury POA zapewni trwałość obiektów i sesji użytkowników. Należałoby przy tym zmodyfikować mechanizm serializacji obiektów w taki sposób, aby łańcuchowe referencje używane w systemie CORBA były w pewien sposób kompresowane (w obrębie tego samego procesu olbrzymia większość danych zawartych w referencji jest identyczna dla wszystkich obiektów). Natomiast w TLCC opisywane problemy rozwiązywane są przez translator.
Nawet w przypadku napisania specjalnej biblioteki w Javie jej użycie nie byłoby wygodne. Przykładem mogą być atrybuty statyczne i dzielone, dla których trzeba tworzyć osobne klasy i ręcznie nimi zarządzać (należy np. zadbać aby widoczność atrybutów statycznych ograniczała się do bieżącej sesji). Innym przykładem jest konieczność blokowania obiektu, który obsługuje jakieś żądanie (aby nie została przeprowadzona jego dezaktywacja). Nie bez znaczenia są także różne utrudnienia, związane z bezpośrednim użyciem technologii CORBA (np. oddzielenie właściwego obiektu od zdalnego pośrednika, konieczność definiowania interfejsów lub potrzeba korzystania z różnych klas pomocniczych itp.).
Implementując fragmenty aplikacji obsługującej listy
tematów można pokazać, że obsługa danych wspólnych dla użytkowników
jest łatwiejsza w języku TLCC. Jako ilustrację można podać kod metod,
które powinny się znaleźć w klasie TopicNode. Jednym z przykładów
jest funkcja, która modyfikuje dane węzła potomnego, takie jak tytuł,
opis i odnośnik.
// TLCC
void modifyChild(int index, NodeData nodeData)
{
childrenData[i] = nodeData;
}
Natomiast gdy chcemy pobrać dane wszystkich elementów podrzędnych,
to używamy funkcji getChildrenData(), której implementacja
jest również oczywista:
// TLCC
NodeData[] getChildrenData()
{
return childrenData;
}
Zatem korzystając z tego, że wszystkie informacje zapamiętujemy w
zwykłej tablicy, możemy ją po prostu przekazać, bez jakiejkolwiek
obróbki. Nie jest to możliwe w przypadku zastosowania bazy danych,
co pokazują kolejne przykłady.
Wszelkie operacje na tablicach, wykonywane w przykładowym serwisie są proste i krótkie w implementacji. W dodatku B zostały opisane różne pomocnicze funkcje, które jeszcze bardziej ułatwiałyby korzystanie z tablic.
Implementując obsługę list tematów w PHP musimy w jakiś sposób przechowywać zgromadzone informacje. Załóżmy, że chcemy napisać w PHP klasę pomocniczą Database, której zadaniem jest wykonywanie operacji na bazie danych (np. MySQL). W tym punkcie znajdują się przykłady implementacji metod z tej klasy, których działanie jest analogiczne do tych przedstawionych w p. 5.3.1 (dla TLCC).
Oto funkcja modyfikująca węzeł o określonym identyfikatorze.
// PHP
function modifyNode($nodeData)
{
$query = "UPDATE NODE_DATA SET TITLE='{$nodeData
-> title}', ";
$query .= "DESCRIPTION='{$nodeData -> description}',
";
$query .= "HREF='{$nodeData -> href}' WHERE NODEID={$nodeData
-> nodeId}";
mysql_query($query);
}
Natomiast gdy chcielibyśmy pobrać dane wszystkich węzłów podrzędnych
aby wyświetlić zawartość grupy o konkretnym identyfikatorze, musimy
zbudować tablicę na podstawie informacji zapisanych w bazie.
// PHP
function getChildrenData($nodeId)
{
$query = "SELECT * FROM NODE_DATA WHERE PARENTID=$nodeId";
$res = mysql_query($query);
$nr = 0;
while ($row = mysql_fetch_row($res))
{
$data = new NodeData();
$data -> nodeId = $row["nodeId"];
$data -> title = $row["title"];
$data -> description = $row["description"];
$data -> href = $row["href"];
$childrenData[$nr] = $data;
$nr++;
}
return $childrenData;
}
Na podanym przykładzie wyraźnie widać, że to co uzyskaliśmy w TLCC
przy pomocy jednego wiersza, w PHP wymaga dłuższego kodu. Dodatkowo
TLCC ma tą przewagę, że dostęp do danych kategorii podrzędnych jest
bardzo szybki, ponieważ zapisane są one blisko siebie (w tym samym
obiekcie). Natomiast jeśli chodzi o bazę danych, to nie mamy żadnych
gwarancji, że poszczególne wiersze tej tabeli nie będą oddalone od
siebie na dysku (przypuszczenie to potwierdziło się w testach, opisanych
w rozdziale 6).
Jeśli chodzi o Javę, to podobnie jak w PHP do przechowywanie
informacji dzielonych wykorzystujemy bazę danych. Przypuśćmy, że tak
jak w PHP implementujemy pomocniczą klasę Database, która
wykonuje pomocnicze operacje. Oto kod funkcji modifyNode()
i getChildrenData().
// Java
void modifyNode(NodeData nodeData)
{
String query = "UPDATE NODE_DATA SET TITLE=?, ";
query += "DESCRIPTION=?, HREF=? WHERE NODEID=?";
PreparedStatement ps = conn.prepareStatement(query);
ps.setString(1, nodeData.title);
ps.setString(2, nodeData.description);
ps.setString(3, nodeData.href);
ps.setInt(4, nodeData.nodeId);
ps.executeUpdate();
}
Vector getChildrenData(int nodeId)
{
String query = "SELECT * FROM NODE_DATA WHERE nodeId=?";
PreparedStatement ps = conn.prepareStatement(query);
ps.setInt(1, nodeId);
ResultSet rs = ps.executeQuery();
Vector childrenData = new Vector();
while (rs.next())
{
NodeData data = new NodeData();
data.nodeId = rs.getInt("nodeId");
data.title = rs.getString("title");
data.description = rs.getString("description");
data.href = rs.getString("href");
childrenData.add(data);
}
return childrenData;
}
W podanym kodzie zakładamy, że zmienna conn zawiera obiekt,
który zapewnia połączenie z bazą danych. Można zauważyć, że definicje
funkcji w Javie są trochę dłuższe od swoich odpowiedników w PHP (zwłaszcza
funkcja modifyNode()), ale też trochę bardziej przejrzyste
(ze względu na specjalne obiekty pośredniczące w wykonywaniu zapytań
do bazy). Kod w Javie jest jednak znacznie dłuższy niż w TLCC (głównie
jeśli chodzi o drugą funkcję), gdyż wymaga wykonywania zapytań w języku
SQL.
W opisywanym systemie zarządzania grupami tematycznymi
użytkownik ma możliwość wykonania wielu różnych działań. Przykładowo,
dla każdej wyświetlanej podgrupy użytkownik z odpowiednimi uprawnieniami
może: wejść do tej podgrupy, rozpocząć jej modyfikację lub skasować
podgrupę. Dla uproszczenia można pominąć przypadek, gdy wyświetlany
element nie jest grupą, tylko końcowym odnośnikiem, a także sprawdzanie
uprawnień użytkownika. Kolejny przykład zawiera kod obsługujący poszczególne
akcje, który można umieścić w wizualizatorze.
// TLCC
NodeData[] data = currentTopicNode.getChildrenData();
[<table>]
for(int i = 0; i < data; i++)
{
NodeData elem = data[i];
[
<tr>
#{
if (modifiedIndex
== i);
// tutaj należy wyświetlić formularz
do edycji elementu
else
[
<td><a href=#action{
currentTopicNode = elem.topicNode;
modifiedIndex = -1;
}#><b>#elem.title#</b></a></td>
<td><i>#elem.description#</i></td>
<td><a href=#action{
modifiedIndex=i}#>MODYFIKUJ</a></td>
<td><a href=#action{
currentTopicNode.removeChild(i)}#>USUŃ</a></td>
]
}#
</tr>
]
}
[</table>]
Zakładam, że atrybuty currentTopicNode i modifiedIndex
zawierają odpowiednio referencję do obiektu bieżącej kategorii i numer
edytowanego elementu w tej grupie. Zakładam również istnienie metody
TopicNode::removeChild(), która usuwa element potomny o podanym
indeksie.
Aby rozpoznawać akcje w PHP należy najpierw ustalić
zmienną, przez którą będą one przekazywane (np. zmienna action).
Następnie trzeba wprowadzić identyfikatory, poprzez które będziemy
rozpoznawać akcję do wykonania. Najlepiej użyć w tym celu specjalnych
zmiennych, aby nie podawać jako identyfikatorów konkretnych napisów.
// PHP
$ACTION_SET_TOPIC = "setTopic";
$ACTION_MODIFY = "modify";
$ACTION_REMOVE = "remove";
Przed wyświetleniem wynikowej strony WWW trzeba obsłużyć zdefiniowane
akcje, żeby zawartość tej strony uwzględniała działanie użytkownika.
// PHP
switch ($action)
{
case $ACTION_SET_TOPIC:
$currentTopicId = $nodeId;
$modifiedIndex = -1;
break;
case $ACTION_MODIFY:
$modifiedIndex = $indexNum;
break;
case $ACTION_REMOVE:
$database -> removeNode($nodeId);
}
Zakładamy, że mamy dostępne zmienne $currentTopicId oraz
$modifiedIndex, które są umieszczone w sesji PHP. Ponadto
na zmiennej $database znajduje się obiekt klasy Database,
który odpowiada za komunikację z bazą danych.
Poniżej znajduje się już odpowiednik kodu z p. 5.4.1,
przepisany na PHP.
// PHP
$data = $database -> getChildrenData();
$size = sizeof($data);
echo "<table>\n";
for($i = 0; $i < $size; $i++)
{
$elem = $data[$i];
echo "<tr>\n";
if ($modifiedIndex == $i);
// wyświetlenie formularza do edycji elementu
else
echo <<<EOT
<td><a href="$REQUEST_URI?action=$ACTION_SET_TOPIC&
nodeId={$elem -> nodeId}">
<b>{$elem -> title}</b></a></td>
<td><i>{$elem -> description}</i></td>
<td><a href="$REQUEST_URI?action=$ACTION_MODIFY&
indexNum=$i">MODYFIKUJ</a></td>
<td><a href="$REQUEST_URI?action=$ACTION_REMOVE&
nodeId={$elem -> nodeId}">USUŃ</a></td>
EOT;
echo "</tr>\n";
}
echo "</table>\n";
Na podanym przykładzie widać, że parametry muszą być przekazywane
jako łańcuchy, a przy obsłudze akcji nazwy tych parametrów stają się
zmiennymi. W przypadku większej liczby akcji łatwo się pomylić i podać
nieprawidłową nazwę parametru. Wszystkie odnośniki reprezentujące
akcje musimy przygotować ręcznie. Ponadto wstawianie bloków kodu HTML
nie jest tak czytelne jak w TLCC.
Budowa kodu obsługującego akcje w serwletach Javy jest
zbliżona do PHP. Jednak w Javie nie możemy łatwo wstawiać napisów
składających się z wielu wierszy. Przechowywanie danych w sesji też
wymaga trochę więcej pracy. Ponieważ dostęp do parametrów zapytania
odbywa się za pośrednictwem zwykłych napisów, więc można zdefiniować
stałe dla wszystkich obsługiwanych parametrów, akcji i zmiennych sesyjnych.
Poprawność użycia tych parametrów zostanie sprawdzona podczas kompilacji.
// Java
static final String PARAM_ACTION = "action";
static final String PARAM_NODE_ID = "nodeId";
static final String PARAM_INDEX_NUM = "indexNum";
static final String ACTION_SET_TOPIC = "setTopic";
static final String ACTION_MODIFY = "modify";
static final String ACTION_REMOVE = "remove";
static final String CURRENT_TOPIC_ID = "currentTopicId";
static final String MODIFIED_INDEX = "modifiedIndex";
Natomiast następny fragment kodu wykonuje działania odpowiadające
określonym akcjom. Zakładam, że na zmiennej request znajduje
się obiekt reprezentujący żądanie użytkownika (klasy HttpServletRequest),
a na zmiennej session obiekt sesji związany z tym żądaniem
(klasy HttpSession).
// Java
String action = request.getParameter(PARAM_ACTION);
if (action != null)
if (action.equals(ACTION_SET_TOPIC))
{
session.putValue(CURRENT_TOPIC_ID, new Integer(
Integer.parseInt(request.getParameter(NODE_ID))));
session.putValue(MODIFIED_INDEX, new Integer(-1));
}
else
if (action.equals(ACTION_MODIFY))
session.putValue(MODIFIED_INDEX, new Integer(
Integer.parseInt(request.getParameter(INDEX_NUM))));
else
if (action.equals(ACTION_REMOVE))
database.removeTopicNode(Integer.parseInt(
request.getParameter(NODE_ID)));
Kolejnym krokiem jest wypisanie odpowiedniej strony WWW, która będzie
zawierała listę tematów w grupie. Dodatkowo zakładam, że na zmiennej
out typu PrintWriter znajduje się obiekt, do którego
należy przekazać napisy mające się znaleźć w wygenerowanej odpowiedzi.
// Java
int currentTopicId =
((Integer) session.getValue(CURRENT_TOPIC_ID)).intValue();
int modifiedIndex =
((Integer) session.getValue(MODIFIED_INDEX)).intValue();
String requestURI = request.getRequestURI();
NodeData[] data = database.getChildrenData(currentTopicId);
out.println("<table>");
for(int i = 0; i < data.length; i++)
{
NodeData elem = data[i];
out.println("<tr>");
if (modifiedIndex == i);
// wypisanie formularza
else
{
out.println("<td><a href=\""
+ requestURI + "?" +
PARAM_ACTION + "=" + ACTION_SET_TOPIC
+ "&" +
PARAM_NODE_ID + "=" + elem.nodeId
+ "\">" +
"<b>" + elem.title + "</b></a></td>");
out.println("<td><i>elem.description</i></td>");
out.println("<td><a href=\""
+ requestURI + "?" +
PARAM_ACTION + "=" + ACTION_MODIFY
+ "&" +
PARAM_INDEX_NUM + "=" + i + "\">MODYFIKUJ</a></td>");
out.println("<td><a href=\""
+ requestURI + "?" +
PARAM_ACTION + "=" + ACTION_REMOVE
+ "&" +
PARAM_NODE_ID + "=" + elem.nodeId
+ "\">USUŃ</a></td>");
}
out.println("</tr>");
}
out.println("</table>");
W tym kodzie (podobnie jak w PHP) musimy ręcznie zakodować wszystkie
identyfikatory i parametry akcji. Również generowanie odnośnika z
akcją i sama obsługa akcji znajdują się w różnych miejscach programu.
Samo tworzenie odnośników jest dosyć kłopotliwe. Można je trochę ułatwić
pisząc funkcje pomocnicze, które pobierają pewne identyfikatory i
na ich podstawie konstruują pełny URL. Jednak w takim przypadku z
góry nie wiemy ile argumentów powinna pobrać ta funkcja, ponieważ
liczba parametrów akcji może być dowolna (zatem trzeba będzie zbudować
odpowiedni wektor). Nadal też będziemy musieli jawnie podać te wszystkie
parametry, w przeciwieństwie do TLCC, gdzie są one wykrywane i przekazywane
automatycznie.
Przy pomocy wbudowanych konstrukcji przeznaczonych
do obsługi formularzy, można w języku TLCC bardzo łatwo zintegrować
je z kodem programu. Dzięki temu elementy formularzy nie są tylko
napisami generowanymi przez program, ale mają określoną semantykę.
Oto brakujący kod z poprzedniego przykładu, w którym obsługuje się
modyfikację pojedynczego elementu kategorii (którym jest podgrupa).
// TLCC
if (modifiedIndex == i)
[
<form action=#form_action()#
method="get">
<td><input type="text" name=#field(elem.title)#
value=#elem.title#></td>
<td><input type="text" name=#field(elem.description)#
value=#elem.description#></td>
<td><input type="submit" value="OK"></td>
#form_action{
currentTopicNode.modifyChild(modifiedIndex,
elem);
modifiedIndex = -1;
}#
</form>
]
Wykorzystujemy tutaj funkcję TopicNode::modifyChild(), która
modyfikuje informacje o podanym węźle potomnym.
Aby obsłużyć formularz trzeba zdefiniować odpowiednią
stałą dla akcji z tego formularza. W kodzie obsługującym tą akcję
będziemy mieć dostęp do wartości pól podanych przez użytkownika. Dodatkową
trudnością jest konieczność przekazywania parametrów akcji w polach
ukrytych tego formularza. Przykładowy kod stanowi brakującą część
poprzedniego przykładu dla PHP (przy czym obsługę akcji należy umieścić
na początku programu).
// PHP
$ACTION_MODIFY_TOPIC = "modifyTopic";
if ($action == $ACTION_SET_DATA)
{
$nodeData = new NodeData($nodeId, $title, $description,
"");
$database -> modifyNode($nodeData);
$modifiedIndex = -1;
}
// ------------------------------------
if ($modifiedIndex == $i)
echo <<<EOT
<form action="$REQUEST_URI" method="get">
<td><input type="text" name="title"
value="{$elem -> title}"></td>
<td><input type="text" name="description"
value="{$elem -> description}"></td>
<td><input type="submit" value="OK"></td>
<input type="hidden" name="action"
value="$ACTION_MODIFY_TOPIC">
<input type="hidden" name="nodeId"
value="{$elem -> nodeId}">
</form>
EOT;
Cechą odróżniającą ten kod od przykładu w TLCC jest to, że formularz
i obsługa akcji z nim związanej są rozdzielone oraz fakt, że programista
musi przekazać wszystkie parametry akcji w polach ukrytych. Ponadto
nie ma żadnego sprawdzania poprawności podanych stałych czy zmiennych,
ale to już jest cechą samego PHP, który jest językiem skryptowym i
nie wymaga podawanie typów zmiennych oraz kompilacji kodu przed uruchomieniem.
Podobnie jak w PHP czynności związane z przetwarzaniem
formularzy muszą być w Javie zakodowane ręcznie. Analogicznie należy
zdefiniować odpowiednie stałe i obsłużyć akcję dla formularza.
// Java
static final String ACTION_MODIFY_TOPIC = "modifyTopic";
static final String PARAM_NODE_ID = "nodeId";
static final String PARAM_TITLE = "title";
static final String PARAM_DESCRIPTION = "description";
if (request.getParameter(PARAM_ACTION).equals(ACTION_MODIFY_TOPIC))
{
database.setTopicData(
Integer.parseInt(request.getParameter(PARAM_NODE_ID)),
request.getParameter(PARAM_TITLE),
request.getParameter(PARAM_DESCRIPTION));
session.putValue(MODIFIED_INDEX, new Integer(-1));
}
Natomiast jeśli chodzi o samo wypisanie formularza, to podobnie jak w PHP wszystkie parametry akcji należy przekazać przy pomocy pól ukrytych. Tak samo jak w poprzednim przykładzie dla Javy (obsługa akcji) kolejne wiersze kodu HTML muszą być wypisywane lub dołączane do pewnego napisu. Samo rozwiązanie jest identyczne jak w przypadku PHP, a zmieniają się jedynie szczegóły składniowe. Dlatego druga część przykładu dla Javy została pominięta.
Przypuśćmy, że chcemy rozszerzyć naszą aplikację o możliwość zapamiętywania ulubionych kategorii użytkownika (np. tych, które może edytować lub często przegląda). Lista tych tematów byłaby wyświetlana w formie zakładek, które umożliwiałyby natychmiastowe przejście do określonej kategorii. Ponieważ zestaw tych tematów byłby unikatowy dla każdego użytkownika, więc można po prostu zapamiętać je jako listę obiektów, z których każdy reprezentuje pojedynczą zakładkę. Atrybutami takiego obiektu byłyby np. tytuł, pełna ścieżka, komentarz użytkownika, odnośnik do obiektu kategorii itp. Tytuły i ścieżki mogłyby być weryfikowane w momencie skorzystania z zakładki przez użytkownika lub automatycznie co pewien czas (np. co kilka żądań byłaby weryfikowana jedna zakładka).
Poza metodami i wizualizatorami w samej klasie tego obiektu nie potrzeba żadnego innego kodu obsługującego zakładki, ponieważ cała obsługa interakcji z użytkownikiem jest przeprowadzana w tym obiekcie (przy pomocy akcji). Ponadto każdy obiekt reprezentujący zakładkę będzie automatycznie ładowany wraz z sesją, więc nie trzeba rozwiązywać problemu składowania tych obiektów.
Sesje w TLCC mogą trwać dłużej niż pojedynczy cykl pracy użytkownika z aplikacją. Serwis może wymagać logowania i po pomyślnym ustaleniu tożsamości użytkownika pozwolić mu kontynuować wcześniejszą sesję. Dzięki takiemu podejściu nie trzeba jawnie zachowywać wszystkich danych użytkownika (na wypadek gdyby opuścił sesję) i odtwarzać ich w nowej sesji po zalogowaniu. Do przechowywania sesji wystarczy jedna zmienna dzielona, na której znajduje się słownik użytkowników: kluczami byłyby identyfikatory, a wartościami główne obiekty użytkowników. W momencie logowania przy pomocy wbudowanej funkcji set_root() można by podmienić korzeń wyświetlania.
Dzięki temu, że PHP pozwala zachowywać poszczególne zmienne między kolejnymi żądaniami użytkownika, obsługa sesji jest znacznie ułatwiona. W przypadku zakładek można spróbować zastosować podobne podejście co w TLCC. Zakładkę można zdefiniować przy pomocy klasy i obiekty tej klasy przechowywać na liście, która byłaby zapamiętana na specjalnej zmiennej. Jednak pewnym problemem byłoby w takim przypadku podłączanie się do wcześniej utworzonej sesji, przy logowaniu użytkownika. Obsługa tego zadania nie może się znaleźć wyłącznie w kodzie PHP, ponieważ potrzebujemy listy identyfikatorów sesji dla użytkowników, która byłaby dostępna ze wszystkich uruchamianych skryptów PHP. Zatem trzeba skorzystać z bazy danych i stworzyć specjalną tabelę, która spełniałaby funkcje analogiczne do słownika użytkowników, wykorzystanego w TLCC.
Innym problemem jest tendencja takich sesji do zmiany wielkości. Użytkownicy mogą systematycznie dodawać nowe zakładki do swoich stron, czego efektem będzie stały wzrost wielkości wszystkich sesji. Ponieważ PHP zapamiętuje dane każdej sesji w osobnym pliku, więc w przypadku dużej liczby użytkowników może to spowodować fragmentację - praktycznie każdy następny blok takiego pliku będzie oddalony od poprzedniego. Przypuszczenia te znalazły potwierdzenie w testach, opisanych w rozdziale 6. Wynika to ze sposobu, w jaki przydzielane są kolejne bloki w systemie plików Ext2 [4].
Gdybyśmy chcieli napisać kod całego serwisu w sposób obiektowy przy użyciu PHP, prawdopodobnie wystąpiłyby problemy związane z poprawnością takiego kodu. Ponieważ w PHP nie ma deklaracji zmiennych i ich typów, przeciążania funkcji składowych, a dostęp do atrybutów obiektu musi się odbywać przy pomocy słowa kluczowego this, więc pisanie obiektowego systemu nie jest zbyt wygodne.
W serwletach Javy programista ma do dyspozycji wbudowane sesje, związane z otrzymywanymi żądaniami HTTP. Jednak sesje te mają następujące wady:
Dla wcześniejszego przykładu związanego z tworzeniem zakładek przez użytkownika wymagane jest zatem umieszczenie wszystkich informacji w bazie danych. Ponieważ Java jest językiem obiektowym, więc najlepszym rozwiązaniem będzie napisanie klas pośredniczących między aplikacją, a bazą danych. Obiekty tych klas mogłyby symulować prawdziwe, trwałe obiekty, lecz ich stworzenie wymaga trochę pracy.
Zatem w stosunku do Javy język TLCC ma przewagę jeśli chodzi o łatwość zarządzania sesją. W odróżnieniu od Javy nie trzeba w nim pisać żadnego kodu, który zapewnia trwałość obiektów między kolejnymi żądaniami użytkownika - trwałość ta jest zapewniana automatycznie.
Dzięki możliwości uruchomienia wielu serwerów obiektów, aplikacja napisana w TLCC dobrze się skaluje. Każdy taki serwer zarządza pewną grupą sesji użytkowników i zawsze istnieje możliwość uruchomienia dodatkowych serwerów obiektów. Nowe sesje przydzielane są w taki sposób, by obciążenie serwerów było równomierne. Przy tym nie trzeba umieszczać w programie żadnego dodatkowego kodu obsługującego rozproszone przetwarzanie żądań.
Analogicznie wygląda sprawa dzielenia obciążenia między serwery obiektów dzielonych. Można uruchomić wiele takich serwerów i zapewnić równomierne rozmieszczenie danych. Wystarczy przy tworzeniu nowego obiektu zaznaczyć, że można go umieścić na dowolnym serwerze obiektów dzielonych. Można to zrobić przy pomocy specjalnego operatora new_shared, który wysyła żądanie utworzenia obiektu do najmniej obciążonego serwera.
W aplikacji opisywanej w tym rozdziale poszczególne grupy tematyczne
mogą się znajdować na dowolnych maszynach. Zatem utworzenie nowej
grupy podrzędnej dla bieżącej grupy może wyglądać następująco:
nodeData.topicNode = new_shared TopicNode(currentTopicNode);
Dzięki zastosowaniu systemu CORBA przy odwołaniach do obiektu nie
trzeba się martwić o to, na której maszynie został on stworzony. Wszystkie
potrzebne dane znajdują się w referencji do tego obiektu.
Ponieważ PHP automatycznie przydziela identyfikatory sesji, więc w przypadku równoważenia obciążenia serwisu trzeba ustalić jaki komputer powinien obsłużyć nadchodzące żądanie. Zatem wymagany jest pewien dodatkowy program, który na podstawie informacji o stworzonych sesjach (zapisanych w bazie danych) będzie rozsyłał żądania do odpowiednich maszyn.
Innym rozwiązaniem mogłoby być dołączenie stosownej informacji do wysłanego pakietu HTTP (np. w ciasteczku). Lecz nadal istnieje konieczność zapisania informacji o komputerze obsługującym sesję w bazie danych. W przypadku wielokrotnego korzystania z tej samej sesji (poprzez logowanie) należałoby tą informację odczytać. Nadal też trzeba skorzystać z programu rozsyłającego nadchodzące żądania do właściwych maszyn.
Natomiast w przypadku danych dzielonych pojawia się problem. Można uruchomić wiele baz danych (najlepiej darmowych, jak np. MySQL) na różnych maszynach, lecz administracja tak wieloma bazami byłaby dość kłopotliwa. Przy takim podejściu można by przechowywać poszczególne tabele w różnych bazach. Lecz rozdzielenie danych z jednej tabeli (np. informacji o grupach tematycznych) byłoby bardziej skomplikowane. Wtedy oprócz identyfikatorów samych grup trzeba by zapamiętać identyfikator maszyny, na której przechowywana jest ta grupa. Jednak takie rozwiązanie nie pozwala wykonywać zapytań odnoszących się do całego zbioru grup, jak np. pobranie wszystkich podkategorii dla konkretnej kategorii.
Zatem wymagane jest w takim przypadku zastosowanie jakiejś rozproszonej bazy danych (np. Oracle). Jednak koszt takiego systemu jest bardzo duży. Ponadto przewagą TLCC jest to, że wszelkie operacje na rozproszonych obiektach można wykonywać bezpośrednio, bez konieczności tworzenia specjalnych zapytań.
Problem rozproszonego przetwarzania żądań w przypadku Javy rozwiązuje się bardzo podobnie jak w PHP. Konieczny jest pewien specjalny program, który na podstawie identyfikatora sesji, zawartego w żądaniu, przekieruje je do właściwej maszyny. Funkcjonalność taką zapewniają niektóre kontenery serwletów, jak np. Tomcat. Jednak sama konfiguracja Tomcata i rozmieszczenie źródeł są znacznie bardziej skomplikowane niż w PHP. Odróżnia to kontenery serwletów także od TLCC, w którym cała konfiguracja przetwarzania żądań sprowadza się do edycji jednego, prostego pliku.
Natomiast jeśli chodzi o rozproszone przechowywanie danych dzielonych między sesjami, to sytuacja wygląda identycznie jak w przypadku PHP (ponieważ również korzystamy z bazy danych).
W tej części znajduje się zestawienie cech różniących język TLCC od PHP i Javy. Wymienione zostały wszystkie zalety TLCC związane z łatwością i szybkością tworzenia aplikacji WWW. Natomiast ostatni punkt omawia wady TLCC.
Oto argumenty świadczące o tym, że tworzenie serwisów WWW w PHP jest bardziej złożone niż w proponowanym przeze mnie języku.
Lista stanowi cechy różniące Javę i TLCC.
W przypadku aplikacji, która prezentuje użytkownikowi przechowywane dane w wielu różnych ujęciach (np. wyświetla złożone statystyki) łatwiejsze w implementacji może być użycie zapytań SQL, niż różnych struktur danych przechowujących obiekty. Jednak zapytania te często też są złożone, a ponadto czas ich wykonywania w razie dużej ilości danych w bazie jest długi. Poza tym wykorzystanie skomplikowanych wyrażeń SQL w typowej aplikacji WWW jest rzadkie. Przykładowy serwis, opisywany w tym rozdziale nie wymagał stosowania takich wyrażeń.
Jednak w pewnych (rzadkich) sytuacjach użyteczne byłoby skorzystanie ze specjalnej funkcji do wykonywania globalnych zapytań, które dotyczą wszystkich obiektów w systemie. Projekt takiego rozszerzenia znajduje się w dodatku B. Użycie tej funkcji przypominałoby wykonanie zapytania do bazy danych w programach napisanych w PHP lub Javie, jednak byłoby nieco łatwiejsze w użyciu.